Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Takahiro Kubo
PDF, PPTX
6,956 views
感情の出どころを探る、一歩進んだ感情解析
Aspect Based Sentiment Analysisの導入資料
Data & Analytics
◦
Read more
16
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 30
2
/ 30
3
/ 30
4
/ 30
5
/ 30
6
/ 30
7
/ 30
8
/ 30
9
/ 30
10
/ 30
11
/ 30
12
/ 30
13
/ 30
14
/ 30
15
/ 30
16
/ 30
17
/ 30
18
/ 30
19
/ 30
20
/ 30
21
/ 30
22
/ 30
23
/ 30
24
/ 30
25
/ 30
26
/ 30
27
/ 30
28
/ 30
29
/ 30
30
/ 30
More Related Content
PDF
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
by
Takahiro Kubo
PPTX
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-D...
by
harmonylab
PPTX
MS COCO Dataset Introduction
by
Shinagawa Seitaro
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
PPTX
ResNetの仕組み
by
Kota Nagasato
Data-Centric AIの紹介
by
Kazuyuki Miyazawa
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
by
Takahiro Kubo
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-D...
by
harmonylab
MS COCO Dataset Introduction
by
Shinagawa Seitaro
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
by
ARISE analytics
ResNetの仕組み
by
Kota Nagasato
What's hot
PDF
大規模言語モデルとChatGPT
by
nlab_utokyo
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
PDF
ユーザーサイド情報検索システム
by
joisino
PDF
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
PDF
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
最適化計算の概要まとめ
by
Yuichiro MInato
PDF
semantic segmentation サーベイ
by
yohei okawa
PPTX
強化学習における好奇心
by
Shota Imai
PPTX
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
PPTX
Depth Estimation論文紹介
by
Keio Robotics Association
PDF
深層生成モデルと世界モデル
by
Masahiro Suzuki
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
PPTX
モデル高速化百選
by
Yusuke Uchida
大規模言語モデルとChatGPT
by
nlab_utokyo
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
【メタサーベイ】Vision and Language のトップ研究室/研究者
by
cvpaper. challenge
ユーザーサイド情報検索システム
by
joisino
cvpaper.challenge 研究効率化 Tips
by
cvpaper. challenge
BlackBox モデルの説明性・解釈性技術の実装
by
Deep Learning Lab(ディープラーニング・ラボ)
【メタサーベイ】数式ドリブン教師あり学習
by
cvpaper. challenge
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
最適化計算の概要まとめ
by
Yuichiro MInato
semantic segmentation サーベイ
by
yohei okawa
強化学習における好奇心
by
Shota Imai
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
Depth Estimation論文紹介
by
Keio Robotics Association
深層生成モデルと世界モデル
by
Masahiro Suzuki
GAN(と強化学習との関係)
by
Masahiro Suzuki
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
by
SSII
モデル高速化百選
by
Yusuke Uchida
More from Takahiro Kubo
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
PDF
Graph Attention Network
by
Takahiro Kubo
PDF
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
PDF
自然言語処理で読み解く金融文書
by
Takahiro Kubo
PDF
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
PDF
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
PDF
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
PDF
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
PDF
Reinforcement Learning Inside Business
by
Takahiro Kubo
PDF
ACL2018の歩き方
by
Takahiro Kubo
PPTX
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
PDF
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
PPTX
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
PDF
EMNLP2018 Overview
by
Takahiro Kubo
PDF
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
PDF
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
PDF
Curiosity may drives your output routine.
by
Takahiro Kubo
PDF
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
PDF
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
機械学習で泣かないためのコード設計 2018
by
Takahiro Kubo
Graph Attention Network
by
Takahiro Kubo
機械学習の力を引き出すための依存性管理
by
Takahiro Kubo
自然言語処理で読み解く金融文書
by
Takahiro Kubo
自然言語処理による企業の気候変動対策分析
by
Takahiro Kubo
財務・非財務一体型の企業分析に向けて
by
Takahiro Kubo
あるべきESG投資の評価に向けた、自然言語処理の活用
by
Takahiro Kubo
国際会計基準(IFRS)適用企業の財務評価方法
by
Takahiro Kubo
Reinforcement Learning Inside Business
by
Takahiro Kubo
ACL2018の歩き方
by
Takahiro Kubo
2018年12月4日までに『呪術廻戦』を読む理由
by
Takahiro Kubo
TISにおける、研究開発の方針とメソッド 2018
by
Takahiro Kubo
ESG評価を支える自然言語処理基盤の構築
by
Takahiro Kubo
EMNLP2018 Overview
by
Takahiro Kubo
arXivTimes Review: 2019年前半で印象に残った論文を振り返る
by
Takahiro Kubo
自然言語処理で新型コロナウィルスに立ち向かう
by
Takahiro Kubo
Curiosity may drives your output routine.
by
Takahiro Kubo
nlpaper.challenge NLP/CV交流勉強会 画像認識 7章
by
Takahiro Kubo
Expressing Visual Relationships via Language: 自然言語による画像編集を目指して
by
Takahiro Kubo
感情の出どころを探る、一歩進んだ感情解析
1.
Copyright © 2017
TIS Inc. All rights reserved. 感情の出どころを探る、一歩進んだ感情解析 戦略技術センター 久保隆宏 Introduction for Aspect Based Sentiment Analysis
2.
Copyright © 2017
TIS Inc. All rights reserved. 2 観点感情解析(Aspect Based Sentiment Analysis)とは 既存の感情解析の問題点 観点感情解析のはじまり 観点感情解析のタスク タスクの定義 現在行われているアプローチ 今後のアプローチ 基本方針 観点表現の認識を起点にした手法 1-shot文分類を利用する手法 観点表現の特定と分類を併用するパターン Try Aspect Based Sentiment Analysis! 目次
3.
Copyright © 2017
TIS Inc. All rights reserved. 3 久保隆宏 TIS株式会社 戦略技術センター 化学系メーカーの業務コンサルタント出身 既存の技術では業務改善を行える範囲に限界があるとの実感から、戦 略技術センターへと異動 現在は機械学習や自然言語処理の研究・それらを用いたシステムのプ ロトタイピングを行う 自己紹介 kintoneアプリ内にたまった データを簡単に学習・活用 (@Cybozu Days 2016) チュートリアル講演:深層学習 の判断根拠を理解するための研 究とその意義(@PRMU 2017) 機械学習をシステムに組み込む 際の依存性管理について (@MANABIYA 2018)
4.
Copyright © 2017
TIS Inc. All rights reserved. 4 chakkiのミッション Summarize data for human あらゆるデータを、人間にとってわかりやすく要約 することを目指します。 chakkiが目指す機能: 要約の観点を、なるべく少ないデータで学習する 自然言語以外の、画像や数値データの要約も扱う 図や表といった表現形態にも挑戦する この機能の実現を通じ、最終的にはいつでもティー タイム(15:00)に帰れる(=茶帰)社会を目指します。 2018年度より具体化
5.
Copyright © 2017
TIS Inc. All rights reserved. 5 観点を指定した自然言語処理 観点単位にまとめることで、情報の欠落を 防ぐと共に図表化を行いやすくする。 モデルにお任せで「こんなん出ました」で なく、利用者が出力をコントロールする。 ex: 観点要約 ペンギンのサイズは小さくて、手触りは冷たい。 「サイズ」は「小さく」 「手触り」は「冷たい」 サイズ 手触り ペンギン 小さい 冷たい ライオン 大きい 温かい ウサギ 中くらい 温かい 業務要件により観点は異なる。そして、観点の学習データは少ない。 ⇒自然言語処理における転移学習に注力し、「少ないデータでカスタマ イズ可能な分類/生成器の作成」を目指している。 (2/3)
6.
Copyright © 2017
TIS Inc. All rights reserved. 6 (3/3) 研究開発活動は基本オープンに行っている(GitHub★総計 728)。 研究に関することであれば、個人のブログ/リポジトリも評価される。 機械学習関連の論文のまとめをGitHubのIssueを使って行っ ています。月一での輪講も開催中です。
7.
観点感情解析(Aspect Based Sentiment
Analysis)とは
8.
Copyright © 2017
TIS Inc. All rights reserved. 8 「何が」肯定的・否定的に評価されているのかわからない。 既存の感情解析の問題点(1/2) ここのピザは絶品だね!うちの家族はみんな大好き と言っているよ。 ただ、ここのビールはとても薄いね!ビールの水割 りと思うくらいさ。 店員さんもちょっとぶっきらぼうかな。割られた ビールの分、サービスしてほしいね! レビューや論評といった肯定・否定が混在するようなケースでは、単に各 文のポジティブ・ネガティブだけでなく、「何が」肯定的/否定的に評価 されているかを知りたい。 Positive Negative Negative
9.
Copyright © 2017
TIS Inc. All rights reserved. 9 以下のように、感情の対象が特定できるとよい。 既存の感情解析の問題点(2/2) ここのピザは絶品だね!うちの家族はみんな大好き と言っているよ。 ただ、ここのビールはとても薄いね!ビールの水割 りと思うくらいさ。 店員さんもちょっとぶっきらぼうかな。割られた ビールの分、サービスしてほしいね! Positive Negative Negative ただ、対象の種類は非常に多い(ピザ、マルゲリータ、etc...)。また、評 価軸も様々(味、サービス、値段、etc...)。 そのため、同じカテゴリに属するもの=同じ観点はまとめたい。
10.
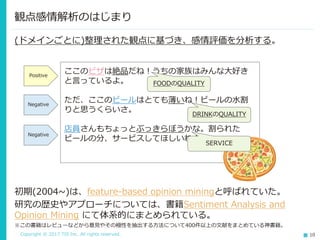
Copyright © 2017
TIS Inc. All rights reserved. 10 ここのピザは絶品だね!うちの家族はみんな大好き と言っているよ。 ただ、ここのビールはとても薄いね!ビールの水割 りと思うくらいさ。 店員さんもちょっとぶっきらぼうかな。割られた ビールの分、サービスしてほしいね! (ドメインごとに)整理された観点に基づき、感情評価を分析する。 観点感情解析のはじまり 初期(2004~)は、feature-based opinion miningと呼ばれていた。 研究の歴史やアプローチについては、書籍Sentiment Analysis and Opinion Mining にて体系的にまとめられている。 ※この書籍はレビューなどから意見やその極性を抽出する方法について400件以上の文献をまとめている神書籍。 Positive Negative Negative FOODのQUALITY SERVICE DRINKのQUALITY
11.
観点感情解析のタスク
12.
Copyright © 2017
TIS Inc. All rights reserved. 12 観点単位の感情解析が、最初に意味解析のワークショップ(SemEval)で取 り上げられたのは2014年。そこから2016年まで3回連続で開催された。 (2017年以降は、TwitterなどのSNS上のメッセージの解析にとってかわられている) そこでのタスク、つまり「どう観点単位の感情解析を行うか?」について は年により若干の違いがある。ただ、最終的には以下の3タスクに落ち着 いている。 Slot1: 各文の観点カテゴリの推定 ピザは美味しいが価格は高い => カテゴリ: (FOOD#QUALITY、FOOD#PRICE) Slot2: 各文の観点カテゴリのエンティティを抽出 ピザは美味しいが価格高い +カテゴリ: (FOOD#QUALITY、FOOD#PRICE) => エンティティ: (FOOD#QUALITY=ピザ、 FOOD#PRICE=価格) Slot3: 各文の観点カテゴリについて極性の推定 ピザは美味しいが価格は高い + カテゴリ: (FOOD#QUALITY、FOOD#PRICE) =>極性: (FOOD#QUALITY =〇、 FOOD#PRICE =×) タスクの定義(1/5)
13.
Copyright © 2017
TIS Inc. All rights reserved. 13 SemEval 2014 Task4 SB1: 観点にかかわる表現の抽出 ピザは美味しいが価格は高い => 表現: (ピザ、価格)、極性: (ピザ=〇、価格=×) SB2: 観点にかかわる表現について、その極性を推定 ピザは美味しいが価格は高い + 表現: (ピザ、価格) => 極性: (ピザ=〇、価格=×) SB3: 各文が議論している観点のカテゴリの推定 ピザは美味しいが価格は高い => カテゴリ: (FOOD、PRICE) SB4: 観点にかかわる表現について、その極性を推定 ピザは美味しいが価格は高い + カテゴリ: (FOOD、PRICE) => 極性: (FOOD=〇、PROCE=×) タスクの定義(2/5) ピザ 美味しい FOOD 観点表現を特定してから、その種別極性を判断する。
14.
Copyright © 2017
TIS Inc. All rights reserved. 14 SemEval 2015 Task12 タスクの定義(3/5) 観点の種別を特定してから、その表現・極性を判断する。 FOOD# QUALITY 美味しい ピザ Slot1: 各文の観点カテゴリの推定 ピザは美味しいが価格は高い => カテゴリ: (FOOD#QUALITY、FOOD#PRICE) Slot2: 各文の観点カテゴリのエンティティを抽出 ピザは美味しいが価格高い +カテゴリ: (FOOD#QUALITY、FOOD#PRICE) => エンティティ: (FOOD#QUALITY=ピザ、 FOOD#PRICE=価格) Slot3: 各文の観点カテゴリについて極性の推定 ピザは美味しいが価格は高い + カテゴリ: (FOOD#QUALITY、FOOD#PRICE) =>極性: (FOOD#QUALITY =〇、 FOOD#PRICE =×)
15.
Copyright © 2017
TIS Inc. All rights reserved. 15 カテゴリは、エンティティ+属性で表現(FOOD#QUALITYなど)。明言さ れていなくてもわかる場合付与する。 例:「この神の舌を持つ僕をうならせる」という場合、明示的に「味」とは言っていないが明らかな ため、FOOD#QUALITYとなる。 また、各文を単独ではなく周辺テキストも含めて考慮する。 例:「ピザの味は本当にいいよ。すごくいい!」という時、二文目(すごくいい!)は単独では何がい いのかわからないが、一文目から推定可能なためFOOD#QUALITYとなる。 SemEval 2016 Task5 SemEval2015に加え、以下のサブタスクが追加された(SubTask1は2015 と同じ)。 Subtask2: テキストレベル(レビュー全体)におけるカテゴリの推定・カ テゴリごとの極性の推定 Subtask3: ドメイン外のテキストでの性能検証(転移性能) ただ提出したチームはなかった? タスクの定義(4/5)
16.
Copyright © 2017
TIS Inc. All rights reserved. 16 SemEval2014~ SemEval2015,2016でタスクが変更された背景。 2014での傾向として「レビュー内で暗黙的に示唆される性質」の特定が 難しかったとしている(特にPCのドメインで。「僕のPCはずっとうなりを あげているよ」はPCの性能について話しているが、性能を示す明確な言葉 はない)。 そのため、2015では明示的な表現(Aspect Term)の特定でなく、全体と して「何を言っているのか」を先に推定する方(Aspect Categoryの推定 =Slot1)に舵を切っている。 ただ、その分少ないデータでエンティティ+属性という多めのカテゴリ (しかもマルチラベル)の問題を一番先に解く形態になってしまってはいる。 タスクの定義(5/5)
17.
Copyright © 2017
TIS Inc. All rights reserved. 17 SemEval 2016までで定義されたタスクをどうこなすかが一つの論点と なっている。一つの研究で3つ(Slot1~Slot3)すべてをやっているものはあ まりなく、どれか一つを選んで行っていることが多い。 Slot1: 各文の観点カテゴリの推定 ピザは美味しいが価格は高い => カテゴリ: (FOOD#QUALITY、FOOD#PRICE) Slot2: 各文の観点カテゴリのエンティティを抽出 ピザは美味しいが価格高い +カテゴリ: (FOOD#QUALITY、FOOD#PRICE) => エンティティ: (FOOD#QUALITY=ピザ、 FOOD#PRICE=価格) Slot3: 各文の観点カテゴリについて極性の推定 ピザは美味しいが価格は高い + カテゴリ: (FOOD#QUALITY、FOOD#PRICE) =>極性: (FOOD#QUALITY =〇、 FOOD#PRICE =×) 現在行われているアプローチ(1/6)
18.
Copyright © 2017
TIS Inc. All rights reserved. 18 ベースラインモデル、また提出された研究については後述するが、大まか には以下のような傾向がある。 Slot1 単語分散表現を利用することで一定の精度はでる。近いドメインの コーパスで学習した分散表現だとなおよい ニューラル系のモデルではそんなに深い層は使ってない(データが 少ないので過学習する) 係り受け関係も一定の効果がある 頻度が少ないカテゴリは切り捨てるのもあり Slot2 CRFがベースで、カテゴリを区別しなくても一定の検出が可能とみ える(カテゴリごとは、数が少なくそもそも難しい) Slot3 Slot1と同等のアプローチで可能 現在行われているアプローチ(2/6)
19.
Copyright © 2017
TIS Inc. All rights reserved. 19 SemEval 2016でベースラインとして使用されている実装は以下。 シンプルな単語特徴を使用したモデル。 現在行われているアプローチ(3/6) モデル スコア Slot1 観点カテゴリの推定 stop wordを除いた1000の上位語を特徴量 としたSVM(One vs All: 一文に複数カテゴ リがつくため) ラベルの確率が0.2を超えるものは付与する F1(micro) 59.928 Slot2 各観点カテゴリのエンティ ティ抽出 学習データ中にある{"カテゴリ": "エンティ ティ表現"}のペアを辞書として持っておき、 順番に当てていく F1(micro) 44.071 Slot3 各観点カテゴリの推定 stop wordを除いた1000の上位語+観点カ テゴリのインデックスを特徴量としたSVM accuracy 76.484
20.
Copyright © 2017
TIS Inc. All rights reserved. 20 タスクで提出された研究のアプローチは以下(スコアが良かったもの)。 NLANGP at SemEval-2016 Task 5: Improving Aspect Based Sentiment Analysis using Neural Network Features Slot1 n-gram、学習データ中のエンティティ表現、係り受け関係にある 単語(HEAD)、単語分散表現、K-meansクラスタなどを特徴使用。 これらの特徴+これらの特徴の一部使ってCNNで畳み込んで予測し た結果を一層のニューラルネットに入れて学習 CNNだけでも精度は高いが、併用するとさらに上がるらしい。 Slot2 CRFにRNNの出力を加えて予測。表現だけ予測すればいいので、ど のAspectのTargetかを区別せず学習。 現在行われているアプローチ(4/6)
21.
Copyright © 2017
TIS Inc. All rights reserved. 21 NileTMRG at SemEval-2016 Task 5: Deep Convolutional Neural Networks for Aspect Category and Sentiment Extraction Slot1 単語の分散表現(YelpやAmazonレビューなどのセンチメント系の データセットでも学習したもの)を、CNNで畳み込む。 Slot3 同じくCNNをベースにした3つのモデルのアンサンブルで予測する。 AUEB-ABSA at SemEval-2016 Task 5: Ensembles of Classifiers and Embeddings for Aspect Based Sentiment Analysis Slot1/2/3すべてを扱っている。Slot1はSVM、Slot2はCRF、Slot3は 特徴量/単語分散表現をベースにした線形回帰。いずれもアンサンブル を行うことで精度を上げている。 実装が公開されている 現在行われているアプローチ(5/6)
22.
Copyright © 2017
TIS Inc. All rights reserved. 22 ECNU: Extracting Effective Features from Multiple Sequential Sentences for Target-dependent Sentiment Analysis in Reviews Aspectの推定(Slot1)に効く特徴を調べた研究。ドメイン固有の単語 (パソコンなら便利、速い、など)がやはり一番効いている。また、係り 受け関係などの文法的特徴が効いている。 Deep Learning for Aspect-Based Sentiment Analysis Slot1 文中単語の単語分散表現を、2層のニューラルネット(Deepと は・・・)で予測(深すぎると過学習するためあえて)。なお、予測ラ ベルで頻度が低いものはOTHERとしてまとめてしまっている。 Slot3 CNNを使用。Aspectの分類確率(Slot1の出力)でもって単語ベクト ルを重みづけしたうえで入力している(これにより、Aspectに関連 する語が重要視されてSentimentが判定される) 現在行われているアプローチ(6/6)
23.
今後のアプローチ方法
24.
Copyright © 2017
TIS Inc. All rights reserved. 24 レストランの評価にはレストランの、ホテルの評価にはホテルの観点単位 のデータが必要、となると評価対象が増えるごとにデータを毎回作らない といけない。これは厳しい。 半教師あり学習 転移学習 こうした技術を活用していく必要がある。 現在までの研究で、最も転移性が期待できるのはSlot2(観点表現の抽出) の箇所。SemEval 2016でトップの成績を出している手法は、いずれも抽 出にあたり観点カテゴリの指定を行っていない(カテゴリを区別しない)。 そのため観点特定を起点にする手法もあるが、1-shotや事前学習済みモデ ルで分類をブーストする方法もありうる。 基本方針
25.
Copyright © 2017
TIS Inc. All rights reserved. 25 観点表現の認識を起点にした手法 Pre-trained Aspect term Detector Aspect Category Classifier Polality Classifier ピザは美味しかった。 ピザは美味しかった。 FOOD#QUALITY POSITIVE ただ、弱点として明確な表現がない場合に対応できない(主語/目的語が省 略されているパターン、比喩表現など)。
26.
Copyright © 2017
TIS Inc. All rights reserved. 26 1-shot文分類を利用する手法 Aspect Category Classifier Target Extraction Polality Classifier ピザは美味しかった/パスタはうまい・・・ POSITIVE あれは僕の舌をうならせた 1/few shot train Trained Aspect Category Classifier FOOD#QUALITY NULL 特定できなくて も問題ない
27.
Copyright © 2017
TIS Inc. All rights reserved. 27 観点表現の特定と分類を併用するパターン Pre-trained Aspect term Detector Aspect Category Classifier Polality Classifier ピザは美味しかった。 ピザは美味しかった。 FOOD#QUALITY POSITIVE 1shot/Pretrainedモ デルを使うことで ブースト Merge 観点表現の特定と分 類は、シリアルに行 う必要は別段ない。
28.
Copyright © 2017
TIS Inc. All rights reserved. 28 観点別の感情解析か・・・面白そうだけど、 どうせ日本語のデータセットはないんだろうな Try Aspect Based Sentiment Analysis!(1/2)
29.
Copyright © 2017
TIS Inc. All rights reserved. 29 Try Aspect Based Sentiment Analysis!(2/2) 有価証券報告書(2016年度)をベースにアノテーションした データを無償で公開しています(GitHub/Kaggleで公開)。 今すぐアクセス!
30.
THANK YOU
Download






















































![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




















