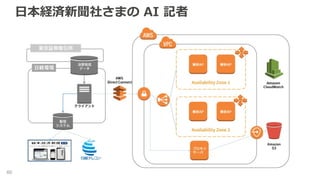
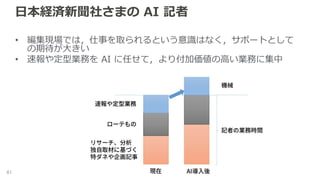
2017/07/05 に開催された,AWS Solution Days 2017 DB Day の講演資料です. https://aws.amazon.com/jp/about-aws/events/2017/solutiondays20170705/


















































![[AWS Start-up ゼミ] よくある課題を一気に解説!〜御社の技術レベルがアップする 2017 夏期講習〜](https://cdn.slidesharecdn.com/ss_thumbnails/awsstartupzemi-2017summer-170816032526-thumbnail.jpg?width=640&height=640&fit=bounds)


















































![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
