Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Amazon Web Services Japan
PDF, PPTX
3,420 views
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法 登壇者名・社名 大谷 晋平(アマゾン データ サービス ジャパン 株式会社)
Read more
4
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 80
2
/ 80
3
/ 80
4
/ 80
5
/ 80
6
/ 80
7
/ 80
8
/ 80
9
/ 80
10
/ 80
11
/ 80
12
/ 80
13
/ 80
14
/ 80
15
/ 80
16
/ 80
17
/ 80
18
/ 80
19
/ 80
20
/ 80
21
/ 80
22
/ 80
23
/ 80
24
/ 80
25
/ 80
26
/ 80
27
/ 80
28
/ 80
29
/ 80
30
/ 80
31
/ 80
32
/ 80
33
/ 80
34
/ 80
35
/ 80
36
/ 80
37
/ 80
38
/ 80
39
/ 80
40
/ 80
41
/ 80
42
/ 80
43
/ 80
44
/ 80
45
/ 80
46
/ 80
47
/ 80
48
/ 80
49
/ 80
50
/ 80
51
/ 80
52
/ 80
53
/ 80
54
/ 80
55
/ 80
56
/ 80
57
/ 80
58
/ 80
59
/ 80
60
/ 80
61
/ 80
62
/ 80
63
/ 80
64
/ 80
65
/ 80
66
/ 80
67
/ 80
68
/ 80
69
/ 80
70
/ 80
71
/ 80
72
/ 80
73
/ 80
74
/ 80
75
/ 80
76
/ 80
77
/ 80
78
/ 80
79
/ 80
80
/ 80
More Related Content
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
PDF
ビックデータ最適解とAWSにおける新しい武器
by
Akihiro Kuwano
PDF
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
PDF
AWSでのビッグデータ分析
by
Amazon Web Services Japan
PDF
Apache Arrow Flight – ビッグデータ用高速データ転送フレームワーク #dbts2021
by
Kouhei Sutou
PDF
Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)
by
Amazon Web Services Japan
PDF
Spark Streaming + Amazon Kinesis
by
Yuta Imai
PDF
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
ビックデータ最適解とAWSにおける新しい武器
by
Akihiro Kuwano
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
AWSでのビッグデータ分析
by
Amazon Web Services Japan
Apache Arrow Flight – ビッグデータ用高速データ転送フレームワーク #dbts2021
by
Kouhei Sutou
Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)
by
Amazon Web Services Japan
Spark Streaming + Amazon Kinesis
by
Yuta Imai
Amazon Kinesis Familyを活用したストリームデータ処理
by
Amazon Web Services Japan
What's hot
PDF
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
ソーシャルゲームのEMR活用事例
by
知教 本間
PPTX
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
PDF
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
PDF
AWS Lambda のご紹介 2015 JAWS沖縄
by
Toshiaki Enami
PDF
個人的にAmazon EMR5.0.0でSpark 2.0を使ってZeppelinでSQL集計してみる
by
Eiji Shinohara
PDF
re:invent 2018 analytics関連アップデート
by
Satoru Ishikawa
PDF
Awsで作るビッグデータ解析今とこれから
by
Shohei Kobayashi
PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
PDF
Amazon Kinesis Analytics によるストリーミングデータのリアルタイム分析
by
Amazon Web Services Japan
PDF
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
PDF
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
PDF
Amazon Web Servicesで未来へススメ!
by
Genta Watanabe
PDF
Pydata Amazon Kinesisのご紹介
by
Toshiaki Enami
PPTX
スケーラブルな Deep Leaning フレームワーク "Apache MXNet” を AWS で学ぶ
by
Amazon Web Services Japan
PDF
Serverless analytics on aws
by
Amazon Web Services Japan
PDF
[F.O.XMeetup#2]インフラ業務を開発エンジニアへ移譲して_2年間の軌跡_
by
Takahiro Moteki
PDF
AWS Summit Chicago 2016発表のサービスアップデートまとめ
by
Amazon Web Services Japan
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
AWSで作る分析基盤
by
Yu Otsubo
ソーシャルゲームのEMR活用事例
by
知教 本間
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
Amazon Elastic MapReduceやSparkを中心とした社内の分析環境事例とTips
by
yuichi_komatsu
AWS Lambda のご紹介 2015 JAWS沖縄
by
Toshiaki Enami
個人的にAmazon EMR5.0.0でSpark 2.0を使ってZeppelinでSQL集計してみる
by
Eiji Shinohara
re:invent 2018 analytics関連アップデート
by
Satoru Ishikawa
Awsで作るビッグデータ解析今とこれから
by
Shohei Kobayashi
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce
by
Amazon Web Services Japan
Amazon Kinesis Analytics によるストリーミングデータのリアルタイム分析
by
Amazon Web Services Japan
クラウド上のデータ活用デザインパターン
by
Amazon Web Services Japan
20120319 aws meister-reloaded-s3
by
Amazon Web Services Japan
Amazon Web Servicesで未来へススメ!
by
Genta Watanabe
Pydata Amazon Kinesisのご紹介
by
Toshiaki Enami
スケーラブルな Deep Leaning フレームワーク "Apache MXNet” を AWS で学ぶ
by
Amazon Web Services Japan
Serverless analytics on aws
by
Amazon Web Services Japan
[F.O.XMeetup#2]インフラ業務を開発エンジニアへ移譲して_2年間の軌跡_
by
Takahiro Moteki
AWS Summit Chicago 2016発表のサービスアップデートまとめ
by
Amazon Web Services Japan
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
Viewers also liked
PDF
PushMaker iBeacon位置連携ソリューション
by
株式会社エスパステクノロジー(ESPACE TECHNOLOGY,Inc.)
PDF
クラウドの力を引き出すクニエのHinemosソリューション
by
Hinemos
PDF
オンラインゲームソリューション@トレジャーデータ
by
Takahiro Inoue
PDF
iBeacon端末を使うインドアナビゲーション WAYFINDERソリューション
by
CRI Japan, Inc.
PDF
OSSを活用して進化しつづける IBMクラウドとコグニティグ・ ソリューションIBM Watsonの最新情報
by
岬 宇藤
PDF
リクルートにおけるVDI導入とCiscoデータセンタソリューション
by
Recruit Technologies
PPTX
【ITソリューション塾・特別講義】Security Fundamentals/2017.5
by
Masanori Saito
PushMaker iBeacon位置連携ソリューション
by
株式会社エスパステクノロジー(ESPACE TECHNOLOGY,Inc.)
クラウドの力を引き出すクニエのHinemosソリューション
by
Hinemos
オンラインゲームソリューション@トレジャーデータ
by
Takahiro Inoue
iBeacon端末を使うインドアナビゲーション WAYFINDERソリューション
by
CRI Japan, Inc.
OSSを活用して進化しつづける IBMクラウドとコグニティグ・ ソリューションIBM Watsonの最新情報
by
岬 宇藤
リクルートにおけるVDI導入とCiscoデータセンタソリューション
by
Recruit Technologies
【ITソリューション塾・特別講義】Security Fundamentals/2017.5
by
Masanori Saito
Similar to ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
PDF
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
PDF
Amazon Web Services 最新事例集
by
SORACOM, INC
PDF
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
PDF
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
PDF
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
はじめてのAWS - ビギナー編 -
by
SORACOM, INC
PDF
20120409 aws meister-reloaded-dynamo-db
by
Amazon Web Services Japan
PDF
はじめてのAmazon Web Services
by
SORACOM, INC
PDF
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
PDF
AWSクラウドサービスツアー
by
a-hisame
PPTX
20111215_第1回EMR勉強会発表資料
by
Kotaro Tsukui
PPTX
NoSQL on AWSで作る最新ソーシャルゲームアーキテクチャ
by
Yasuhiro Matsuo
PDF
次世代ディザスタリカバリを成功させるアマゾンクラウド活用法
by
SORACOM, INC
PDF
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
PDF
Amazon Web Servicesのご紹介 - 東北クラウド実践カンファレンス2011
by
SORACOM, INC
PPTX
MongoDB on AWSクラウドという選択
by
Yasuhiro Matsuo
PPTX
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
Kenta Suzuki
PDF
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
PDF
エンターテイメント業界におけるAWS活用事例
by
Amazon Web Services Japan
AWS初心者向けWebinar AWSでBig Data活用
by
Amazon Web Services Japan
Amazon Web Services 最新事例集
by
SORACOM, INC
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
VOYAGE GROUP
AWS Elastic MapReduce詳細 -ほぼ週刊AWSマイスターシリーズ第10回-
by
SORACOM, INC
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
はじめてのAWS - ビギナー編 -
by
SORACOM, INC
20120409 aws meister-reloaded-dynamo-db
by
Amazon Web Services Japan
はじめてのAmazon Web Services
by
SORACOM, INC
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
AWSクラウドサービスツアー
by
a-hisame
20111215_第1回EMR勉強会発表資料
by
Kotaro Tsukui
NoSQL on AWSで作る最新ソーシャルゲームアーキテクチャ
by
Yasuhiro Matsuo
次世代ディザスタリカバリを成功させるアマゾンクラウド活用法
by
SORACOM, INC
AWS Black Belt Techシリーズ Amazon EMR
by
Amazon Web Services Japan
Amazon Web Servicesのご紹介 - 東北クラウド実践カンファレンス2011
by
SORACOM, INC
MongoDB on AWSクラウドという選択
by
Yasuhiro Matsuo
Jenkinsとhadoopを利用した継続的データ解析環境の構築
by
Kenta Suzuki
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編
by
Kotaro Tsukui
エンターテイメント業界におけるAWS活用事例
by
Amazon Web Services Japan
More from Amazon Web Services Japan
PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
PPTX
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法
1.
ビッグデータの3つのVと4つの プロセスを支えるAWS活用法 アマゾンデータサービスジャパン
ソリューションアーキテクト 大谷 晋平 (ohtani@amazon.co.jp)
2.
WIFIおよびハッシュタグ WiFi
access # hashtag Network:awssummit #AWSTokyo Password:awstokyo
3.
自己紹介 大谷 晋平(おおたに しんぺい) アマゾンデータサービスジャパン •
お客様がAWSクラウドを最適に使えるように、 お手伝いをするお仕事をしています • ソリューションアーキテクト ソーシャルネットワーク(連絡先) • Twitter: @shot6 • Facebook: facebook.com/shot6 • Mail: ohtani@amazon.co.jp
4.
自己紹介(続き) 経歴 • 金融エンジニア • →ITアーキテクト •
→ソリューションアーキテクト(←イマココ) 執筆
5.
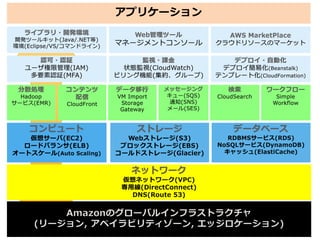
アジェンダ AWSのおさらい ビッグデータとは何か? 事例に学ぶビッグデータ活用 ビッグデータアーキテクチャ まとめ
6.
AWSのおさらい
8.
ビッグデータとは
何か?
9.
amazon.co.jp, today
10.
amazon.co.jp, today
11.
ビッグデータ?
12.
ビッグデータ =データ量??
13.
ビッグデータ =3つのV
14.
1つ目のV Volume (データ量)
15.
そもそもデータ量はなぜ増えるか? • デバイス数の増加・高機能化 • パーソナライゼーション
• 各ユーザ毎の動向・リコメンデーション • ビジネスメトリクスの確保 • 低価格Webストレージの出現 • 桁違いの量の補完が実現可能に
16.
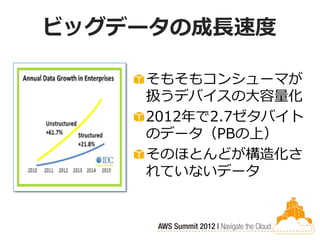
ビッグデータの成長速度
そもそもコンシューマが 扱うデバイスの大容量化 2012年で2.7ゼタバイト のデータ(PBの上) そのほとんどが構造化さ れていないデータ
17.
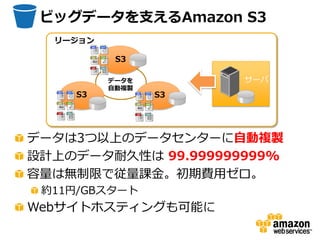
ビッグデータを支えるAmazon S3
リージョン S3 データを 1 サーバ 自動複製 S3 S3 データは3つ以上のデータセンターに自動複製 設計上のデータ耐久性は 99.999999999% 容量は無制限で従量課金。初期費用ゼロ。 約11円/GBスタート Webサイトホスティングも可能に
18.
Amazon S3のコンセプト 堅牢
常時利用可能 スケーラブル 安全・安心 高速 シンプル 従量課金・低価格 EASY!
19.
2つ目のV Velocity (データ到達速度)
20.
・エンドユーザはデバイスの多様化、 高機能化によって、あらゆるシーンに おいてITを利用 ・マシンが直接生成するデータも増加
=データの生成速度があがった =データがビジネスのライフライン
21.
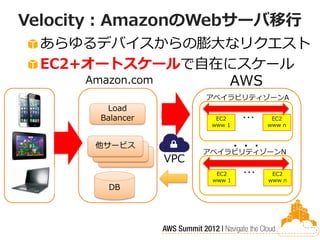
Velocity:AmazonのWebサーバ移行 あらゆるデバイスからの膨大なリクエスト EC2+オートスケールで自在にスケール
Amazon.com AWS アベイラビリティゾーンA Load Balancer EC2 www 1 … EC2 www n 他サービス ・・・ アベイラビリティゾーンN VPC EC2 www 1 … EC2 www n DB
22.
3つ目のV Variety (データの種類)
24.
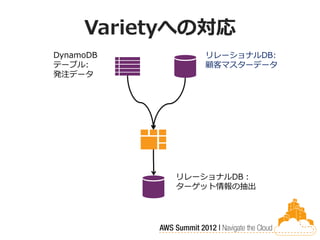
Varietyへの対応 DynamoDB
リレーショナルDB: テーブル: 顧客マスターデータ 発注データ リレーショナルDB: ターゲット情報の抽出
25.
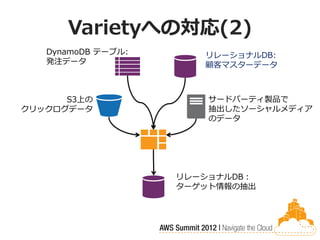
Varietyへの対応(2)
DynamoDB テーブル: リレーショナルDB: 発注データ 顧客マスターデータ S3上の サードパーティ製品で クリックログデータ 抽出したソーシャルメディア のデータ リレーショナルDB: ターゲット情報の抽出
26.
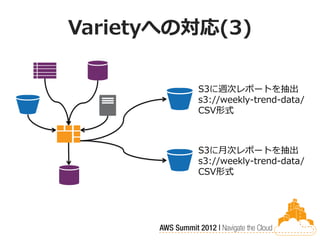
Varietyへの対応(3)
S3に週次レポートを抽出 s3://weekly-trend-data/ CSV形式 S3に月次レポートを抽出 s3://weekly-trend-data/ CSV形式
27.
事実:AWSではビッグデータに対応する様々な インフラストラクチャサービスを展開しています
Dynamo DB S3 EMRのクラスタ RDS EC2上のデータ ウェアハウス インフラやアプリケー ション監視 サードパーティの データセット
28.
BIG DATA 4つのプロセス
1.収集 2.保存 3.分析 4.共有
29.
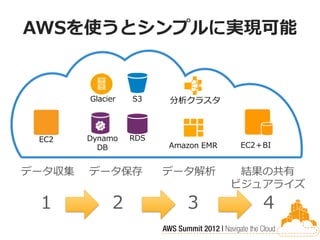
AWSを使うとシンプルに実現可能
Glacier S3 分析クラスタ EC2 Dynamo RDS DB Amazon EMR EC2+BI データ収集 データ保存 データ解析 結果の共有 ビジュアライズ 1 2 3 4
30.
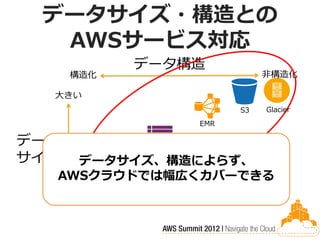
データサイズ・構造との AWSサービス対応
データ構造 構造化 非構造化 大きい S3 Glacier EMR データ Dynamo DB サイズ データサイズ、構造によらず、 AWSクラウドでは幅広くカバーできる RDS 小さい
31.
事例に学ぶ ビッグデータ活用
32.
リクルート様
33.
リクルート様の課題 Suumoでのビジネスニーズの追及 • ユーザの行動分析をすぐにやりたい •
利用者800万ユニークユーザ • ユーザへのレコメンドもすぐにやりたい スピード最優先で進めたい
34.
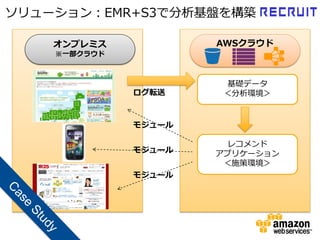
ソリューション:EMR+S3で分析基盤を構築
オンプレミス AWSクラウド ※一部クラウド 基礎データ ログ転送 <分析環境> モジュール レコメンド モジュール アプリケーション <施策環境> モジュール
35.
リクルート様での効果 物件情報のリコメンド • 「この物件見た方はこちらも見ています」 • RDBMSで構築した場合、1日以上→EMRで30分 Webサイトでのユーザ行動分析 •
統計専門家がすぐ開始。リードタイムの劇的短縮 ターゲッティングメルマガ コンバージョン数集計、月次集計 おすすめメンバのリコメンド
36.
Sonet様
37.
Sonet様の課題 広告分析基盤の構築 • データ量は増え続ける • 初期費用がかかりすぎる データ量が増えても、スケールさせたい 人材は自社メンバだけでやりたい
38.
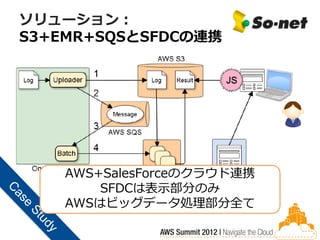
ソリューション: S3+EMR+SQSとSFDCの連携
AWS+SalesForceのクラウド連携 SFDCは表示部分のみ AWSはビッグデータ処理部分全て
39.
Sonet様での効果 広告配信ログの分析 • 1日平均10GB、年間3.65TB以上 • 1年分5TBをS3アップロードしてEMRで解析 コスト効果 •
オンプレミス試算:初期費用で数千万円単位 • AWSの価格:毎月50万円(年間600万円) • 価格差は20分の1 • EC2スポットインスタンスで、アドホック分析 • 更にコストを50%削減
40.
アンデルセンサービス様
41.
アンデルセンサービス様の課題 原材料からの原価計算バッチが4時間 かかっている • BOM展開、原価積み上げ、組み合わせ爆発 原価計算をもっと頻度高く行いたい • 想定データではなく、実際の数字で •
何回も実施し、原価への影響をみたい
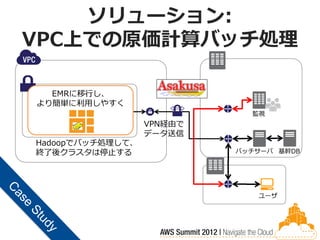
42.
ソリューション: VPC上での原価計算バッチ処理 原価計算バッチ環境(EC2) EMRに移行し、 より簡単に利用しやすく
Hadoop Hadoop Master 監視 Slave EMR VPN経由で データ送信 Hadoopでバッチ処理して、 終了後クラスタは停止する バッチサーバ 基幹DB VPN ユーザ
43.
アンデルセンサービス様での効果 夜間バッチからの解放→業務変革 • データ量は多くないが、組み合わせが膨大 時間的制約からの解放 より新しいチャレンジへ 運用コストの大幅削減 既存データベースの負荷軽減
44.
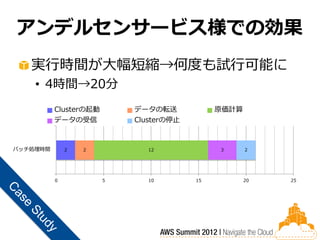
アンデルセンサービス様での効果
実行時間が大幅短縮→何度も試行可能に • 4時間→20分 Clusterの起動 データの転送 原価計算 データの受信 Clusterの停止 バッチ処理時間 2 2 12 3 2 0 5 10 15 20 25
45.
Netflix様
46.
2500万人以上のストリーミング会員
47.
500億以上のイベント
48.
Netflix様の課題 複数の箇所で発生するフォーマットの データを受けきるデータハブの構築 大量に発生するイベントデータの処理 複数の分析方法でどれが良いかをもっと 安価に試したい
49.
Netflix様の課題 複数の箇所で発生するフォーマットの データを受けきるデータハブの構築 大量に発生するイベントデータの処理 複数の分析方法でどれが良いかをもっと 安価に試したい
50.
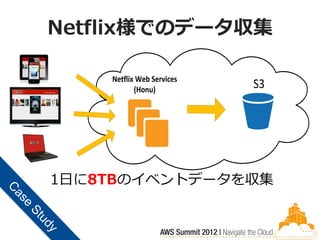
Netflix様でのデータ収集
Netflix Web Services (Honu) S3 1日に8TBのイベントデータを収集
51.
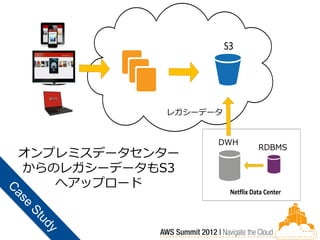
S3
レガシーデータ Data Center DWH RDBMS オンプレミスデータセンター からのレガシーデータもS3 へアップロード Netflix Data Center
52.
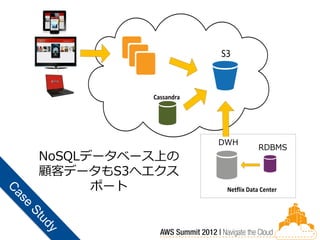
DWH
RDBMS NoSQLデータベース上の 顧客データもS3へエクス ポート
53.
事実:Netflixでは1PB以上のデータを Amazon
S3に保存しています S3
54.
Netflix様の課題 複数の箇所で発生するフォーマットの データを受けきるデータハブの構築 大量に発生するイベントデータの処理 複数の分析方法でどれが良いかをもっと 安価に試したい
55.
Netflix様でのデータ解析
Prod Cluster EMRクラスタ S3 (EMR) EMR HDFS EMRを活用して、 データはすべてS3から提供
56.
Netflix様でのデータ解析
Prod Cluster EMRクラスタ S3 (EMR) EMR HDFS 結果はS3へ書き戻す
57.
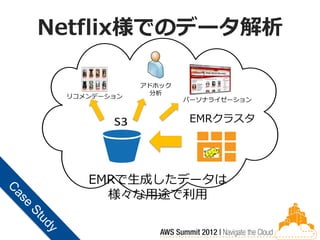
Netflix様でのデータ解析
アドホック 分析 リコメンデーション パーソナライゼーション S3 EMRクラスタ Prod Cluster (EMR) EMR EMRで生成したデータは 様々な用途で利用
58.
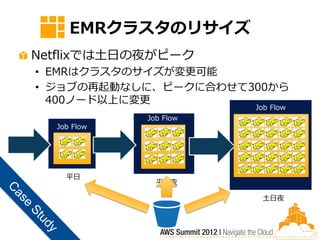
EMRクラスタのリサイズ Netflixでは土日の夜がピーク • EMRはクラスタのサイズが変更可能 • ジョブの再起動なしに、ピークに合わせて300から
400ノード以上に変更 Job Flow Job Flow Job Flow 平日 平日夜 土日夜
59.
Netflix様の課題 複数の箇所で発生するフォーマットの データを受けきるデータハブの構築 大量に発生するイベントデータの処理 複数の分析方法でどれが良いかをもっと 安価に試したい
60.
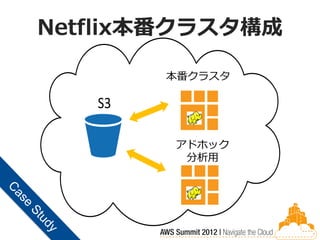
Netflix本番クラスタ構成
Prod Cluster 本番クラスタ (EMR) S3 EMR アドホック Query Cluster 分析用 (EMR) EMR
61.
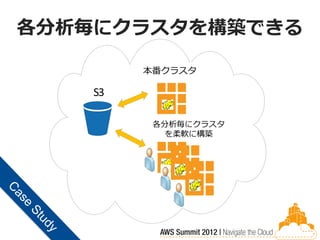
各分析毎にクラスタを構築できる
Prod Cluster 本番クラスタ (EMR ) S3 EMR 各分析毎にクラスタ Query Cluster (を柔軟に構築 EMR ) EMR EMR EMR EMR
62.
Yelp様の事例
63.
スペルミスの
検索ワードの リコメン 自動修正 自動補完 デーション
64.
どこでAWSクラウドが動いているか?
必要なデータ スペルミスの自動修正 月間のユーザ毎の履歴 一般的な間違いの データ Westen Wistin Westan Whestin
65.
YelpのWebサイトログは全てS3で保管
Amazon S3 月間のユーザ検索データ 検索用語 ミススペルデータ クリックデータ
66.
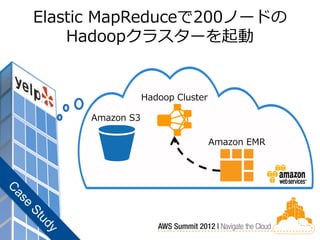
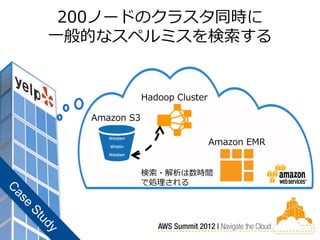
Elastic MapReduceで200ノードの
Hadoopクラスターを起動 Hadoop Cluster Amazon S3 Amazon EMR
67.
200ノードのクラスタ同時に 一般的なスペルミスを検索する
Hadoop Cluster Amazon S3 Westen Wistin Amazon EMR Westan 検索・解析は数時間 で処理される
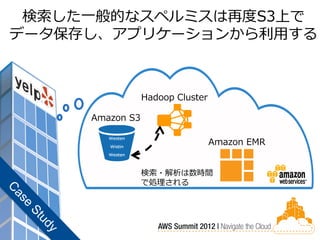
68.
検索した一般的なスペルミスは再度S3上で データ保存し、アプリケーションから利用する
Hadoop Cluster Amazon S3 Westen Wistin Amazon EMR Westan 検索・解析は数時間 で処理される
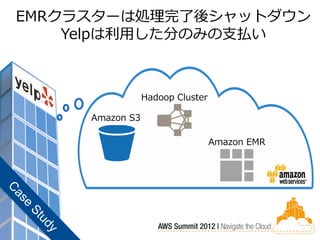
69.
EMRクラスターは処理完了後シャットダウン
Yelpは利用した分のみの支払い Hadoop Cluster Amazon S3 Amazon EMR
70.
での効果 Yelpのエンジニアで、ビッグデータ処理 は日常になった • いつでも、好きな時に、制限なく利用可能 1日400GBのログはS3に保存 • 月間5000万PV、1800万レビューデータ •
データを捨てる必要もない 毎週平均250台のクラスターを利用
71.
ビッグデータ アーキテクチャ
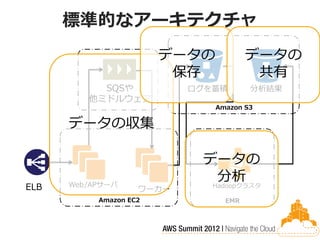
72.
標準的なアーキテクチャ
データの データの 保存 共有 SQSや ログを蓄積 分析結果 他ミドルウェア Amazon S3 データの収集 データの Web/APサーバ 分析 ELB ワーカー Hadoopクラスタ Amazon EC2 EMR
73.
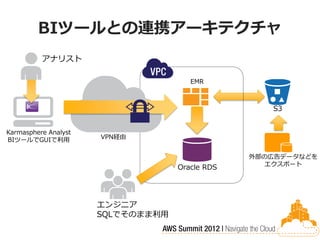
BIツールとの連携アーキテクチャ
アナリスト EMR S3 Karmasphere Analyst BIツールでGUIで利用 VPN経由 外部の広告データなどを エクスポート Oracle RDS エンジニア SQLでそのまま利用
74.
データ中心アーキテクチャ データを中心にコンピュート処理は
S3 データ可視化 データ集約・変換 柔軟に状況に応じて、処理の仕方・ レポーティング 量を変動させる =クラウドがベストフィット ビッグデータ処理部分は ・いつでも実施可能 パーソナライゼーション ・いつでもリサイズ可能 高速バッチ処理 リコメンデーション ・いつでも複製可能 ・揮発・長期どちらも可能
75.
まとめ
76.
ビジネス編まとめ AWSクラウドxビッグデータ=革新 • 3つのV(Volume, Velocity,
Variety) • 4つのプロセス(収集、保存、分析、共有) • AWSクラウドがベストフィット • 従量課金・低コスト・スケール ビッグデータ処理自体も普及期へ • バズワードからの脱却
77.
技術編まとめ 3つのV(Volume, Velocity, Variety) •
Volume:S3のスケーラビリティ • Velocity:EC2+AutoScaling • Variety:S3、RDS、DynamoDB 4つのプロセス(収集、保存、分析、共有) • AWSでは4プロセスを全方位カバー • S3、EC2、EMR、RDS等、柔軟に選択可能 ビッグデータ処理のアーキテクチャが、 確立しつつある
78.
次のアクションは? AWSの始め方 • http://aws.amazon.com/jp/aws-first-step/ AWSクラウドサービス活用 • http://aws.amazon.com/jp/aws-jp-introduction/ お問い合わせ •
http://aws.amazon.com/jp/contact-us/aws-sales/ • ohtani@amazon.co.jp まで
79.
ビッグデータビジネスで ぜひAWSクラウドをご 活用ください! Meet the
SAコーナーでお待ちしています 質問・疑問等ありましたらお気軽にどうぞ!
80.
ご静聴ありがとう ございました!
Download













































































![[F.O.XMeetup#2]インフラ業務を開発エンジニアへ移譲して_2年間の軌跡_](https://cdn.slidesharecdn.com/ss_thumbnails/tittle-180330034333-thumbnail.jpg?width=640&height=640&fit=bounds)













































![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
