Download to read offline



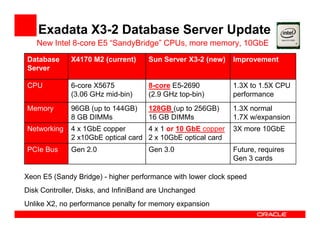
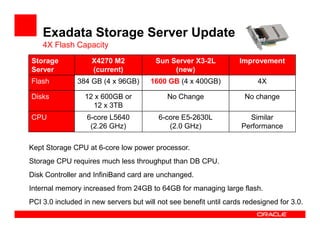
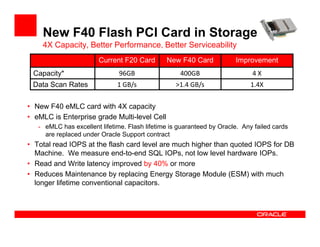







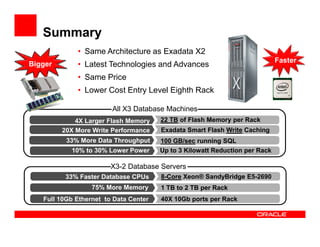
















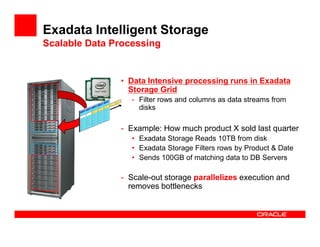
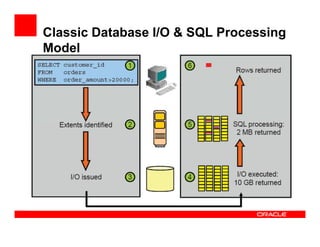
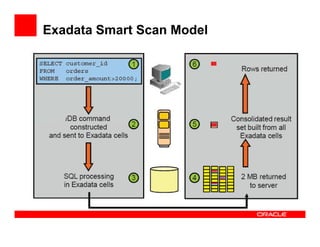
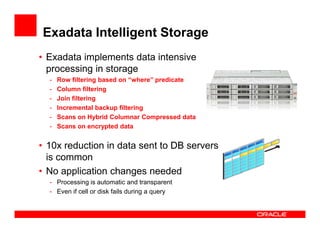
















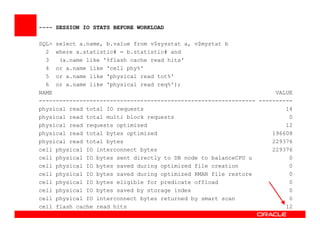

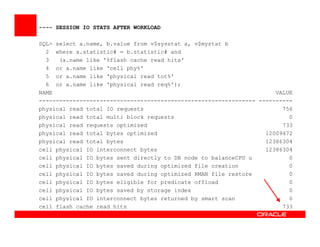



The Exadata X3 introduces new hardware with dramatically more and faster flash memory, more DRAM memory, faster CPUs, and more connectivity while maintaining the same price as the previous Exadata X2 platform. Key software enhancements include Exadata Smart Flash Write Caching which provides up to 20 times more write I/O performance, and Hybrid Columnar Compression which now supports write-back caching and provides storage savings of up to 15 times. The Exadata X3 provides higher performance, more storage capacity, and lower power usage compared to previous Exadata platforms.

































































