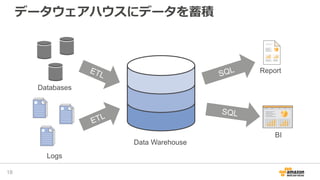
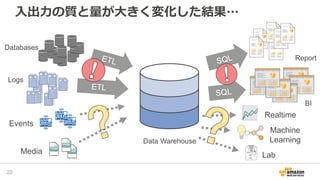
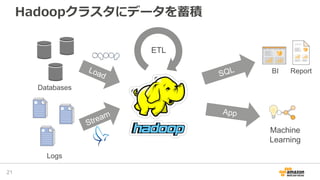
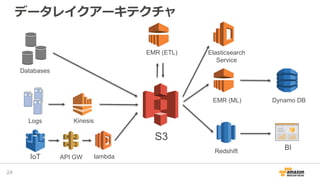
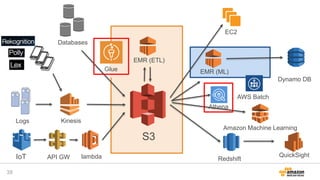
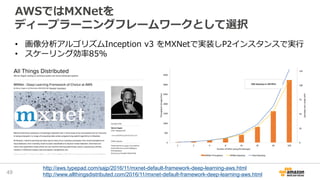
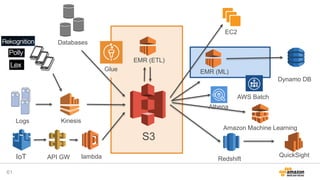
2016/12/17開催「今年もやるよ!ビッグデータオールスターズ -日本を代表するビッグデータエンジニア・マーケターが大集結!- 」での発表資料「データレイクを基盤としたAWS上での機械学習サービス構築」です






































































![[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessiondatalake-191027185852-thumbnail.jpg?width=640&height=640&fit=bounds)







![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)









![[CTO Night & Day 2019] よくある課題を一気に解説!御社の技術レベルがアップする 2019 秋期講習 #ctonight](https://cdn.slidesharecdn.com/ss_thumbnails/ctond2019morningsessionstartupzemifall2019-191028200214-thumbnail.jpg?width=640&height=640&fit=bounds)



















