Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Amazon Web Services Japan
PDF, PPTX
2,364 views
クラウド上のデータ活用デザインパターン
2017/06/30 - 07/01 にかけて開催された,db analytics_show_case の講演資料です.
Technology
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 63
2
/ 63
3
/ 63
4
/ 63
5
/ 63
6
/ 63
7
/ 63
8
/ 63
9
/ 63
10
/ 63
11
/ 63
12
/ 63
13
/ 63
14
/ 63
15
/ 63
16
/ 63
17
/ 63
18
/ 63
19
/ 63
20
/ 63
21
/ 63
22
/ 63
23
/ 63
24
/ 63
25
/ 63
26
/ 63
27
/ 63
28
/ 63
29
/ 63
30
/ 63
31
/ 63
32
/ 63
33
/ 63
34
/ 63
35
/ 63
36
/ 63
37
/ 63
38
/ 63
39
/ 63
40
/ 63
41
/ 63
42
/ 63
43
/ 63
44
/ 63
45
/ 63
46
/ 63
47
/ 63
48
/ 63
49
/ 63
50
/ 63
51
/ 63
52
/ 63
53
/ 63
54
/ 63
55
/ 63
56
/ 63
57
/ 63
58
/ 63
59
/ 63
60
/ 63
61
/ 63
62
/ 63
63
/ 63
More Related Content
PDF
AWSではじめるMLOps
by
MariOhbuchi
PDF
SparkとCassandraの美味しい関係
by
datastaxjp
PDF
Amazon S3による静的Webサイトホスティング
by
Yasuhiro Horiuchi
PDF
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
PDF
20190522 AWS Black Belt Online Seminar AWS Step Functions
by
Amazon Web Services Japan
PDF
Amazon VPCトレーニング-VPCの説明
by
Amazon Web Services Japan
PDF
AWS IoTアーキテクチャパターン
by
Amazon Web Services Japan
AWSではじめるMLOps
by
MariOhbuchi
SparkとCassandraの美味しい関係
by
datastaxjp
Amazon S3による静的Webサイトホスティング
by
Yasuhiro Horiuchi
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL
by
Amazon Web Services Japan
AWS Black Belt Online Seminar Amazon Aurora
by
Amazon Web Services Japan
20190522 AWS Black Belt Online Seminar AWS Step Functions
by
Amazon Web Services Japan
Amazon VPCトレーニング-VPCの説明
by
Amazon Web Services Japan
AWS IoTアーキテクチャパターン
by
Amazon Web Services Japan
What's hot
PDF
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
PDF
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
PDF
20201111 AWS Black Belt Online Seminar AWS CodeStar & AWS CodePipeline
by
Amazon Web Services Japan
PDF
20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL Compatib...
by
Amazon Web Services Japan
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
PDF
게임서비스를 위한 ElastiCache 활용 전략 :: 구승모 솔루션즈 아키텍트 :: Gaming on AWS 2016
by
Amazon Web Services Korea
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
20200930 AWS Black Belt Online Seminar Amazon Kinesis Video Streams
by
Amazon Web Services Japan
PDF
AWS Black Belt Online Seminar 2016 AWS IoT
by
Amazon Web Services Japan
PDF
AWS Black Belt Tech シリーズ 2015 - AWS CloudFormation
by
Amazon Web Services Japan
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PDF
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
PDF
【メモ】一般的に設計書に定義される項目例
by
Hirokazu Yatsunami
PDF
Azure load testingを利用したパフォーマンステスト
by
Kuniteru Asami
PDF
AWS Black Belt Techシリーズ AWS IAM
by
Amazon Web Services Japan
PDF
Dockerの期待と現実~Docker都市伝説はなぜ生まれるのか~
by
Masahito Zembutsu
PDF
脆弱性ハンドリングと耐える設計 -Vulnerability Response-
by
Tomohiro Nakashima
PPTX
ぼくらのアカウント戦略〜マルチアカウン トでのガバナンスと権限管理の全て〜
by
Mamoru Ohashi
PPTX
[社内勉強会]ELBとALBと数万スパイク負荷テスト
by
Takahiro Moteki
PDF
AWS初心者向けWebinar AWSとのネットワーク接続入門
by
Amazon Web Services Japan
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
20201111 AWS Black Belt Online Seminar AWS CodeStar & AWS CodePipeline
by
Amazon Web Services Japan
20190828 AWS Black Belt Online Seminar Amazon Aurora with PostgreSQL Compatib...
by
Amazon Web Services Japan
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
게임서비스를 위한 ElastiCache 활용 전략 :: 구승모 솔루션즈 아키텍트 :: Gaming on AWS 2016
by
Amazon Web Services Korea
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
20200930 AWS Black Belt Online Seminar Amazon Kinesis Video Streams
by
Amazon Web Services Japan
AWS Black Belt Online Seminar 2016 AWS IoT
by
Amazon Web Services Japan
AWS Black Belt Tech シリーズ 2015 - AWS CloudFormation
by
Amazon Web Services Japan
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
VPC Reachability Analyzer 使って人生が変わった話
by
Noritaka Sekiyama
【メモ】一般的に設計書に定義される項目例
by
Hirokazu Yatsunami
Azure load testingを利用したパフォーマンステスト
by
Kuniteru Asami
AWS Black Belt Techシリーズ AWS IAM
by
Amazon Web Services Japan
Dockerの期待と現実~Docker都市伝説はなぜ生まれるのか~
by
Masahito Zembutsu
脆弱性ハンドリングと耐える設計 -Vulnerability Response-
by
Tomohiro Nakashima
ぼくらのアカウント戦略〜マルチアカウン トでのガバナンスと権限管理の全て〜
by
Mamoru Ohashi
[社内勉強会]ELBとALBと数万スパイク負荷テスト
by
Takahiro Moteki
AWS初心者向けWebinar AWSとのネットワーク接続入門
by
Amazon Web Services Japan
Similar to クラウド上のデータ活用デザインパターン
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
PDF
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
PDF
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
PPTX
Microsoft AI セミナー - Microsoft AI Platform
by
Daiyu Hatakeyama
PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
PDF
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
PDF
tut_pfi_2012
by
Preferred Networks
PPTX
20170826 Oita JAWS
by
Kameda Harunobu
PDF
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
PDF
Data discoveryを支えるawsのbig data技術と最新事例
by
Takashi Koyanagawa
PPTX
研究用途でのAWSの利用事例と機械学習について
by
Yasuhiro Matsuo
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PPTX
(2017.6.2) Azure HDInsightで実現するスケーラブル分析環境
by
Mitsutoshi Kiuchi
PPT
Big data解析ビジネス
by
Mie Mori
PDF
実装(1) 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第30回】
by
Tomoharu ASAMI
PPTX
20170803 bigdataevent
by
Makoto Uehara
PPTX
デジタルトランスフォーメーション時代を生き抜くためのビジネス力 ~ AI、Advanced Analytics の使いどころ ~
by
Daiyu Hatakeyama
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
PPTX
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
Microsoft AI セミナー - Microsoft AI Platform
by
Daiyu Hatakeyama
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
by
Amazon Web Services Japan
避けては通れないビッグデータ周辺の重要課題
by
kurikiyo
tut_pfi_2012
by
Preferred Networks
20170826 Oita JAWS
by
Kameda Harunobu
【講演資料】ビッグデータ時代の経営を支えるビジネスアナリティクスソリューション
by
Dell TechCenter Japan
Data discoveryを支えるawsのbig data技術と最新事例
by
Takashi Koyanagawa
研究用途でのAWSの利用事例と機械学習について
by
Yasuhiro Matsuo
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
(2017.6.2) Azure HDInsightで実現するスケーラブル分析環境
by
Mitsutoshi Kiuchi
Big data解析ビジネス
by
Mie Mori
実装(1) 【クラウドアプリケーションのためのオブジェクト指向分析設計講座 第30回】
by
Tomoharu ASAMI
20170803 bigdataevent
by
Makoto Uehara
デジタルトランスフォーメーション時代を生き抜くためのビジネス力 ~ AI、Advanced Analytics の使いどころ ~
by
Daiyu Hatakeyama
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
Use case and Live demo : Agile data integration from Legacy system to Hadoop ...
by
DataWorks Summit/Hadoop Summit
More from Amazon Web Services Japan
PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
PDF
202201 AWS Black Belt Online Seminar Apache Spark Performnace Tuning for AWS ...
by
Amazon Web Services Japan
PPTX
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
202201 AWS Black Belt Online Seminar Apache Spark Performnace Tuning for AWS ...
by
Amazon Web Services Japan
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
クラウド上のデータ活用デザインパターン
1.
クラウド上のデータ活用デザインパターン アマゾンウェブサービスジャパン株式会社 ソリューションアーキテクト, 志村 誠 2017.06.30 ©
2017, Amazon Web Services, Inc. or its affiliates. All rights reserved.
2.
自己紹介 2 所属: アマゾンウェブサービスジャパン株式会社 業務: ソリューションアーキテクト (データサイエンス領域) 経歴: Hadoopログ解析基盤の開発 データ分析 データマネジメントや組織のデータ活用 志村 誠 (Makoto
Shimura)
3.
Agenda • データ分析の特徴 • オンプレミス環境でありがちな問題 •
AWS 上のデータ活用環境 • AWS におけるデータ活用のデザインパターン • AWS 上のデータ活用事例 3
4.
データ分析の特徴 4
5.
データ分析の特徴 5 試行錯誤の回数 必要リソースの変動 必要なツールやリソースのバラエティ
6.
試行錯誤の回数 • データ分析は,基本的に試行錯誤を伴う – 元データに対する前処理 –
モデル開発における手法やパラメタの比較検討 – 結果をもとにしたモデルの継続的な改善 • この試行錯誤の回数をいかに高速に積み重ねる かが,良い結果を導きだすために重要 6
7.
必要リソースの変動 • フェーズによって必要なリソースが異なる – モデル開発のときは,小さなデータセットで高速に プロトタイピングを行う –
ステージング検証,本番導入のときには大規模なリ ソースを必要とする 7
8.
必要なツールやリソースのバラエティ • データ分析にはさまざまなツールがある – 可視化-基礎集計のための
SQL / パイプライン処理ツール – ディープラーニングフレームワーク or Hadoop クラスタ – モデルを組み込んだアプリケーション • ツールやモデルによって必要リソースも異なる – CPU / GPU / メモリ / IO – 単一インスタンス / クラスタ / 組み込み 8
9.
データ分析をうまく進めるには 適切なツールやリソースを確保して 試行錯誤のサイクルを高速に回す必要がある
10.
オンプレミス環境でありがちな問題 10
11.
オンプレミス環境でのデータ分析は さまざまな「柔軟性」がないために うまくサイクルを回せないことが多い
12.
柔軟性の問題 • 時間の柔軟性 • アーキテクチャの柔軟性 •
リソースの柔軟性 • ワークロードの柔軟性 12
13.
時間の柔軟性 13 ハードウェアの減価償却サイクルが長く 技術が進歩するスピードやデータ量の増加に追従できない
14.
アーキテクチャの柔軟性 14 既存のアーキテクチャに投資してしまっており そこに付け加える形での活用を前提に考えがち
15.
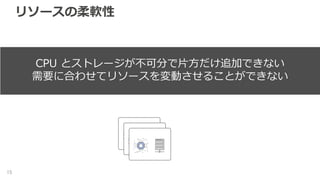
リソースの柔軟性 15 CPU とストレージが不可分で片方だけ追加できない 需要に合わせてリソースを変動させることができない
16.
ワークロードの柔軟性 16 ワークロードにより異なるさまざまなリソースを 適宜用意するのが難しい
17.
オンプレミス環境でのデータ分析は さまざまな「柔軟性」がないために うまくサイクルを回せないことが多い
18.
AWS 上のデータ活用環境 18
19.
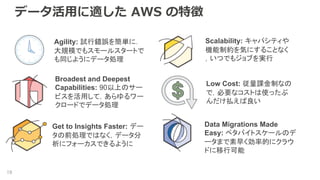
データ活用に適した AWS の特徴 19 Agility:
試行錯誤を簡単に. 大規模でもスモールスタートで も同じようにデータ処理 Scalability: キャパシティや 機能制約を気にすることなく ,いつでもジョブを実行 Get to Insights Faster: デー タの前処理ではなく,データ分 析にフォーカスできるように Broadest and Deepest Capabilities: 90以上のサー ビスを活用して,あらゆるワー クロードでデータ処理 Low Cost: 従量課金制なの で,必要なコストは使ったぶ んだけ払えば良い Data Migrations Made Easy: ペタバイトスケールのデ ータまで素早く効率的にクラウ ドに移行可能
20.
Amazon S3 Data Lake Batch
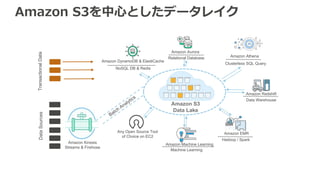
Analytics Amazon Kinesis Streams & Firehose Hadoop / Spark Amazon Redshift Data Warehouse Amazon DynamoDB & ElastiCache NoSQL DB & Redis Relational Database Amazon EMR Amazon Aurora Amazon Machine Learning Machine Learning Any Open Source Tool of Choice on EC2 DataSources Amazon S3を中心としたデータレイク Clusterless SQL Query Amazon Athena TransactionalData
21.
Amazon S3 Data Lake Batch
Analytics Amazon Kinesis Streams & Firehose Hadoop / Spark Amazon Redshift Data Warehouse Amazon DynamoDB & ElastiCache NoSQL DB & Redis Relational Database Amazon EMR Amazon Aurora Amazon Machine Learning Machine Learning Any Open Source Tool of Choice on EC2 DataSources Amazon S3を中心としたデータレイク Clusterless SQL Query Amazon Athena TransactionalData すべてのデータを1ヶ所に集めて保存 データストアとデータ処理の分離 用途に応じた適切な処理方法の選択
22.
Amazon S3 高い耐久性と可用性を持つスケーラブルなオブジェクトストレージ • 99.999999999%の耐久性と,99.99%の 可用性を持つ設計 •
暗号化技術(SSE, CSE)にも対応し,安 全にデータを保存 • 利用したデータのぶんだけ従量課金 • 多くのAWSにとって仮想的なデータレイヤ
23.
Amazon Kinesis Amazon Kinesis Streams ストリームデータを 処理・分析するための データを格納 Amazon
Kinesis Firehose ストリームデータを S3, Redshift, ESに 簡単にロード Amazon Kinesis Analytics ストリーミングデータを 標準的なSQLクエリで 簡単に分析 ストリームデータを収集・処理・配信するためのマネージドサービス群
24.
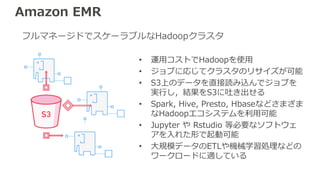
Amazon EMR • 運用コストでHadoopを使用 •
ジョブに応じてクラスタのリサイズが可能 • S3上のデータを直接読み込んでジョブを 実行し,結果をS3に吐き出せる • Spark, Hive, Presto, Hbaseなどさまざま なHadoopエコシステムを利用可能 • Jupyter や Rstudio 等必要なソフトウェ アを入れた形で起動可能 • 大規模データのETLや機械学習処理などの ワークロードに適している フルマネージドでスケーラブルなHadoopクラスタ
25.
Amazon Athena 25 フルマネージドでS3上のデータに対してSQLクエリを実行 • フルマネージドで運用コストがかからない •
Prestoベースで標準SQLが実行可能 • 走らせたクエリのぶんだけ従量課金 • S3に貯めたWebサーバのログに対してク エリを投げてサービス障害の原因を探った り,手軽にアドホック分析をおこなう
26.
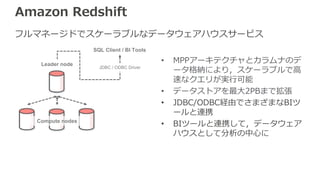
Amazon Redshift フルマネージドでスケーラブルなデータウェアハウスサービス Leader node Compute
nodes SQL Client / BI Tools JDBC / ODBC Driver • MPPアーキテクチャとカラムナのデ ータ格納により,スケーラブルで高 速なクエリが実行可能 • データストアを最大2PBまで拡張 • JDBC/ODBC経由でさまざまなBIツ ールと連携 • BIツールと連携して,データウェア ハウスとして分析の中心に
27.
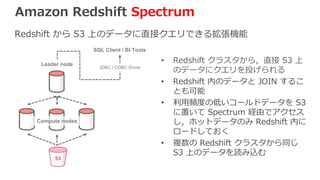
Amazon Redshift Spectrum Redshift
から S3 上のデータに直接クエリできる拡張機能 Leader node Compute nodes SQL Client / BI Tools JDBC / ODBC Driver • Redshift クラスタから,直接 S3 上 のデータにクエリを投げられる • Redshift 内のデータと JOIN するこ とも可能 • 利用頻度の低いコールドデータを S3 に置いて Spectrum 経由でアクセス し,ホットデータのみ Redshift 内に ロードしておく • 複数の Redshift クラスタから同じ S3 上のデータを読み込む
28.
P2 インスタンス +
Deep Learning AMI • インスタンスあたり最大 16個の GPU (NVIDIA Tesla K80)を使う ことで,ディープラーニングのモデル構築にかかる時間を大幅に短 縮可能 • Deep Learning AMI によって,主要フレームワークがすべてプリ インストールされた状態で,インスタンスが立ち上がる 28 Instance Name GPU Count Memory GPU Memory Network Performance P2.xlarge 1 61GiB 12 GiB High P2.8xlarge 8 488GiB 96 GiB 10 Gigabit P2.16xlarge 16 732GiB 192 GiB 20 Gigabit
29.
AWS におけるデータ活用のデザインパターン 29
30.
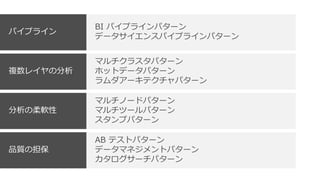
BI パイプラインパターン データサイエンスパイプラインパターン パイプライン マルチクラスタパターン ホットデータパターン ラムダアーキテクチャパターン 複数レイヤの分析 マルチノードパターン マルチツールパターン スタンプパターン 分析の柔軟性 AB テストパターン データマネジメントパターン カタログサーチパターン 品質の担保
31.
BI パイプラインパターン DS パイプラインパターン パイプライン マルチクラスタパターン ホットデータパターン ラムダアーキテクチャパターン 複数レイヤの分析 マルチノードパターン マルチツールパターン スタンプパターン 分析の柔軟性 AB
テストパターン データマネジメントパターン カタログサーチパターン 品質の担保
32.
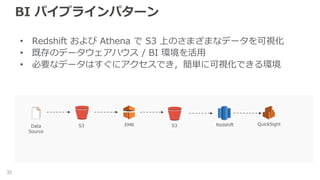
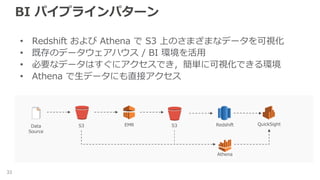
BI パイプラインパターン 32 • Redshift
および Athena で S3 上のさまざまなデータを可視化 • 既存のデータウェアハウス / BI 環境を活用 • 必要なデータはすぐにアクセスでき,簡単に可視化できる環境 S3 S3EMRData Source Redshift QuickSight
33.
BI パイプラインパターン 33 • Redshift
および Athena で S3 上のさまざまなデータを可視化 • 既存のデータウェアハウス / BI 環境を活用 • 必要なデータはすぐにアクセスでき,簡単に可視化できる環境 • Athena で生データにも直接アクセス S3 S3EMRData Source Redshift QuickSight Athena
34.
リブセンスさま アナリティクスのためのデータパイプライン https://speakerdeck.com/livesense/ribusensufalsedetafen-xi-ji-pan-falsequan-mao
35.
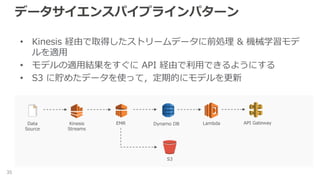
データサイエンスパイプラインパターン 35 • Kinesis 経由で取得したストリームデータに前処理
& 機械学習モデ ルを適用 • モデルの適用結果をすぐに API 経由で利用できるようにする • S3 に貯めたデータを使って,定期的にモデルを更新 Data Source Kinesis Streams EMR S3 Dynamo DB Lambda API Gateway
36.
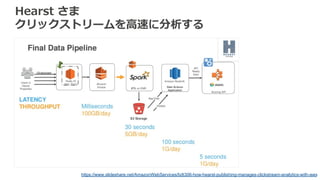
Hearst さま クリックストリームを高速に分析する https://www.slideshare.net/AmazonWebServices/bdt306-how-hearst-publishing-manages-clickstream-analytics-with-aws
37.
BI パイプラインパターン DS パイプラインパターン パイプライン マルチノードパターン マルチツールパターン スタンプパターン 分析の柔軟性 AB
テストパターン データマネジメントパターン カタログサーチパターン 品質の担保 マルチクラスタパターン ホットデータパターン ラムダアーキテクチャパターン 複数レイヤの分析
38.
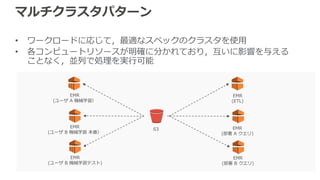
マルチクラスタパターン • ワークロードに応じて,最適なスペックのクラスタを使用 • 各コンピュートリソースが明確に分かれており,互いに影響を与える ことなく,並列で処理を実行可能 S3 EMR (ETL) EMR (部署
A クエリ) EMR (部署 B クエリ) EMR (ユーザ A 機械学習) EMR (ユーザ B 機械学習テスト) EMR (ユーザ B 機械学習 本番)
39.
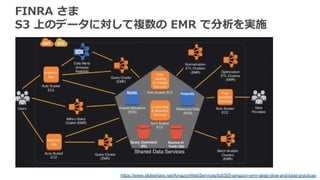
FINRA さま S3 上のデータに対して複数の
EMR で分析を実施 https://www.slideshare.net/AmazonWebServices/bdt305-amazon-emr-deep-dive-and-best-practices
40.
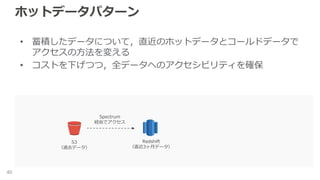
ホットデータパターン 40 • 蓄積したデータについて,直近のホットデータとコールドデータで アクセスの方法を変える • コストを下げつつ,全データへのアクセシビリティを確保 S3 (過去データ) Redshift (直近3ヶ月データ) Spectrum 経由でアクセス
41.
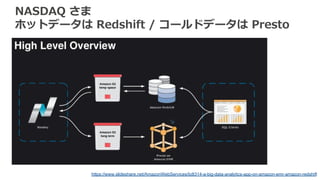
NASDAQ さま ホットデータは Redshift
/ コールドデータは Presto https://www.slideshare.net/AmazonWebServices/bdt314-a-big-data-analytics-app-on-amazon-emr-amazon-redshift
42.
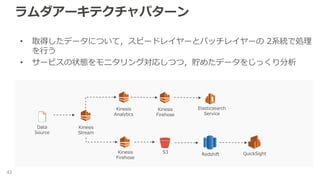
ラムダアーキテクチャパターン 42 • 取得したデータについて,スピードレイヤーとバッチレイヤーの 2系統で処理 を行う •
サービスの状態をモニタリング対応しつつ,貯めたデータをじっくり分析 Kinesis Stream Data Source Kinesis Analytics Kinesis Firehose Elasticsearch Service S3Kinesis Firehose Redshift QuickSight
43.
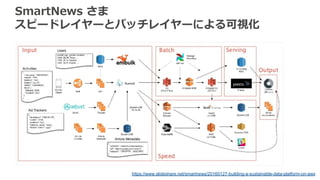
SmartNews さま スピードレイヤーとバッチレイヤーによる可視化 https://www.slideshare.net/smartnews/20160127-building-a-sustainable-data-platform-on-aws
44.
BI パイプラインパターン DS パイプラインパターン パイプライン AB
テストパターン データマネジメントパターン カタログサーチパターン 品質の担保 マルチクラスタパターン ホットデータパターン ラムダアーキテクチャパターン 複数レイヤの分析 マルチノードパターン マルチツールパターン スタンプパターン 分析の柔軟性
45.
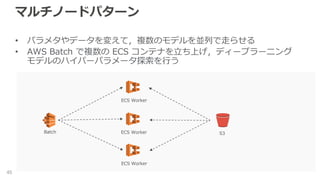
マルチノードパターン 45 • パラメタやデータを変えて,複数のモデルを並列で走らせる • AWS
Batch で複数の ECS コンテナを立ち上げ,ディープラーニング モデルのハイパーパラメータ探索を行う S3Batch ECS Worker ECS Worker ECS Worker
46.
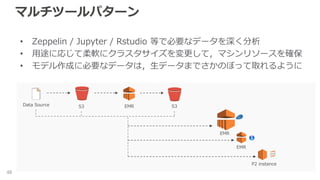
マルチツールパターン 46 • Zeppelin /
Jupyter / Rstudio 等で必要なデータを深く分析 • 用途に応じて柔軟にクラスタサイズを変更して,マシンリソースを確保 • モデル作成に必要なデータは,生データまでさかのぼって取れるように S3 S3EMRData Source EMR EMR P2 instance
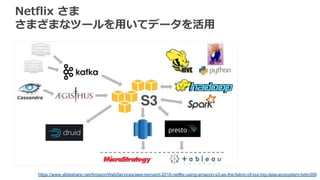
47.
Netflix さま さまざまなツールを用いてデータを活用 https://www.slideshare.net/AmazonWebServices/aws-reinvent-2016-netflix-using-amazon-s3-as-the-fabric-of-our-big-data-ecosystem-bdm306
48.
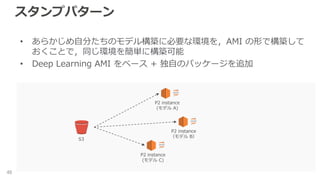
スタンプパターン 48 • あらかじめ自分たちのモデル構築に必要な環境を,AMI の形で構築して おくことで,同じ環境を簡単に構築可能 •
Deep Learning AMI をベース + 独自のパッケージを追加 S3 P2 instance (モデル A) P2 instance (モデル B) P2 instance (モデル C)
49.
BI パイプラインパターン DS パイプラインパターン パイプライン マルチクラスタパターン ホットデータパターン ラムダアーキテクチャパターン 複数レイヤの分析 マルチノードパターン マルチツールパターン スタンプパターン 分析の柔軟性 AB
テストパターン データマネジメントパターン カタログサーチパターン 品質の担保
50.
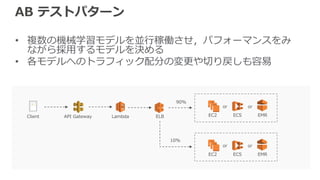
AB テストパターン • 複数の機械学習モデルを並行稼働させ,パフォーマンスをみ ながら採用するモデルを決める •
各モデルへのトラフィック配分の変更や切り戻しも容易 Client API Gateway Lambda ELB EC2 ECS EMR or or EC2 ECS EMR or or 90% 10%
51.
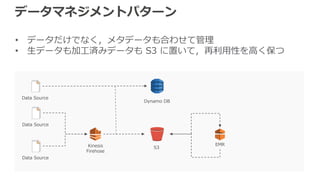
データマネジメントパターン • データだけでなく,メタデータも合わせて管理 • 生データも加工済みデータも
S3 に置いて,再利用性を高く保つ S3 EMR Data Source Dynamo DB Kinesis Firehose Data Source Data Source
52.
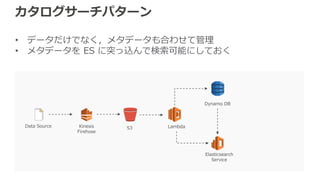
カタログサーチパターン • データだけでなく,メタデータも合わせて管理 • メタデータを
ES に突っ込んで検索可能にしておく Kinesis Firehose Data Source S3 Dynamo DB Lambda Elasticsearch Service
53.
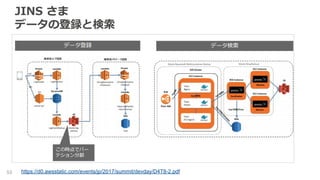
JINS さま データの登録と検索 53 https://d0.awsstatic.com/events/jp/2017/summit/devday/D4T8-2.pdf
54.
AWS 上のデータ活用事例 54
55.
Cookpad さまの機械学習基盤 55 https://d0.awsstatic.com/events/jp/2017/summit/slide/D3T5-2.pdf
56.
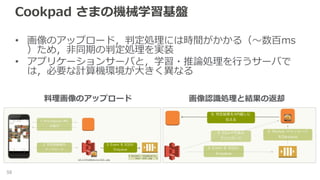
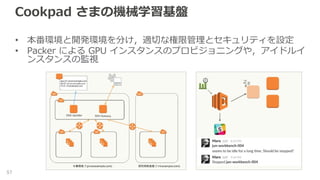
Cookpad さまの機械学習基盤 • 画像のアップロード,判定処理には時間がかかる(〜数百ms )ため,非同期の判定処理を実装 •
アプリケーションサーバと,学習・推論処理を行うサーバで は,必要な計算機環境が大きく異なる 56 料理画像のアップロード 画像認識処理と結果の返却
57.
Cookpad さまの機械学習基盤 • 本番環境と開発環境を分け,適切な権限管理とセキュリティを設定 •
Packer による GPU インスタンスのプロビジョニングや,アイドルイ ンスタンスの監視 57
58.
日本経済新聞社さまの AI 記者 •
決算サマリーを自動生成して配信 • 2017/1/25-5/26 で 6787 サマリーを生成,1-2 分で記事を公開 58 https://d0.awsstatic.com/events/jp/2017/summit/slide/D4T5-3.pdf
59.
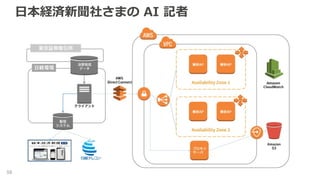
日本経済新聞社さまの AI 記者 59
60.
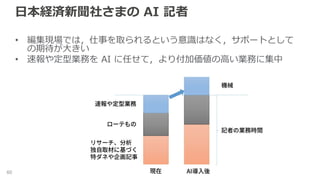
日本経済新聞社さまの AI 記者 •
編集現場では,仕事を取られるという意識はなく,サポートとして の期待が大きい • 速報や定型業務を AI に任せて,より付加価値の高い業務に集中 60
61.
まとめ 61
62.
まとめ • AWS を活用することで,必要なツールやリソ ースを柔軟に確保し,高速な試行錯誤のサイク ルを回すことが可能に •
データ活用システムを構築する際には,デザイ ンパターンや事例を参考にして,よいアーキテ クチャを実現 62
63.
63
Download


























































![[社内勉強会]ELBとALBと数万スパイク負荷テスト](https://cdn.slidesharecdn.com/ss_thumbnails/elbalb-160822022623-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)

















