• Redis Cluster
•3.5TB in-memory capacity
• ~4.5 million writes per second
• ~20 million reads per second
• Auto-Sharding with support up to 15 shards
• Cluster Level Backup and Restore
• Faster Failover (~30 seconds, 4X times faster)
• Enhanced Redis Engine for Improved Robustnes
s and Stability
• Redis 3.2 Engine
Redis Cluster
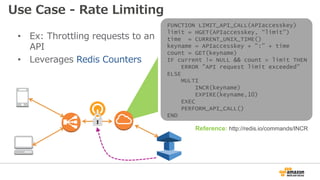
• Ex: Throttlingrequests to an
API
• Leverages Redis Counters
ELB
Externally
Facing
API
Reference: http://redis.io/commands/INCR
FUNCTION LIMIT_API_CALL(APIaccesskey)
limit = HGET(APIaccesskey, “limit”)
time = CURRENT_UNIX_TIME()
keyname = APIaccesskey + ":” + time
count = GET(keyname)
IF current != NULL && count > limit THEN
ERROR ”API request limit exceeded"
ELSE
MULTI
INCR(keyname)
EXPIRE(keyname,10)
EXEC
PERFORM_API_CALL()
END
Use Case - Rate Limiting
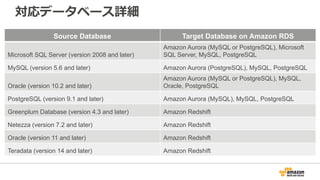
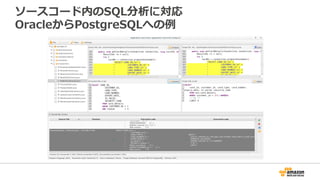
P o st g r e S Q L F o r A u r o r a
Aurora is now fully compatible with
both PostgreSQL and MySQL
12.
1/10th The CostOf
Commercial Grade
Databases
Fully PostgreSQL
Compatible
Several times better
performance than typical
PostgreSQL database
Scalable,
Durable and Secure
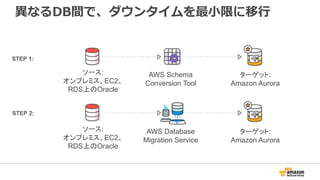
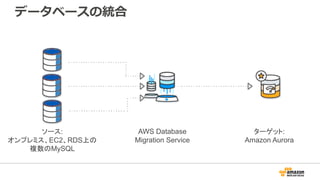
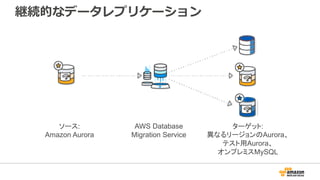
Migrate From
RDS For PostgreSQL
Amazon Aurora PostgreSQL-Compatible Edition
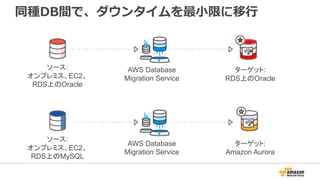
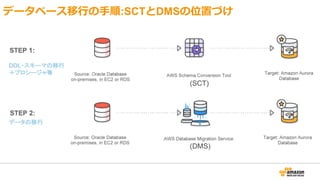
Migrating Databases ToAWS
20,000+
databases migrated
Migrate between
on-prem and AWS
Migrate between
databases
Automated schema
conversion
Data replication for
zero downtime migrations
























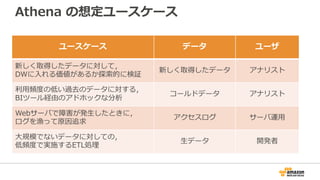
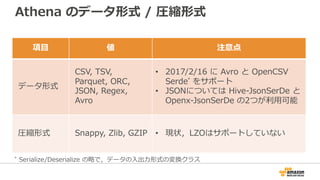

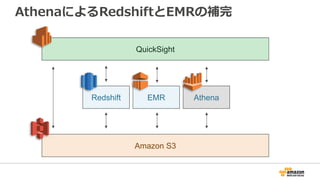
![Athena のクエリ
• Presto と同様,標準 ANSI SQL に準拠したクエリ
• WITH句,Window関数,JOINなどに対応
• Presto で⽤意されている関数は,基本的に使⽤可能
[ WITH with_query [, ...] ]
SELECT [ ALL | DISTINCT ] select_expression [, ...]
[ FROM from_item [, ...] ]
[ WHERE condition ]
[ GROUP BY [ ALL | DISTINCT ] grouping_element [, ...] ]
[ HAVING condition ]
[ UNION [ ALL | DISTINCT ] union_query ]
[ ORDER BY expression [ ASC | DESC ] [ NULLS FIRST | NULLS LAST] [, ...] ]
[ LIMIT [ count | ALL ] ]](https://image.slidesharecdn.com/awsdatabaseupdate-public-170424084629/85/AWS-2017-50-320.jpg)





























![[AWS Start-up ゼミ] よくある課題を一気に解説!〜御社の技術レベルがアップする 2017 夏期講習〜](https://cdn.slidesharecdn.com/ss_thumbnails/awsstartupzemi-2017summer-170816032526-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[Black Belt Online Seminar] AWS上でのログ管理](https://cdn.slidesharecdn.com/ss_thumbnails/aws-log-mgmt-161201043056-thumbnail.jpg?width=640&height=640&fit=bounds)











![[PGConf.ASIA 2018]Deep Dive on Amazon Aurora with PostgreSQL Compatibility](https://cdn.slidesharecdn.com/ss_thumbnails/20181212pgconfasiaaurorapostgresql-181212055637-thumbnail.jpg?width=640&height=640&fit=bounds)

![[MANABIYA] 20180323 Amazon Aurora with PostgreSQL Compatibility](https://cdn.slidesharecdn.com/ss_thumbnails/20180323manabiyaaurorapostgresql-180323071750-thumbnail.jpg?width=640&height=640&fit=bounds)





![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Deep Dive]Infra寄りのDevがお送りするRDS for Aurora徹底検証](https://cdn.slidesharecdn.com/ss_thumbnails/auroradeep-150322203758-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
