Download as PDF, PPTX











![GO CLIENT
• go get -u github.com/apache/pulsar/pulsar-client-go/pulsar
client, err := pulsar.NewClient(pulsar.ClientOptions{
URL: "pulsar://localhost:6650"
})
producer, err := client.CreateProducer(pulsar.ProducerOptions{
Topic: "my-topic",
})
for i := 0; i < 10; i++ {
err := producer.Send(context.Background(), pulsar.ProducerMessage{
Payload: []byte(fmt.Sprintf("hello-%d", i)),
})
}
• Based on C++ client library — Pure Go client is being worked on
20](https://image.slidesharecdn.com/pulsar-flexiblepub-subforinternetscale-181002061232/85/Pulsar-flexible-pub-sub-for-internet-scale-20-320.jpg)

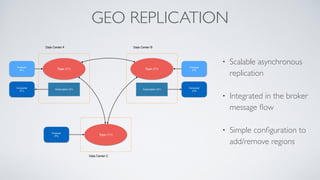


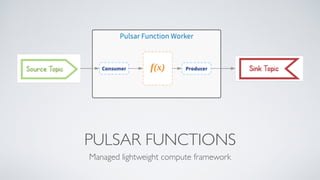




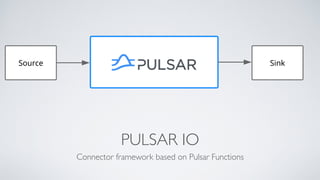

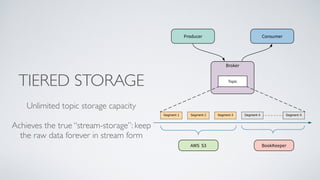






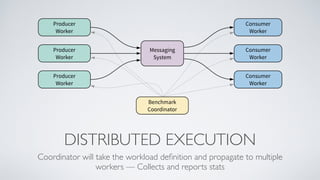
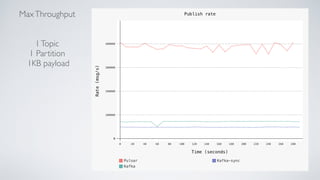
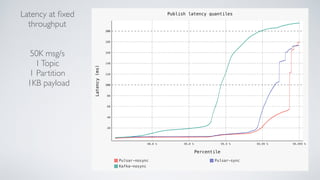
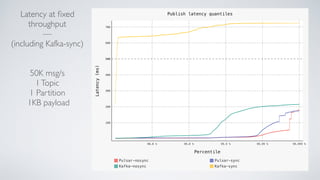
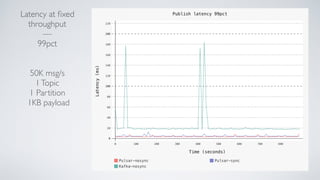


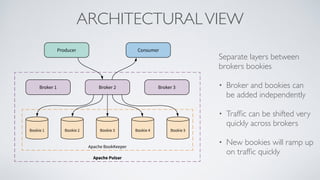
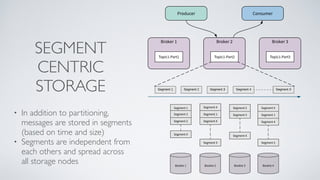
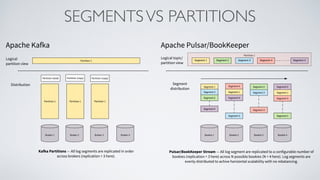
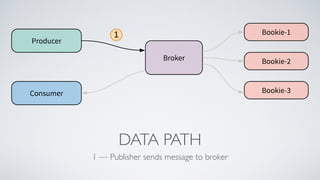
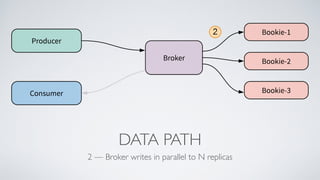
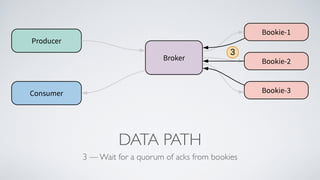
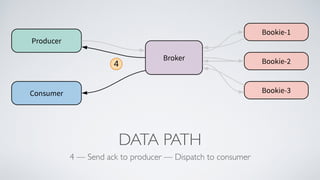
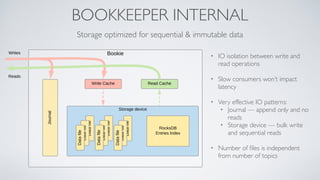
Apache Pulsar is a flexible, multi-tenant pub-sub messaging system designed for large-scale internet applications, offering features like high throughput, low latency, and geo-replication. It evolved from initial development at Yahoo in 2012 to becoming an Apache project, addressing scalability and operational challenges faced by existing systems. The architecture includes separate layers for brokers and storage, and it supports multiple client libraries and functions for processing messages.



































































