Downloaded 762 times

















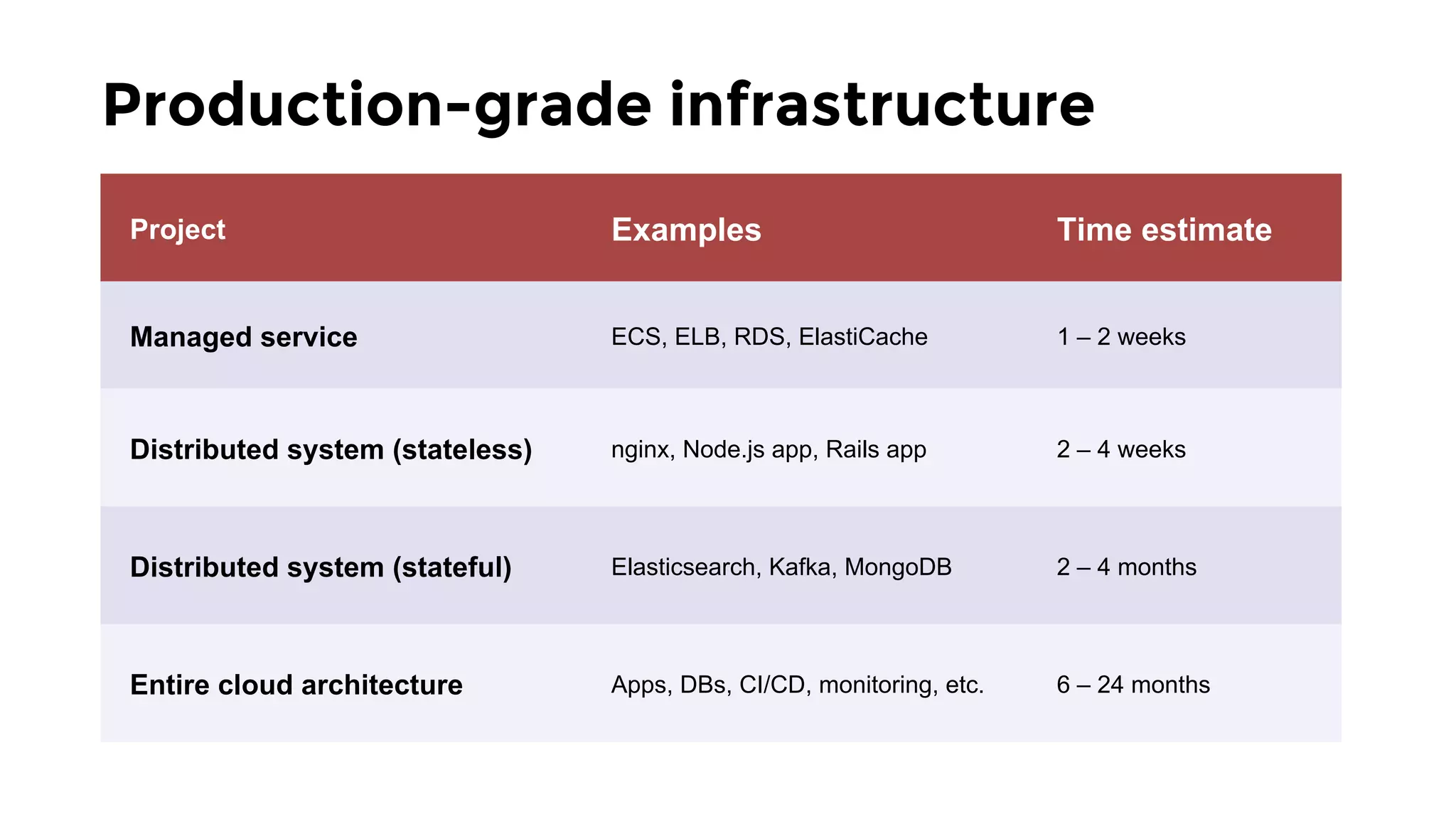









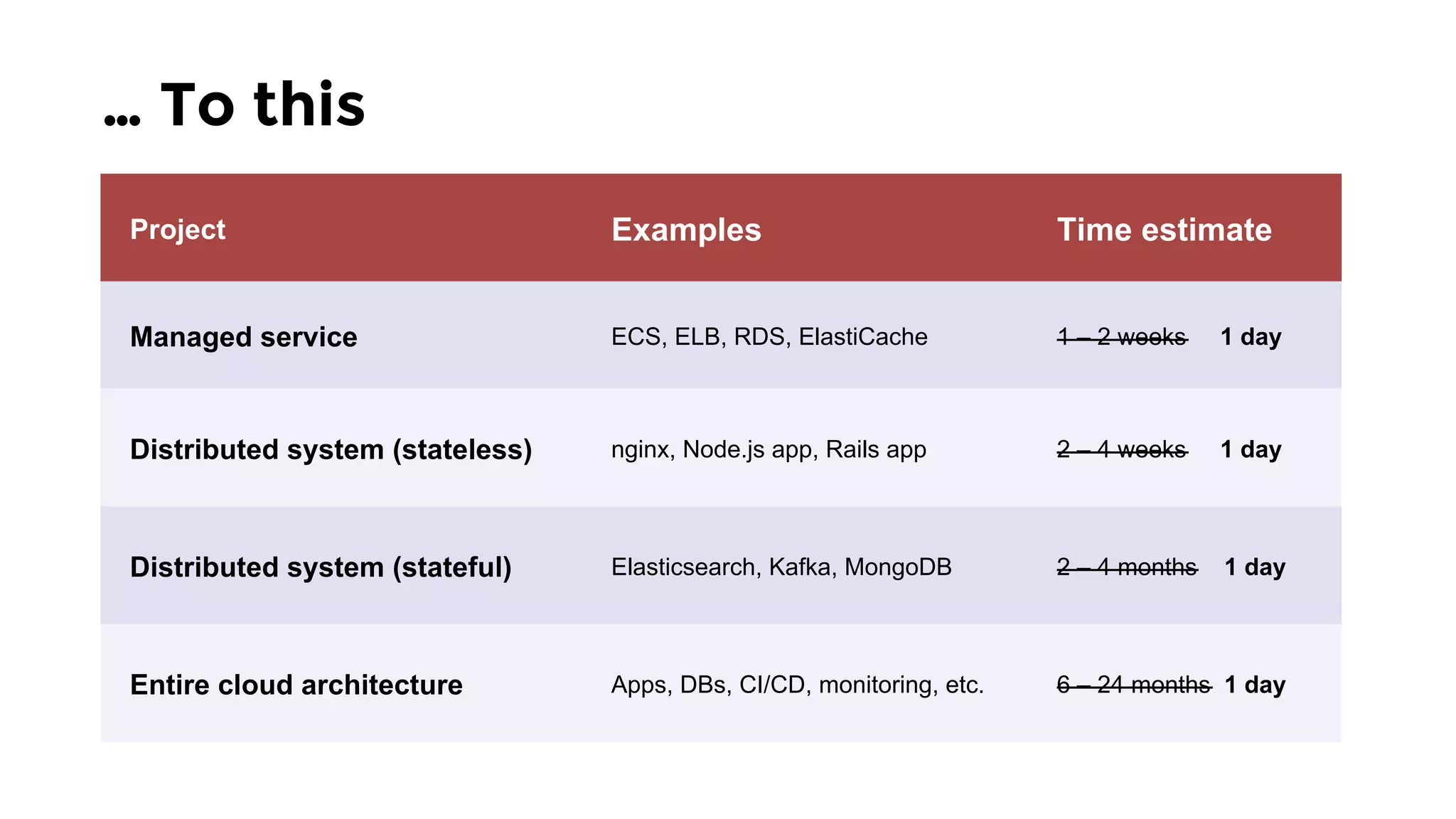







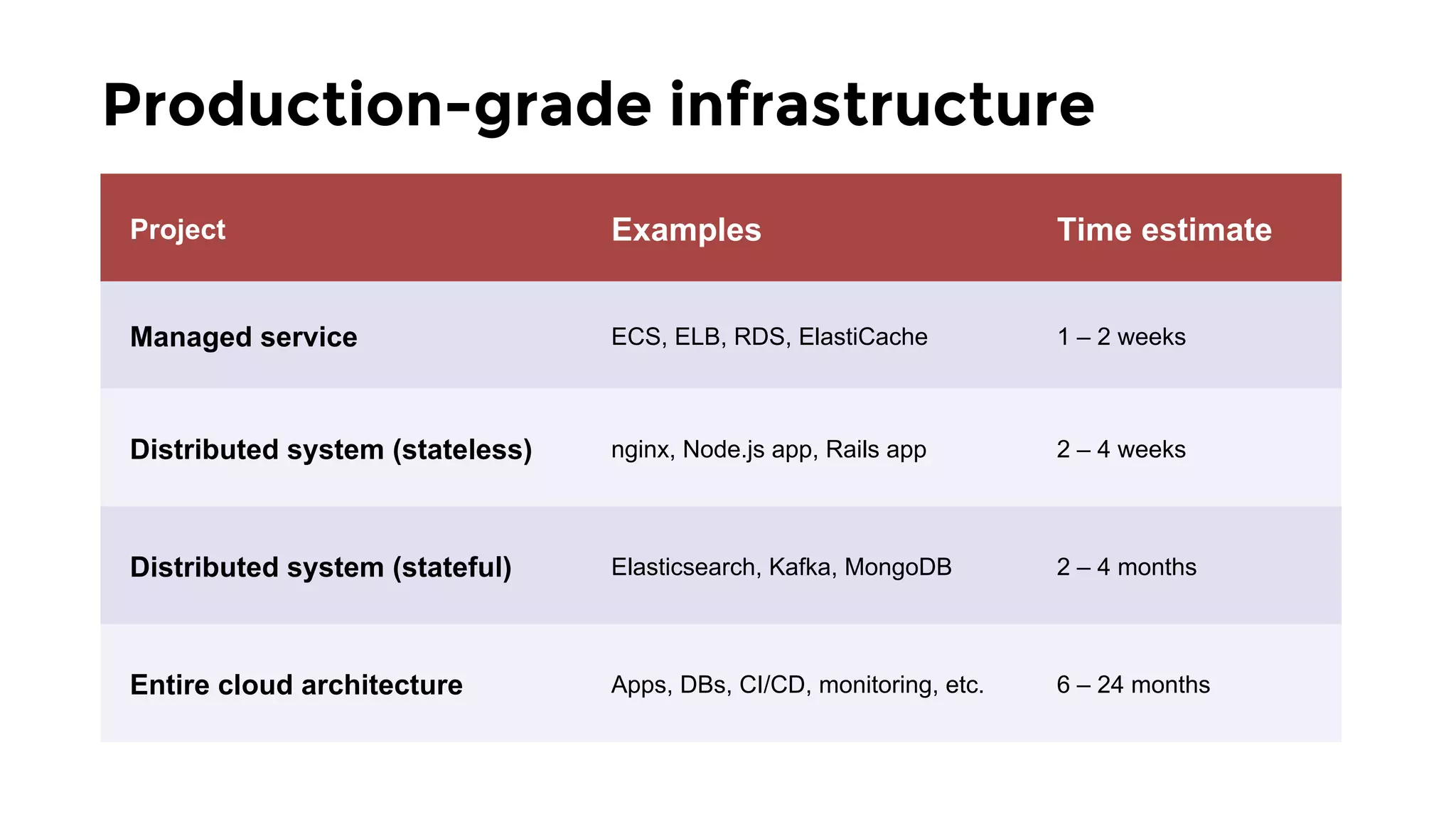





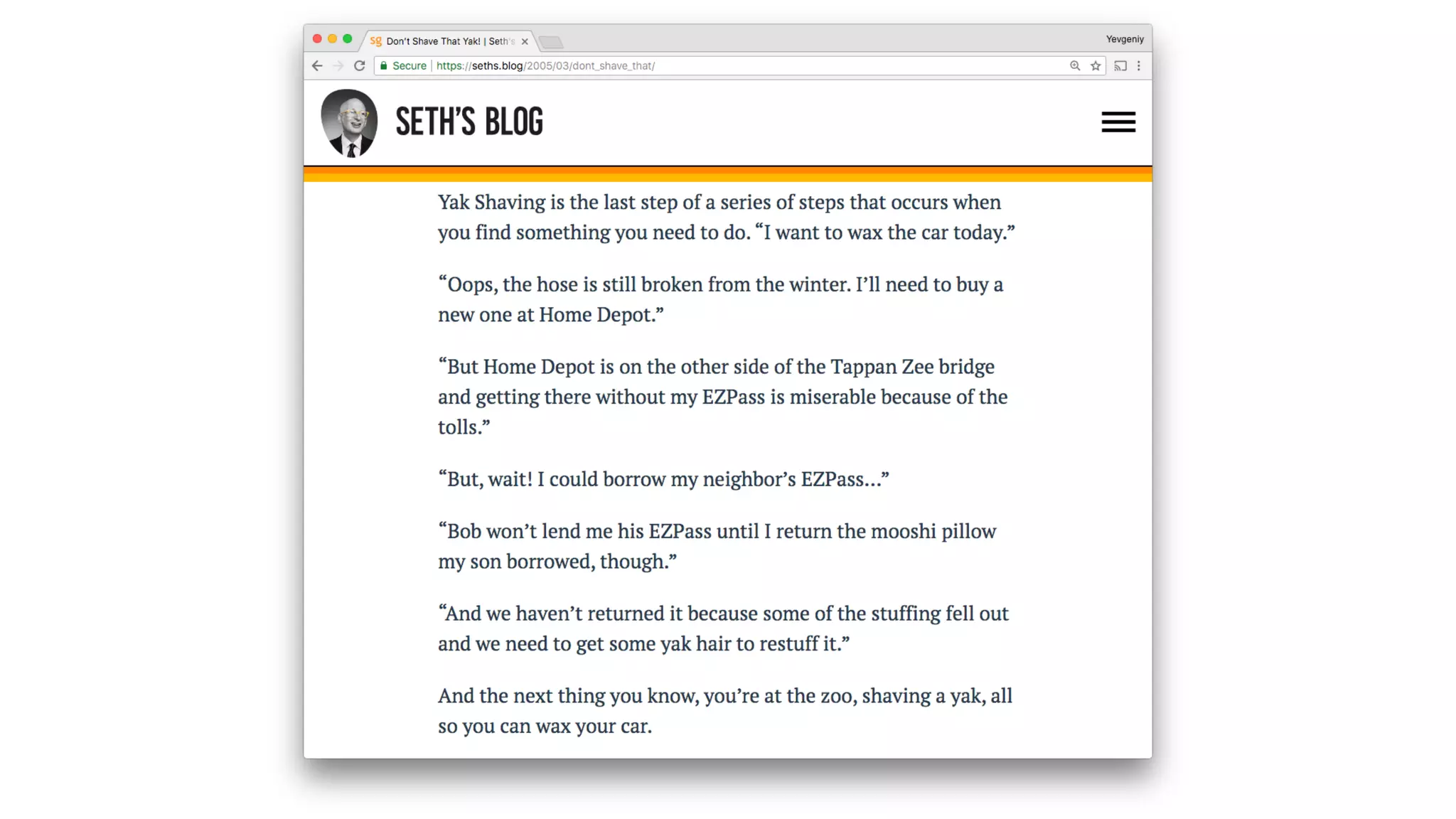



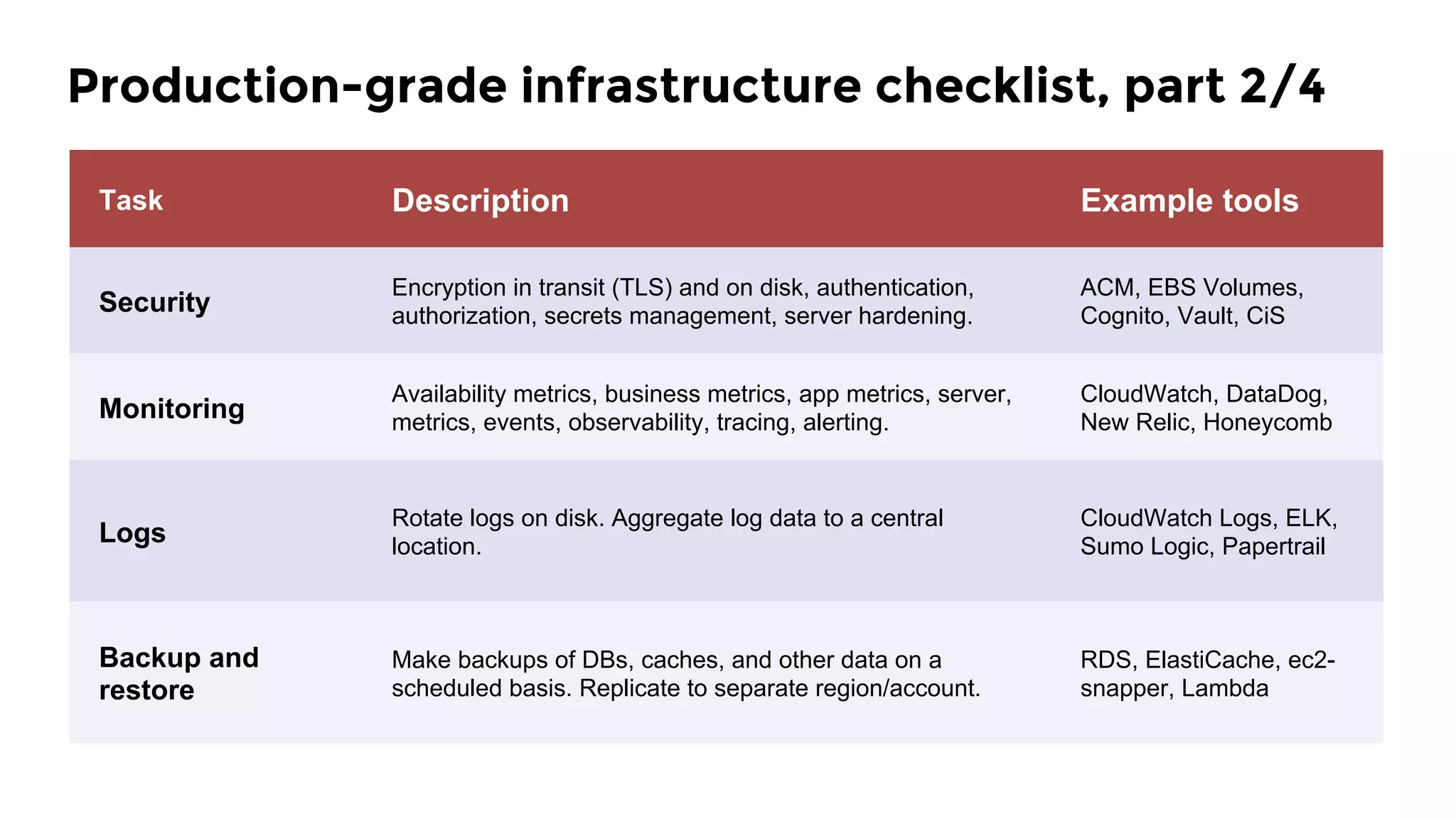

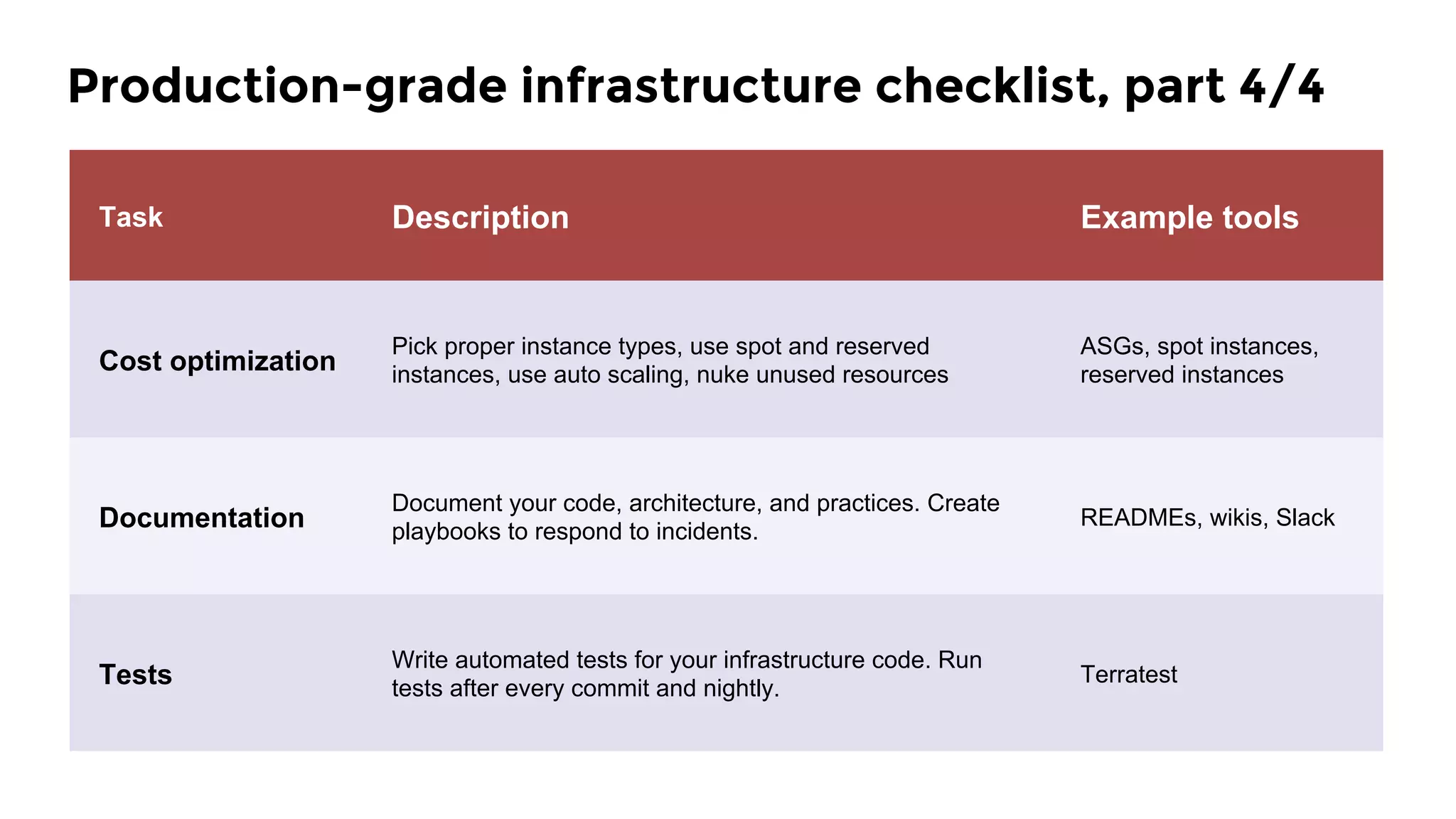

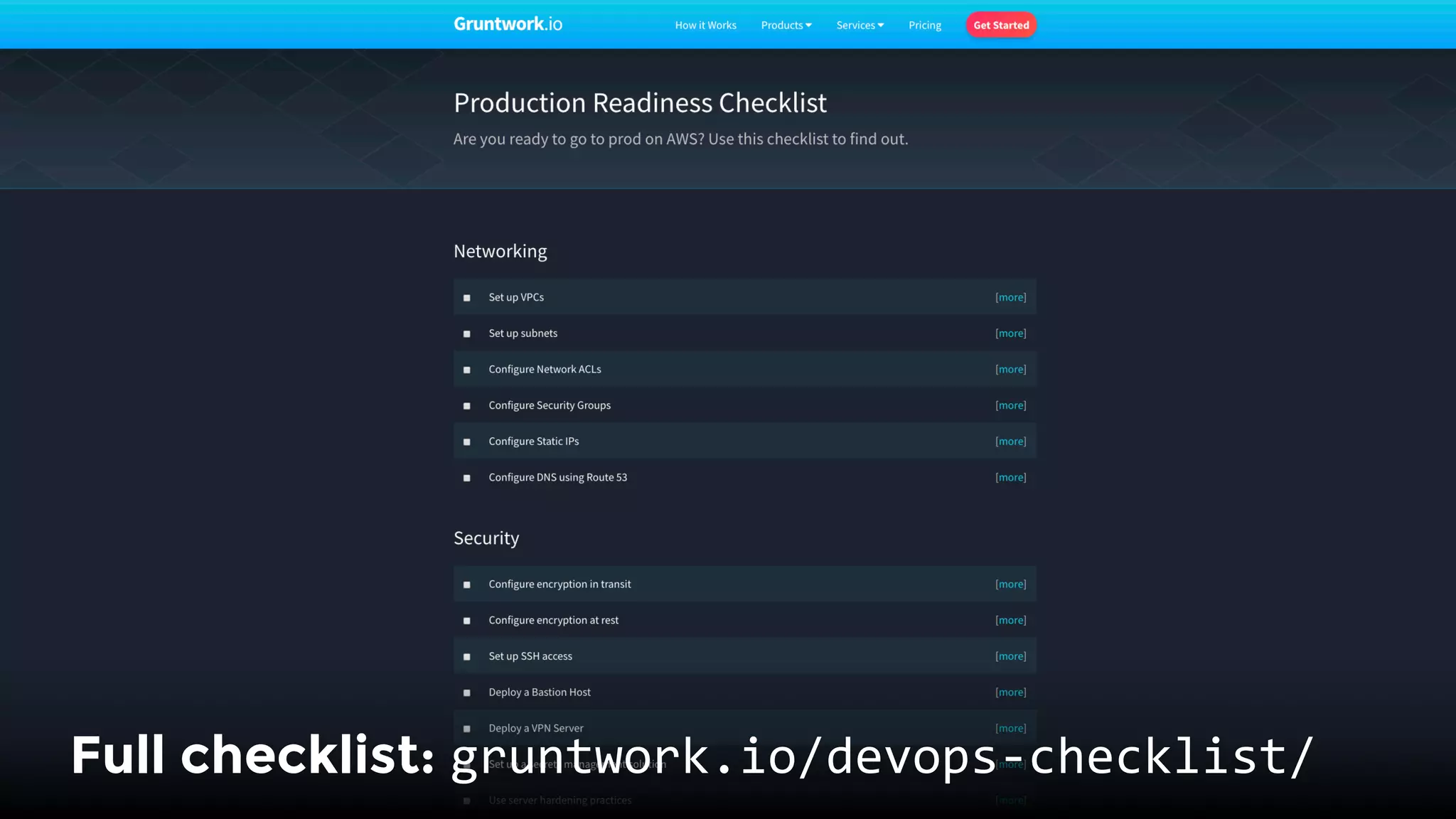




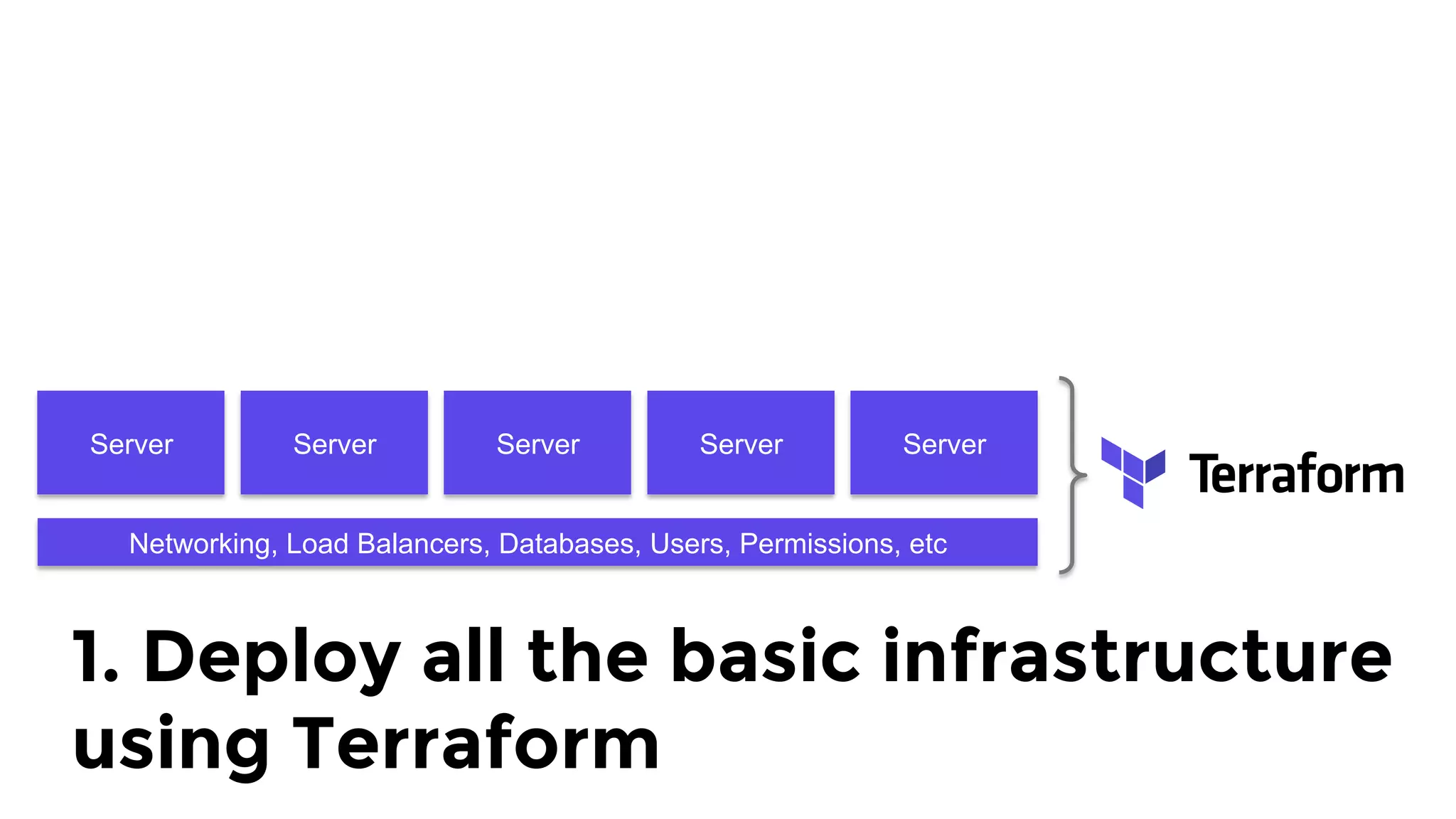
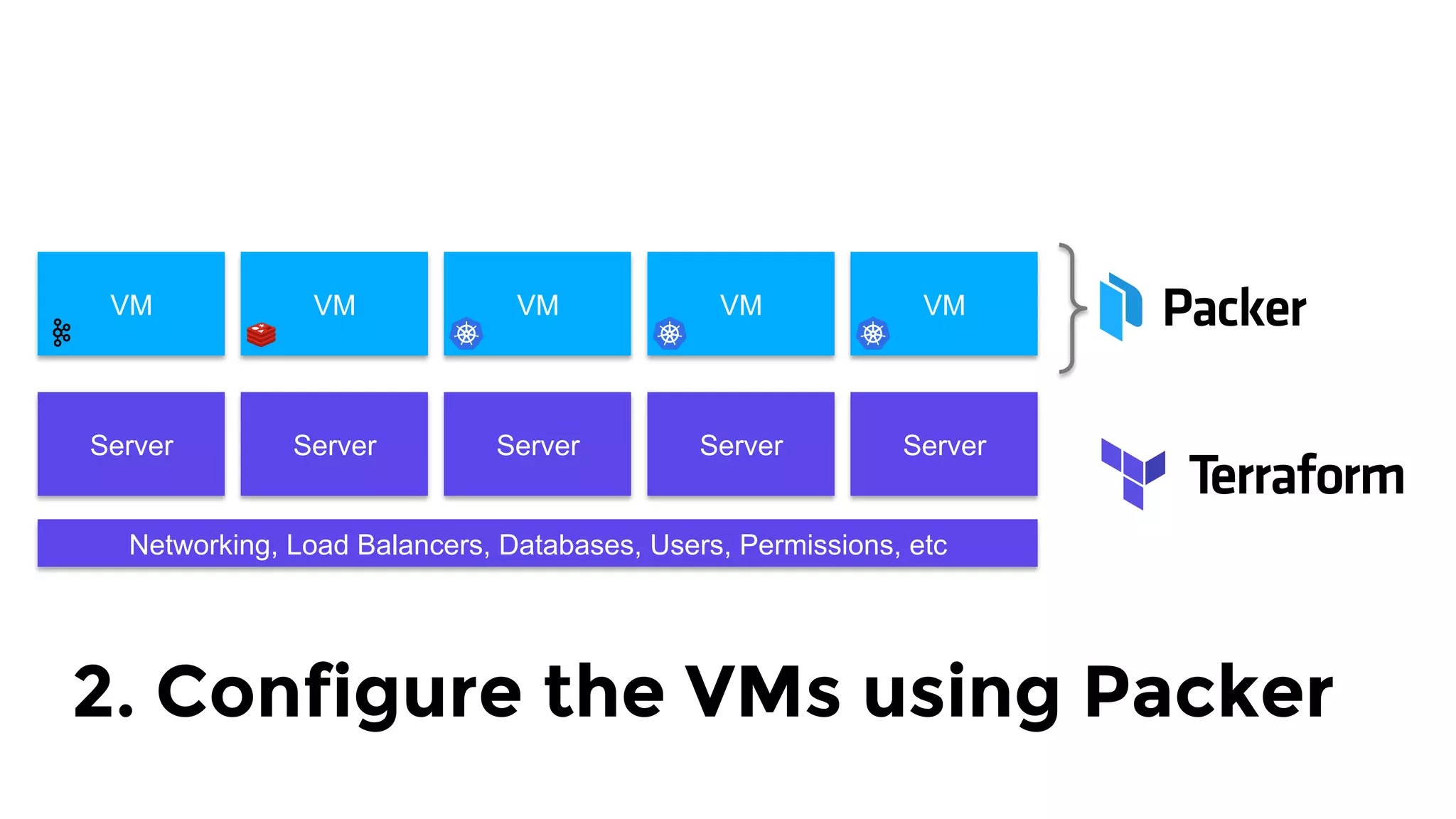
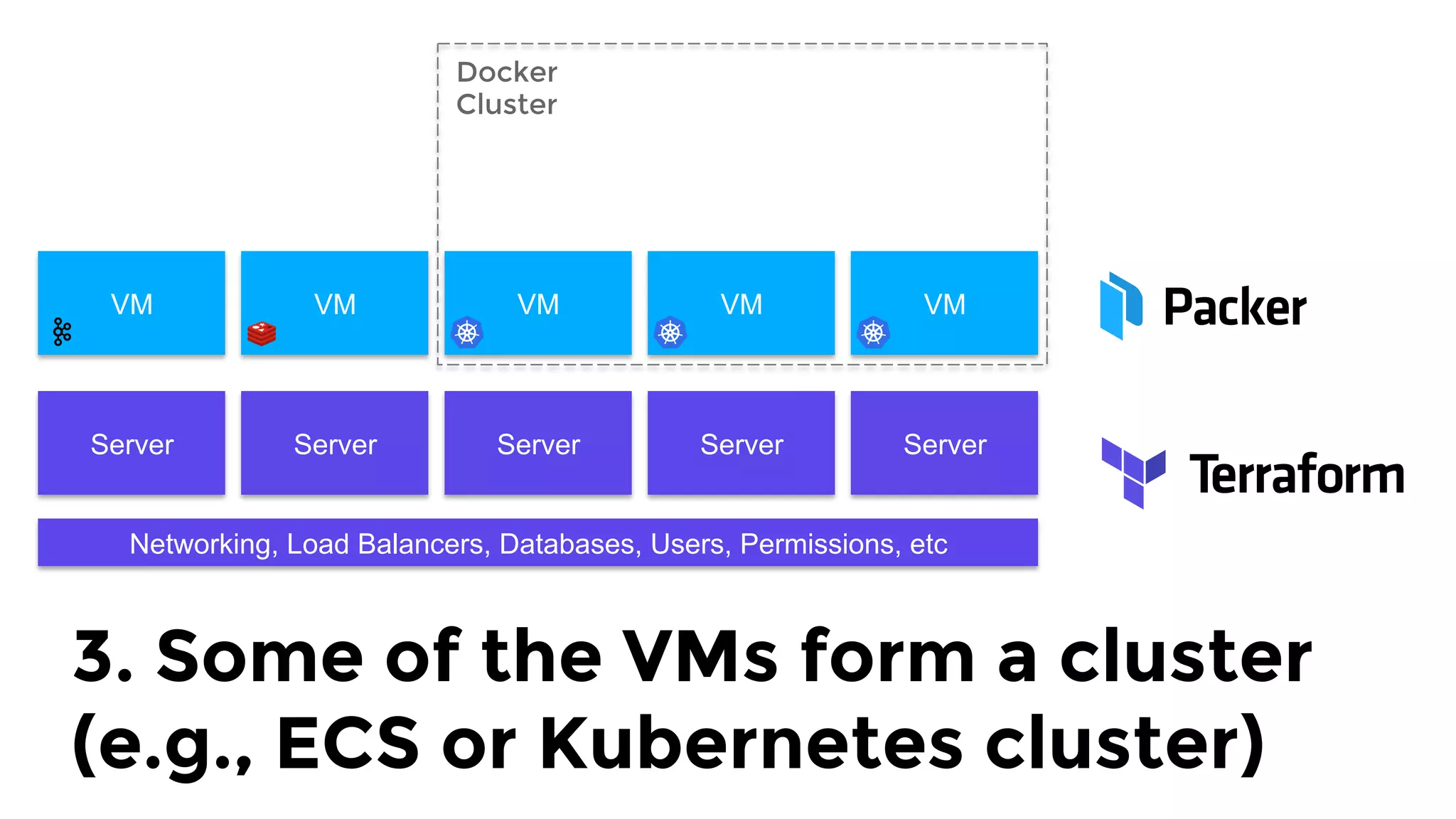
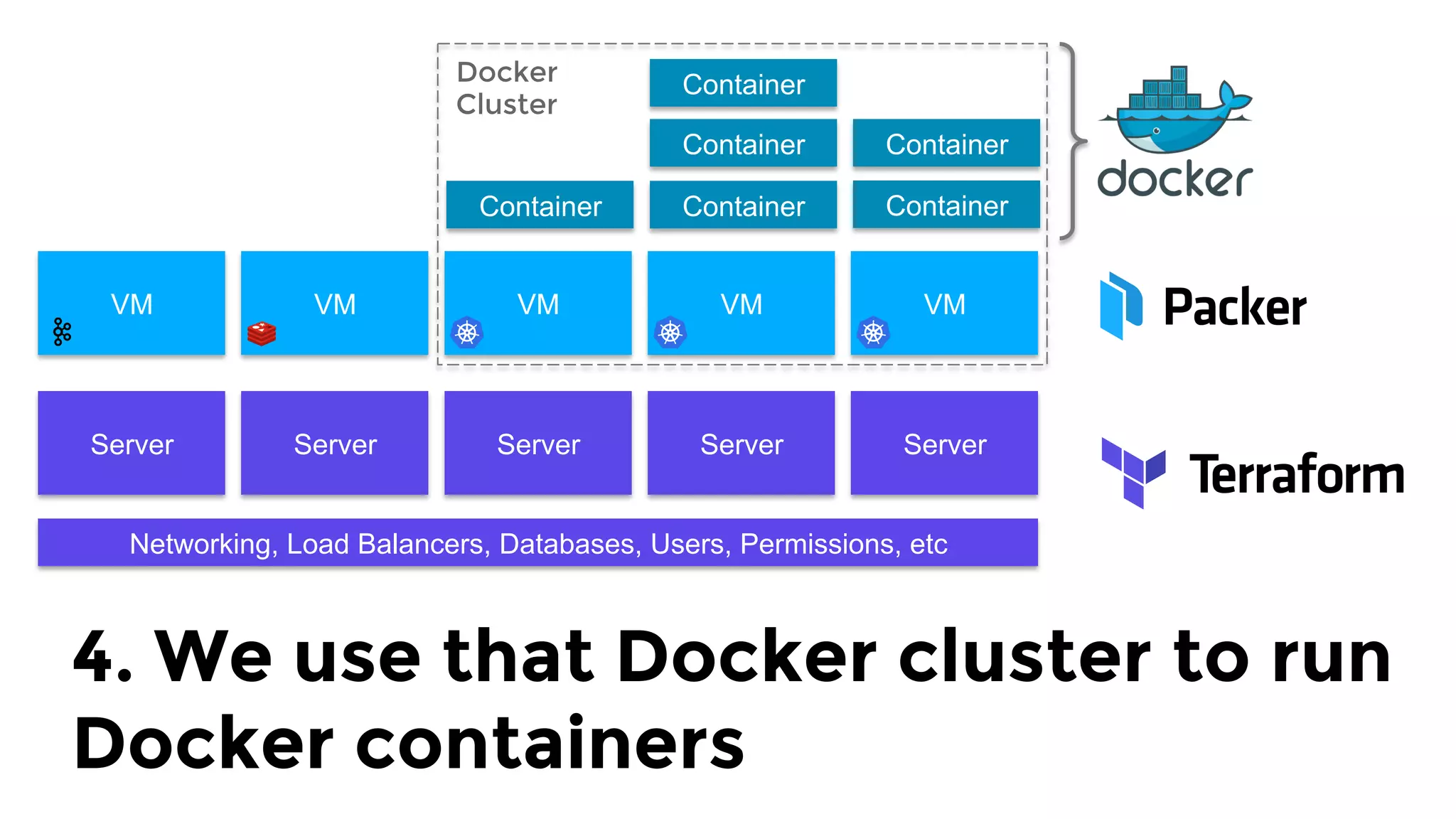
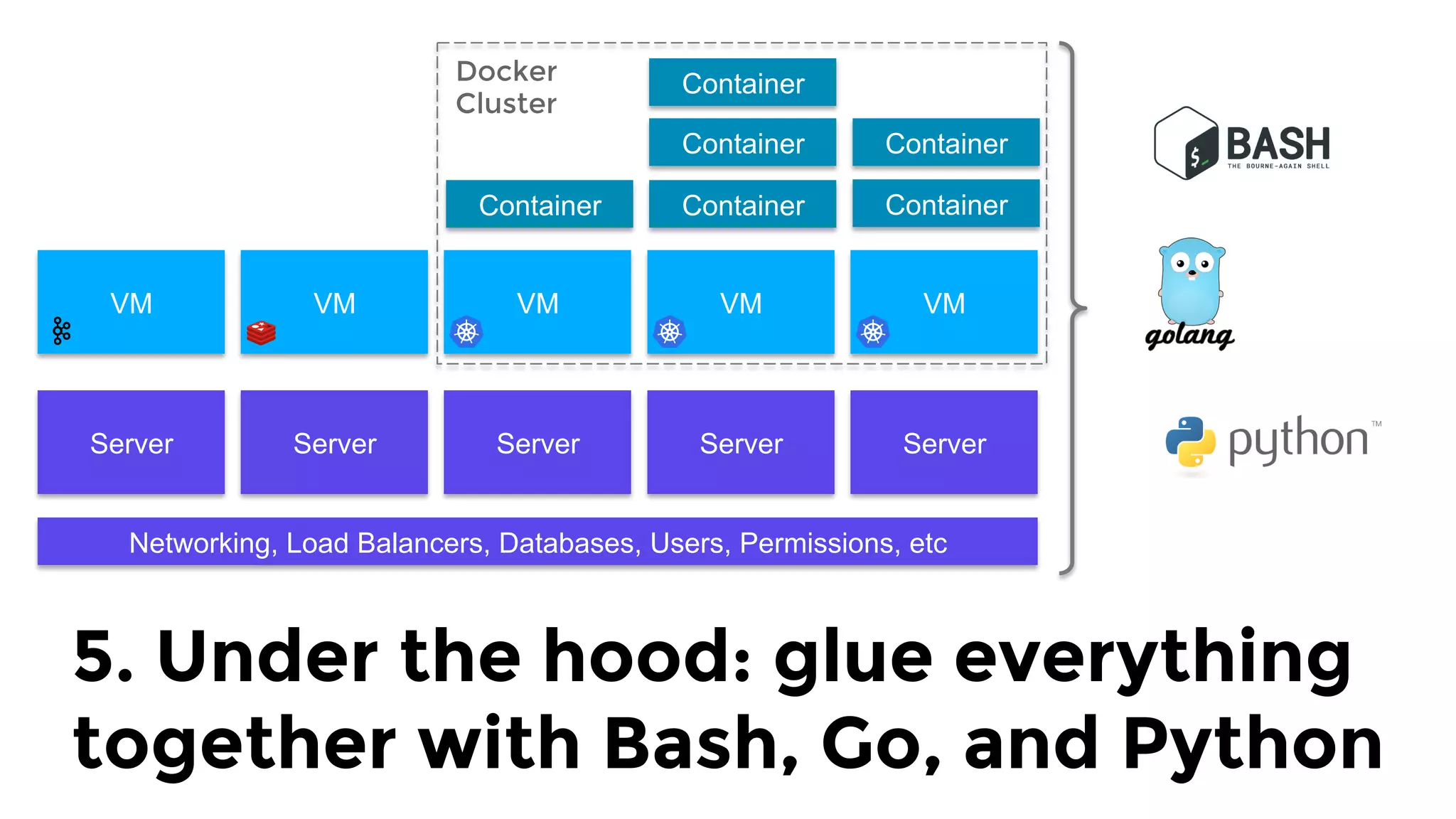




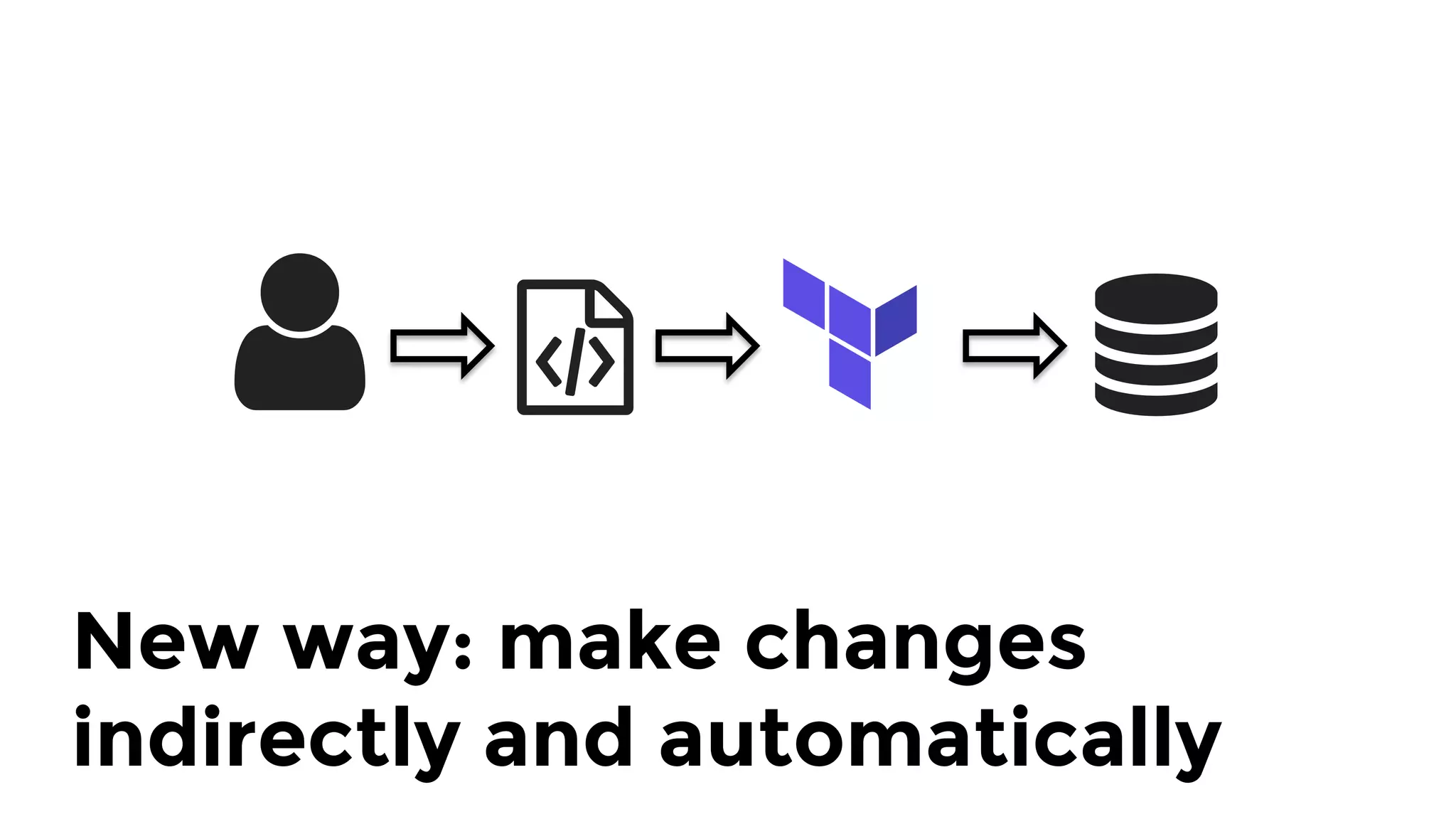
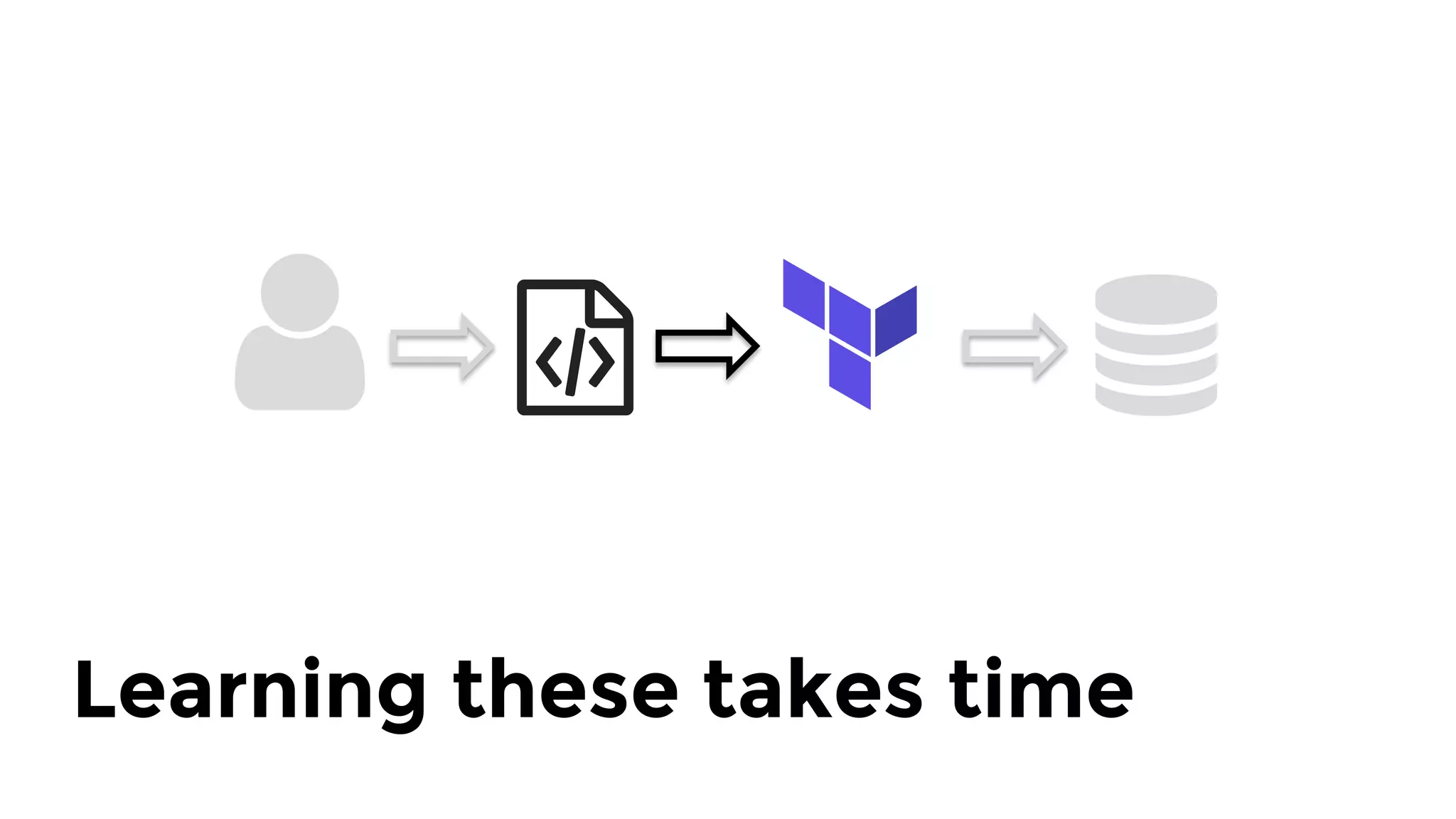
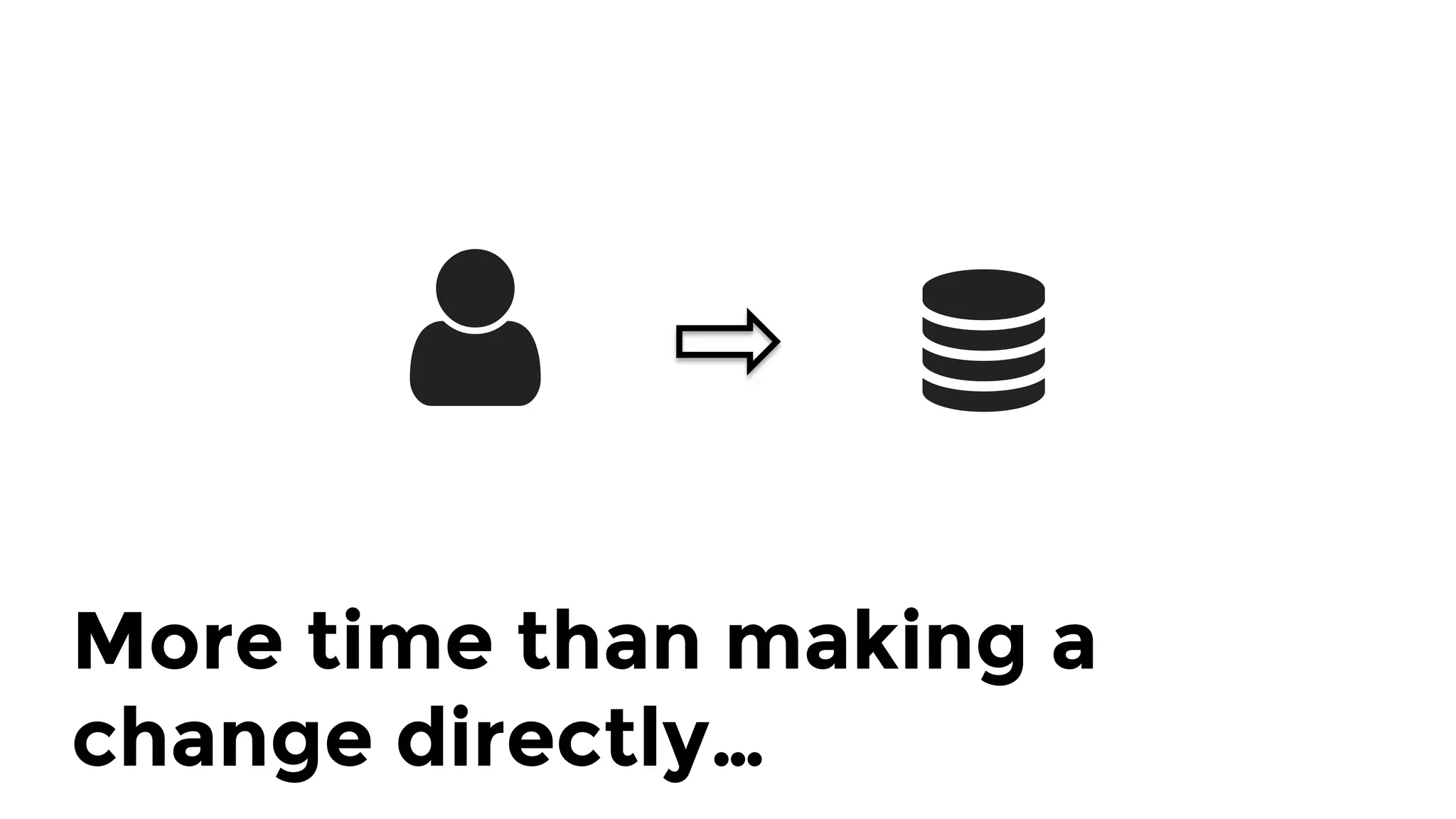




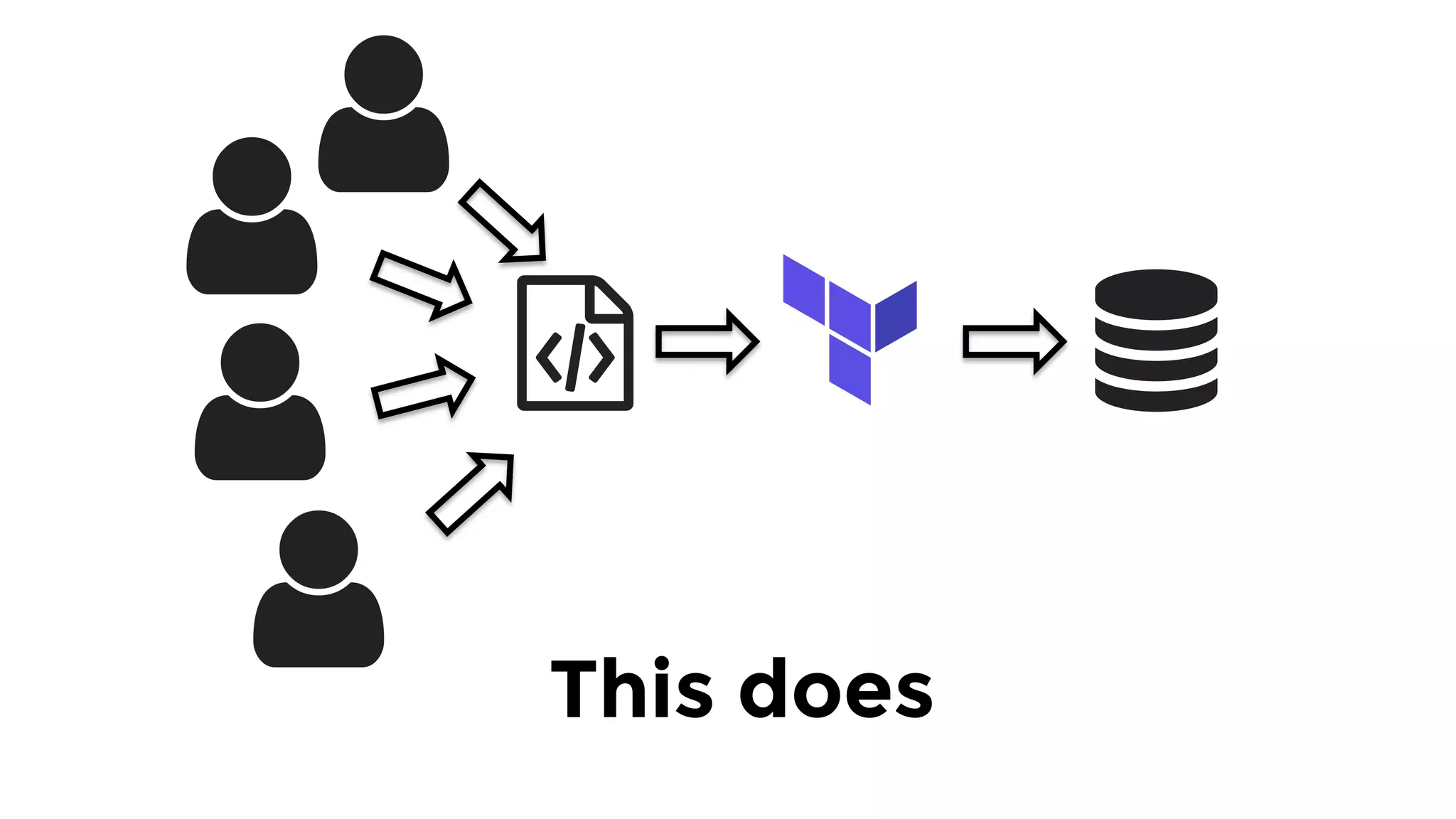








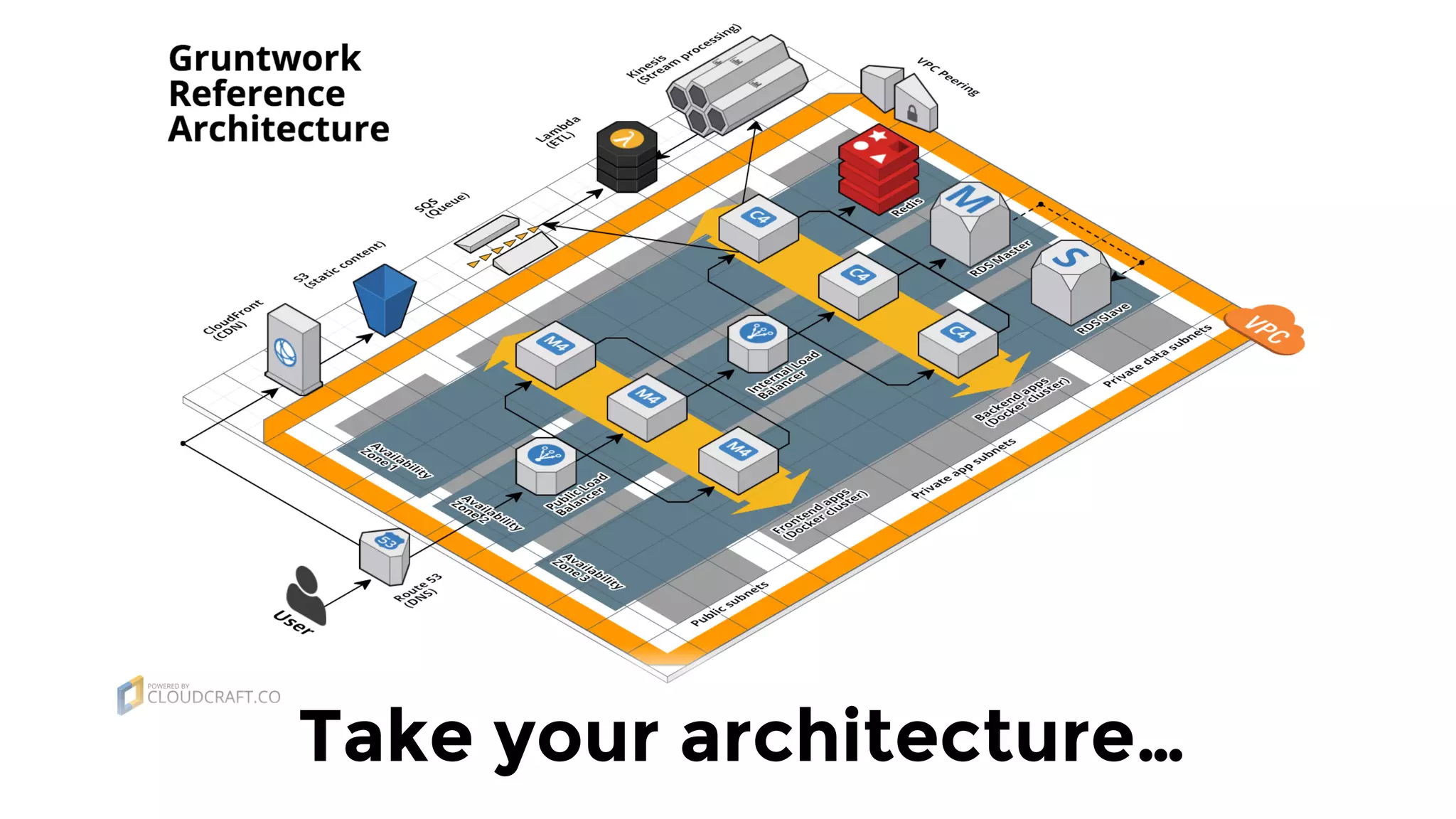
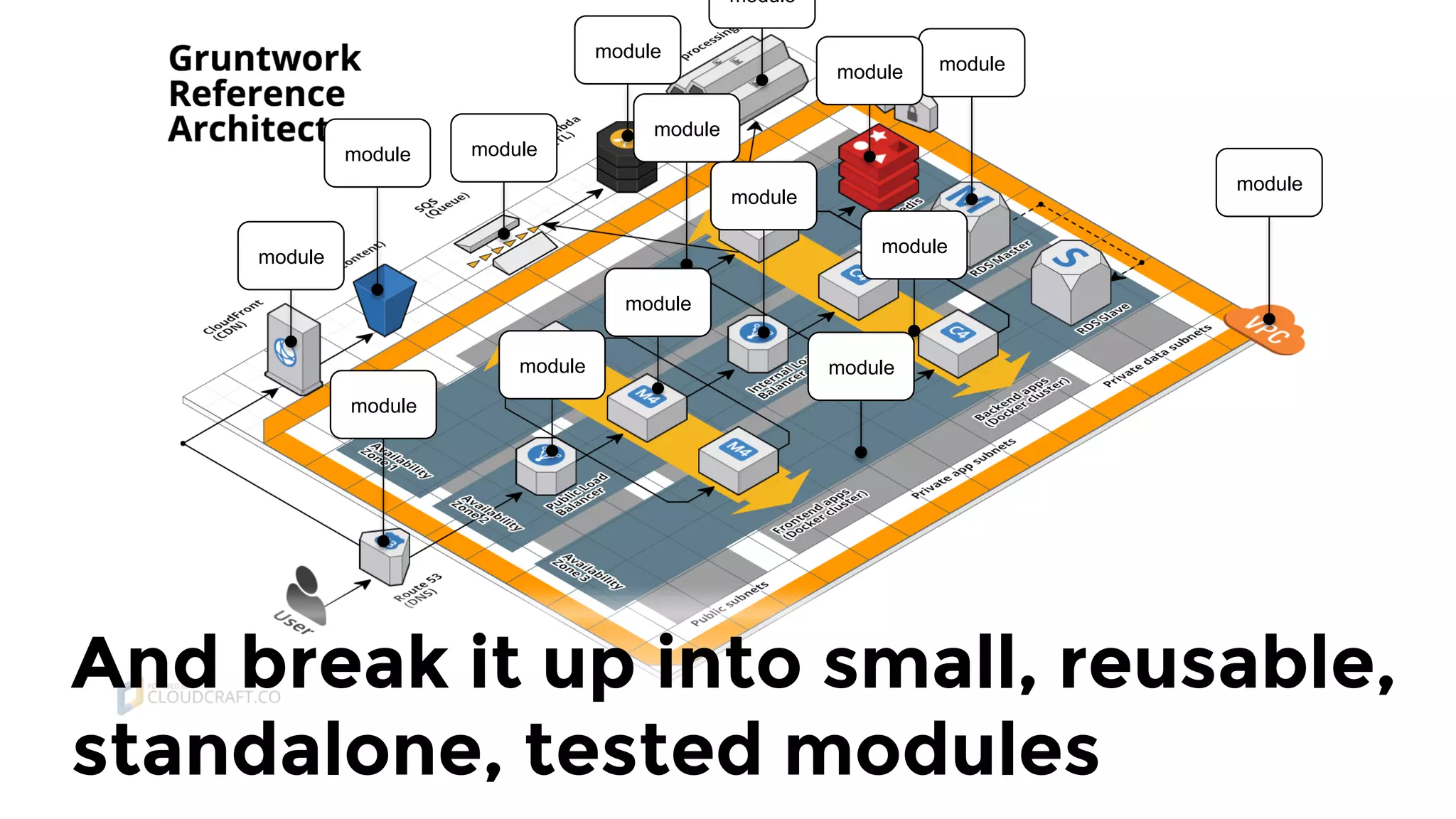


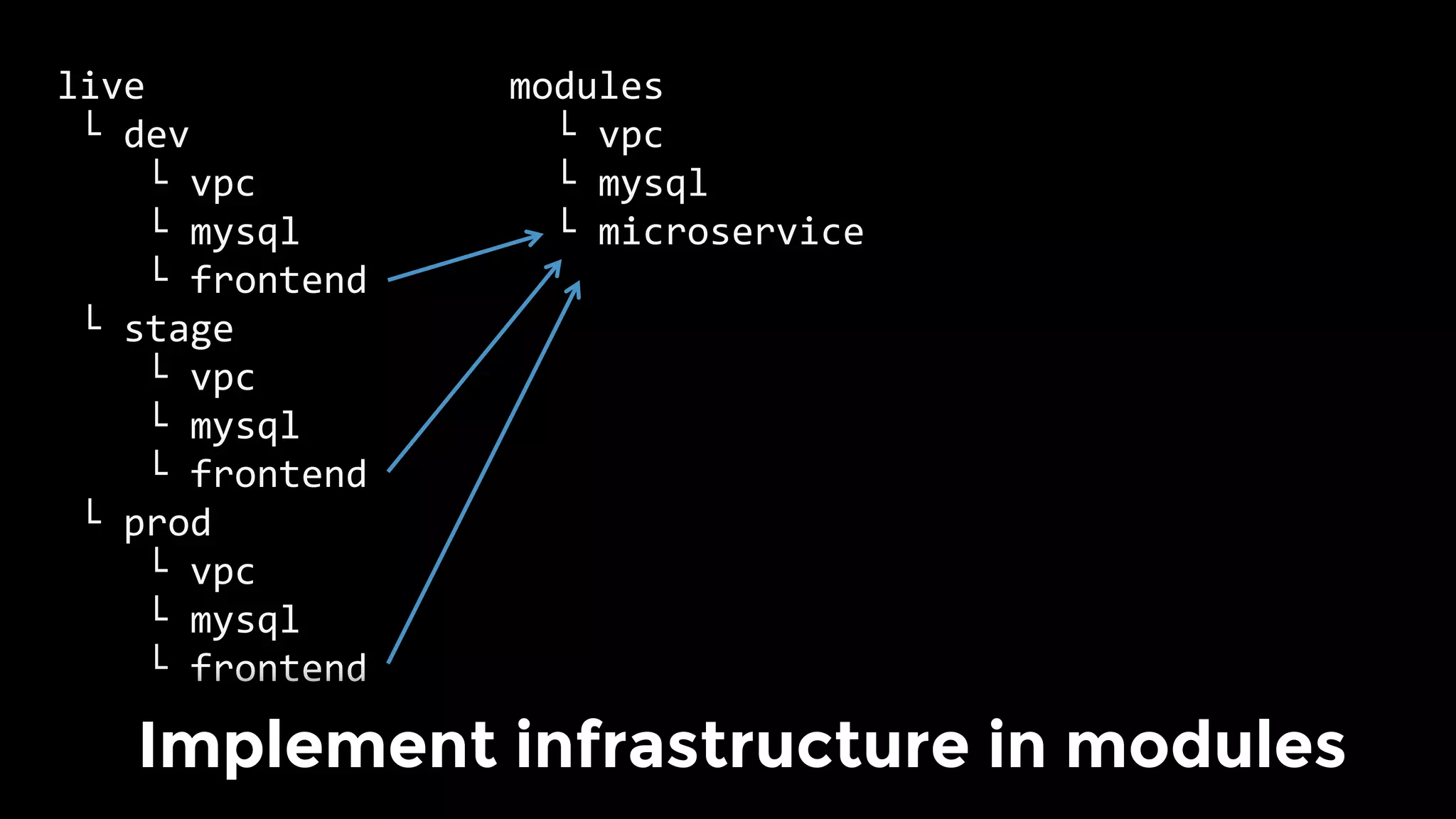
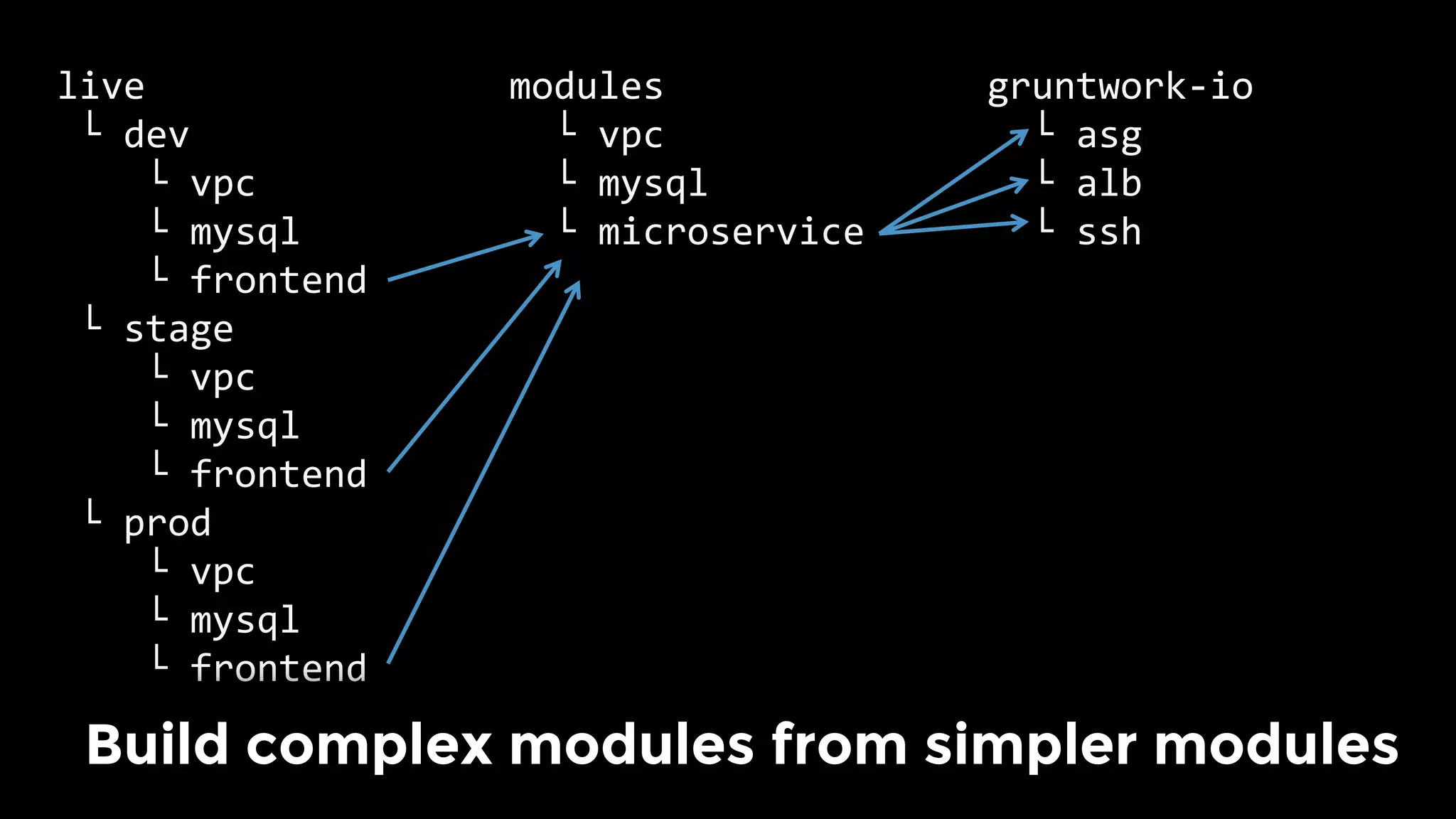
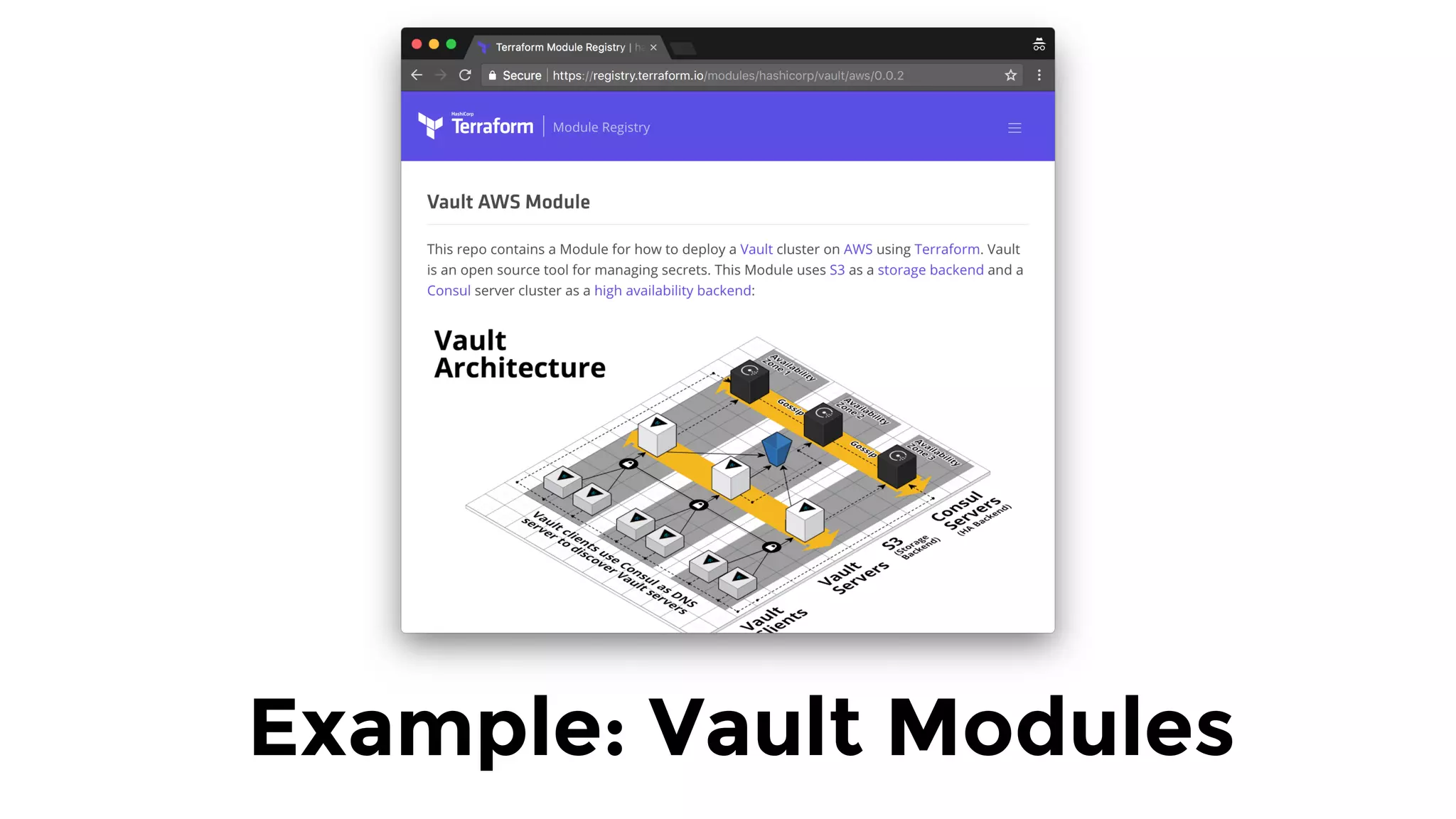







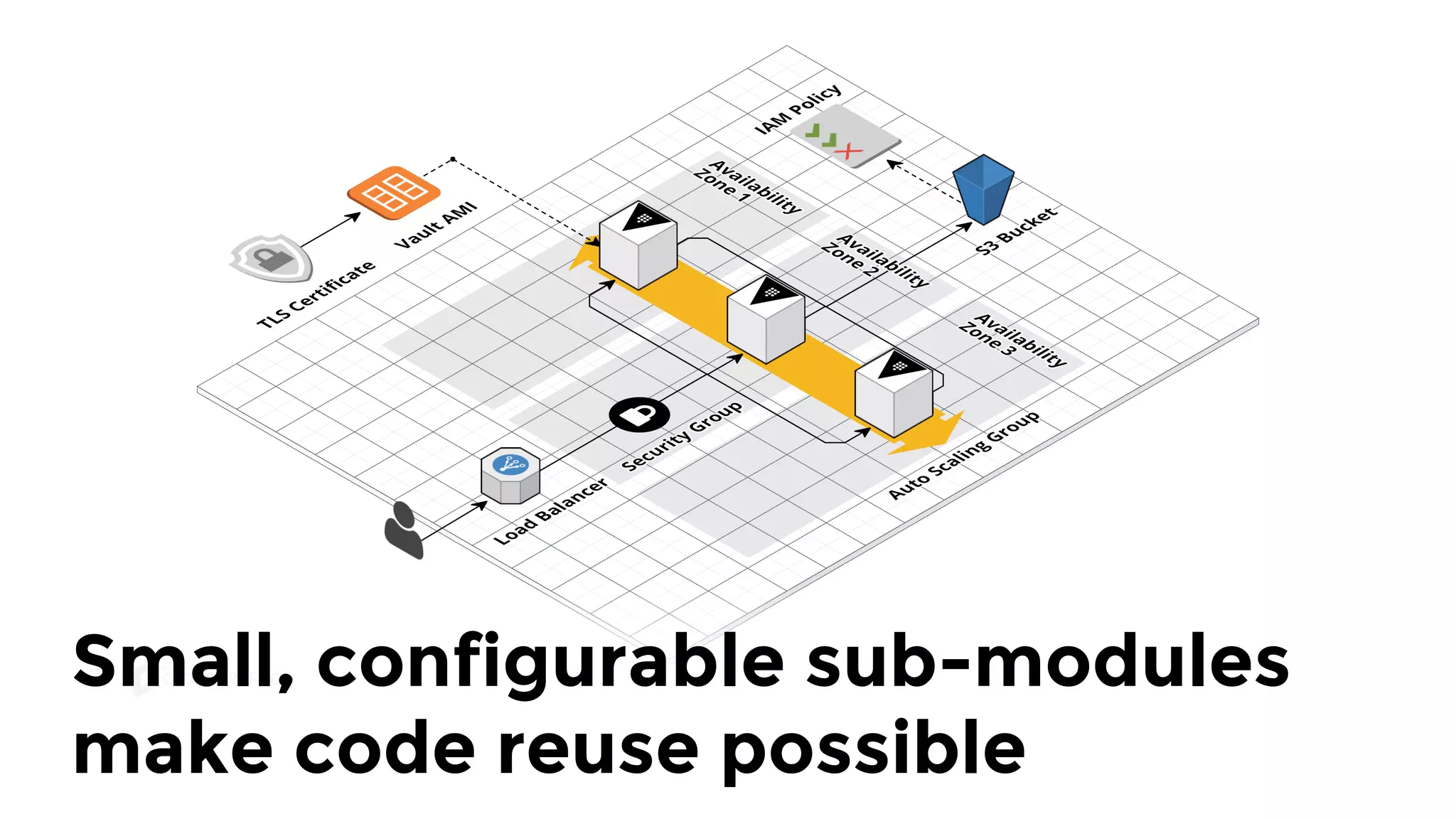
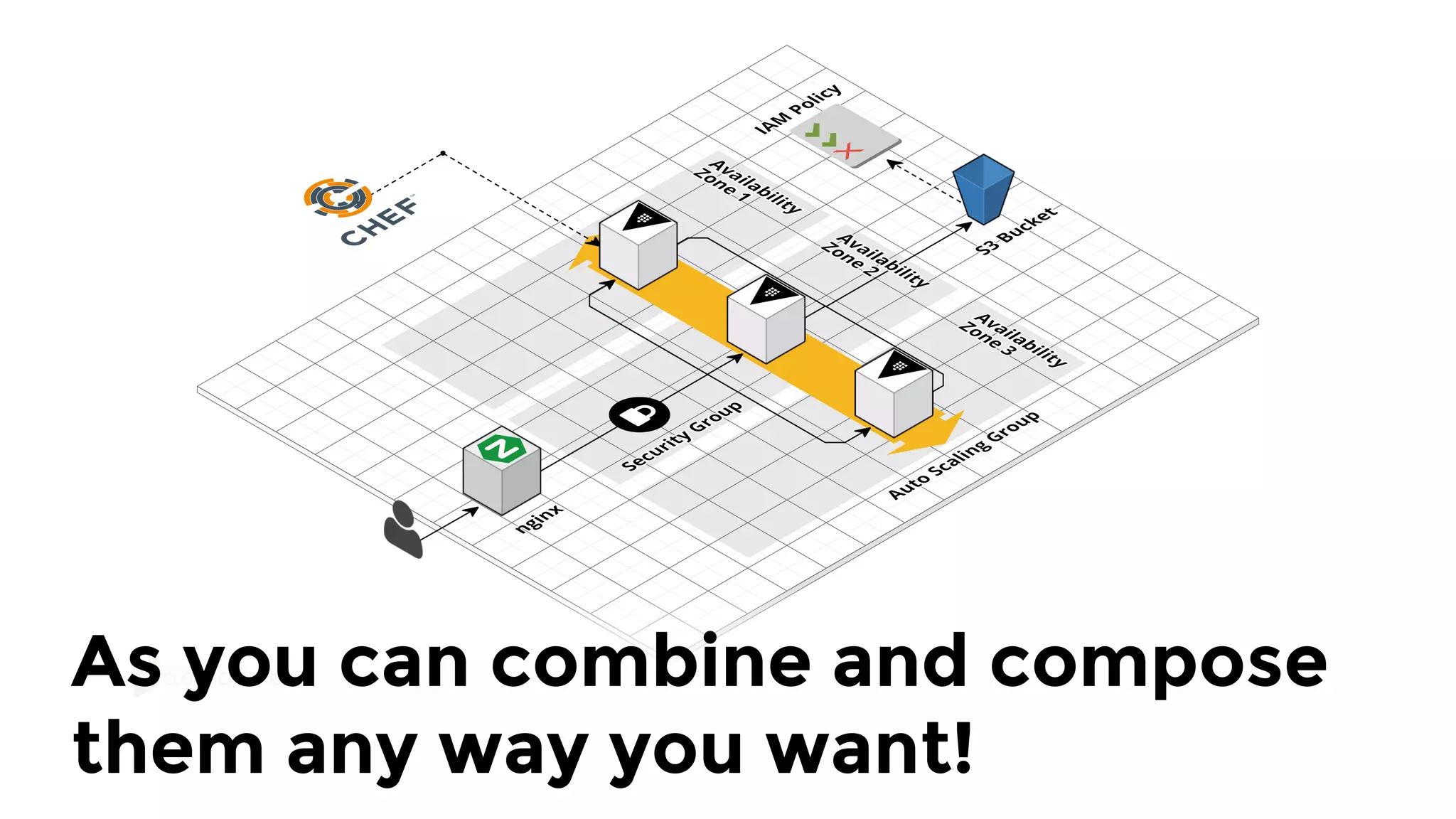



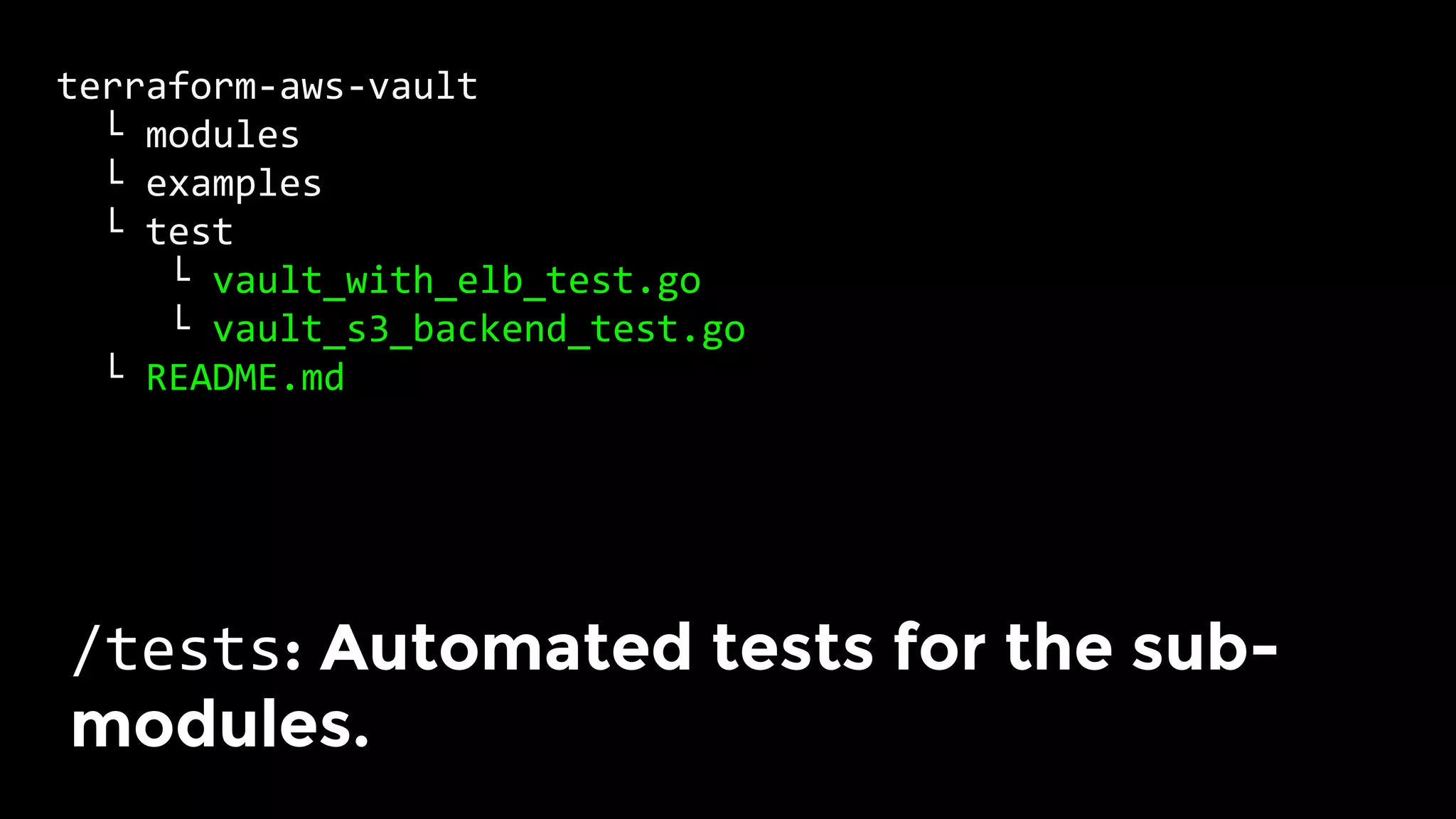
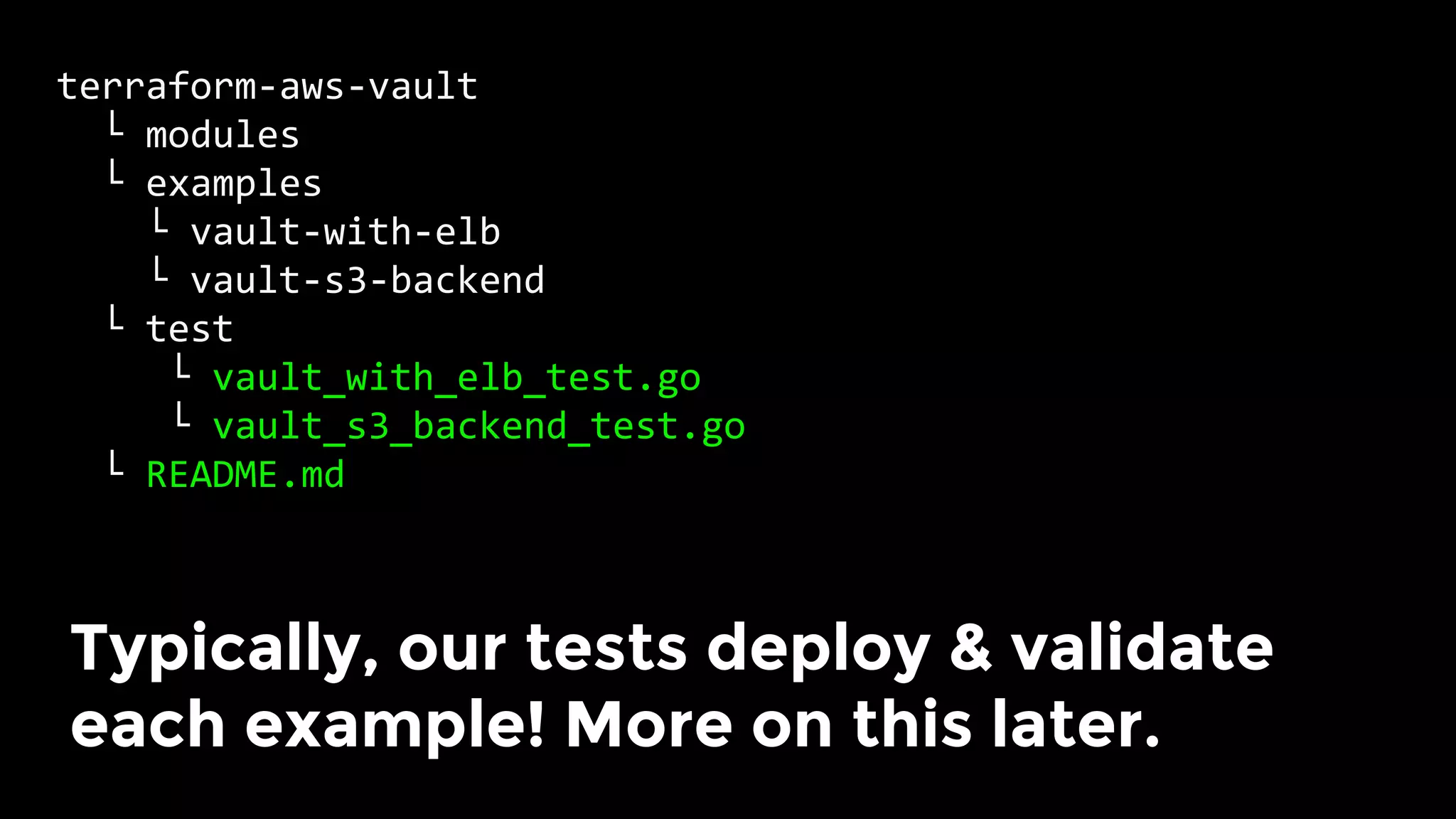

















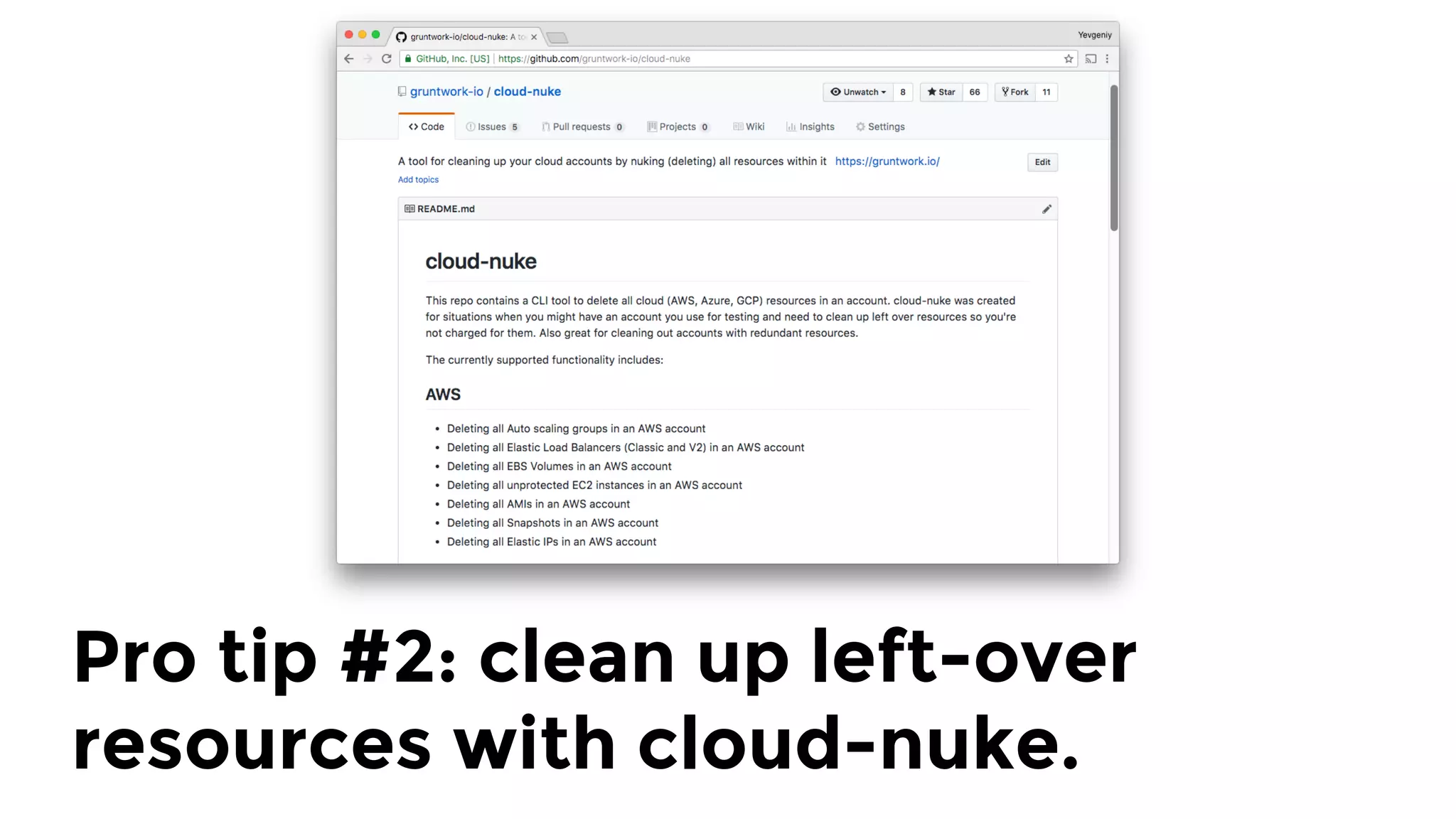
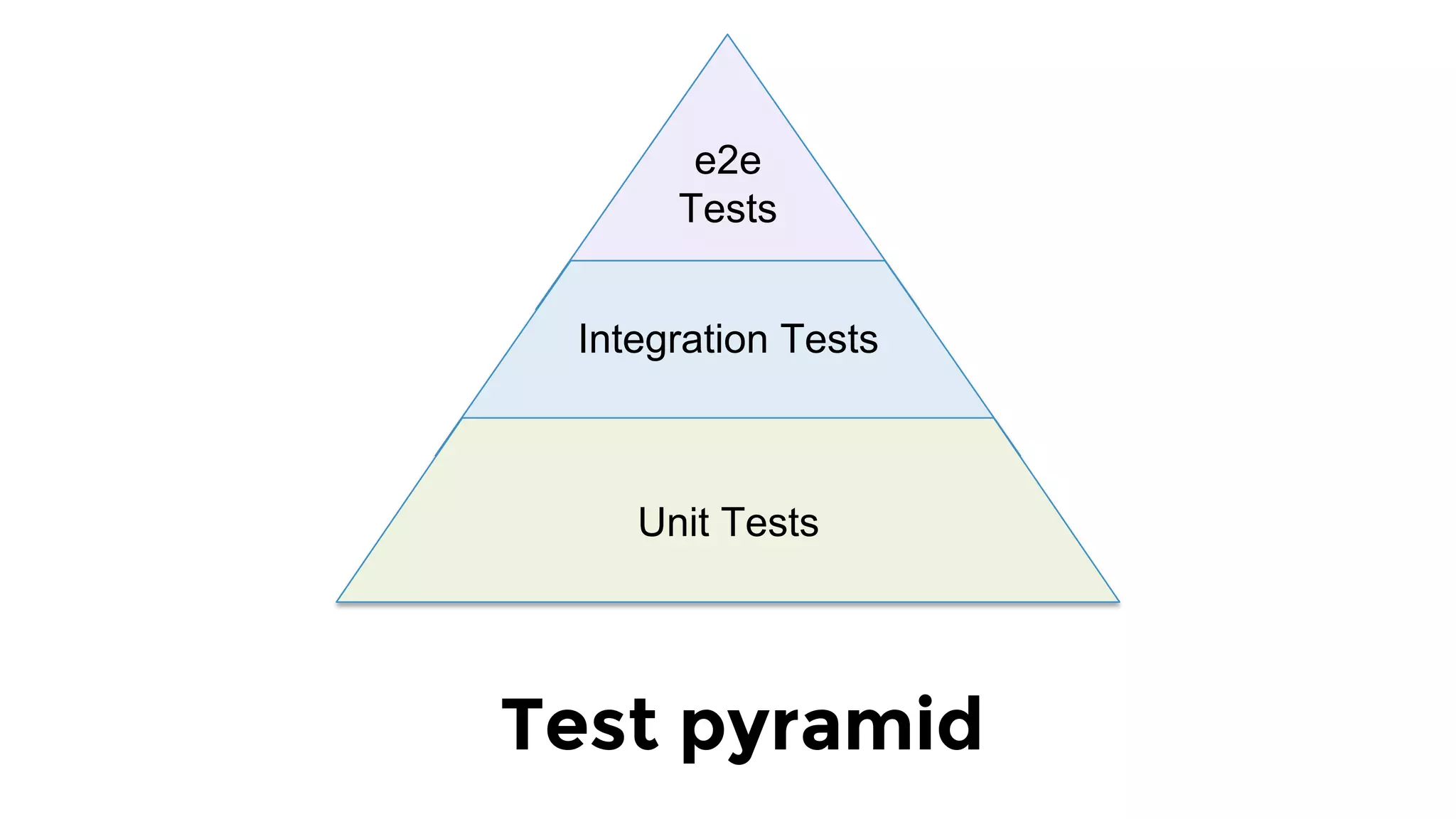
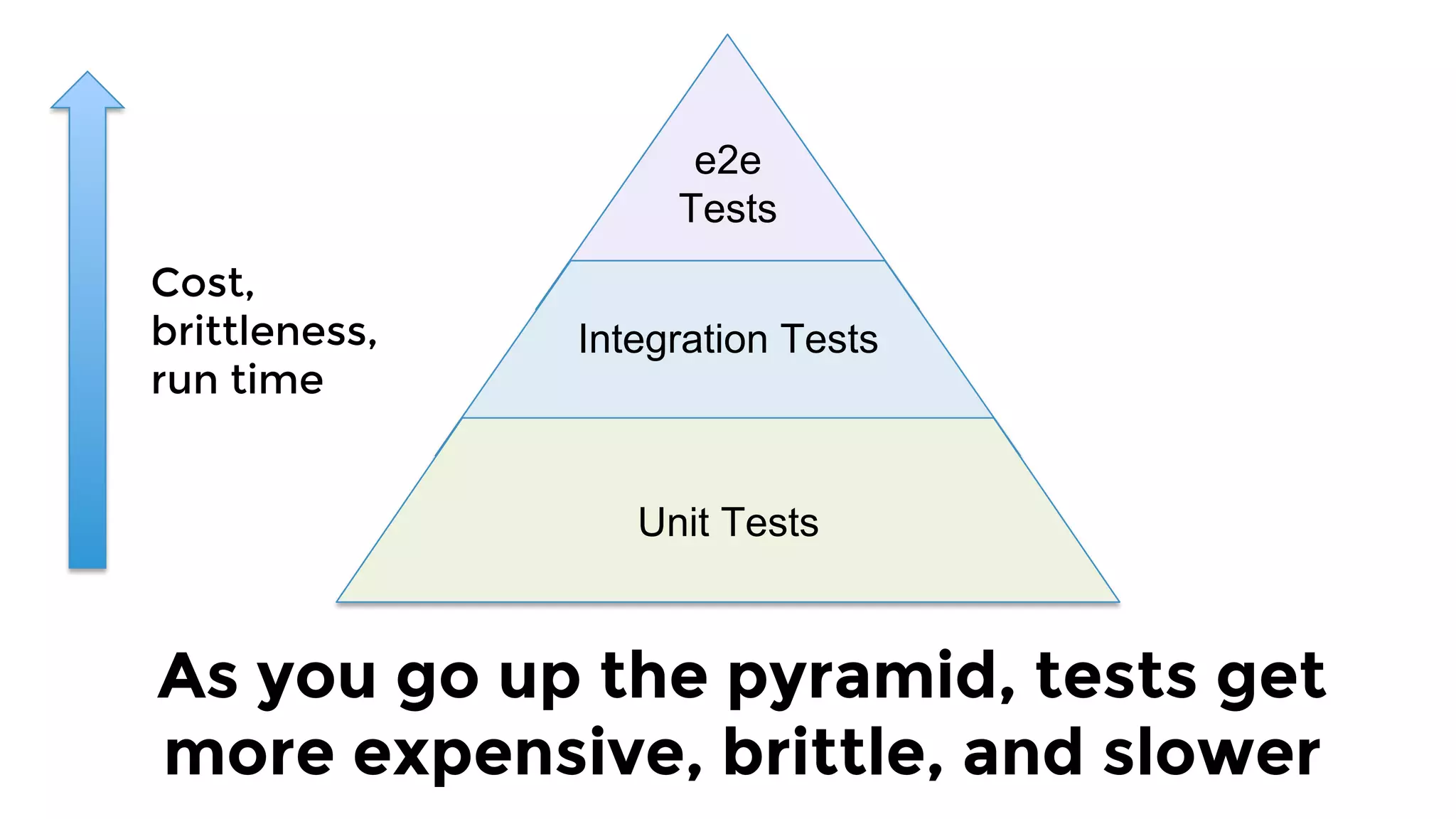

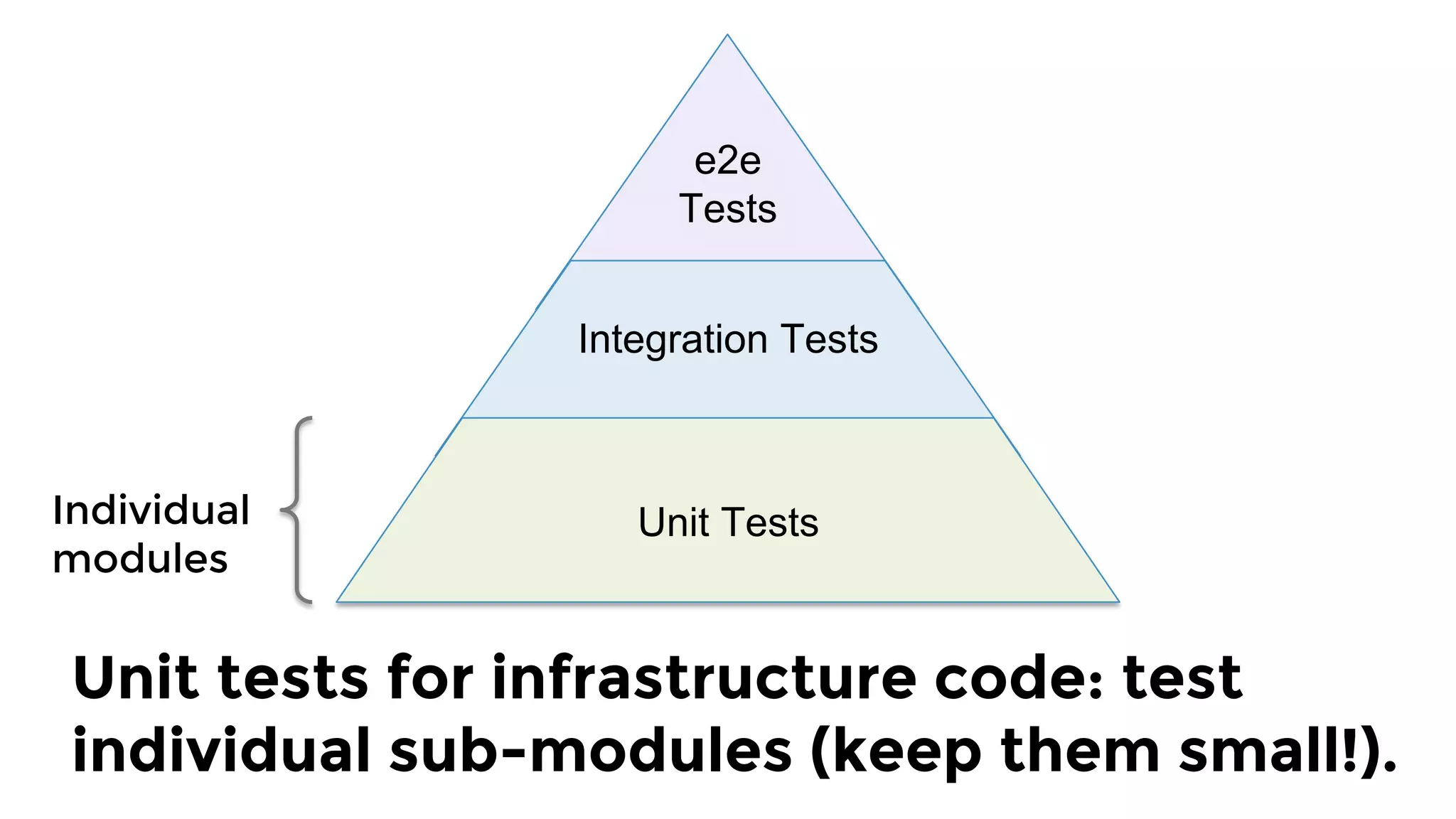
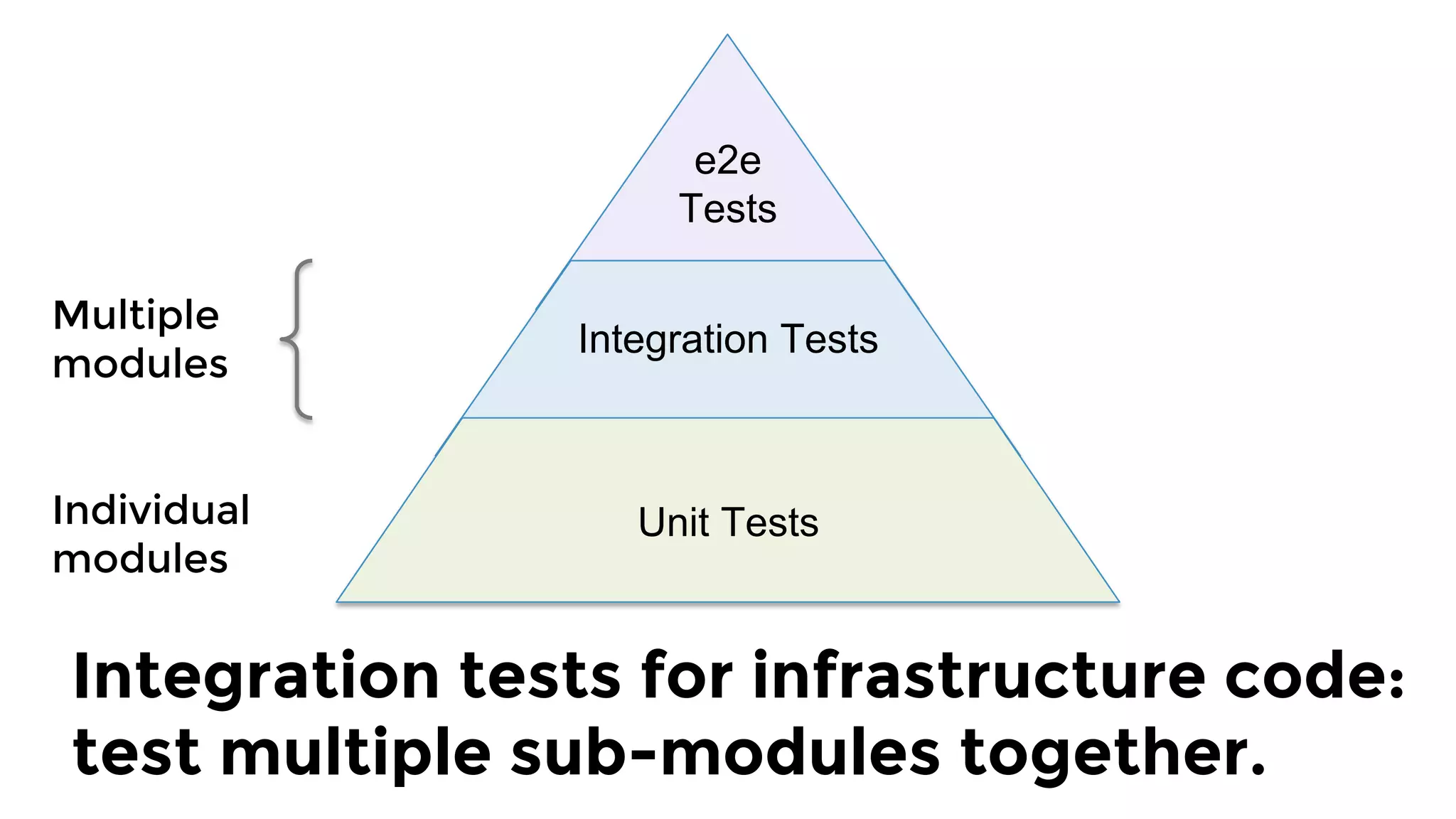
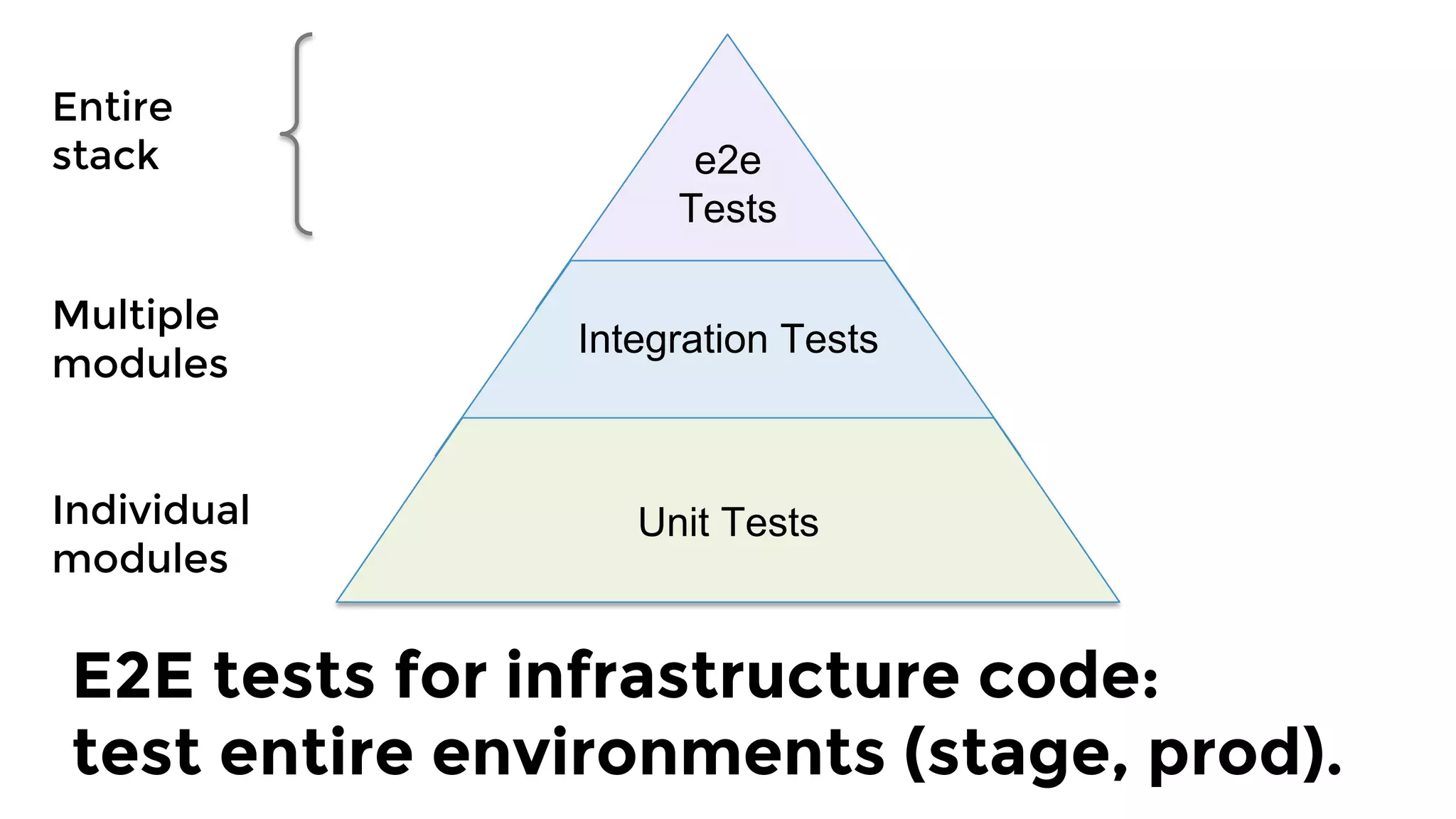
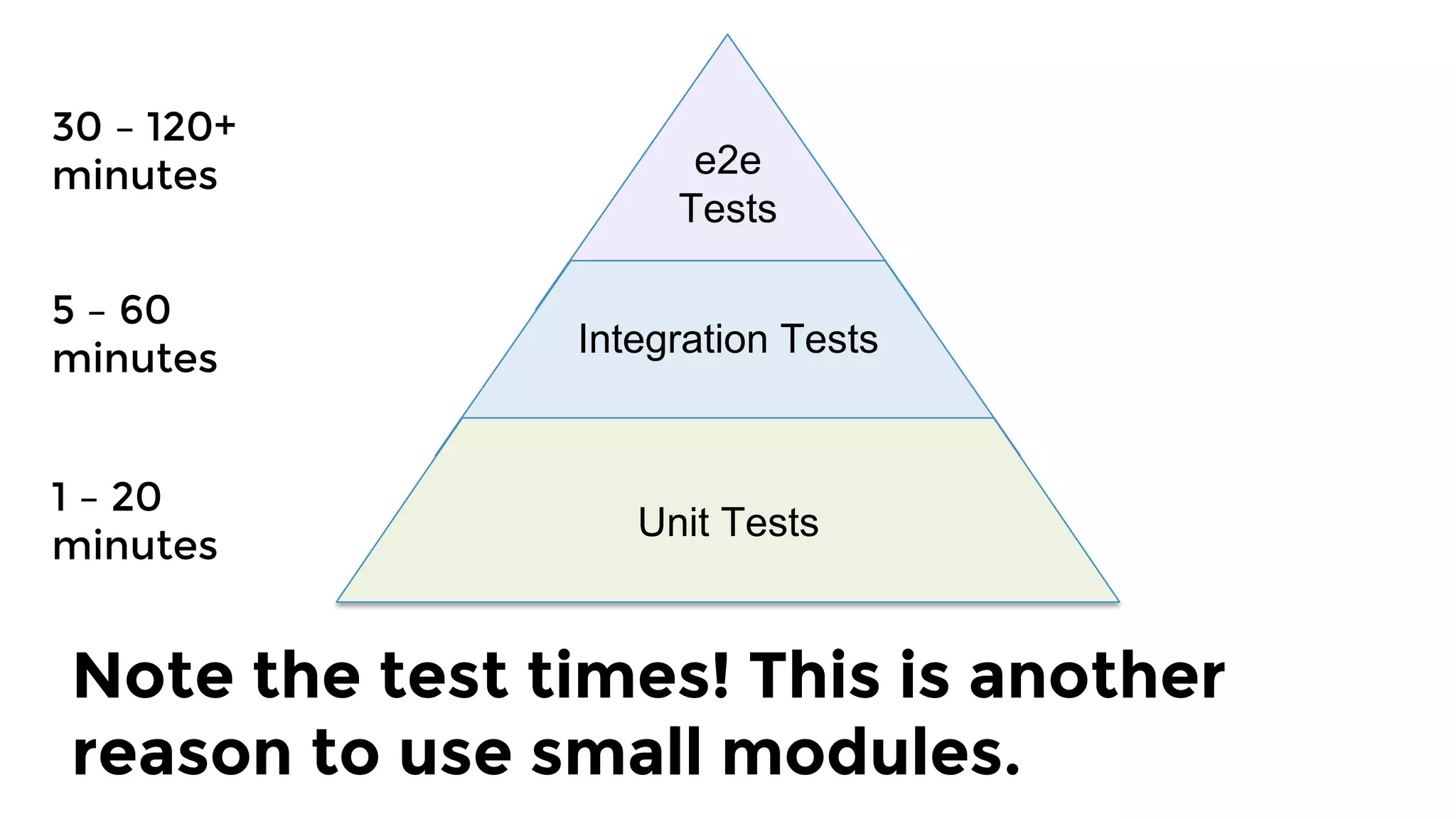
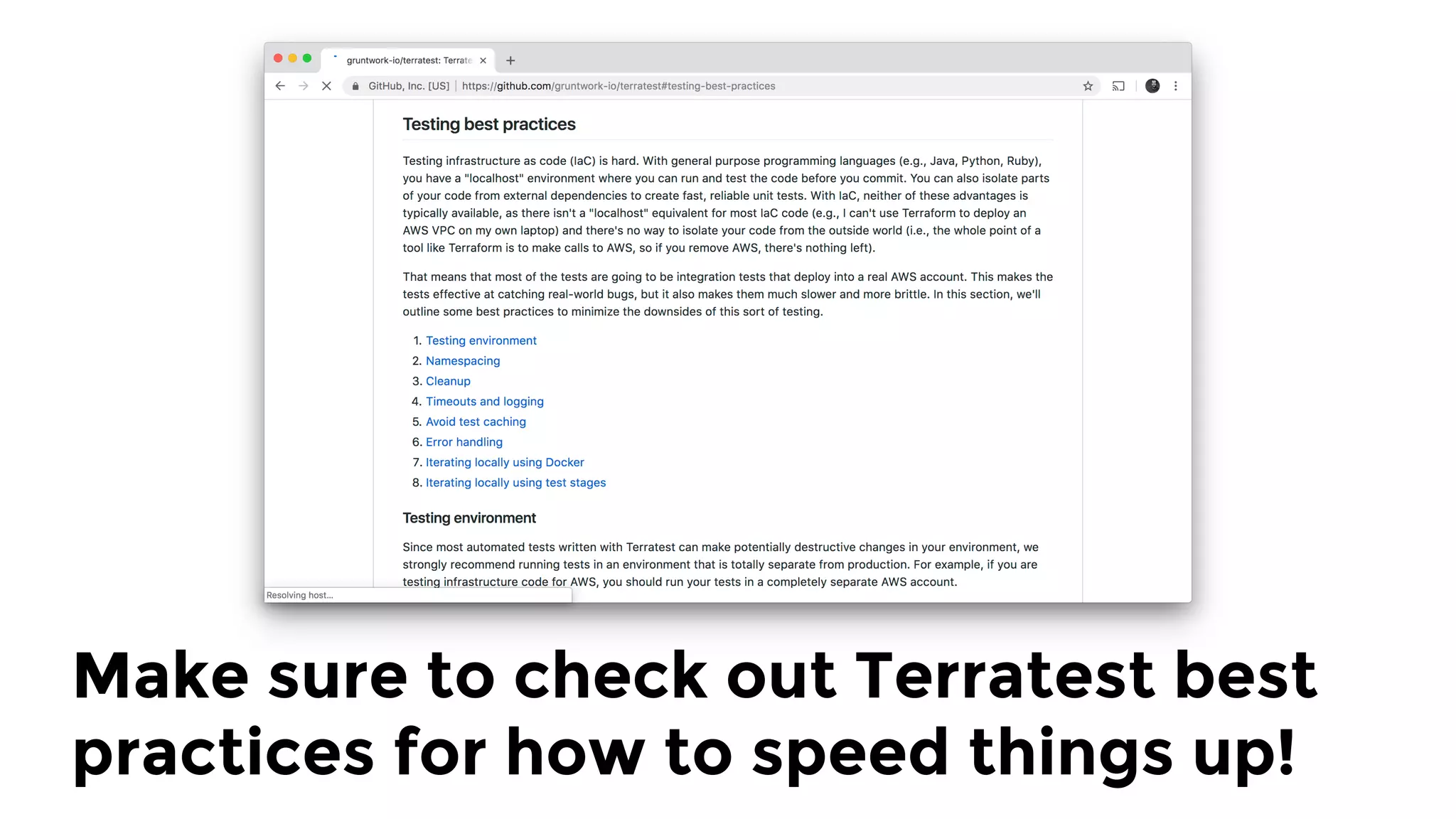






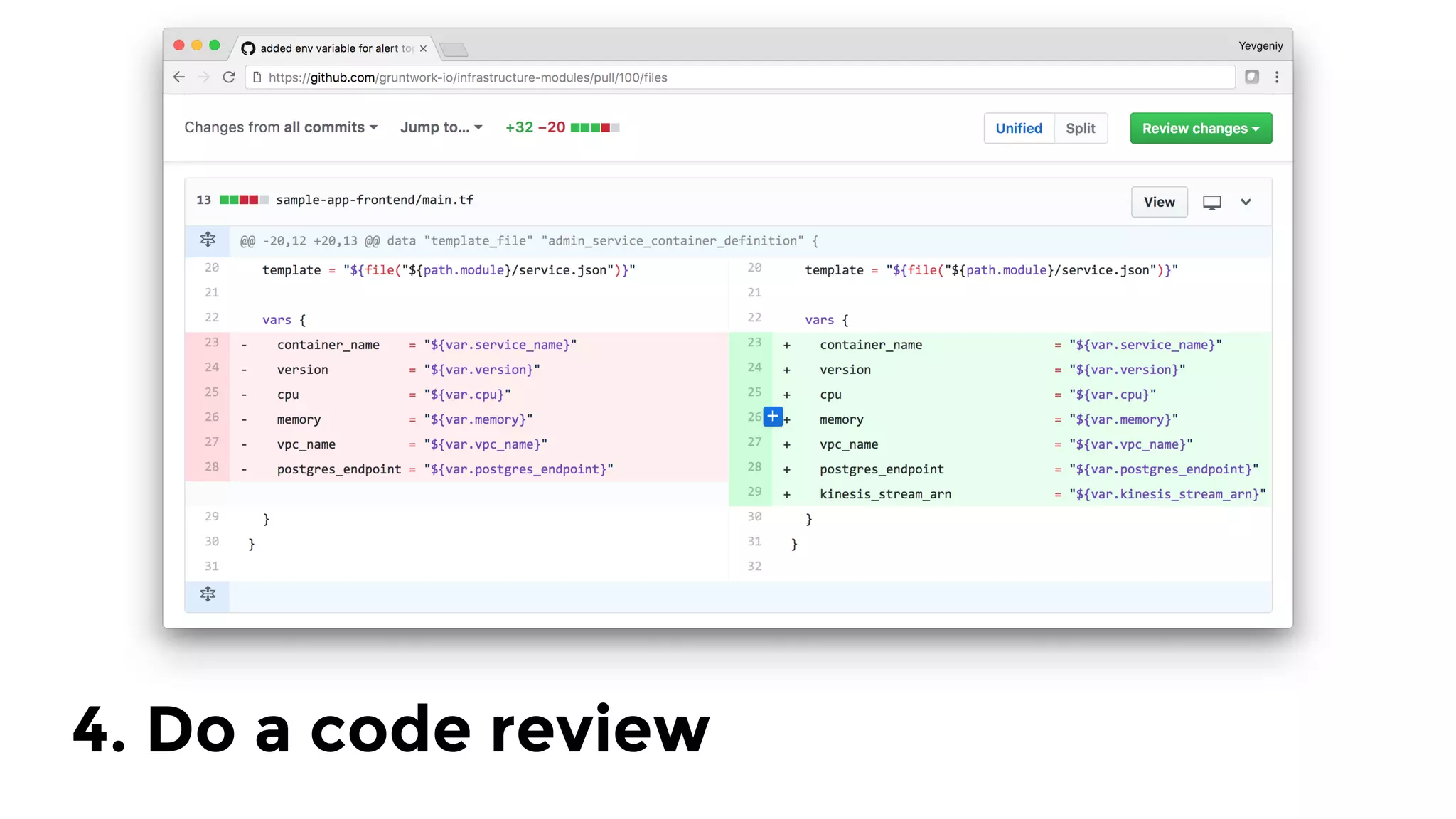
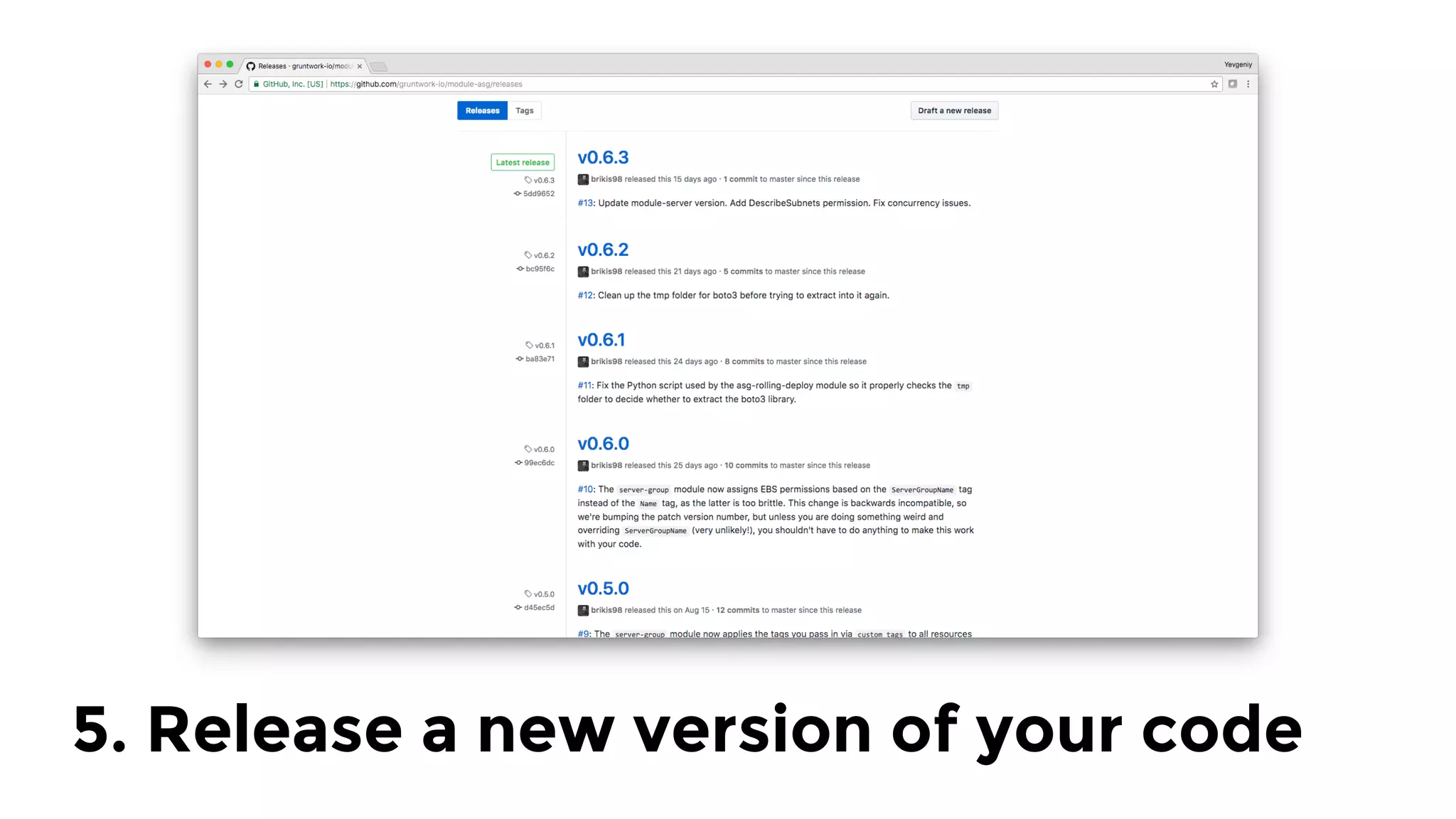
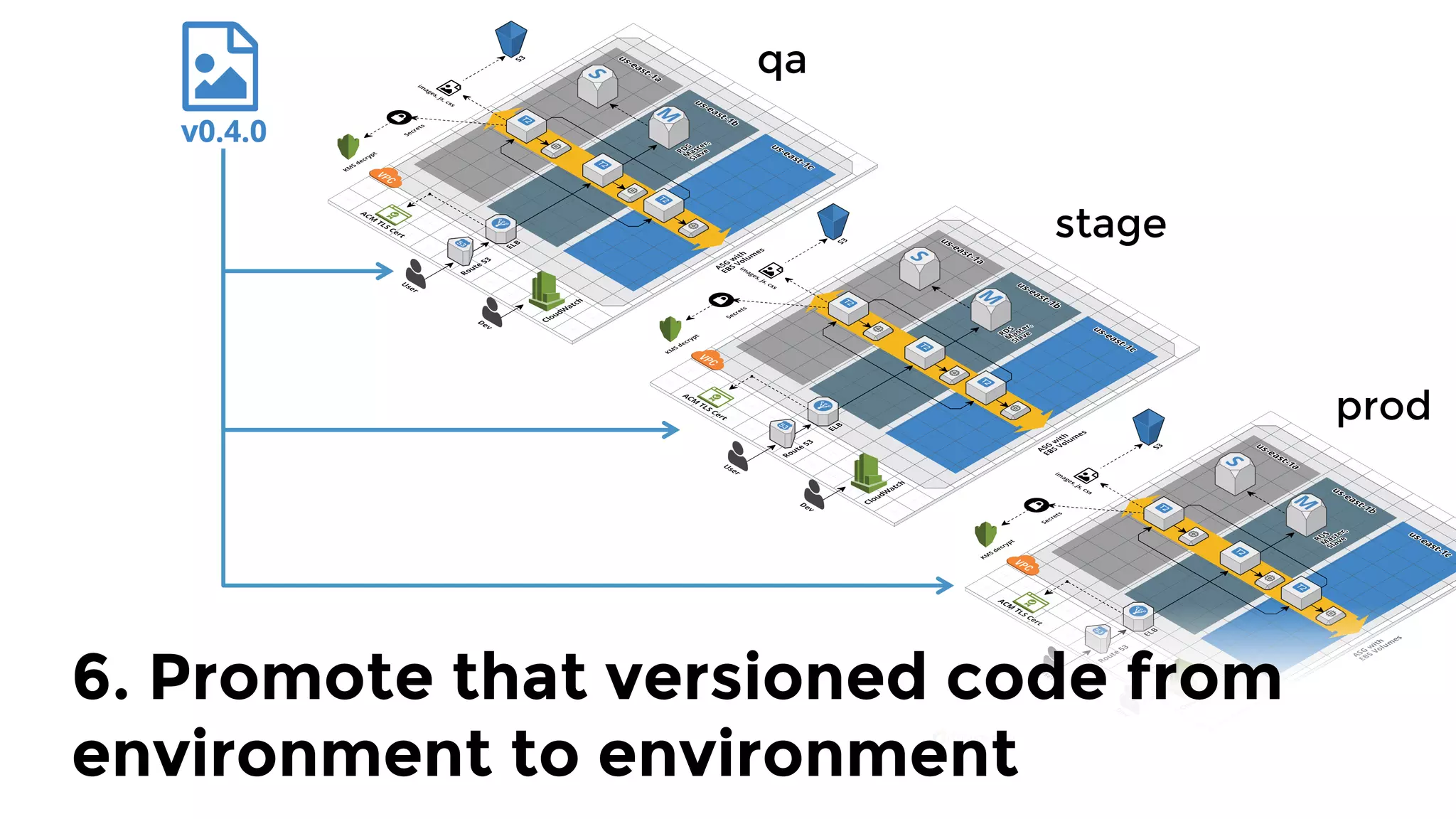




The document discusses the challenges and lessons learned from writing extensive infrastructure code, highlighting the complexities involved in building production-grade systems and the lengthy timelines required for various infrastructure projects. The author emphasizes the significance of using infrastructure as code, automation, and modular design to streamline processes, reduce project durations, and improve code quality. Additionally, it advocates for thorough testing of infrastructure code to ensure reliability and maintainability.










![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)
























































![Hackdays and [in]cubator](https://cdn.slidesharecdn.com/ss_thumbnails/hackdaysandincubator-130211223338-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















