Introduction
• Supervised learning
Ex)우편번호 인식, 음성 인식, 자동 운전 차량, 그리고 인간의
게놈 유전자 이해에도 도움
한계) input feature를 입력해주어야 함
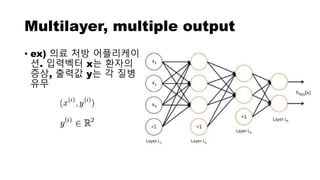
• Unsupervised learning – Autoencoder
분류 안된 데이터에서 특징을 자동으로 학습하는 알고리즘
The best case의 supervised learning 보다는 성능이 낮음
Ex) 음성, 문자 인식에 좋은 성능
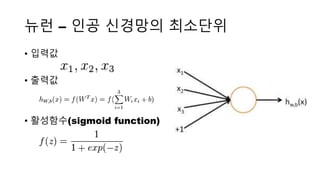
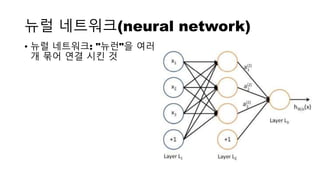
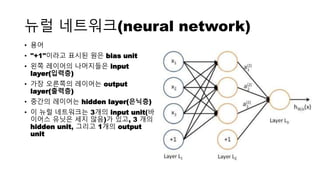
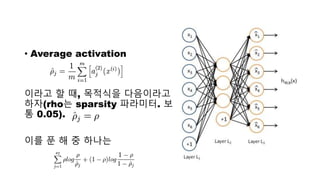
뉴럴 네트워크(neural network)
•용어
• "+1"이라고 표시된 원은 bias unit
• 왼쪽 레이어의 나머지들은 input
layer(입력층)
• 가장 오른쪽의 레이어는 output
layer(출력층)
• 중간의 레이어는 hidden layer(은닉층)
• 이 뉴럴 네트워크는 3개의 input unit(바
이어스 유닛은 세지 않음)가 있고, 3 개의
hidden unit, 그리고 1개의 output
unit
11.
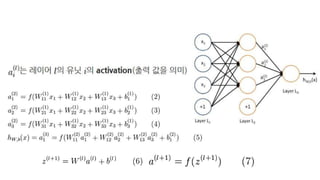
뉴럴 네트워크의 계산순서
• 네트워크의 출력을 계산하려면, 모든 activation을 계산
• 즉 레이어 를 계산하고, 을 계산하고, 까지 식
(6-7)을 써서 완료















































![[모두의연구소] 쫄지말자딥러닝](https://cdn.slidesharecdn.com/ss_thumbnails/20160528-160529034614-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)









