Downloaded 50 times




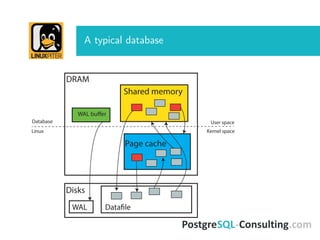



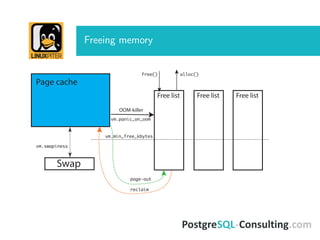



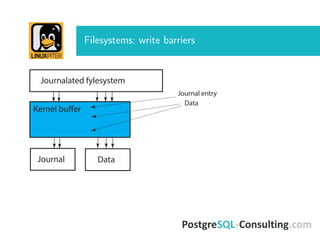

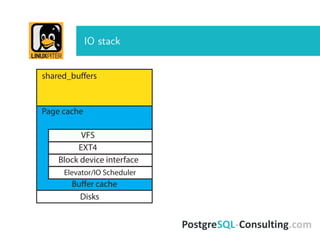



The document discusses Linux I/O internals relevant to database administrators, focusing on I/O problems encountered when operating databases on Linux systems. It emphasizes the importance of configurations such as memory allocation, page synchronization between memory and disks, and tuning various Linux kernel parameters to optimize performance. Key takeaways include the management of shared memory segments, the impact of I/O schedulers, and recommendations for handling potential out-of-memory situations.























































































