AWS Podcast
•Episode #145| September 5, 2016
• Jon Handler: Principal Search Services Solutions Architect
• Elasticsearchとは?
• Elasticsearchのどういうところが良い?
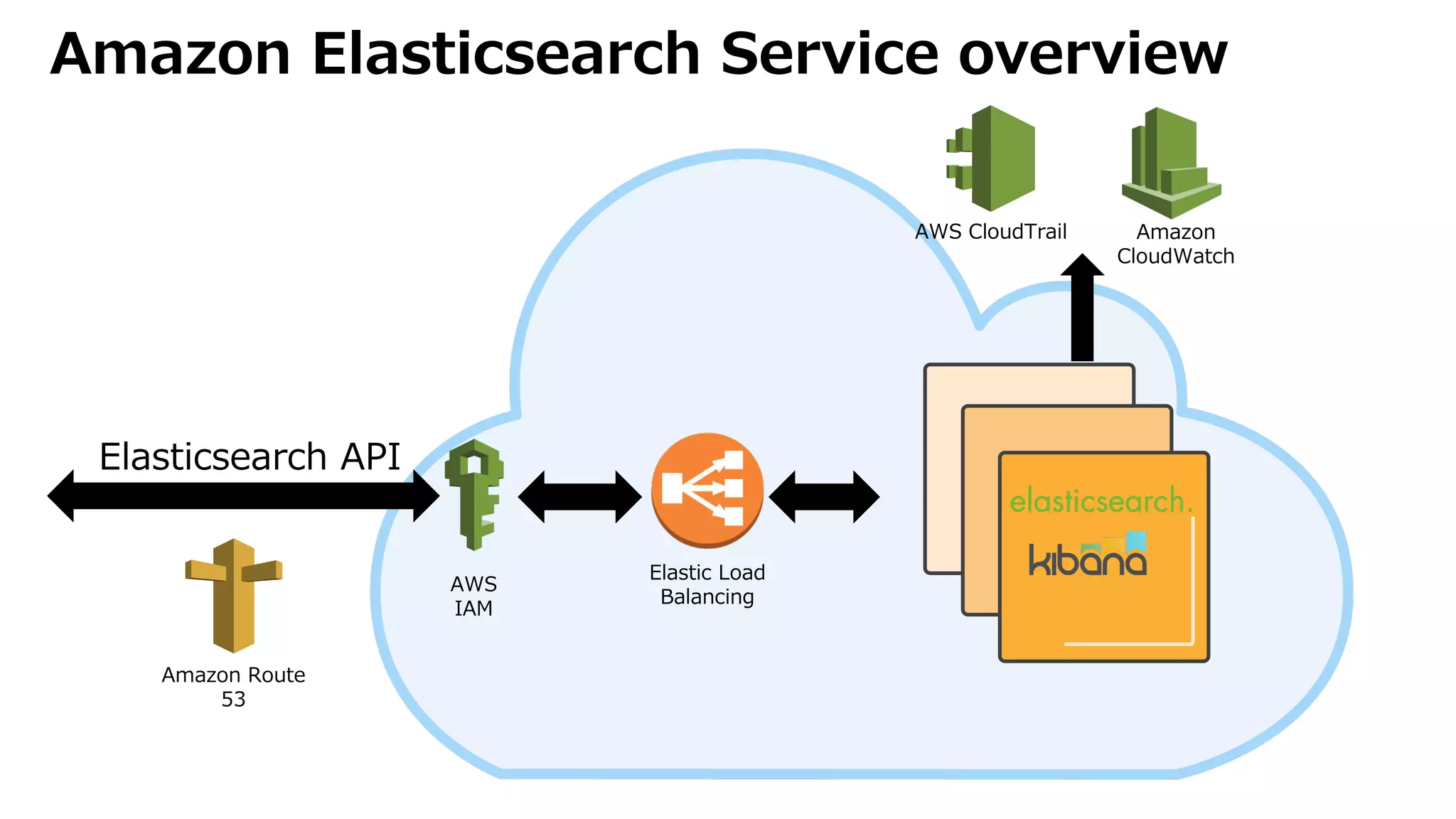
• Amazon Elasticsearch Serviceとは?
• Eliminate undifferenciated heavy lifting
• Easy to manage, operate, and scale
• Security
• Monitoring
• Just a few clicks to deploy
9.
AWS re:Invent 2016
•Real-Time Data Exploration and Analytics with
Amazon Elasticsearch Service and Kibana(BDM302)
https://www.youtube.com/watch?v=R40N9eZTaAA
10.
AWS re:Invent 2016
•Real-Time Data Exploration and Analytics with
Amazon Elasticsearch Service and Kibana(BDM302)
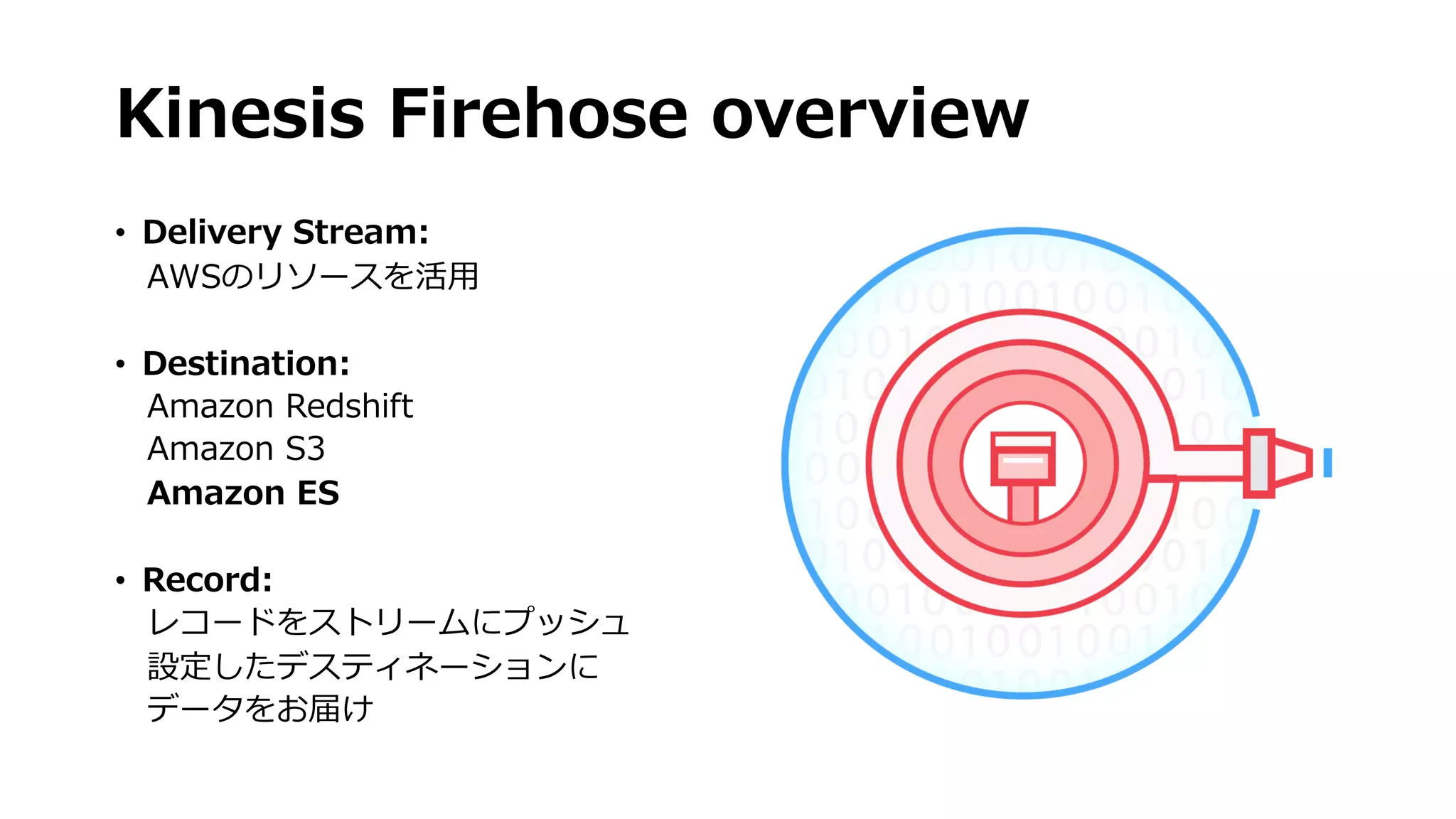
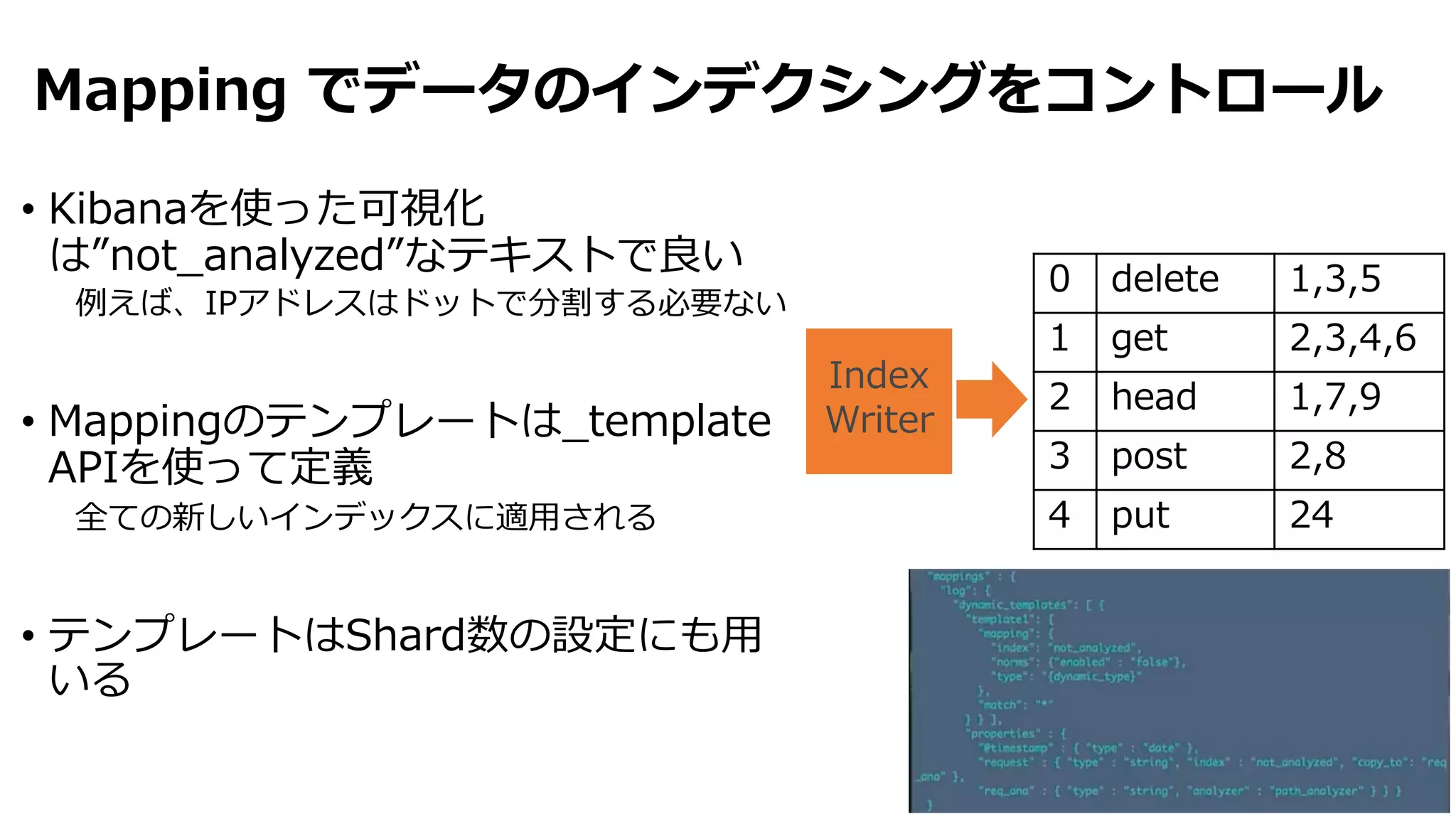
• Apacheのログを使ってend-to-endでログ解析する⽅法を紹介
• Amazon Kinesis Firehoseを使ってAmazon ESクラスタにデータを
投⼊
• インスタンスタイプ, ストレージオプション, shard数, インデック
スのローテーション等のベスト・プラクティスを紹介
• Kibanaのセットアップおよびカスタムダッシュボードウィジェット
の作成⽅法
• Deep Dive: Elasticsearch Query DSLやcustom/ad-hocレポート
の⽣成⽅法の紹介 等
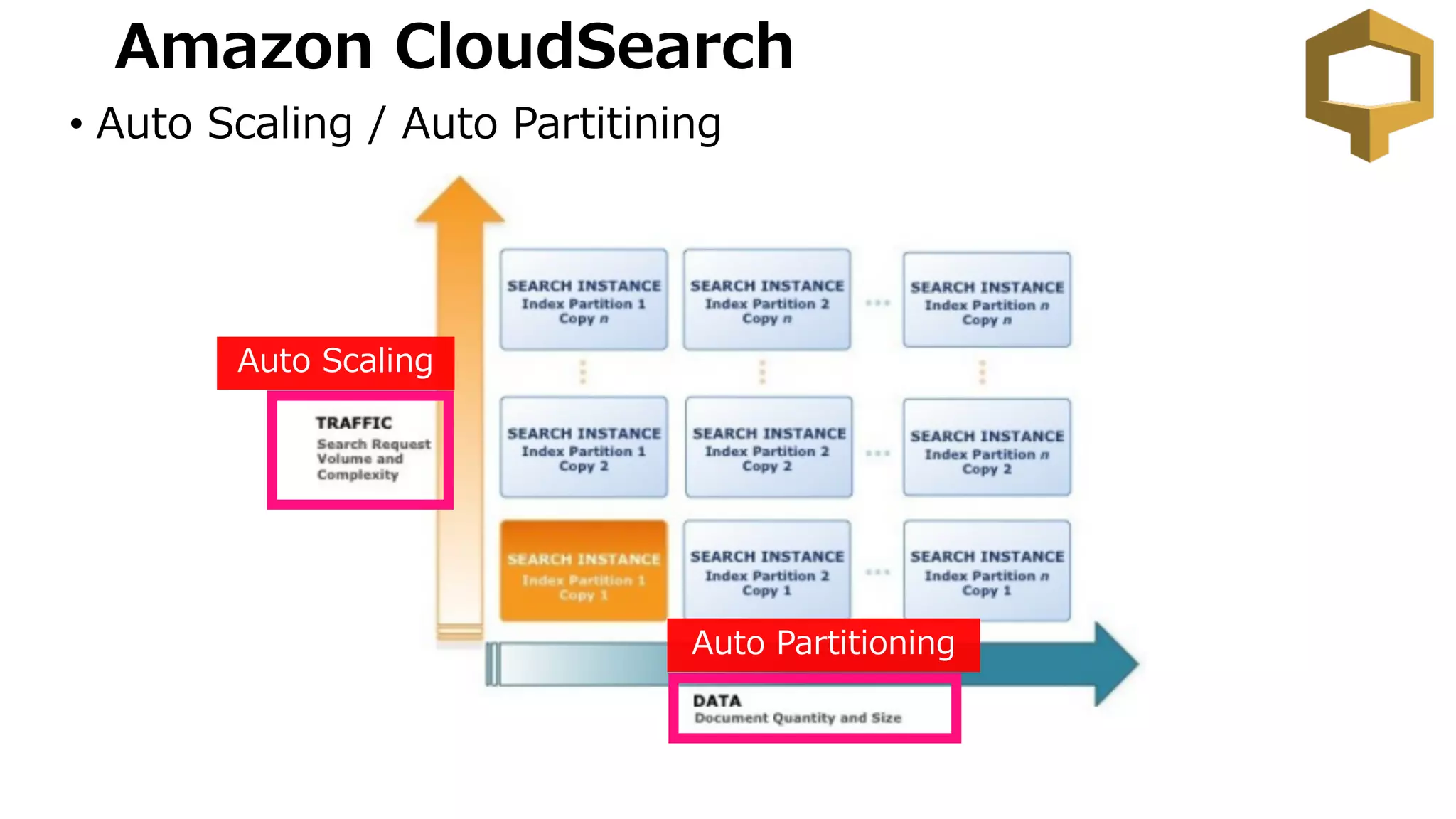
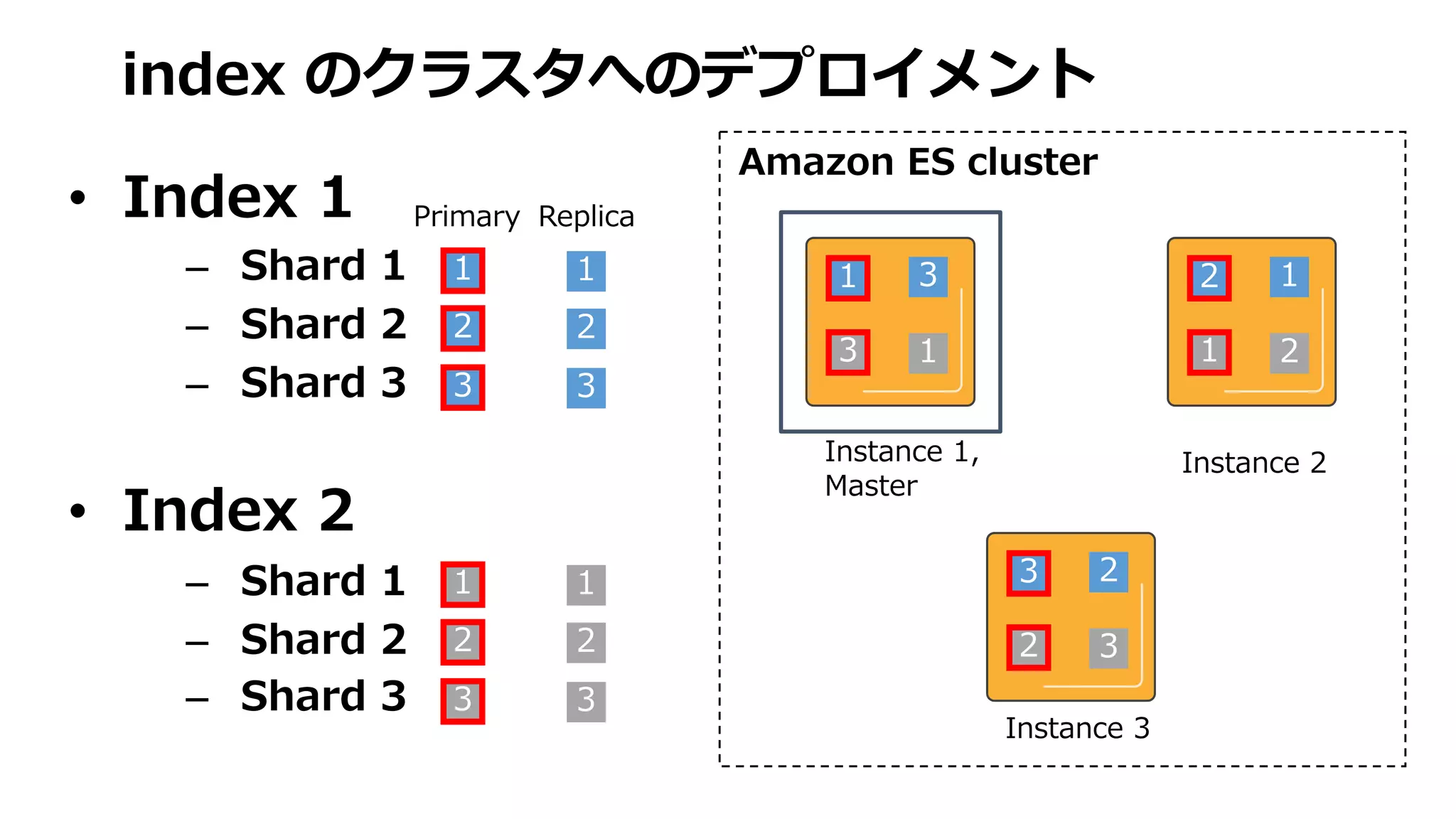
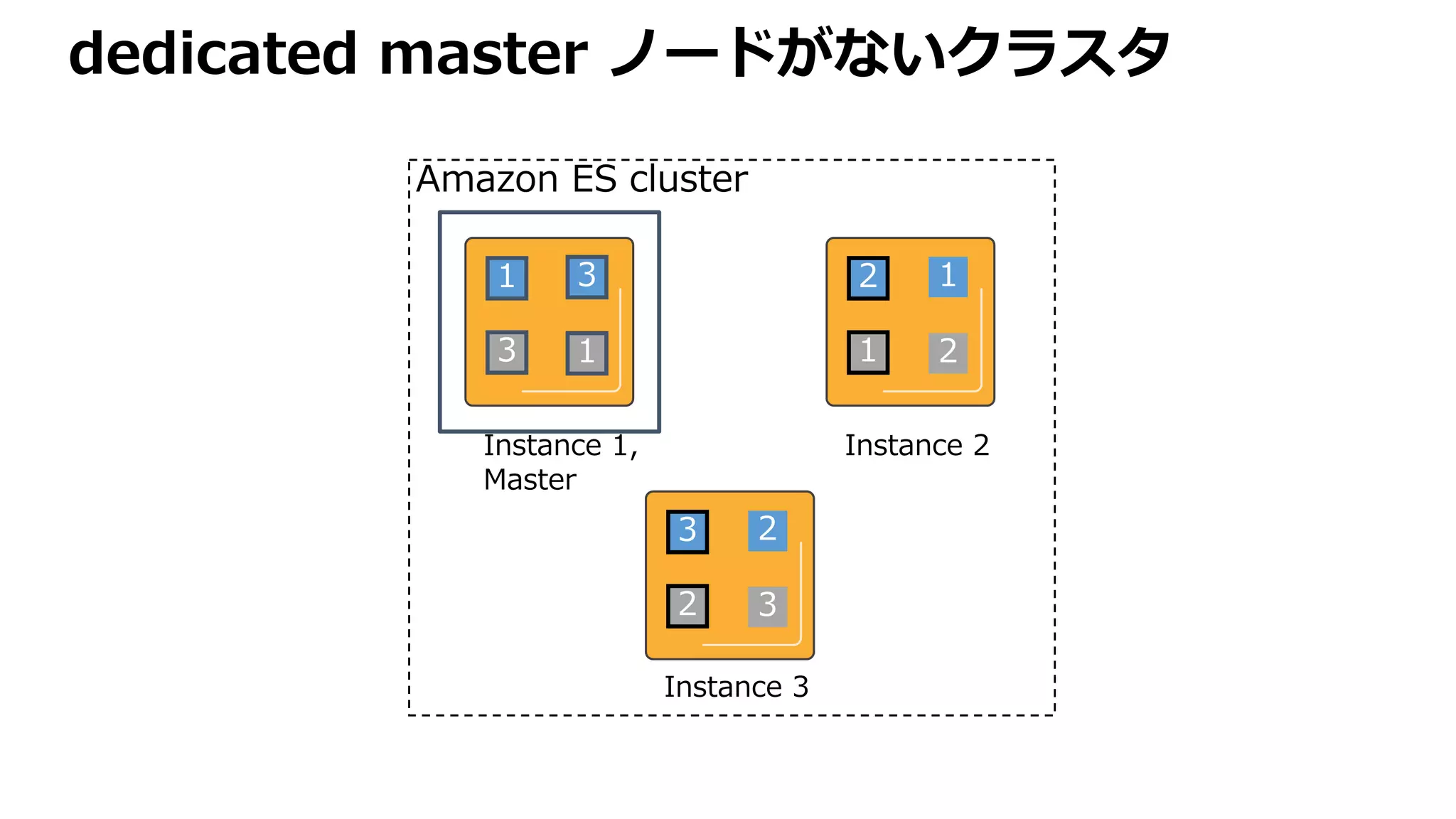
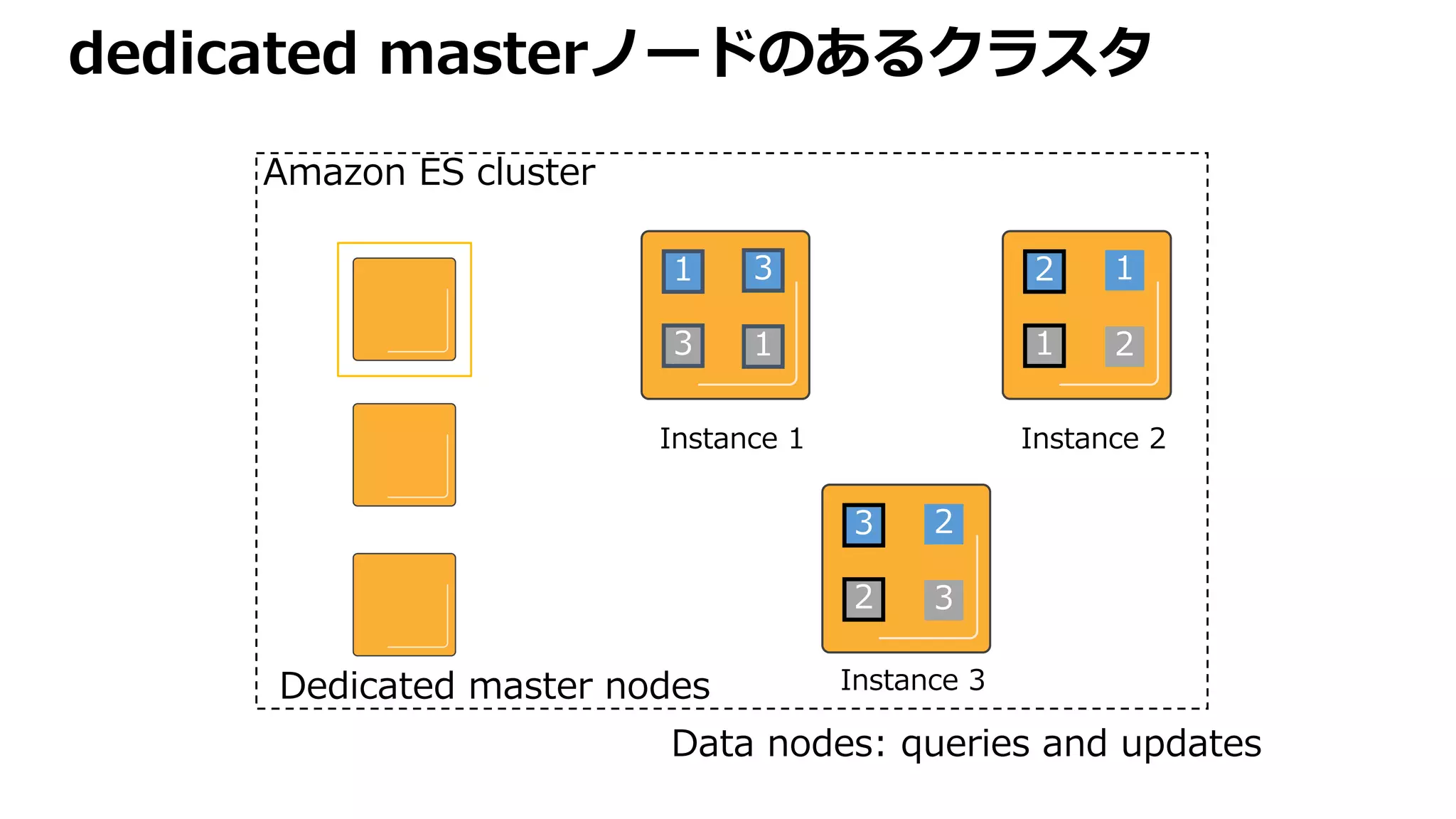
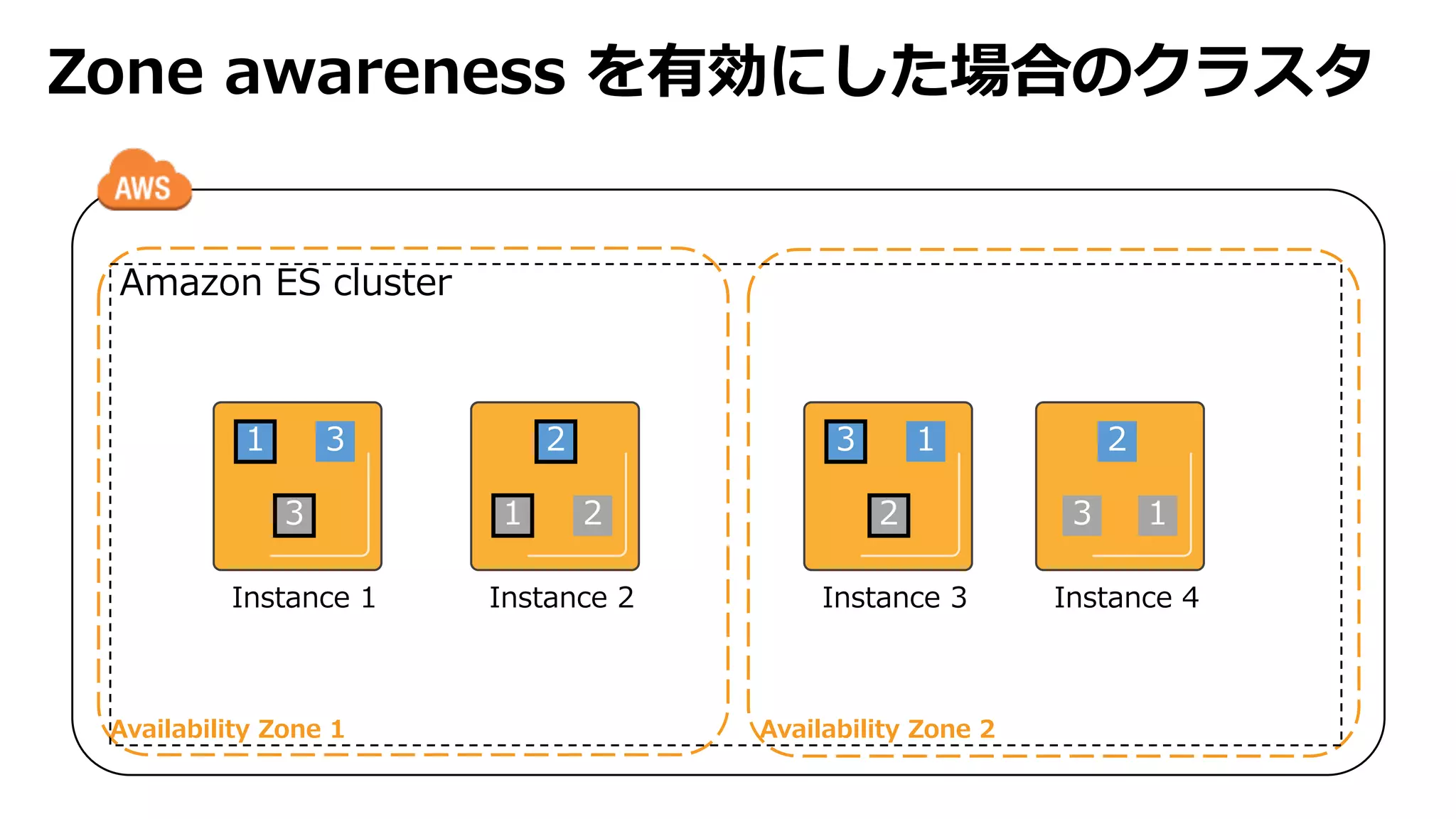
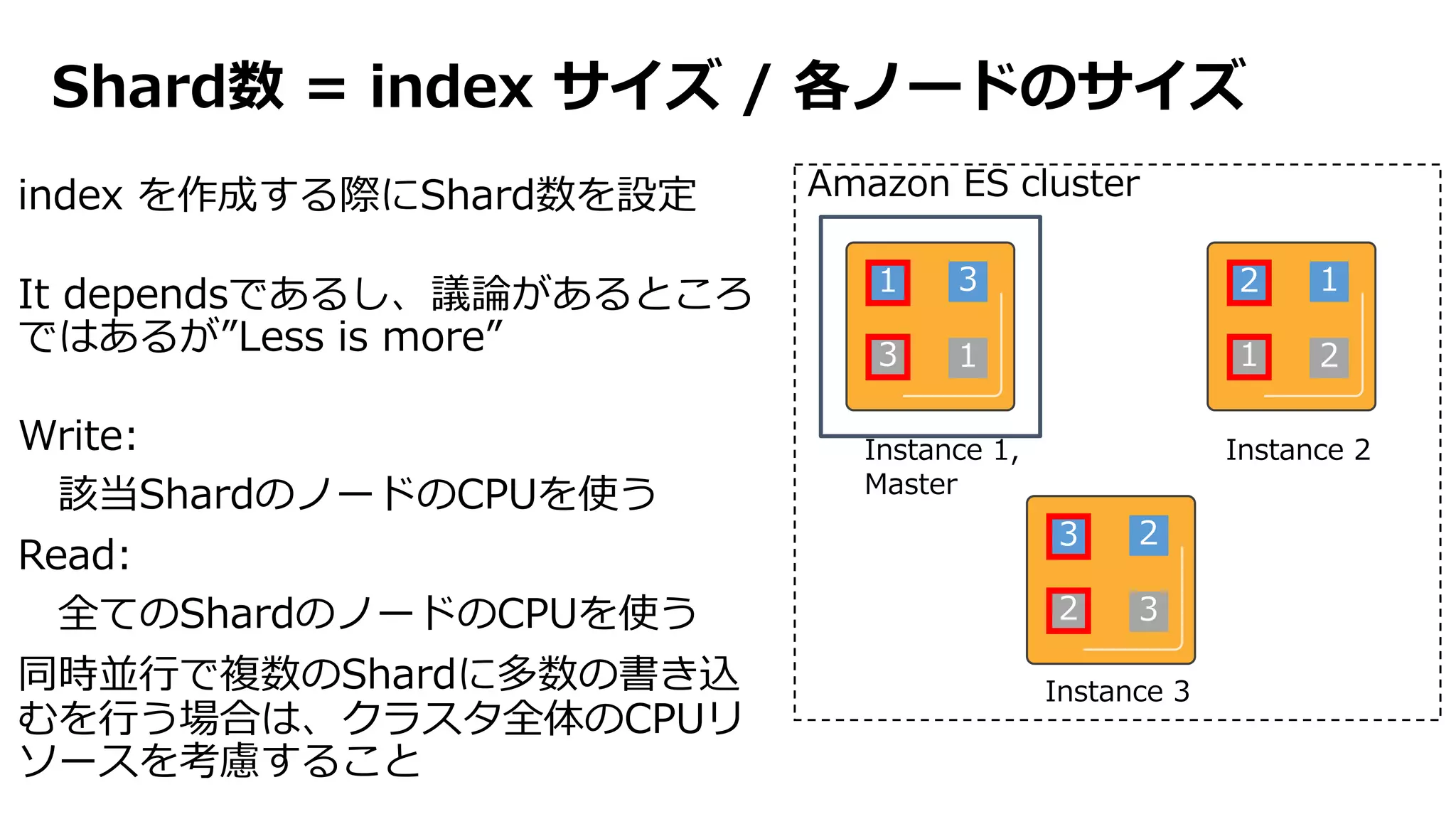
Shard 1 Shard2 Shard 3 Shard 4
index は document の集合。各ドキュメント
は分割された shard に配置されます
Documents
Index
ID ID ID ID ID ID ID ID ID ID ID ID ID ID ID ID
...
Indexing, compression
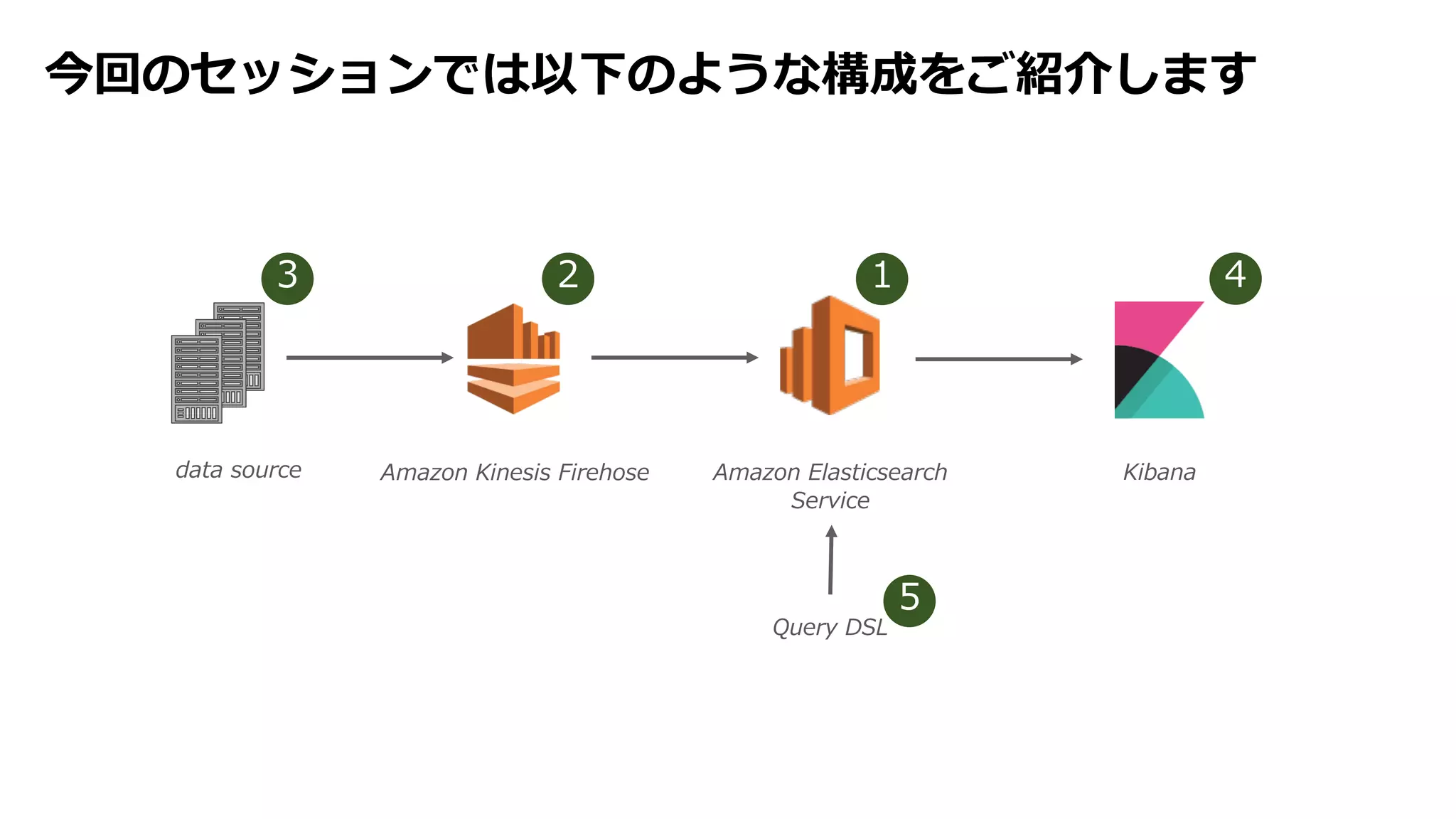
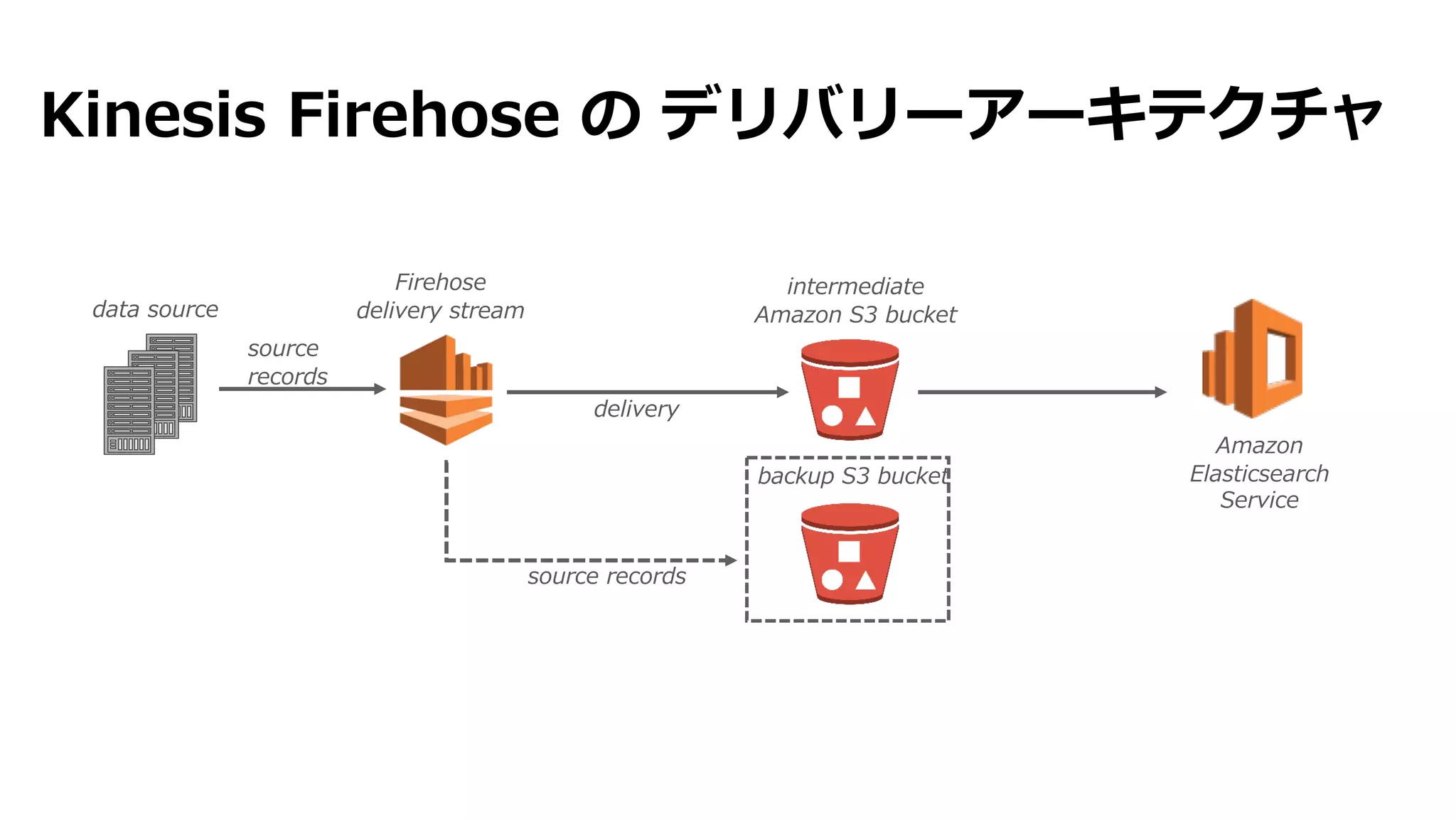
Kinesis Firehose のデリバリーアーキテクチャ
intermediate
Amazon S3 bucket
backup S3 bucket
source records
data source
source
records
Amazon
Elasticsearch
Service
Firehose
delivery stream
delivery
26.
[Coming soon!]
Kinensis Firehoseのデリバリーアーキテクチャ
with transformations
intermediate
Amazon S3
bucket
backup S3 bucket
source records
data source
source records
Amazon
Elasticsearch
Service
Firehose
delivery stream
transformed
records transformed
records
transformation failure
delivery failure
※指定したLambda Functionで変換
Run Elasticsearch inthe AWS cloud with
Amazon Elasticsearch Service
Use Kinesis Firehose to ingest data simply
Kibana for monitoring, Elasticsearch
queries for deeper analysisAmazon
Elasticsearch
Service
41.
Lucene/Solr Revolution 2016
•PlayStation and Lucene - Indexing 1M documents per second
Alexander Filipchik, Sony Interactive Entertainment
http://www.slideshare.net/lucidworks/playstation-and-lucene-indexing-1m-documents-per-
second-presented-by-alexander-filipchik-sony-interactive-entertainment














![[Coming soon!]
Kinensis Firehose のデリバリーアーキテクチャ
with transformations
intermediate
Amazon S3
bucket
backup S3 bucket
source records
data source
source records
Amazon
Elasticsearch
Service
Firehose
delivery stream
transformed
records transformed
records
transformation failure
delivery failure
※指定したLambda Functionで変換](https://image.slidesharecdn.com/searchsolutionsonaws-161206071432/75/Search-Solutions-on-AWS-26-2048.jpg)



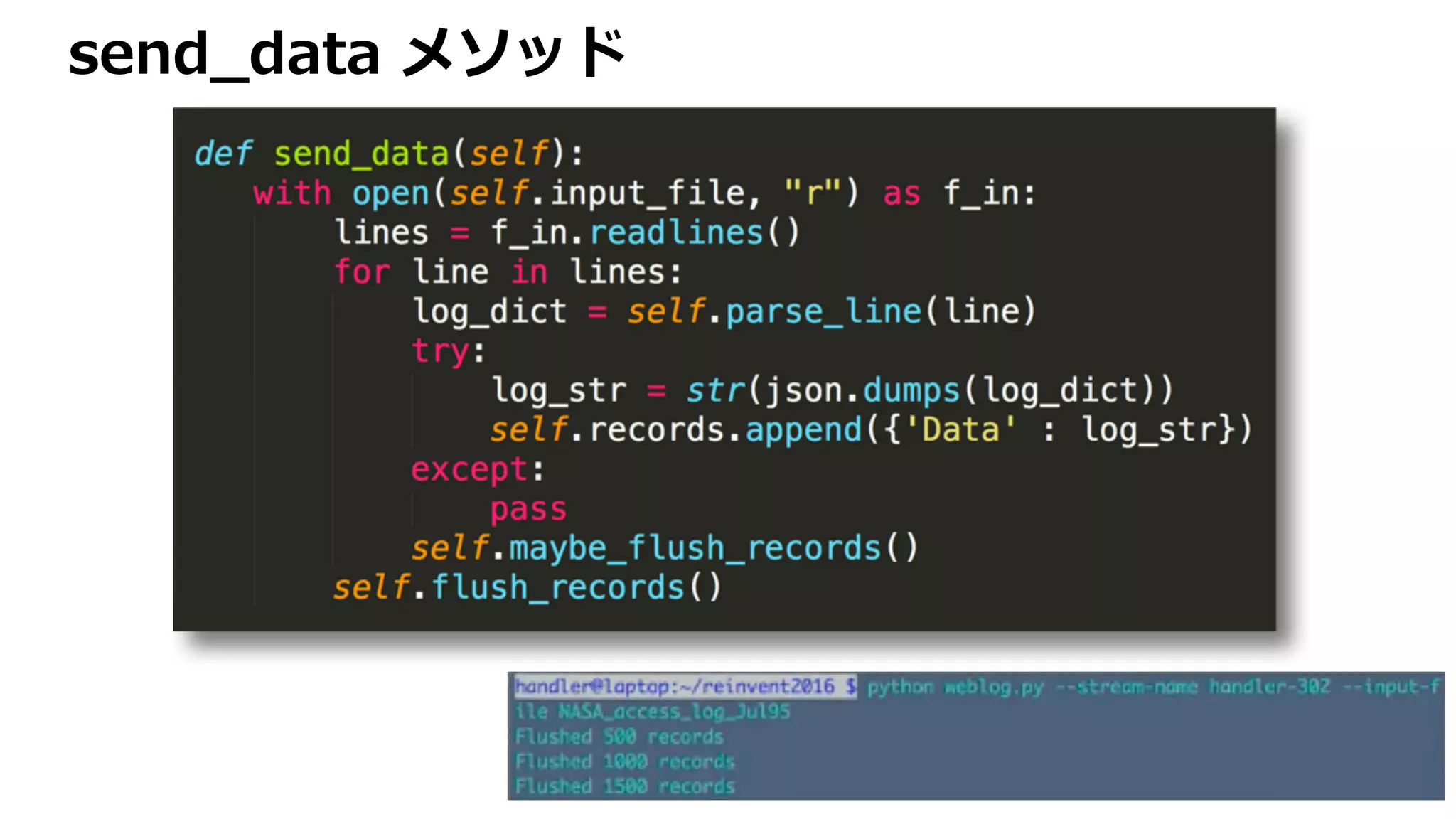
![Log データを検索ドキュメントに変換
d104.aa.net - - [01/Jul/1995:00:00:15 -0400] "GET /images/KSC-logosmall.gif
HTTP/1.0" 200 1204
{"status": 200, "ident": "-", "@timestamp": "1995-07-01T00:00:05", "request":
"/images/KSC-logosmall.gif HTTP/1.0", "auth": "-", "host": "d104.aa.net", "verb":
"GET", "time": "01/Jul/1995:00:00:15 -0400", "size": 1204}](https://image.slidesharecdn.com/searchsolutionsonaws-161206071432/75/Search-Solutions-on-AWS-33-2048.jpg)
































![[Aurora事例祭り]毎日新聞ニュースサイトをクラウド化 ~Amazon Aurora 導入事例紹介~](https://cdn.slidesharecdn.com/ss_thumbnails/mainichiawsaurora2017-170313035655-thumbnail.jpg?width=640&height=640&fit=bounds)



























































