Downloaded 28 times


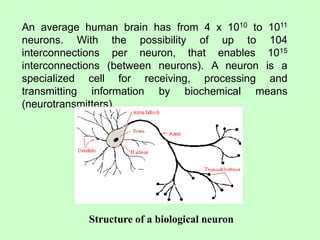
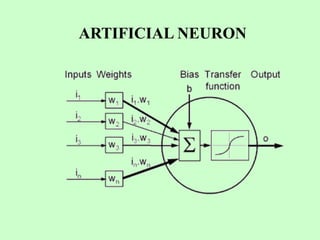

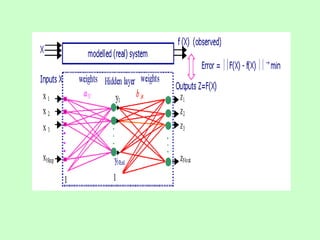












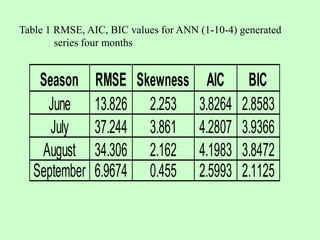
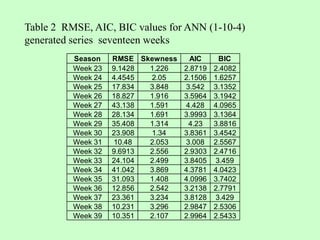
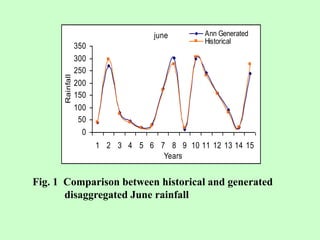
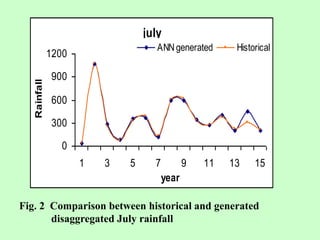
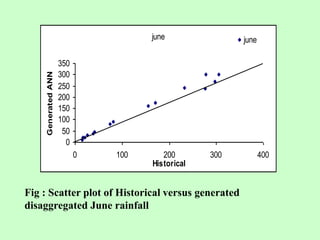
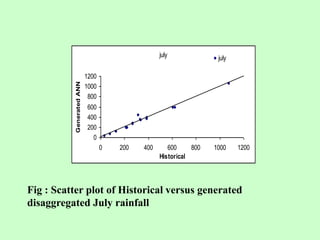

This document discusses the use of artificial neural networks (ANN) to disaggregate annual rainfall data into monthly and weekly series, leveraging the ANN's capabilities in processing complex information. The study details the methodology, including network training and validation processes, with an emphasis on achieving low error values for generated rainfall series. Results indicate that a three-layer ANN architecture effectively captures the historical rainfall patterns, demonstrating congruence with actual recorded data.










































































