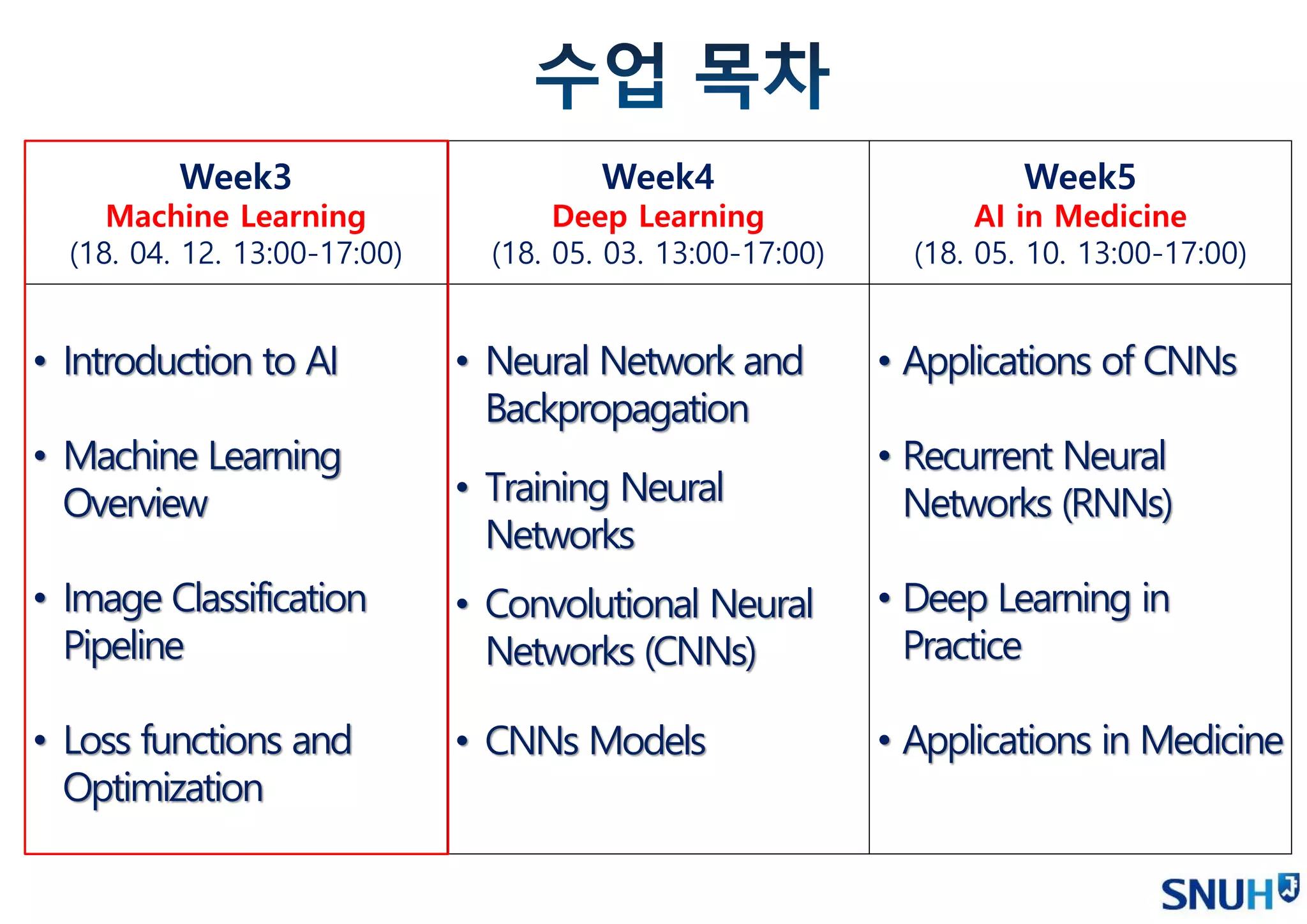
Week3
Machine Learning
(18. 04.12. 13:00-17:00)
Week4
Deep Learning
(18. 05. 03. 13:00-17:00)
Week5
AI in Medicine
(18. 05. 10. 13:00-17:00)
• Introduction to AI
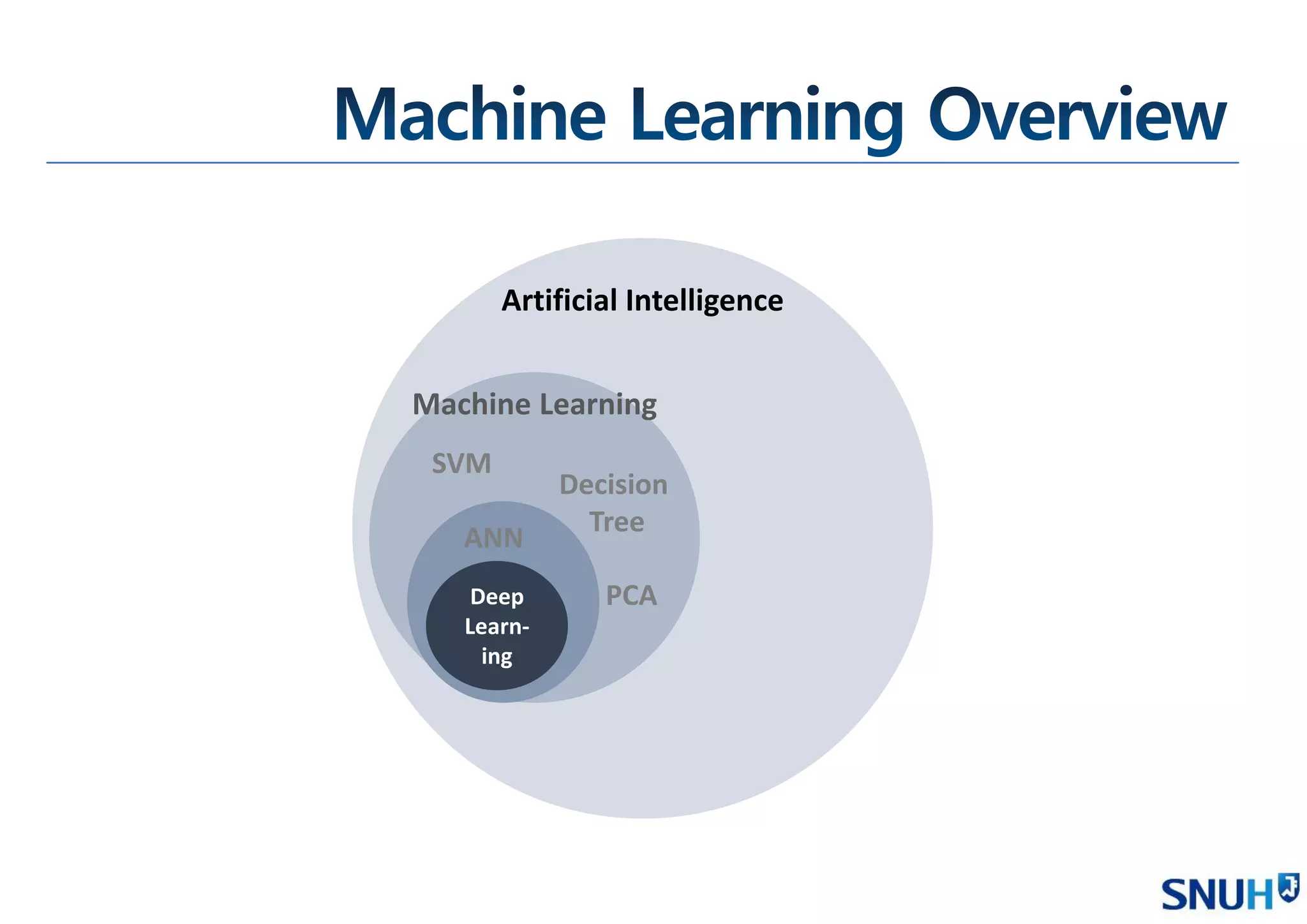
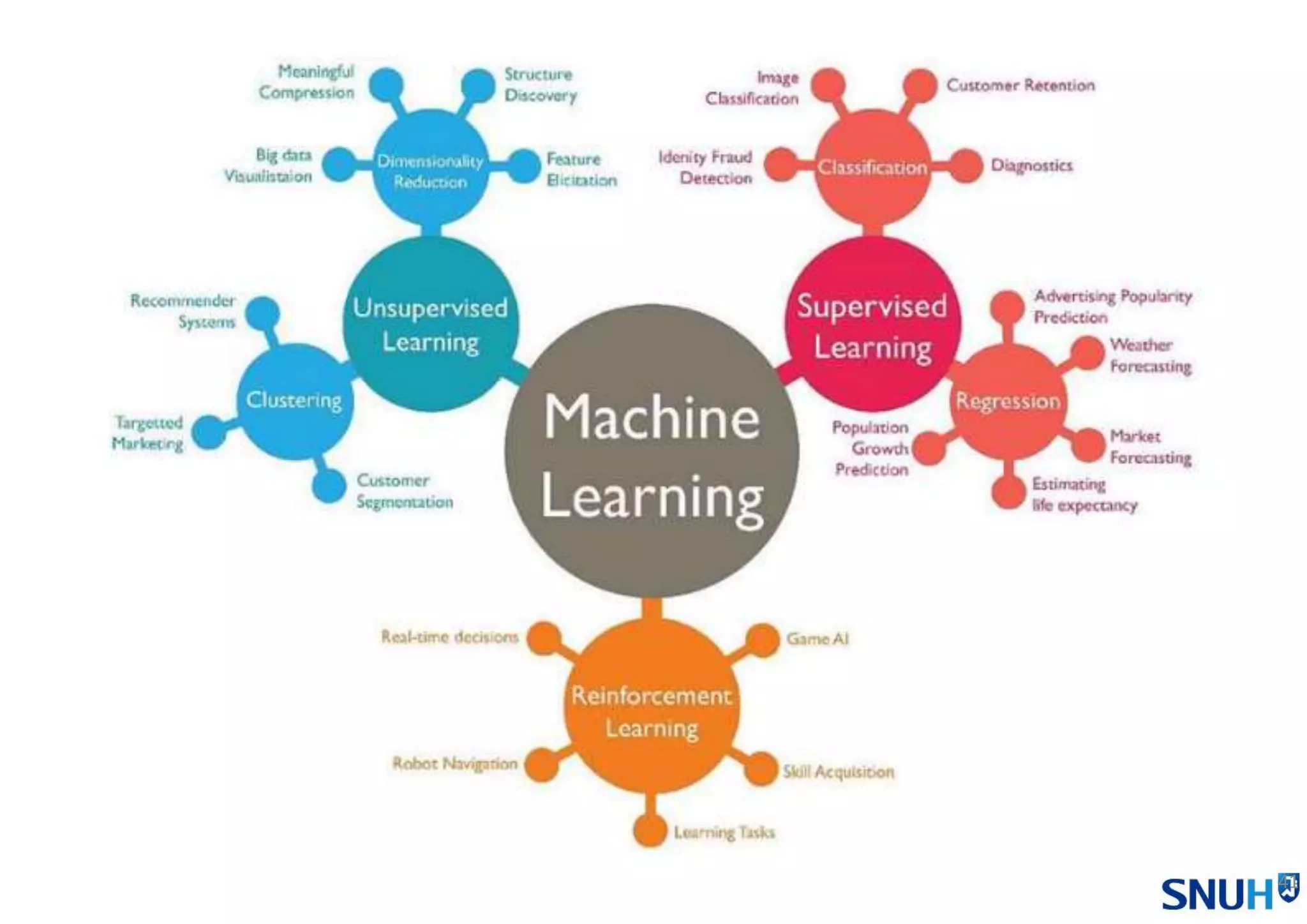
• Machine Learning
Overview
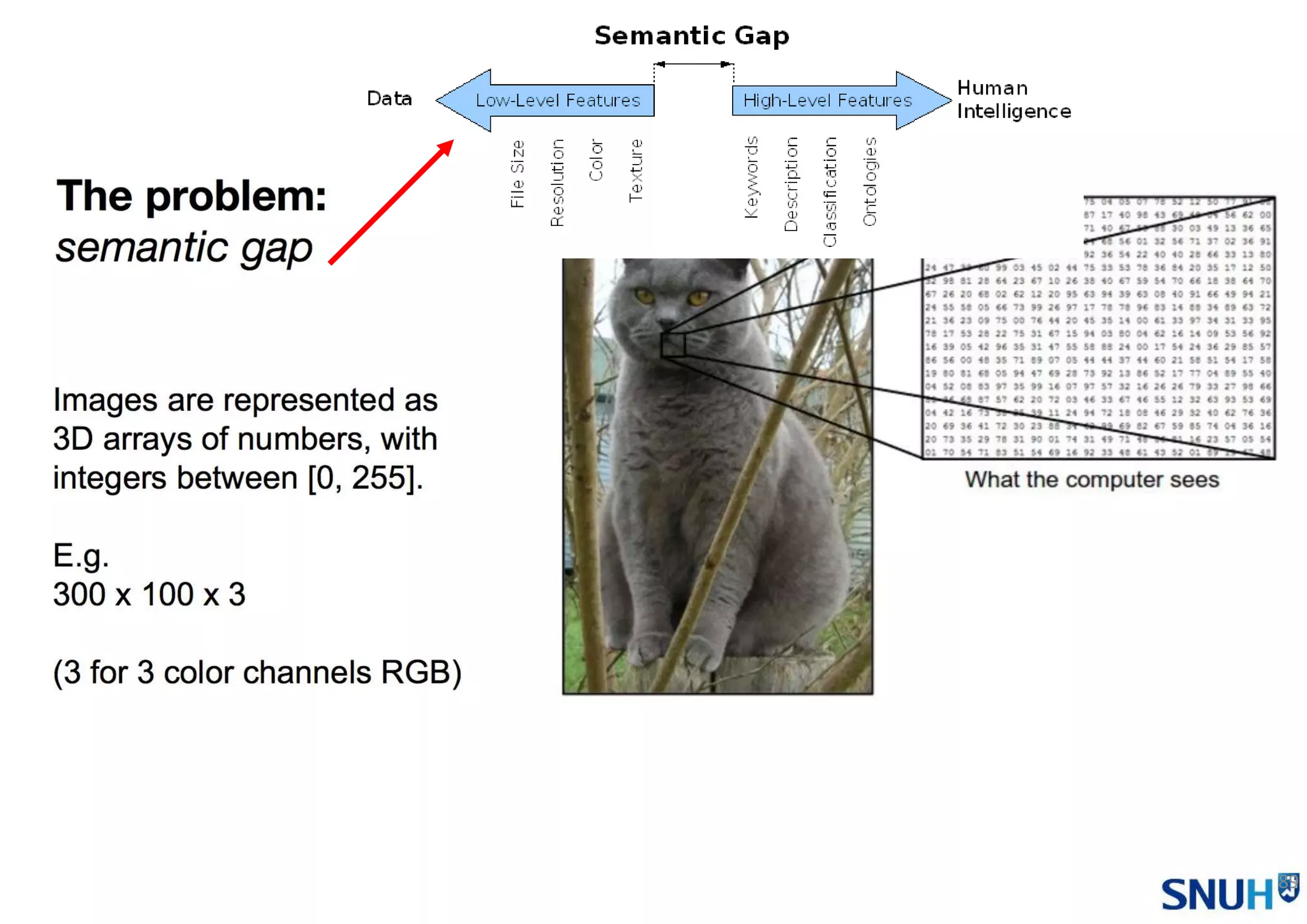
• Image Classification
Pipeline
• Loss functions and
Optimization
• Neural Network and
Backpropagation
• Training Neural
Networks
• Convolutional Neural
Networks (CNNs)
• CNNs Models
• Applications of CNNs
• Recurrent Neural
Networks (RNNs)
• Deep Learning in
Practice
• Applications in Medicine
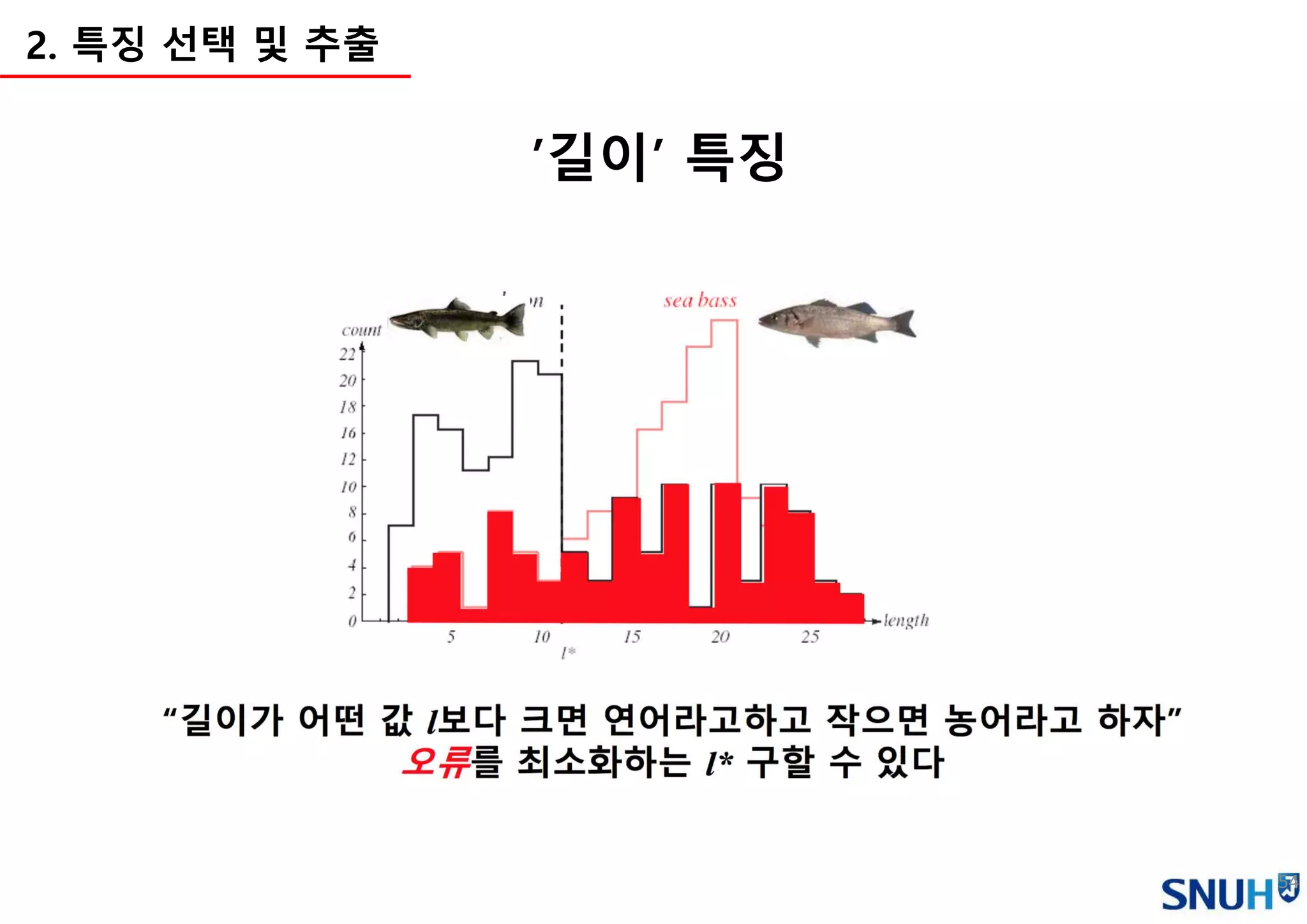
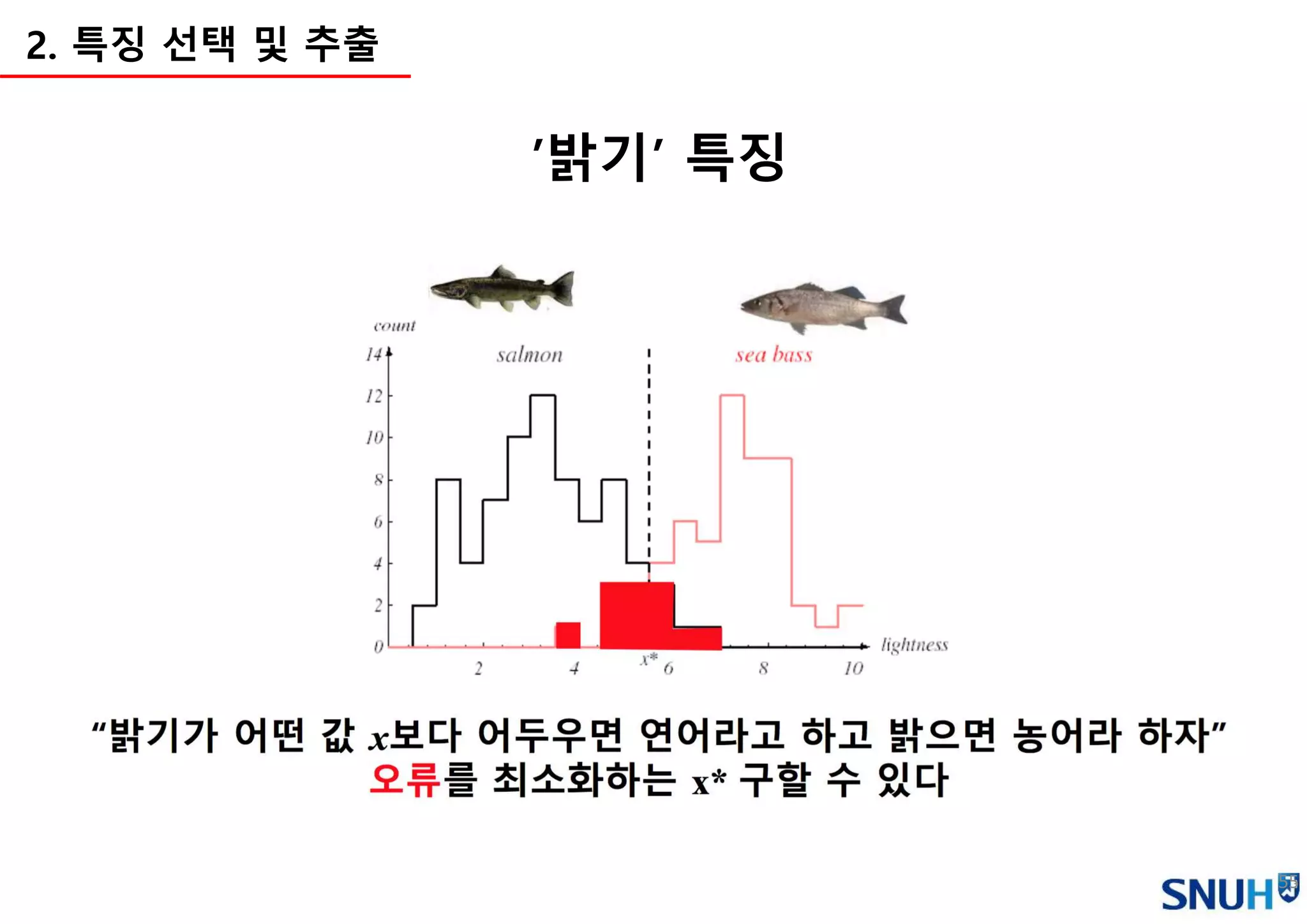
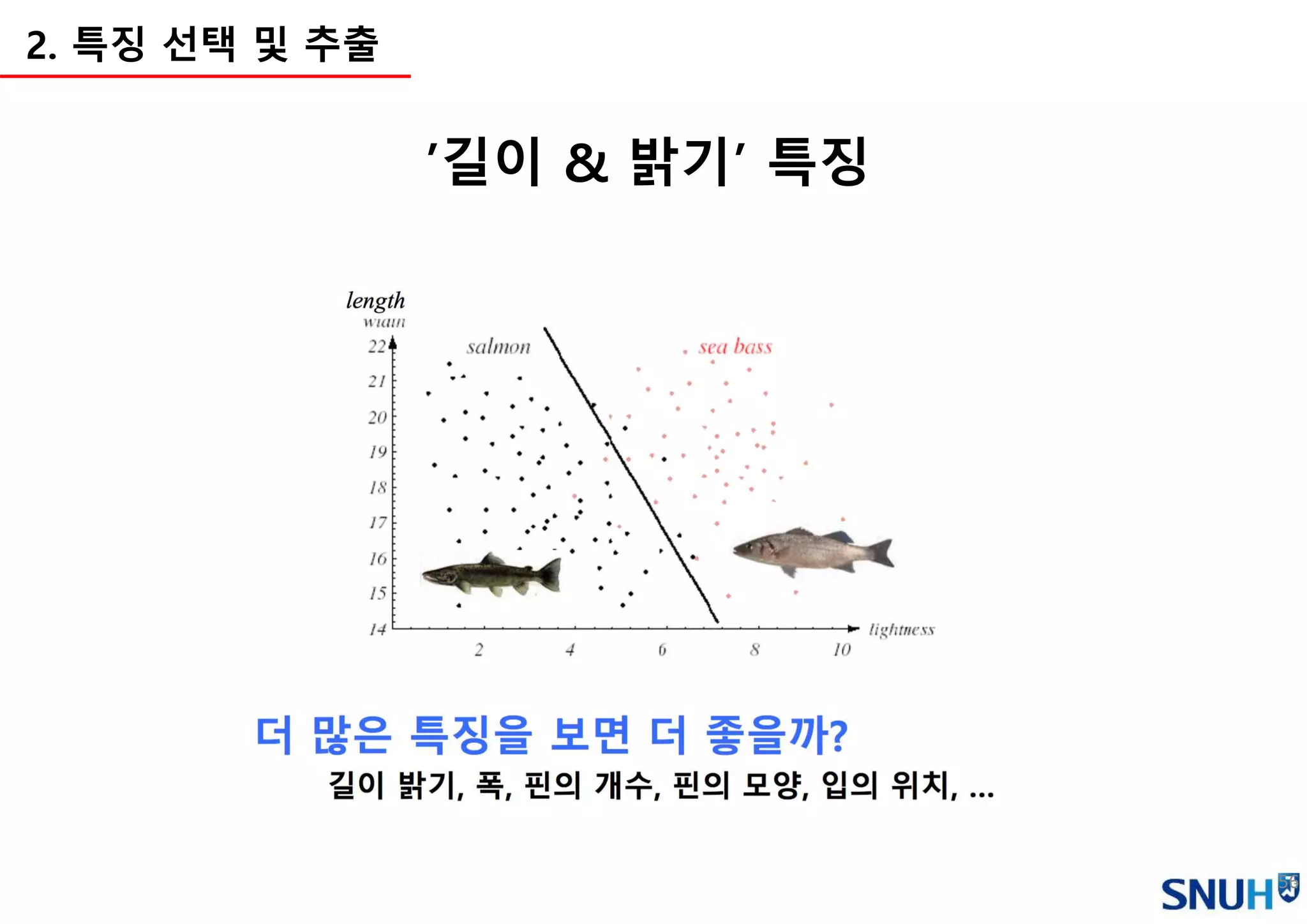
3.
Introduction toAI
Machine Learning Overview
Image Classification Pipeline
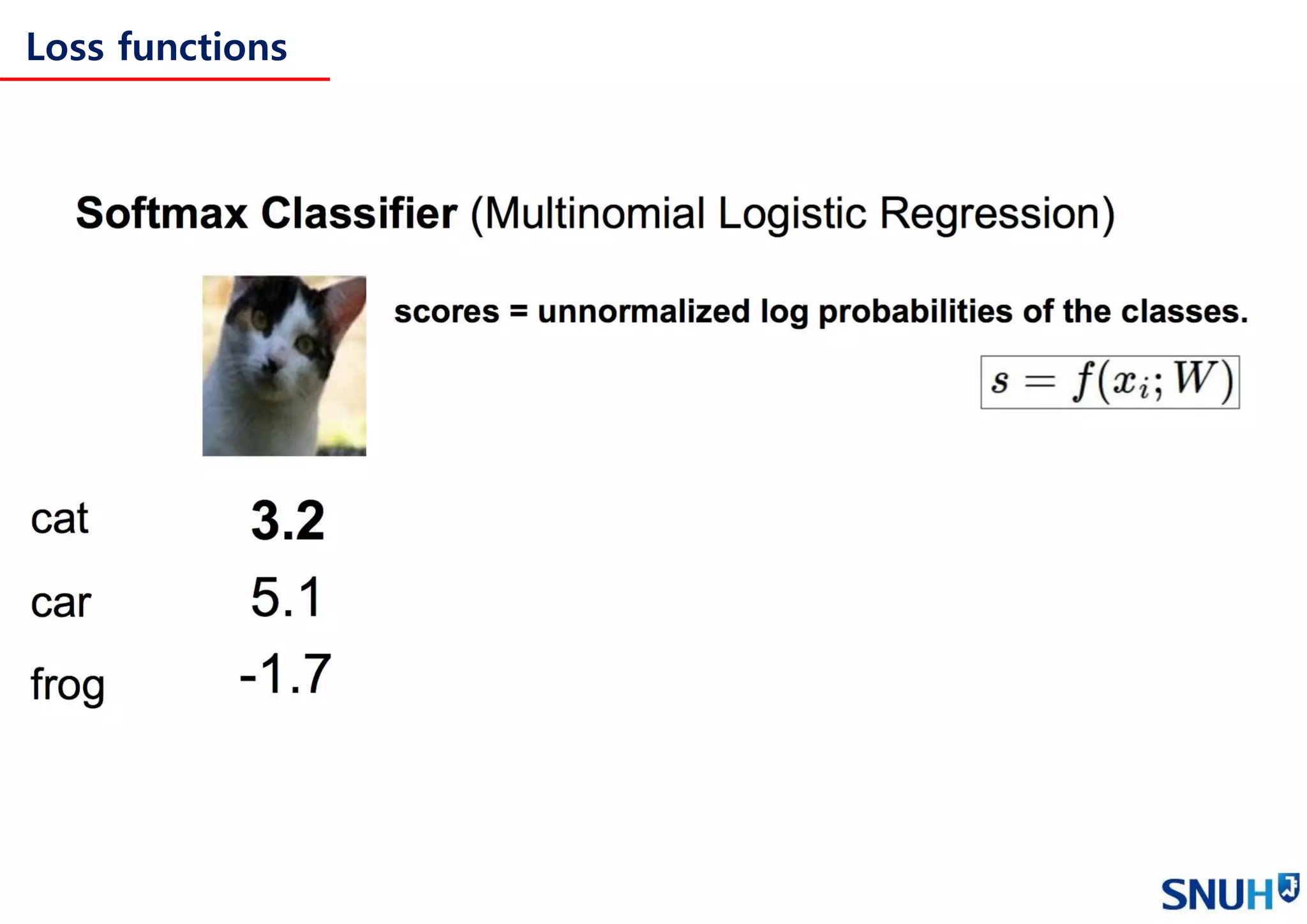
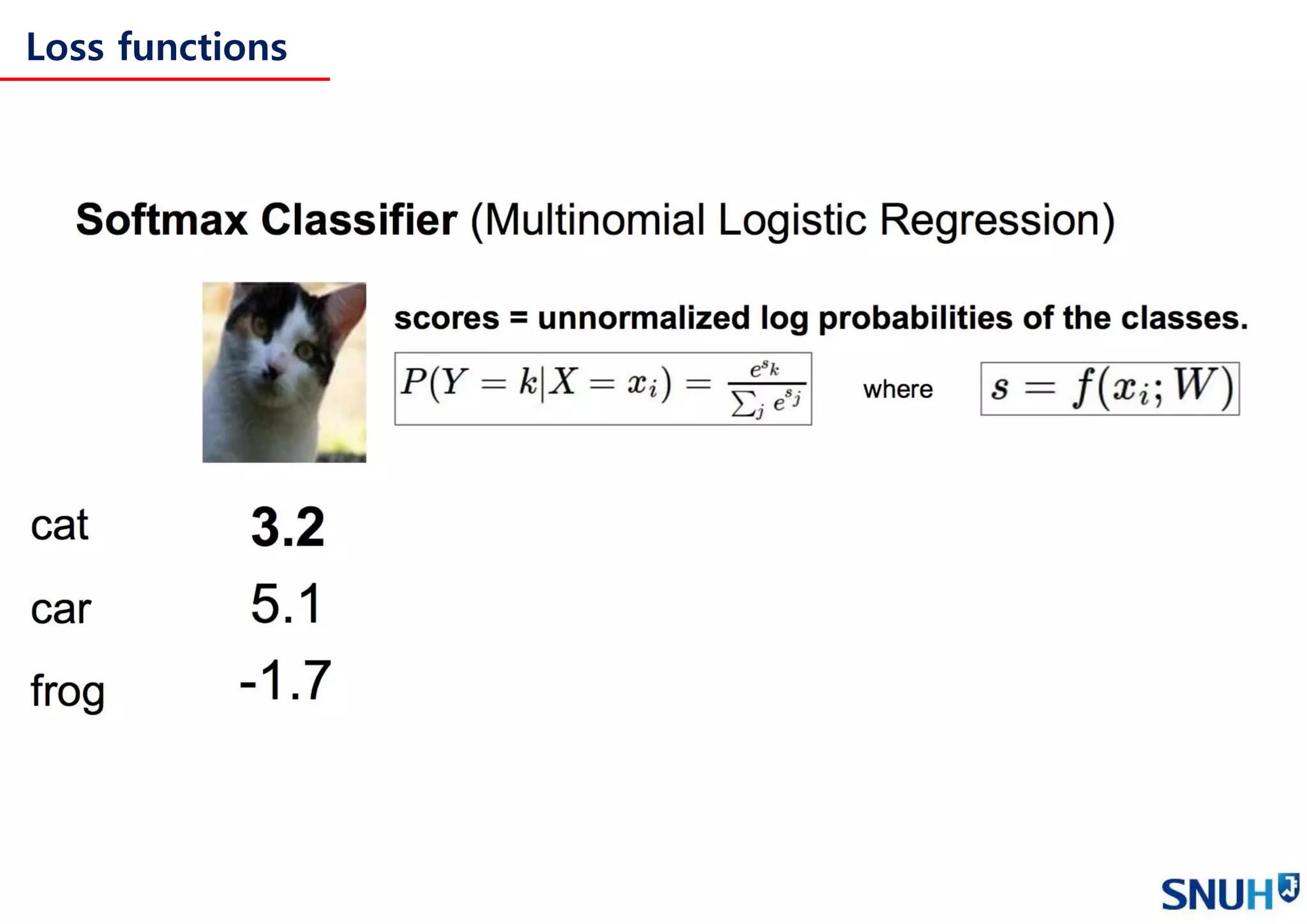
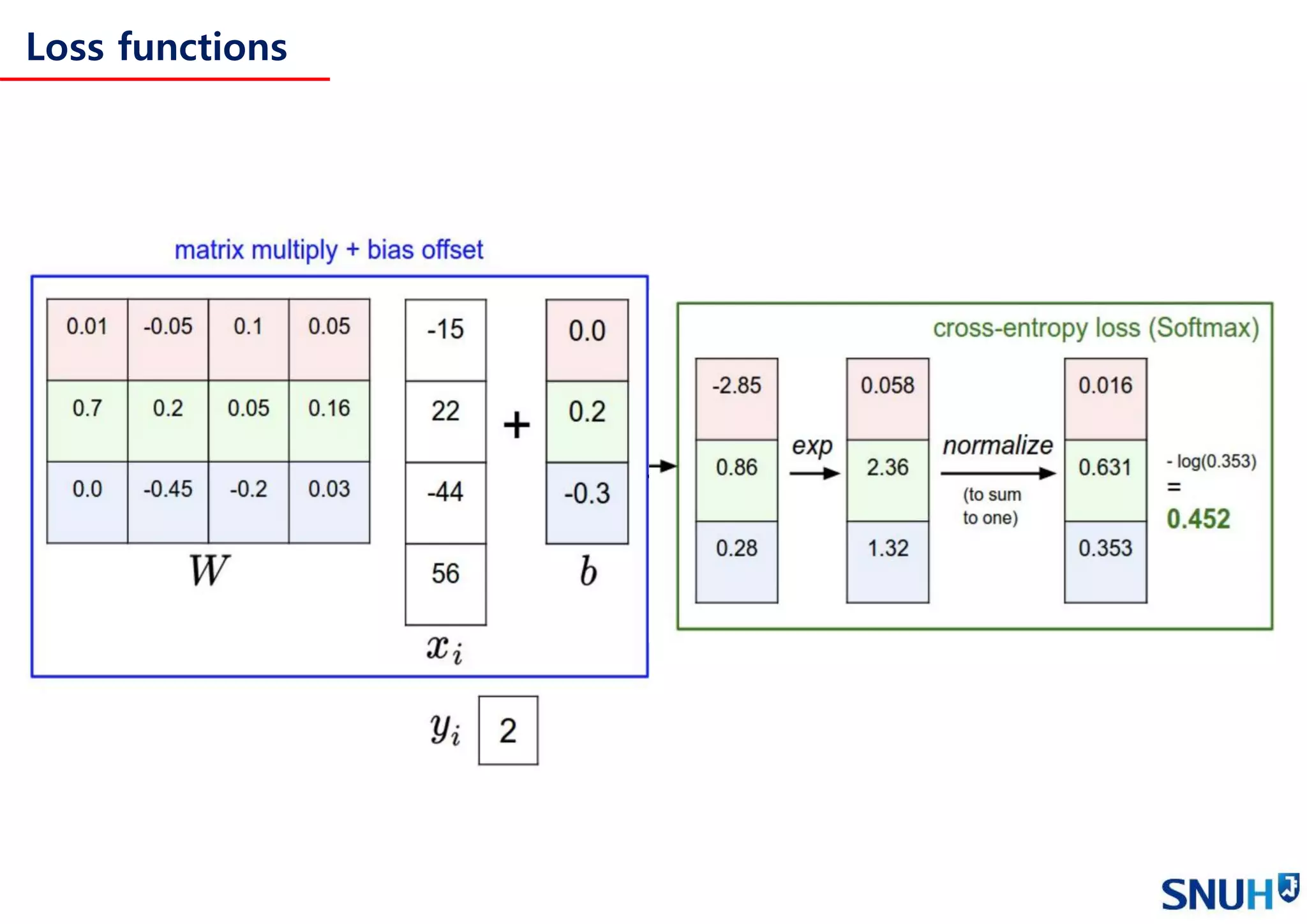
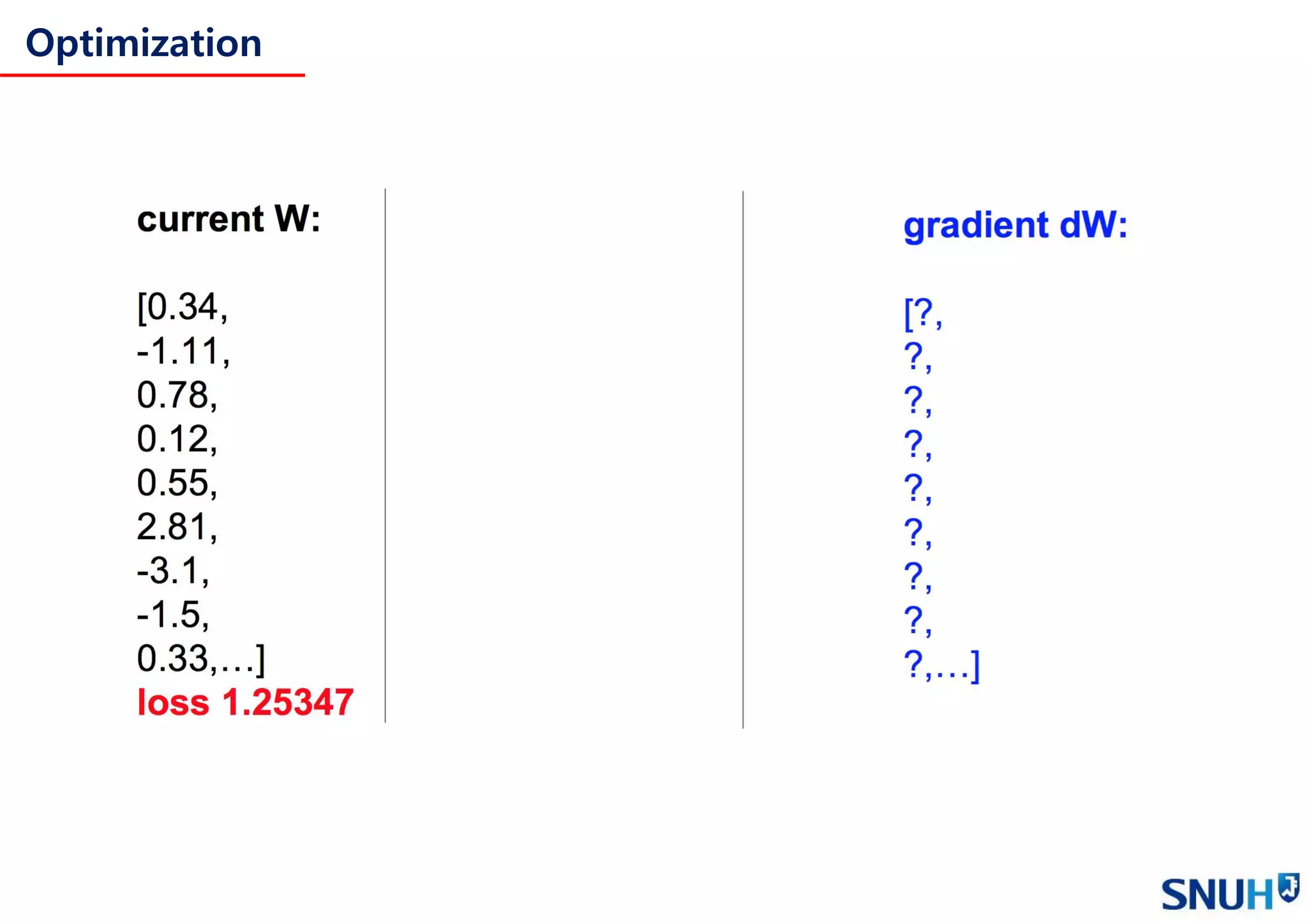
Loss functions and Optimization
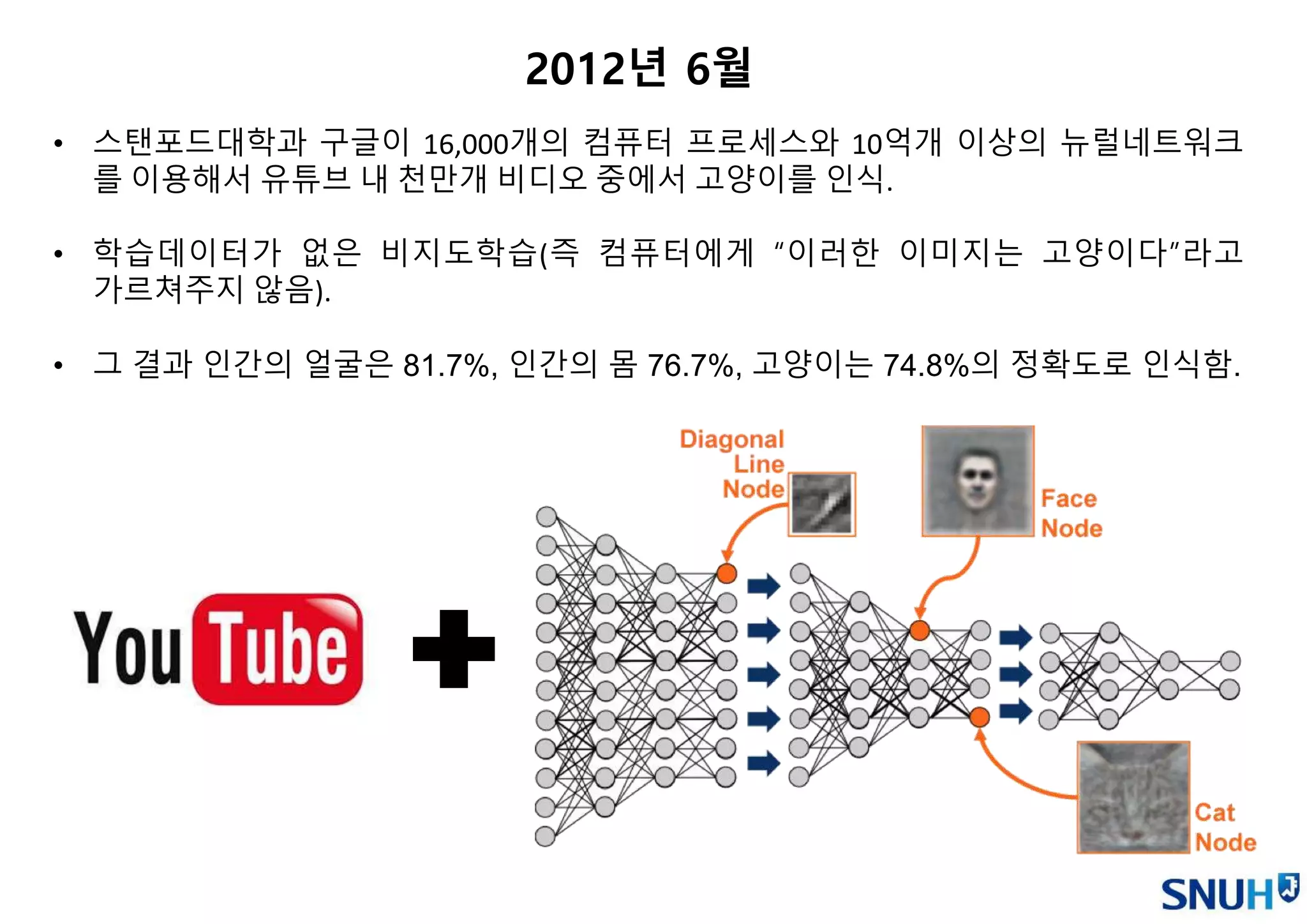
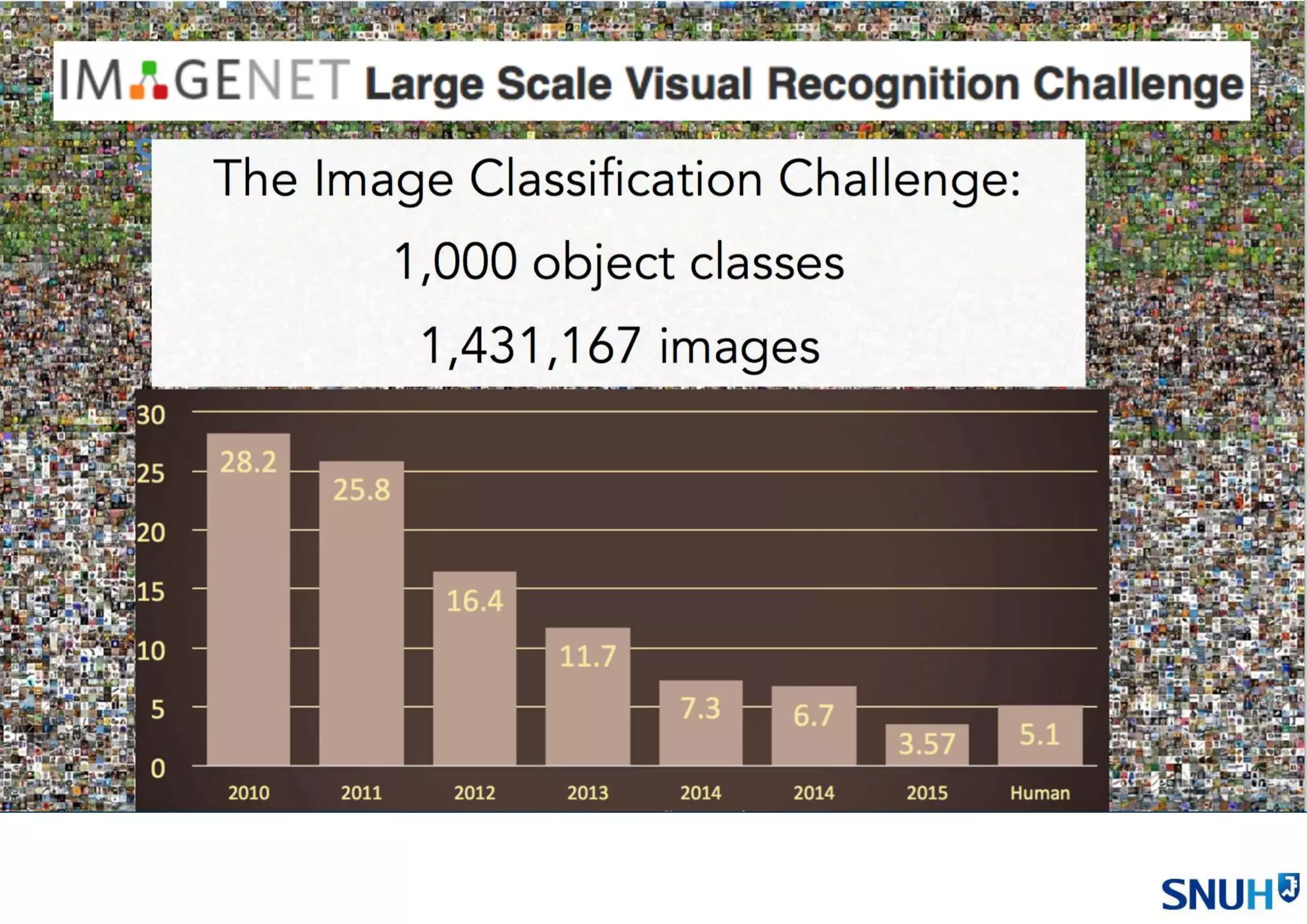
• 스탠포드대학과 구글이16,000개의 컴퓨터 프로세스와 10억개 이상의 뉴럴네트워크
를 이용해서 유튜브 내 천만개 비디오 중에서 고양이를 인식.
• 학습데이터가 없은 비지도학습(즉 컴퓨터에게 “이러한 이미지는 고양이다”라고
가르쳐주지 않음).
• 그 결과 인간의 얼굴은 81.7%, 인간의 몸 76.7%, 고양이는 74.8%의 정확도로 인식함.
2012년 6월
병원명 AI 시스템개발 내용
Lunit과 Chest X-ray 폐암 조기진단
시스템 개발 협력
OBS Korea와 치과용 인공지능 시스템 개발 협력
AI 벤처기업과 심혈관 질환
조기 진단 시스템 개발 협력
VUNO와 폐암 CT 영상 분석 시스템 개발 협력
삼성 메디슨과 초음파를 이용한 유방암
조기 진단 시스템 개발 협력
인공지능 암 치료 개발 사업 추진 예정
암 진단을 위한 IBM Watson 도입
지능형 의료 안내 로봇 개발
국내 주요 병원 AI 기술 개발 현황 (2017년 기준)
Reason 1. Humanswill always maintain ultimate responsibility.
Reason 2. Radiologists don’t just look at images.
Reason 3. Productivity gains will drive demand.
Why AI will not replace radiologists?
Doctors?
Doctors
39
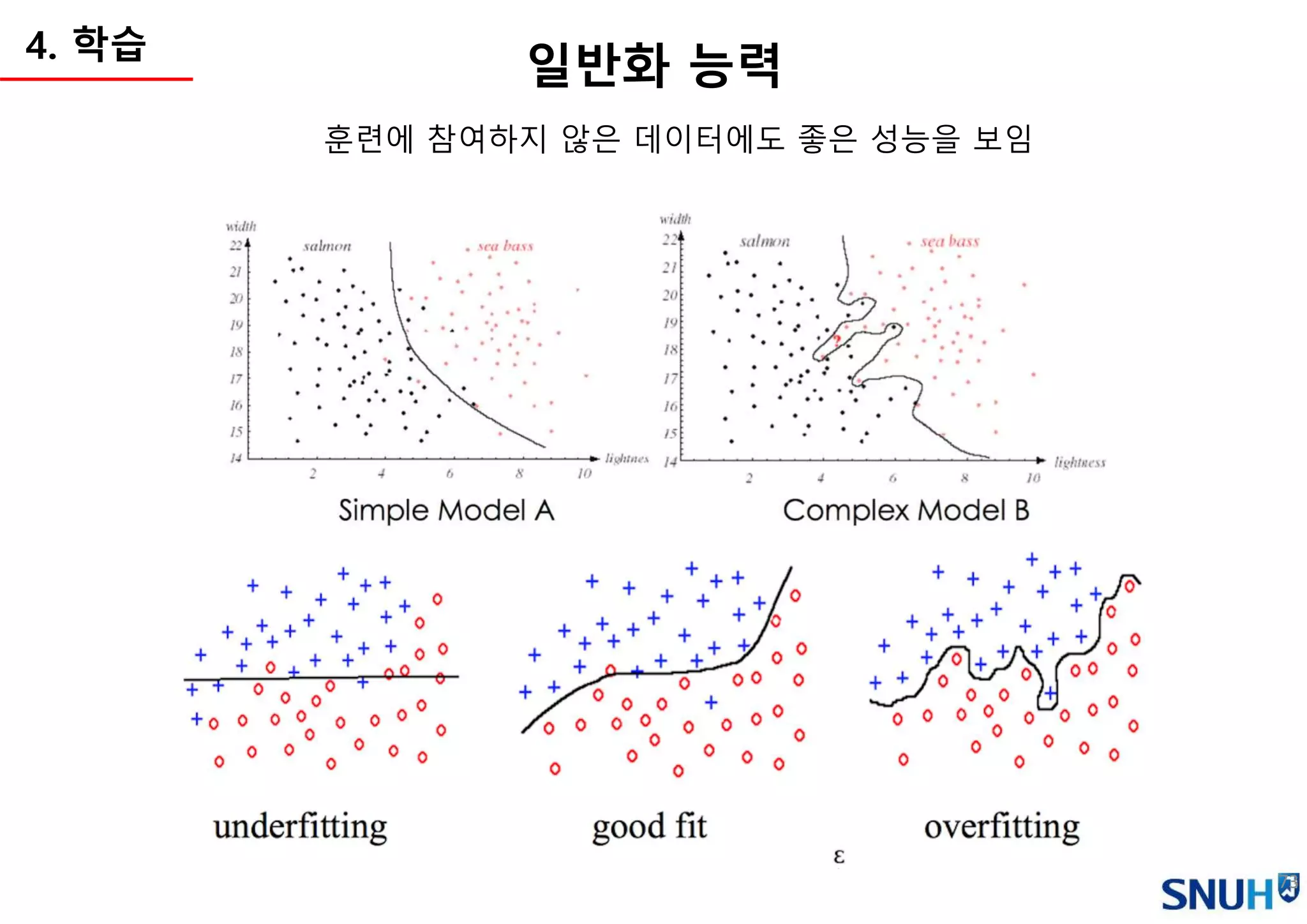
Q. What islearning?
• 인간이 연속된 경험을 통해 배워가는 일련의 과정 - David Kolb
• 기억(Memorization)하고 적응(Adaptation)하고, 이를 일반화(Generalization)하는 것
Q. Why machines need to learn?
• 모든 것을 프로그래밍 할 수 없다.
• 모든 상황을 커버할 수 있는 룰을 만드는 것은 불가능하다.
• 알고리즘으로 정의하기 어려운 일들이 있다.
57
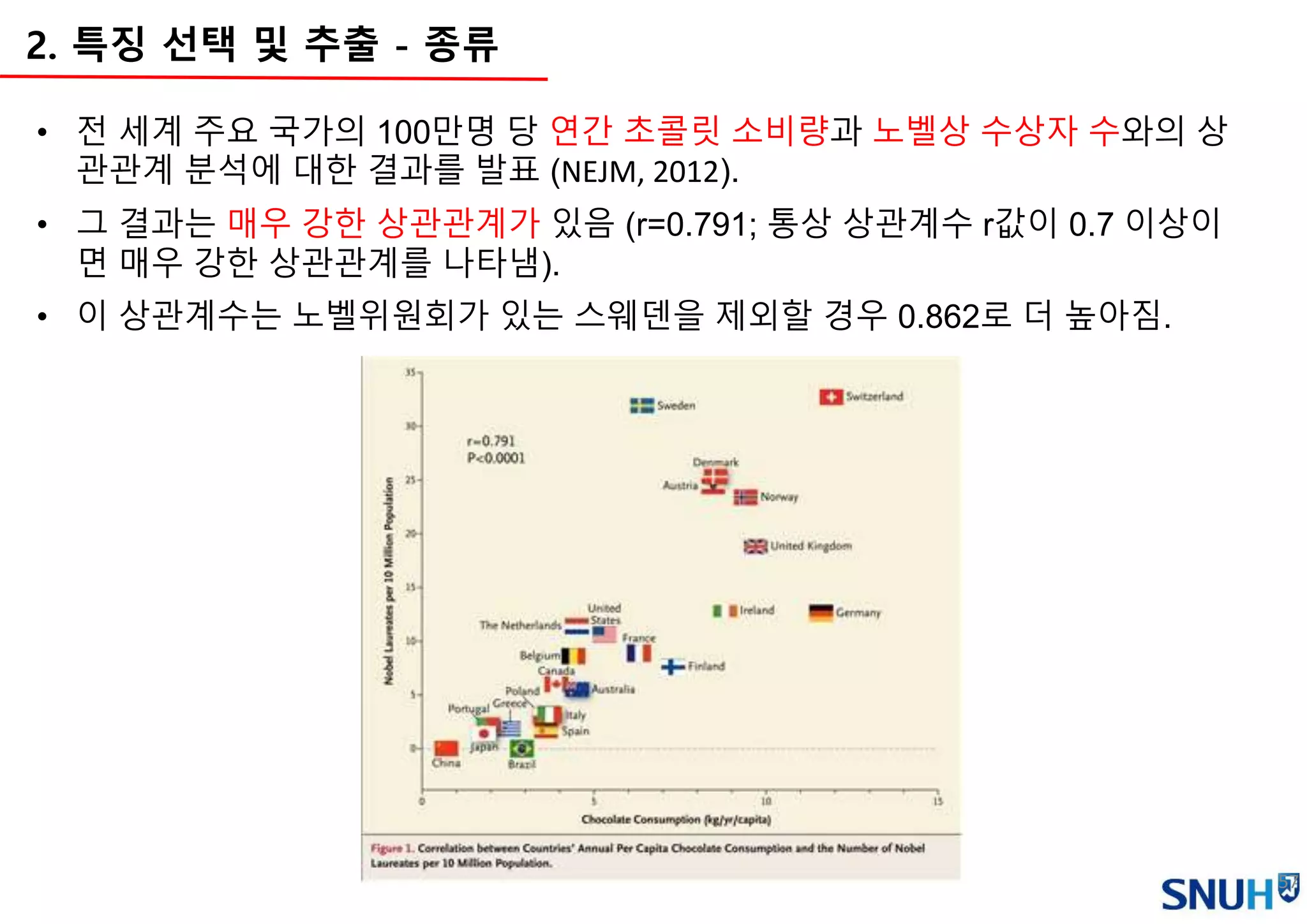
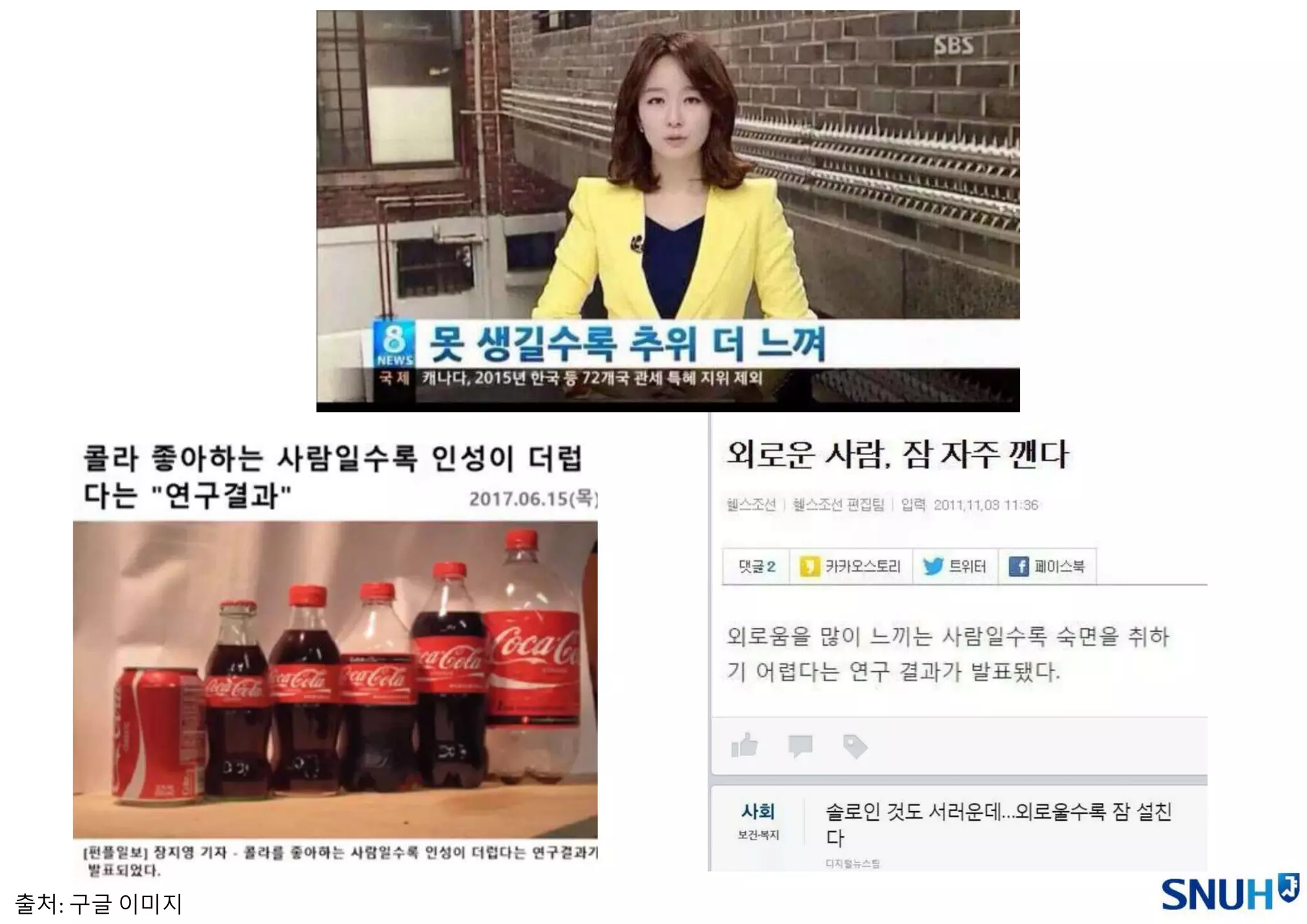
• 전 세계주요 국가의 100만명 당 연간 초콜릿 소비량과 노벨상 수상자 수와의 상
관관계 분석에 대한 결과를 발표 (NEJM, 2012).
• 그 결과는 매우 강한 상관관계가 있음 (r=0.791; 통상 상관계수 r값이 0.7 이상이
면 매우 강한 상관관계를 나타냄).
• 이 상관계수는 노벨위원회가 있는 스웨덴을 제외할 경우 0.862로 더 높아짐.
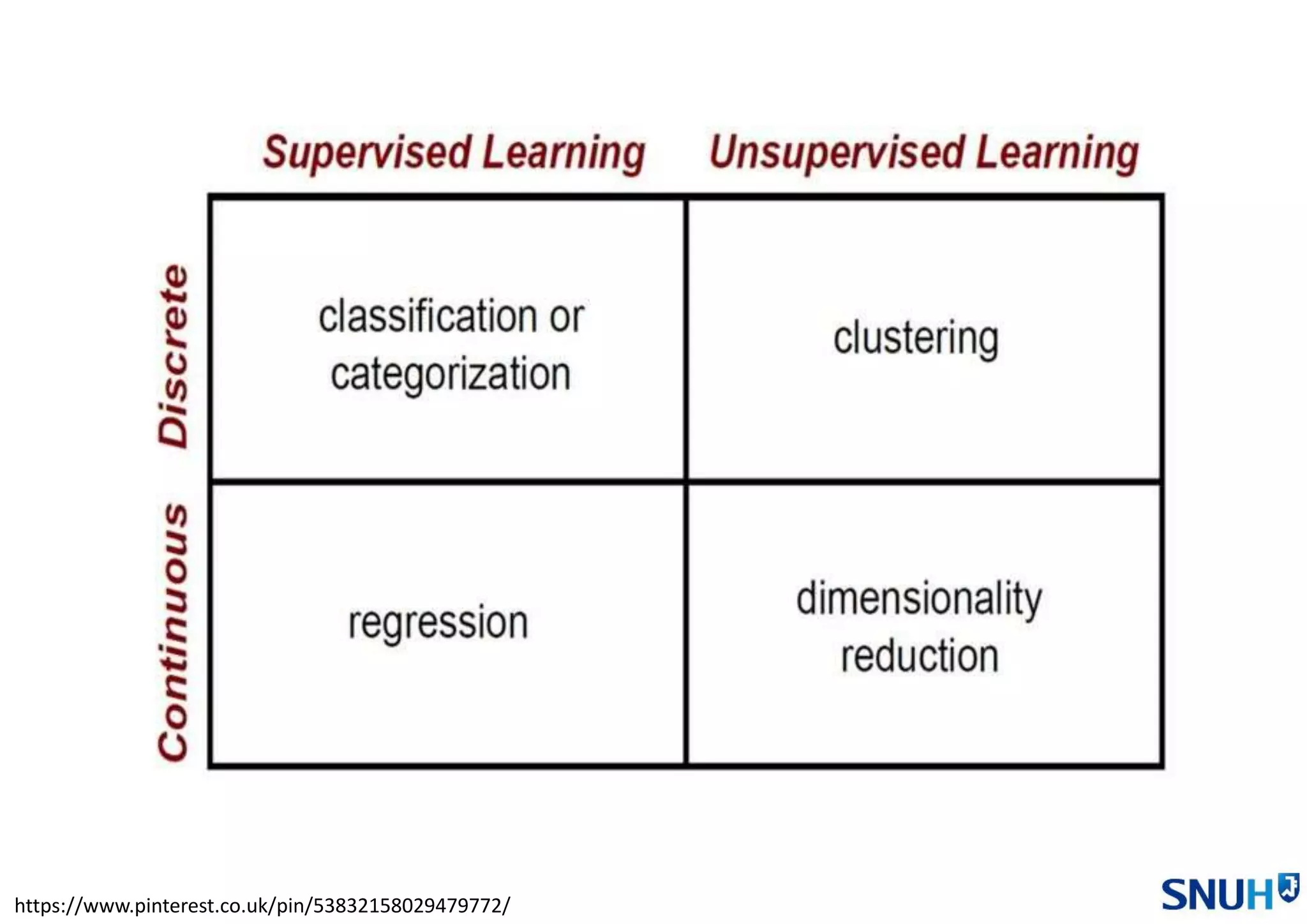
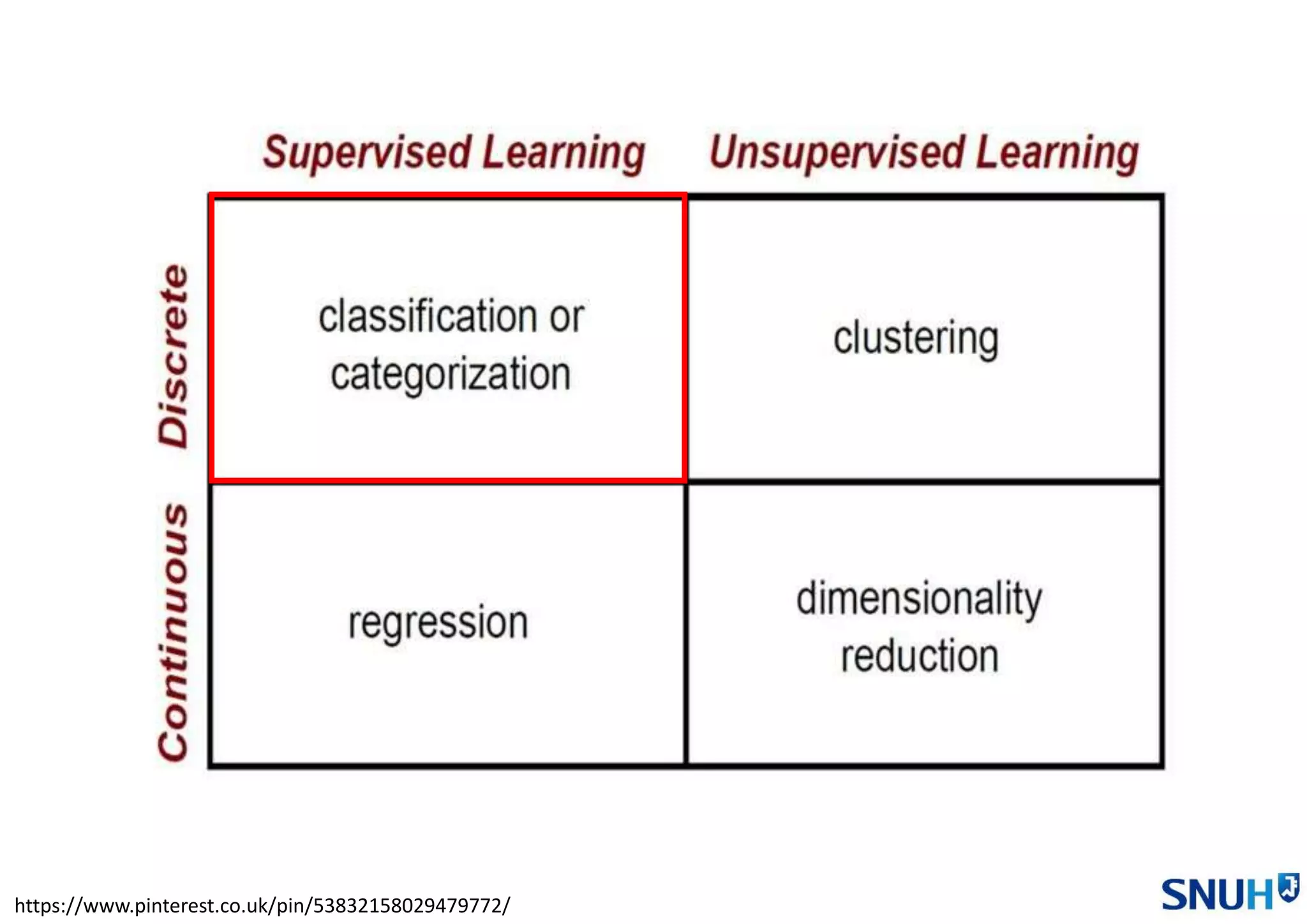
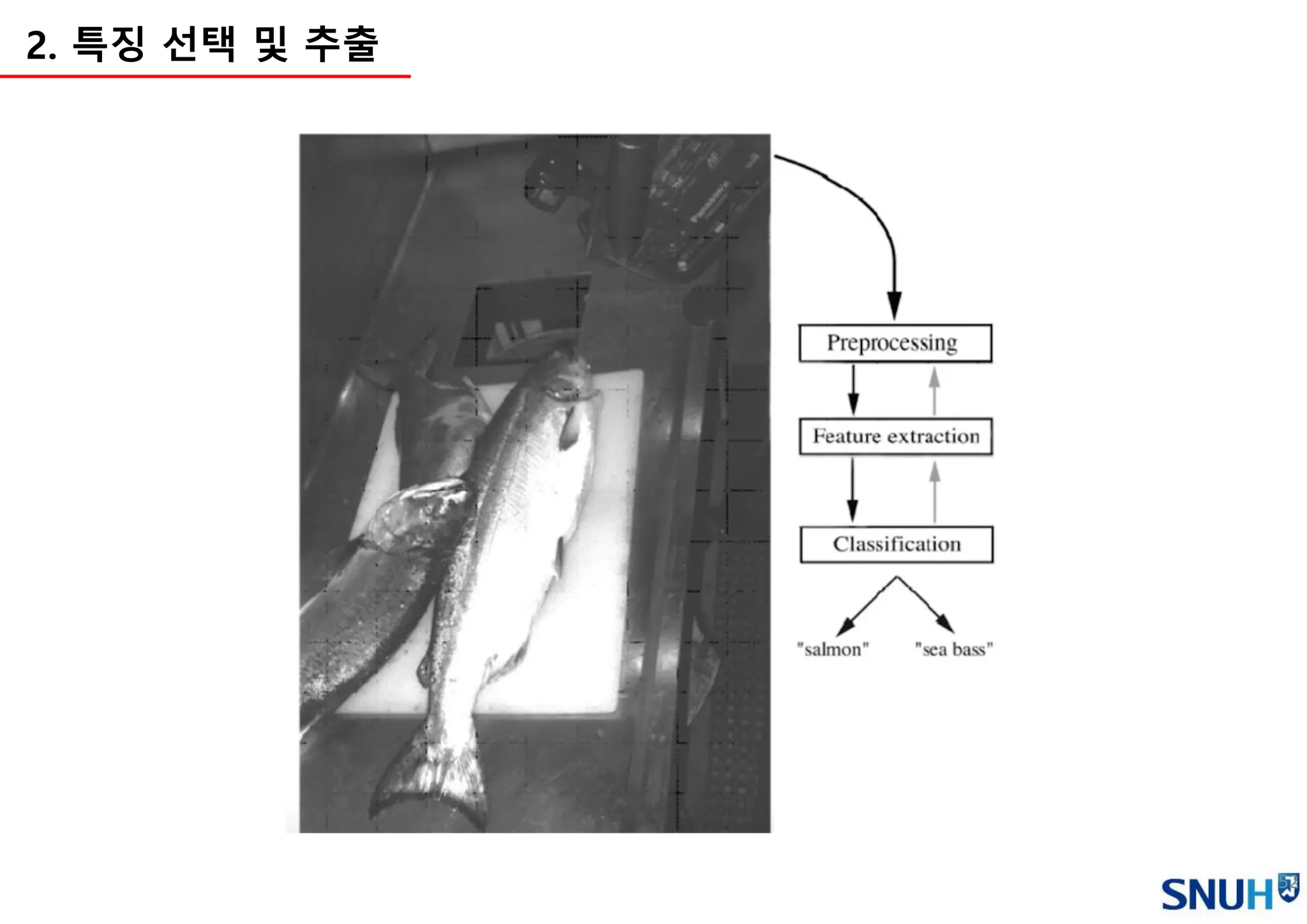
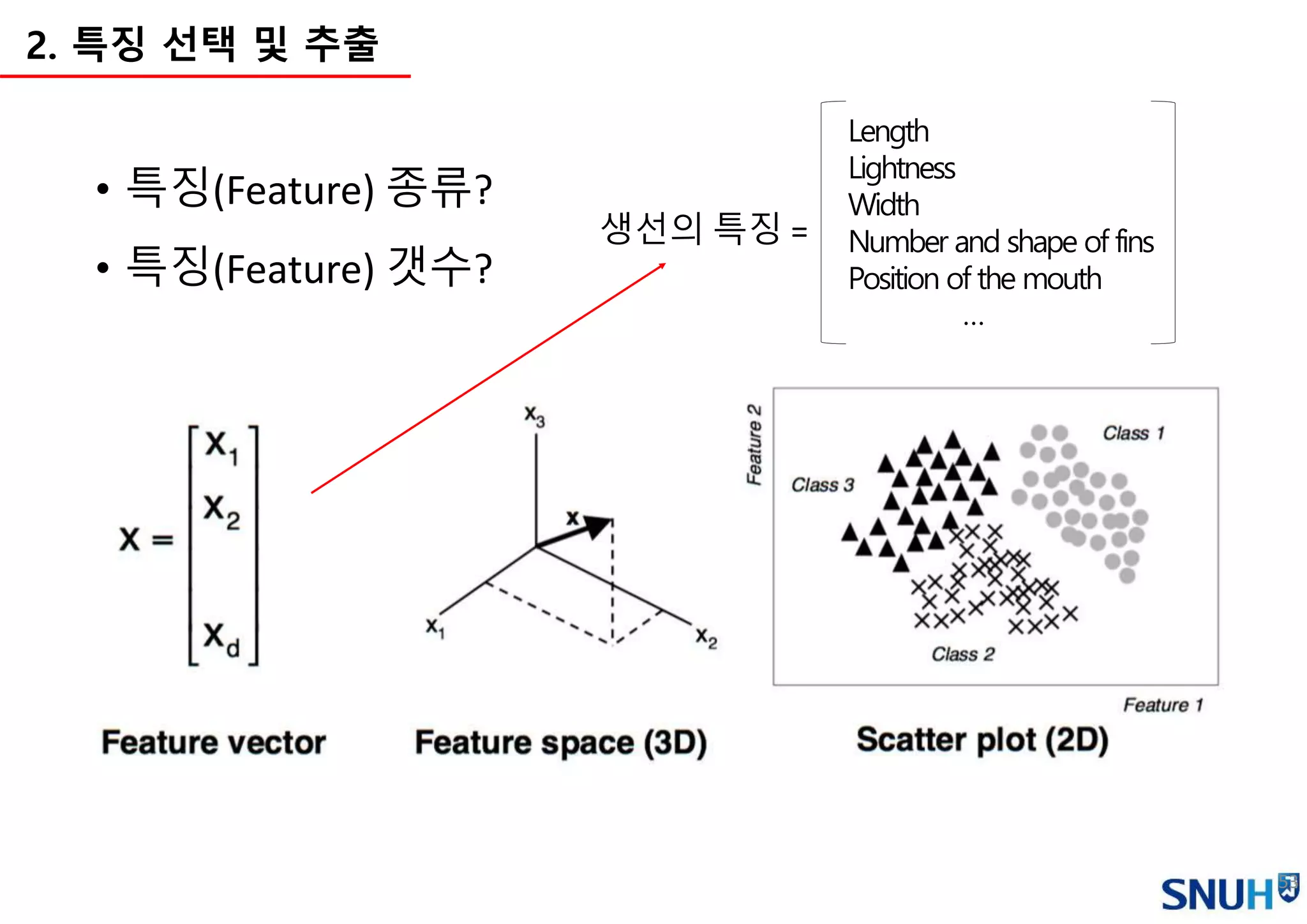
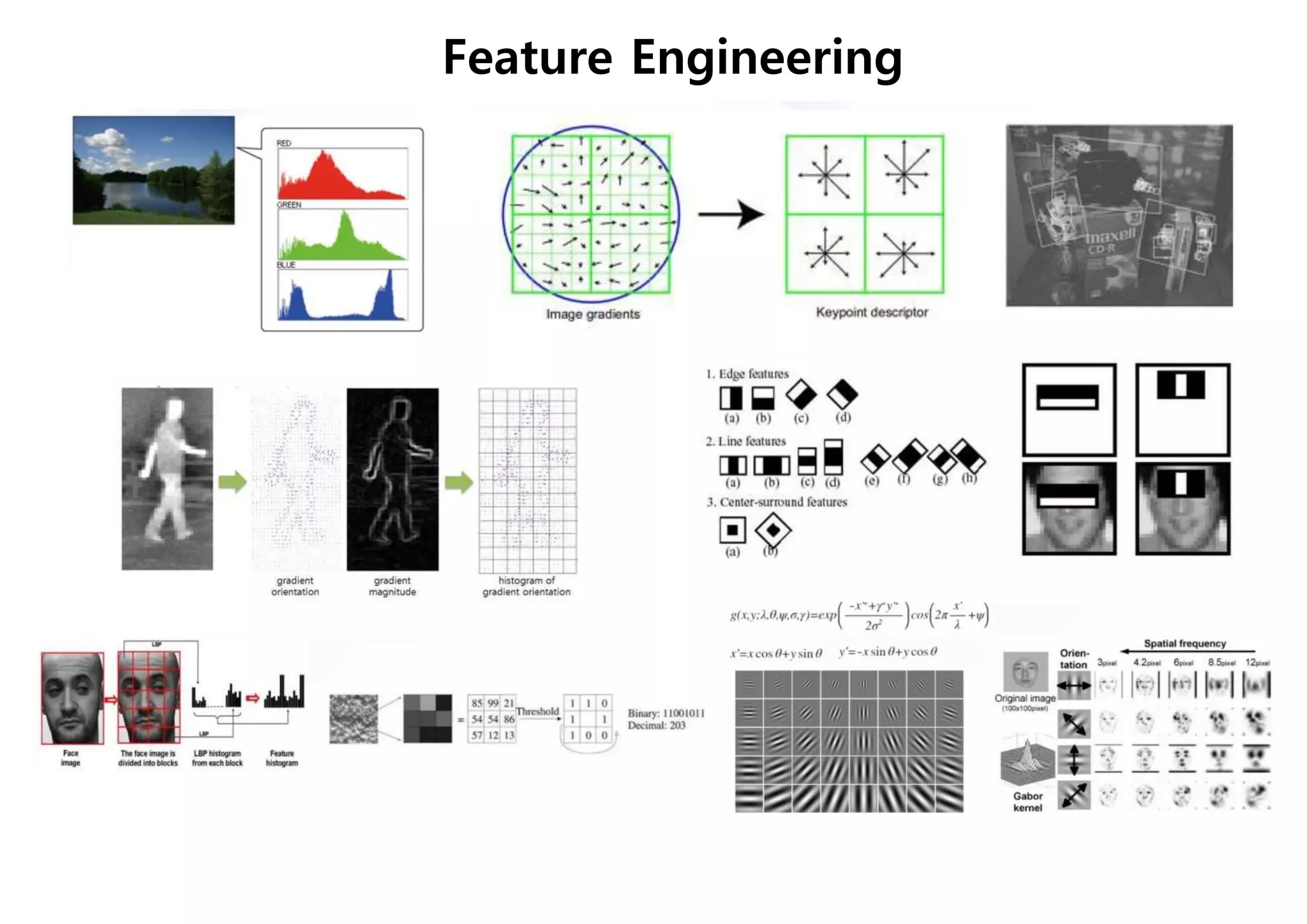
2. 특징 선택 및 추출 - 종류
59
2. 특징 선택및 추출 - 크기
e.g.
• BMI = 키, 몸무게 (2D)
• 건강상태 = 혈압, 나이, BMI (5D)
60.
60
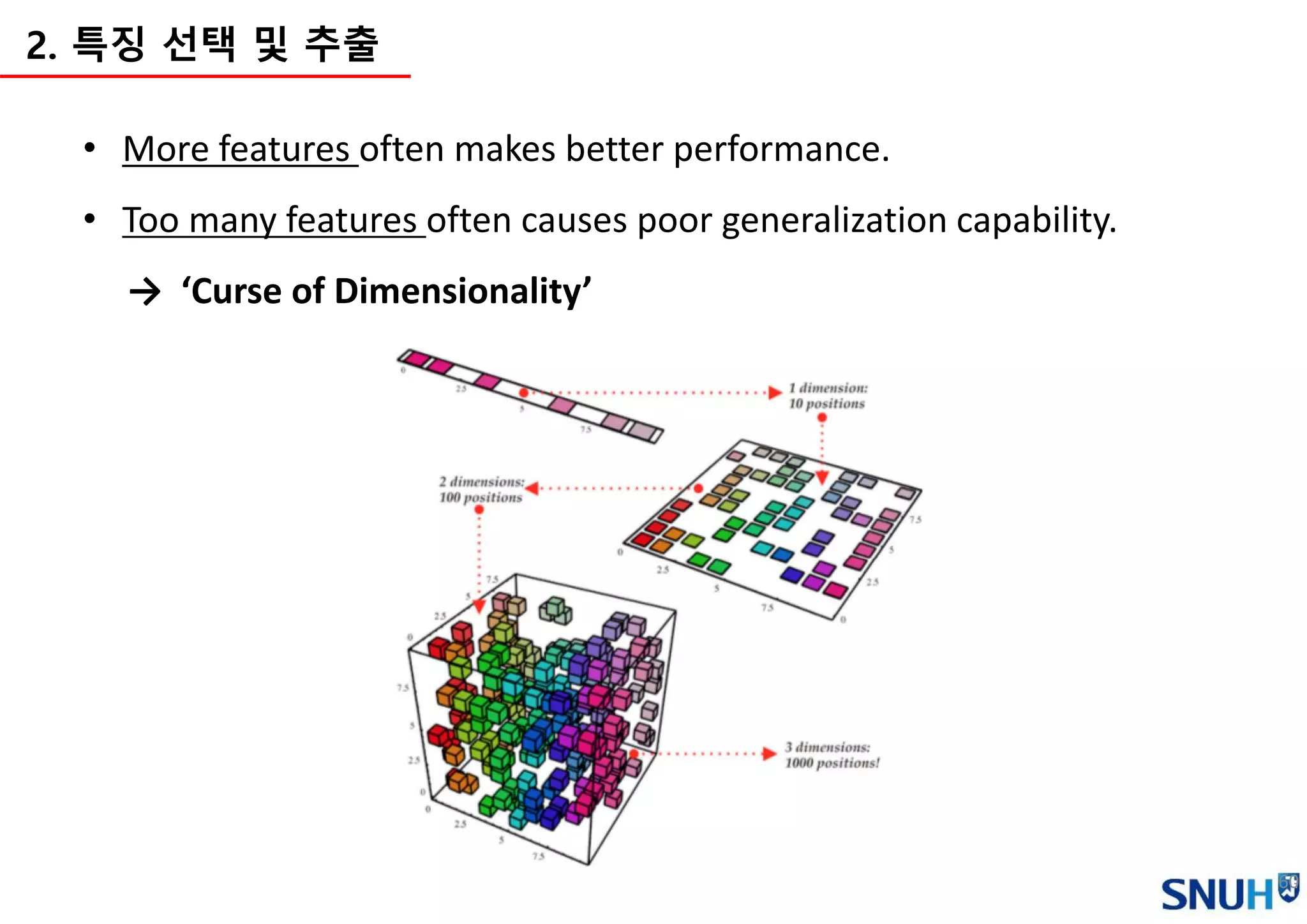
2. 특징 선택및 추출
• More features often makes better performance.
• Too many features often causes poor generalization capability.
→ ‘Curse of Dimensionality’
61.
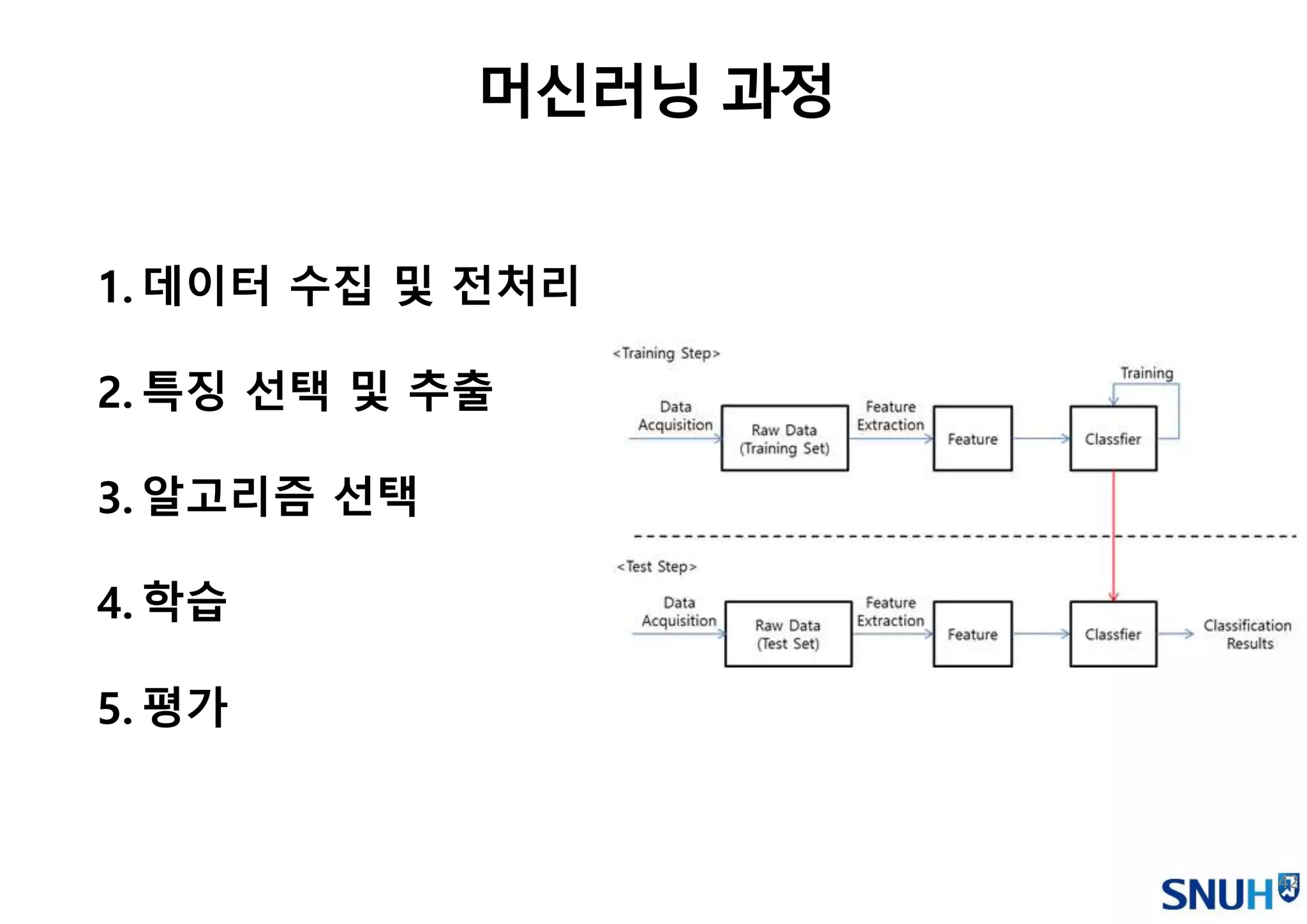
1.데이터 수집 및전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
1.데이터 수집 및 전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
62.
1.데이터 수집 및전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
1.데이터 수집 및 전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
1.데이터 수집 및전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
1.데이터 수집 및 전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
67.
1.데이터 수집 및전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
1.데이터 수집 및 전처리
2.특징 선택 및 추출
3.알고리즘 선택
4.학습
5.평가
68.
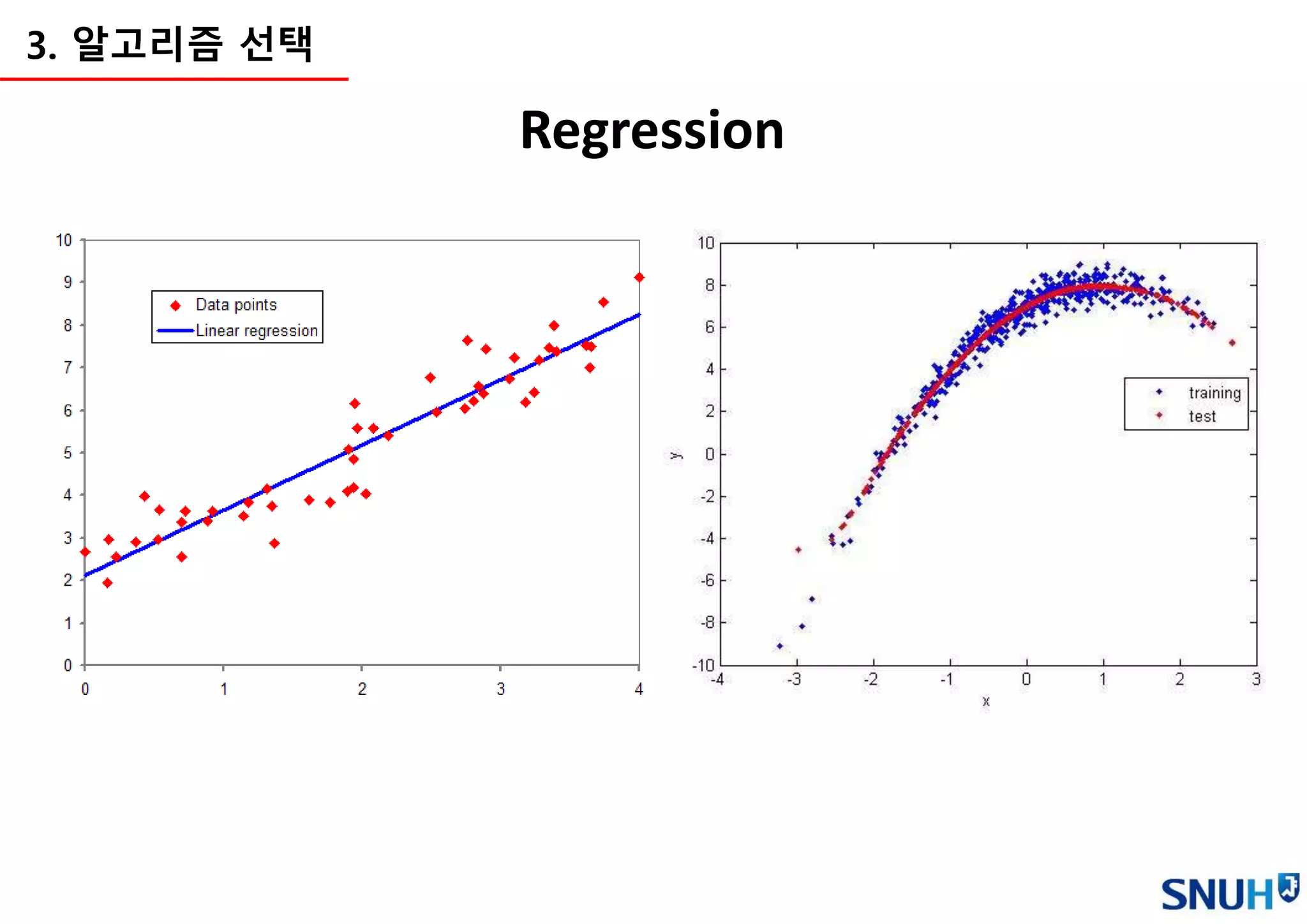
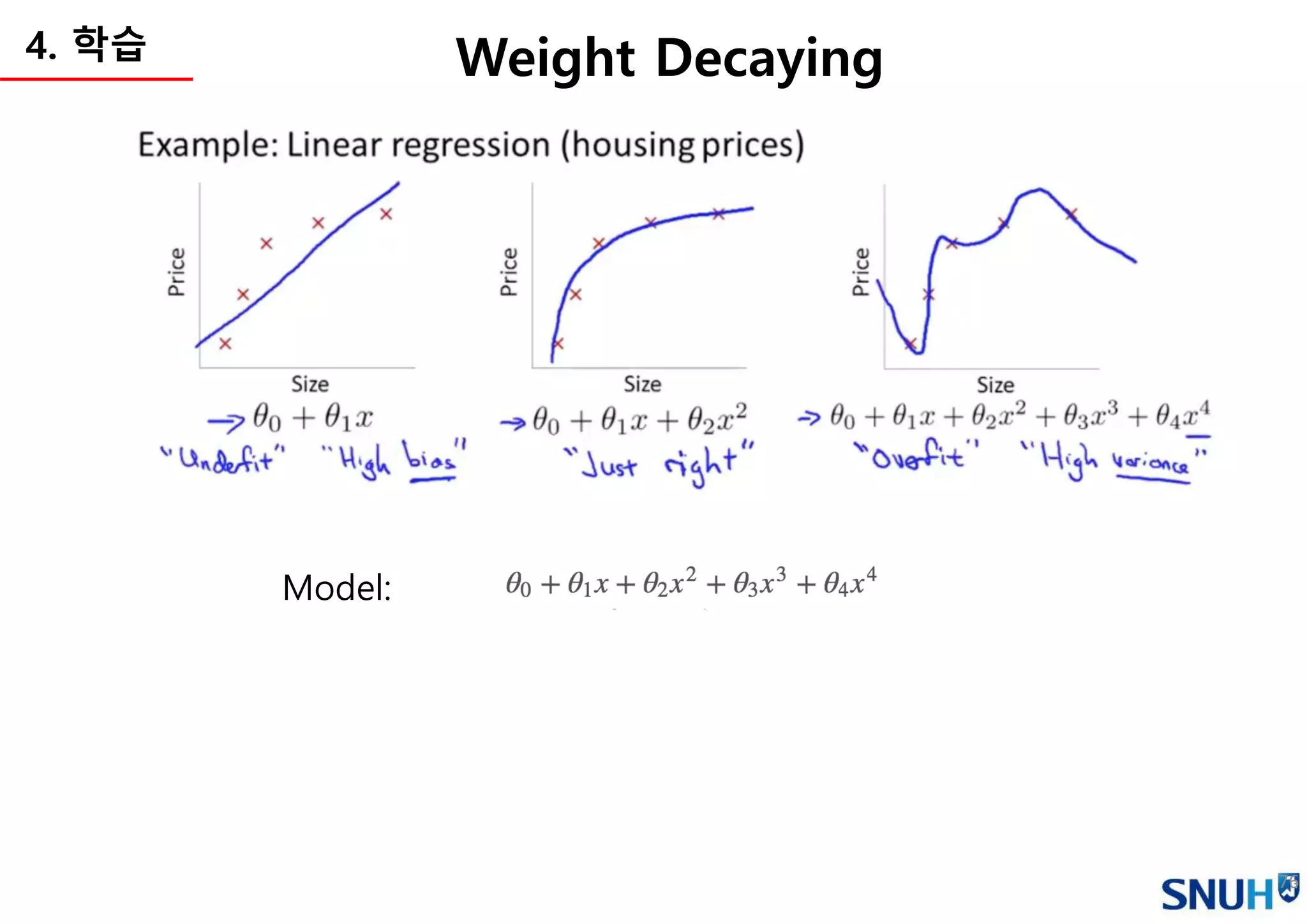
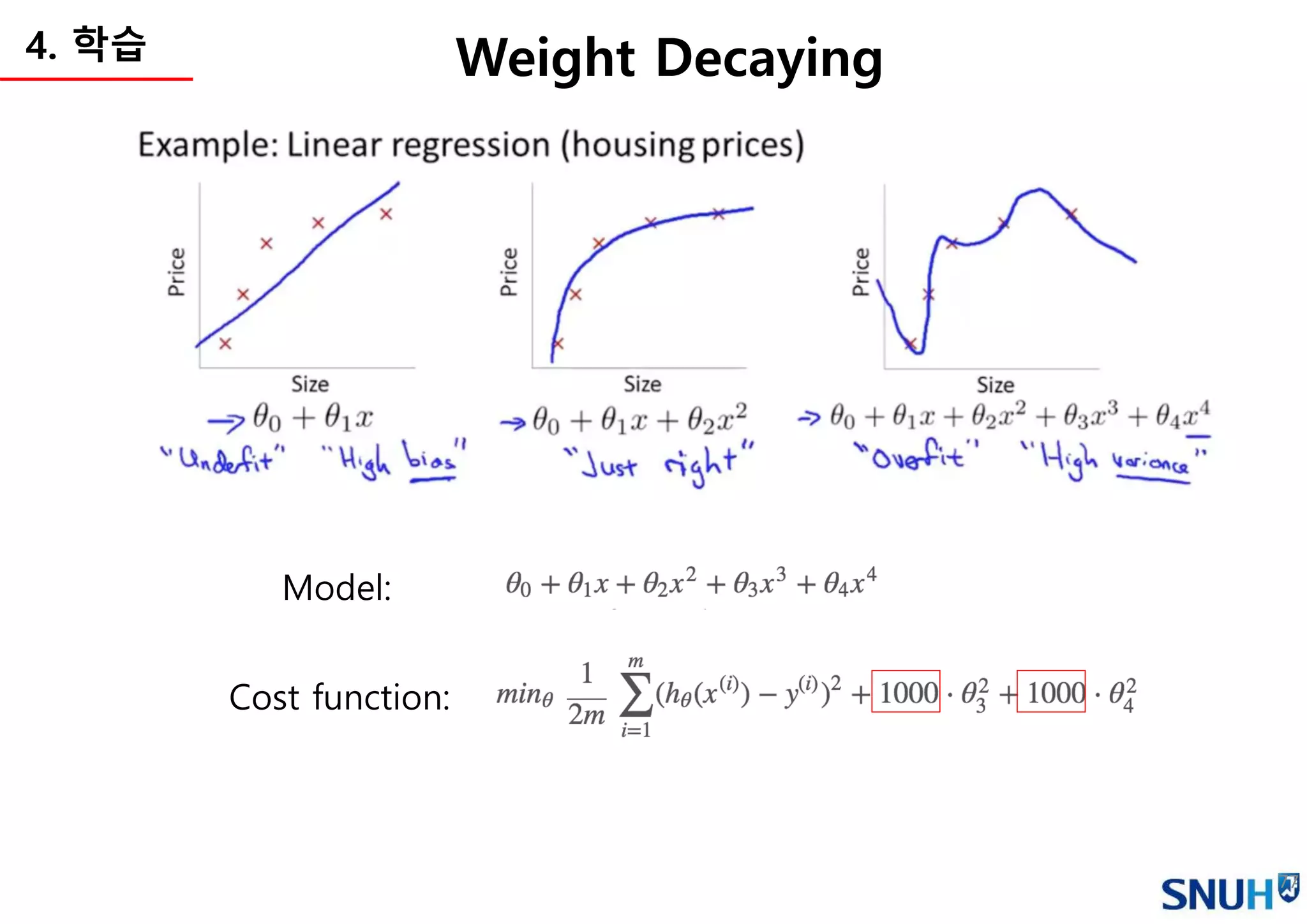
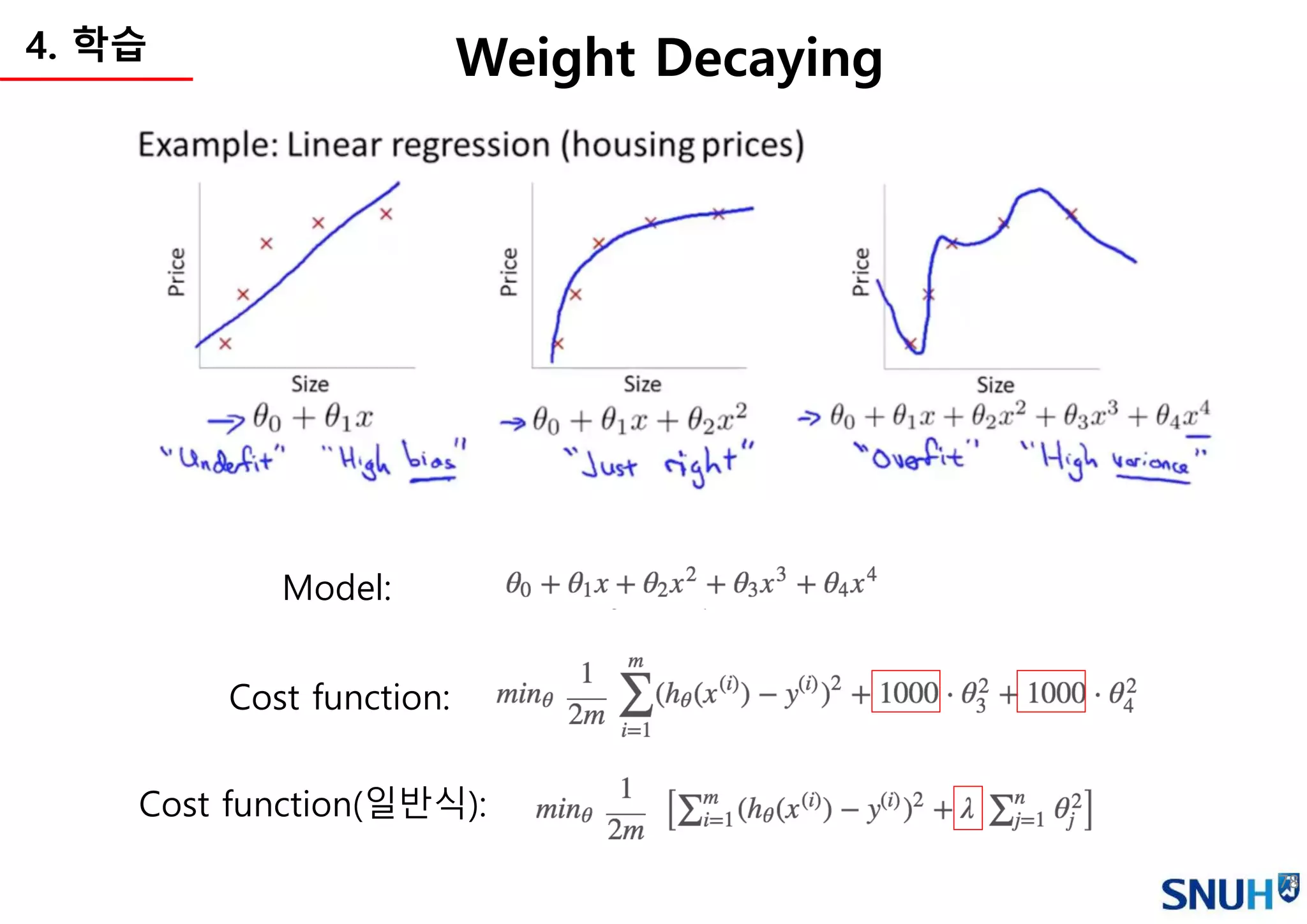
Continuous value
Categorical value
(Binary,One-hot)
e.g. Least Square Method e.g. Cross-entropy
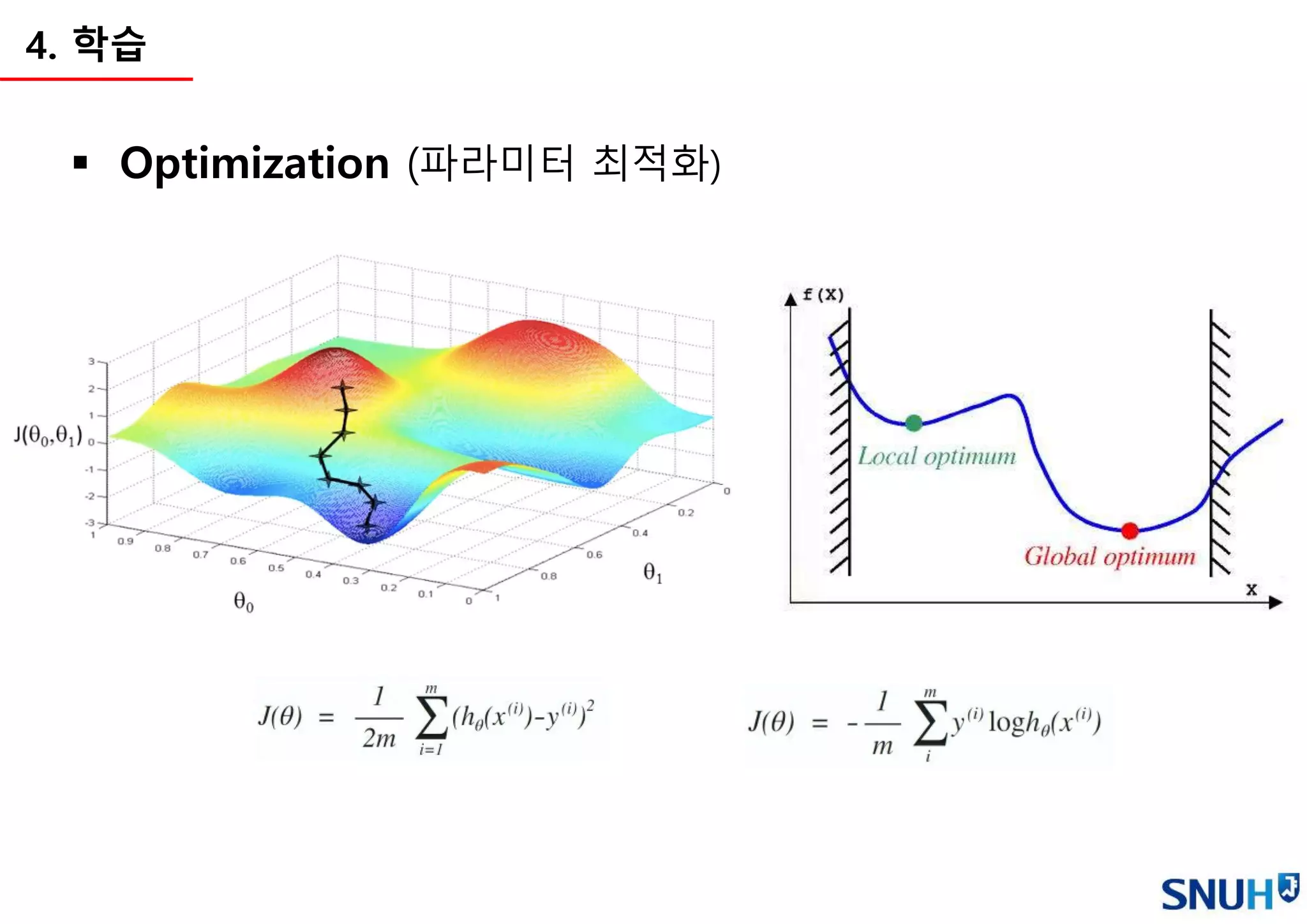
Cost function (a.k.a Loss function)
• 학습의 기준이 되는 함수를 정의
• Cost function이 최소화하는 방향으로 학습을 진행 (파라미터 변경)
4. 학습
69.
4. 학습
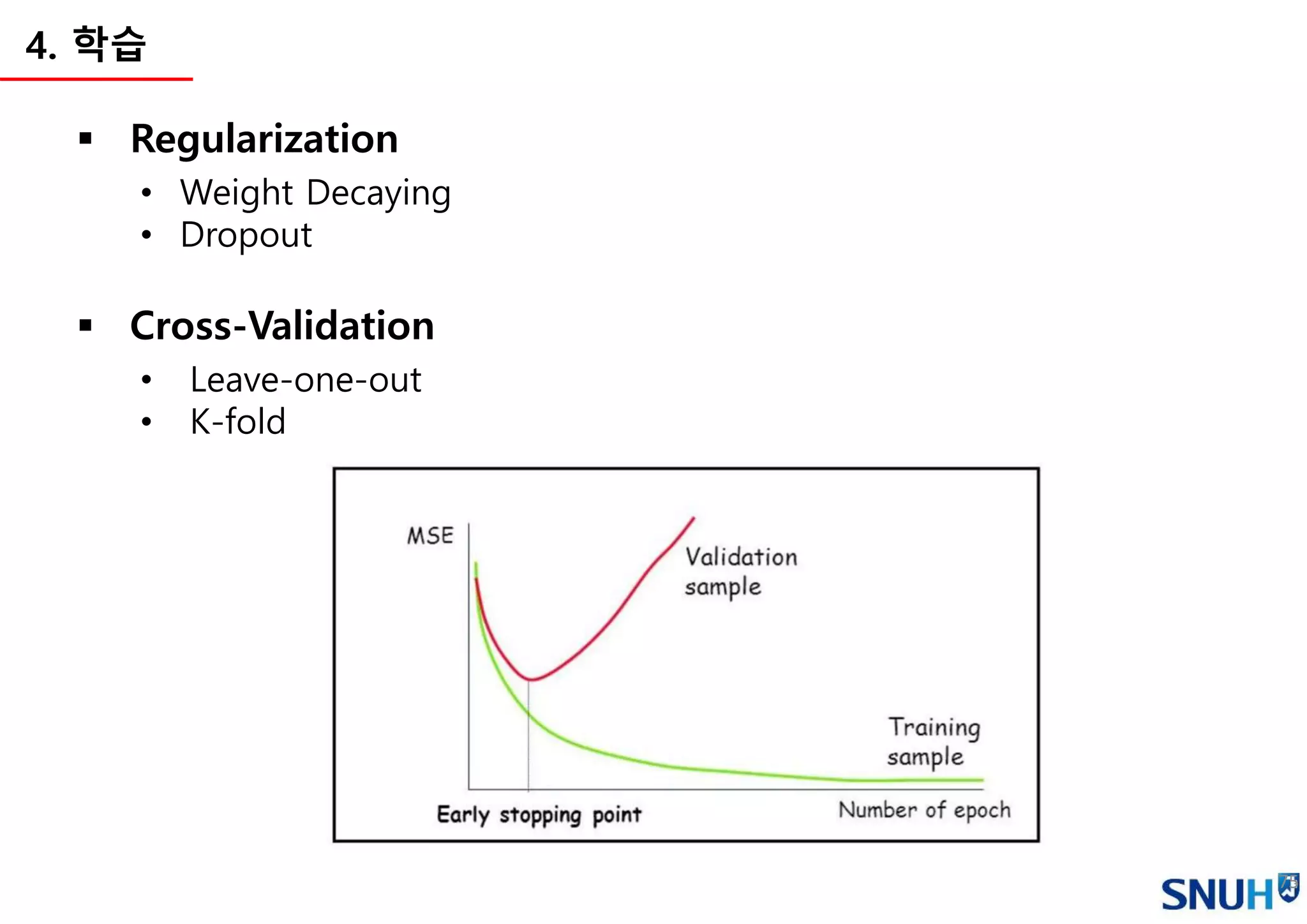
Hyperparameters(모델 학습을 위한 파라미터)
• Learning rate
• Regularization constant
• Loss function
• Weight Initialization strategy
• Number of epochs
• Batch size
• (Number of layers)
• (Nodes in hidden layer)
• (Activation functions)
…
1. 데이터 수집및 전처리
• CIFAR-10
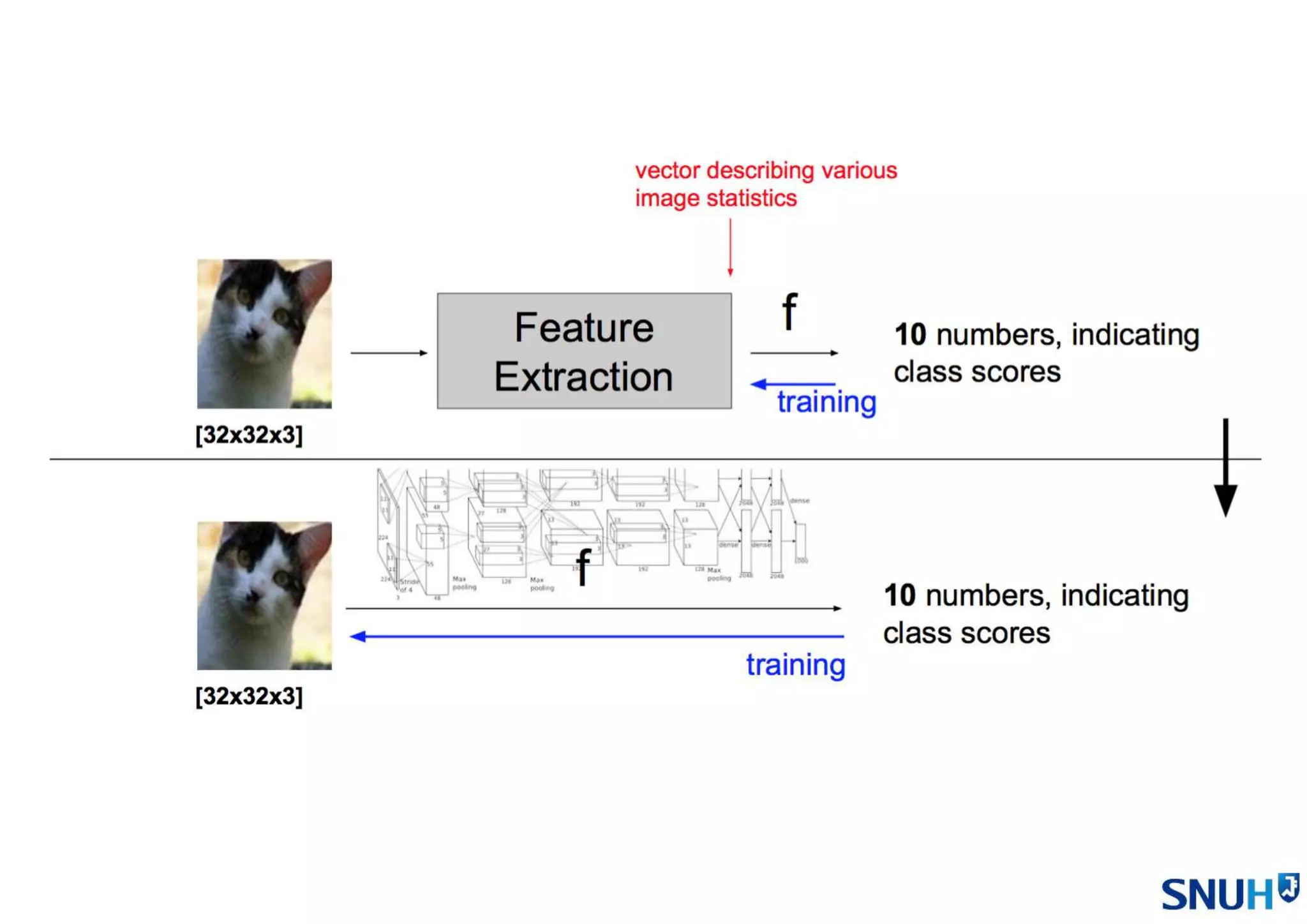
2. 특징 선택 및 추출
• 원본 이미지 그대로
3. 알고리즘 선택
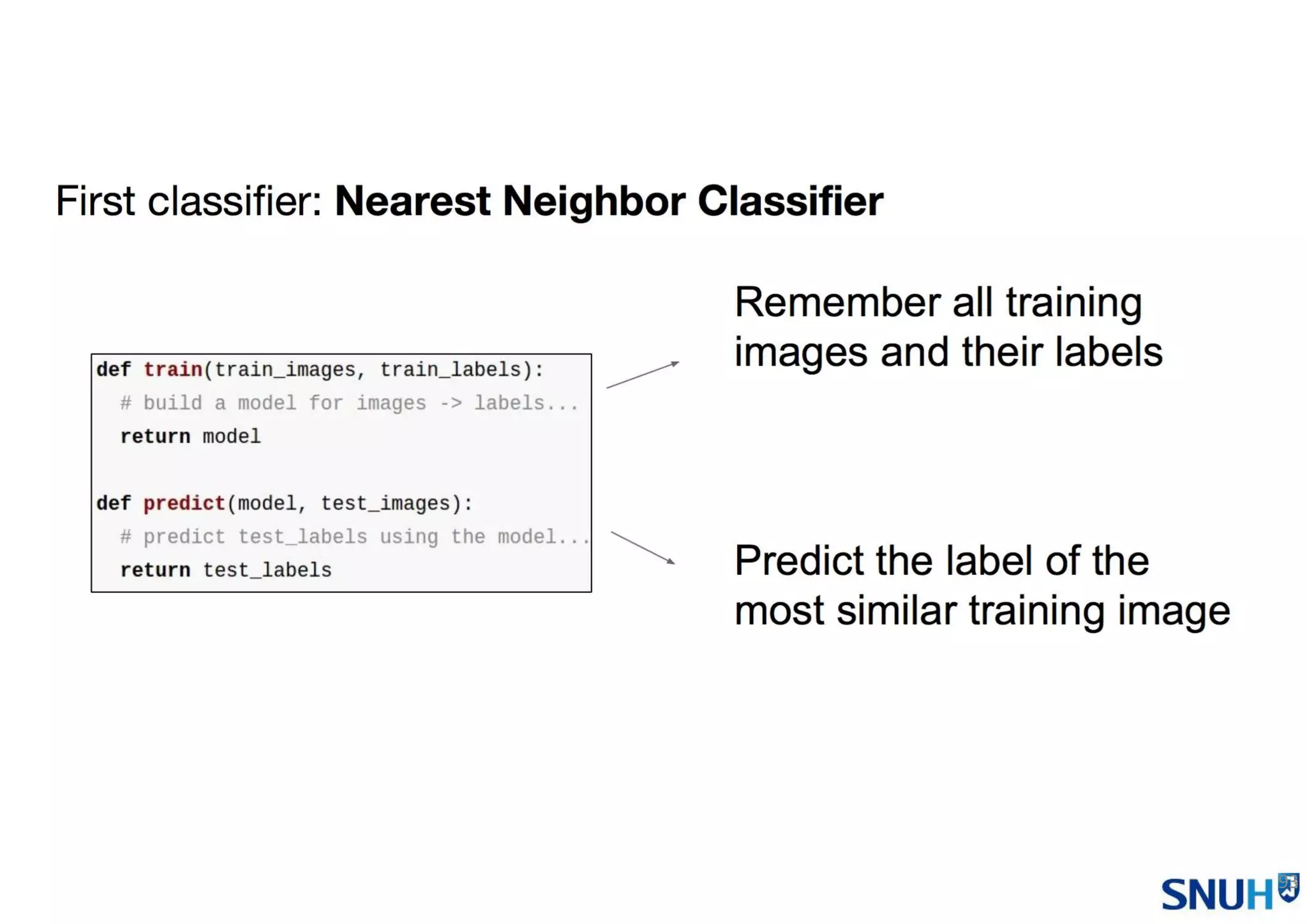
• NN Classifier
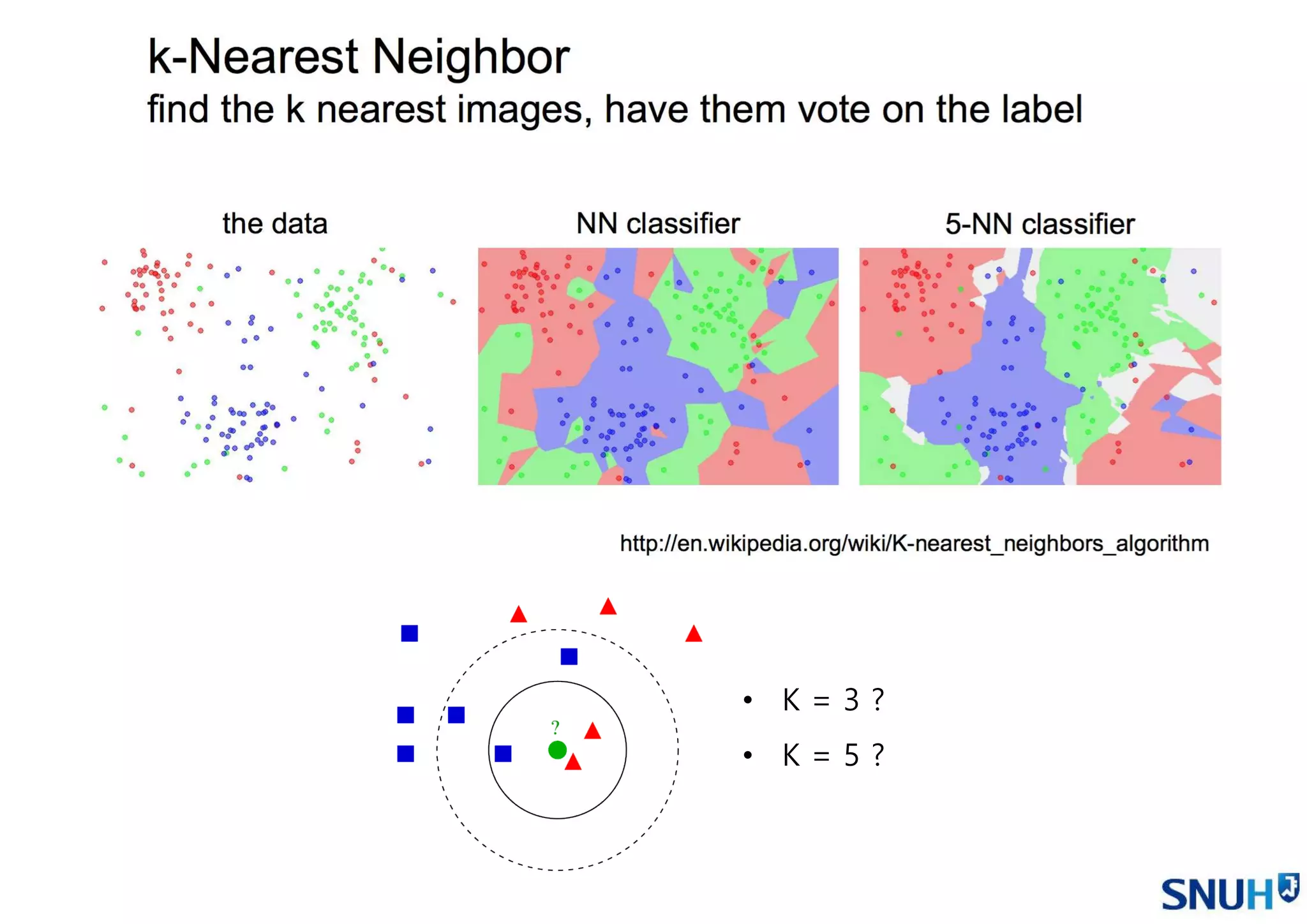
• K-NN Classifier
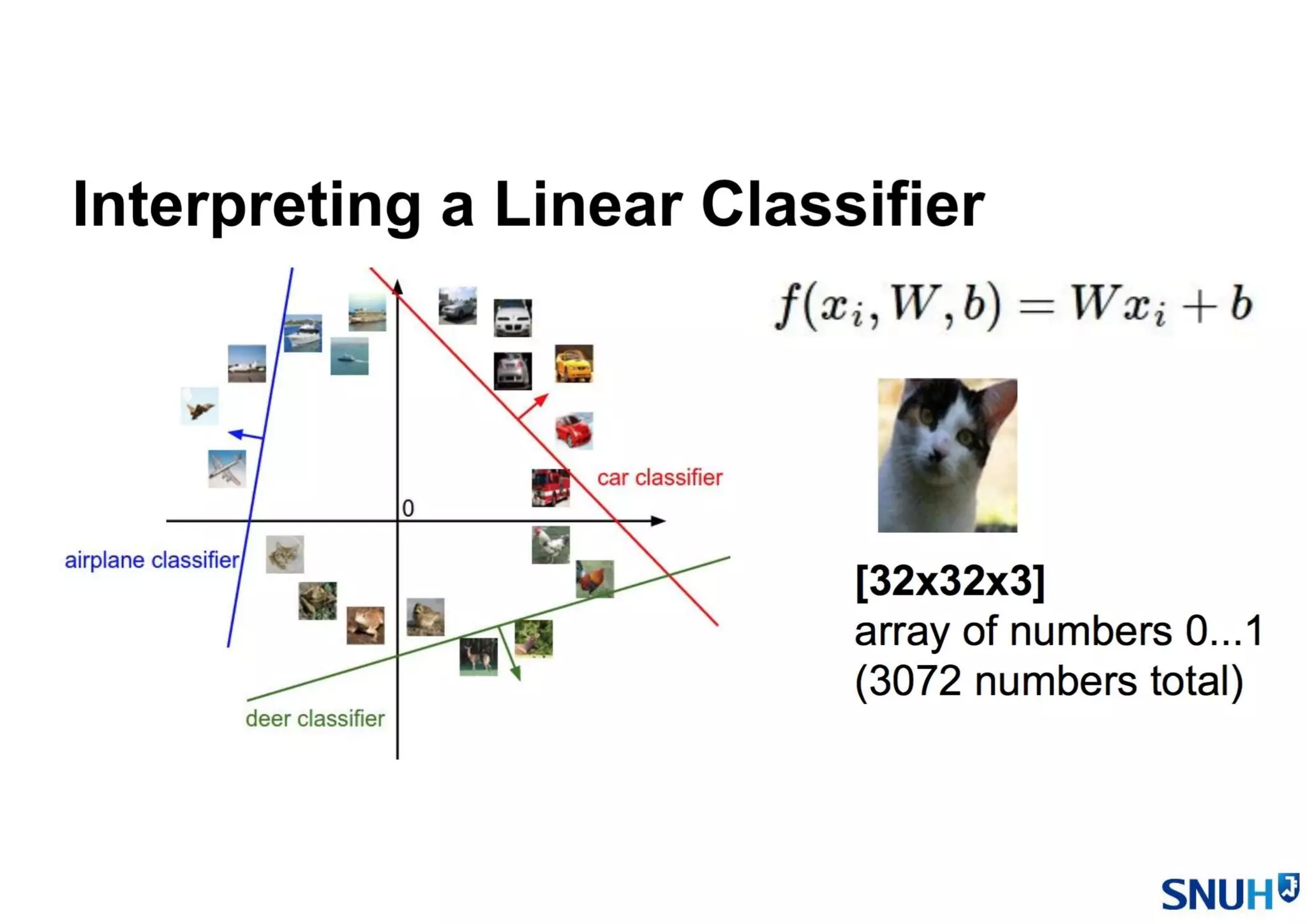
• Linear Classifier
Summary
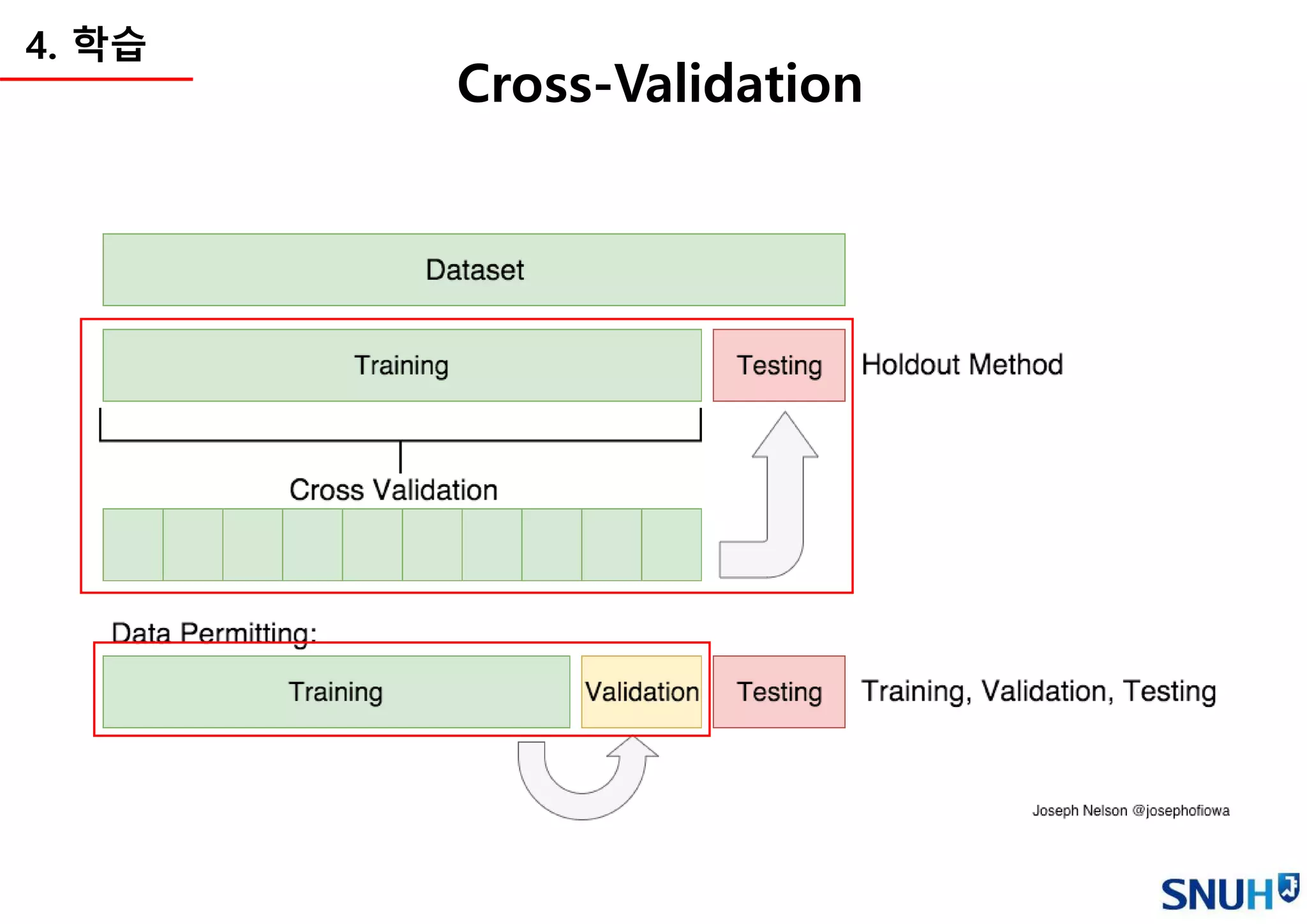
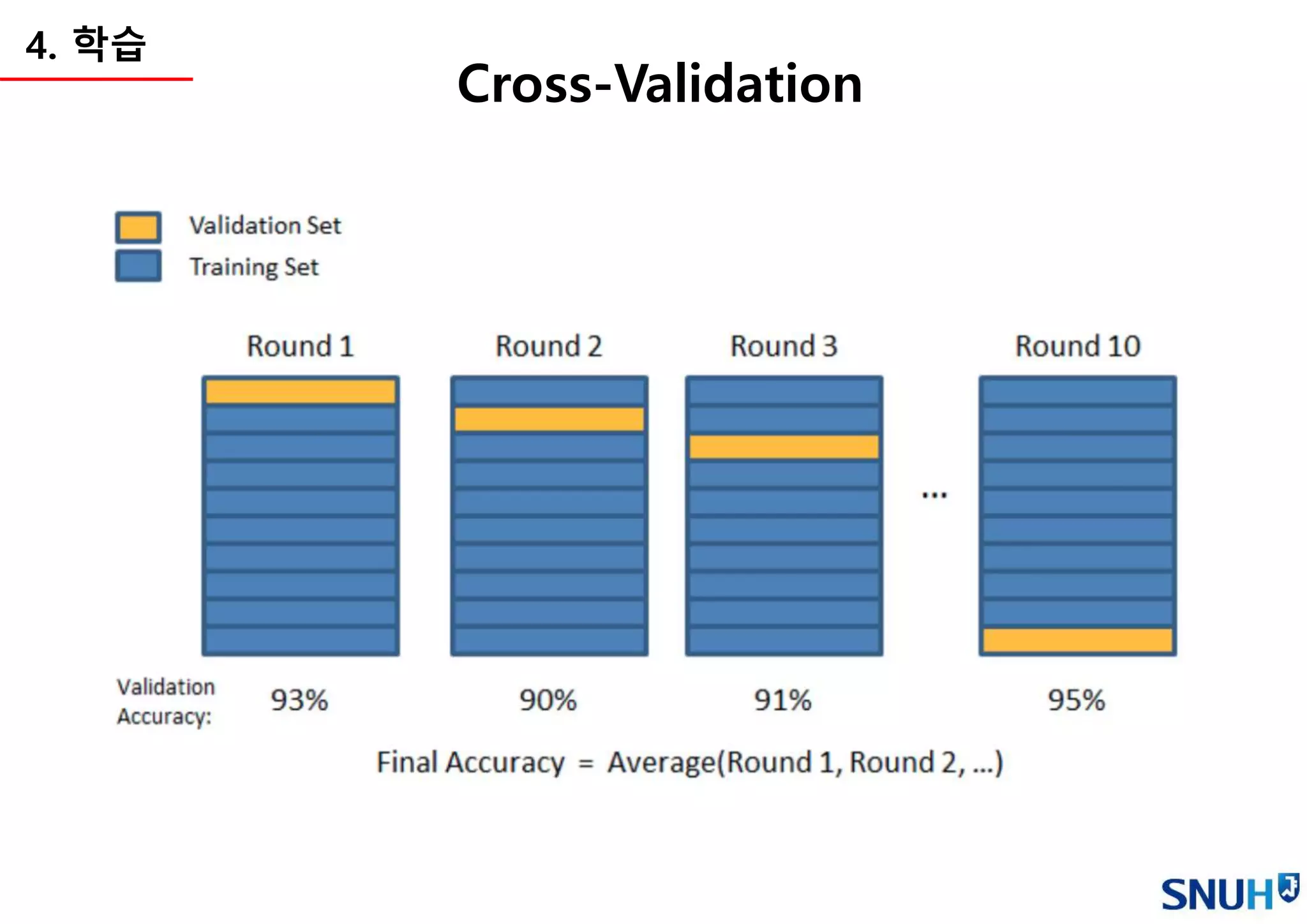
4. 학습
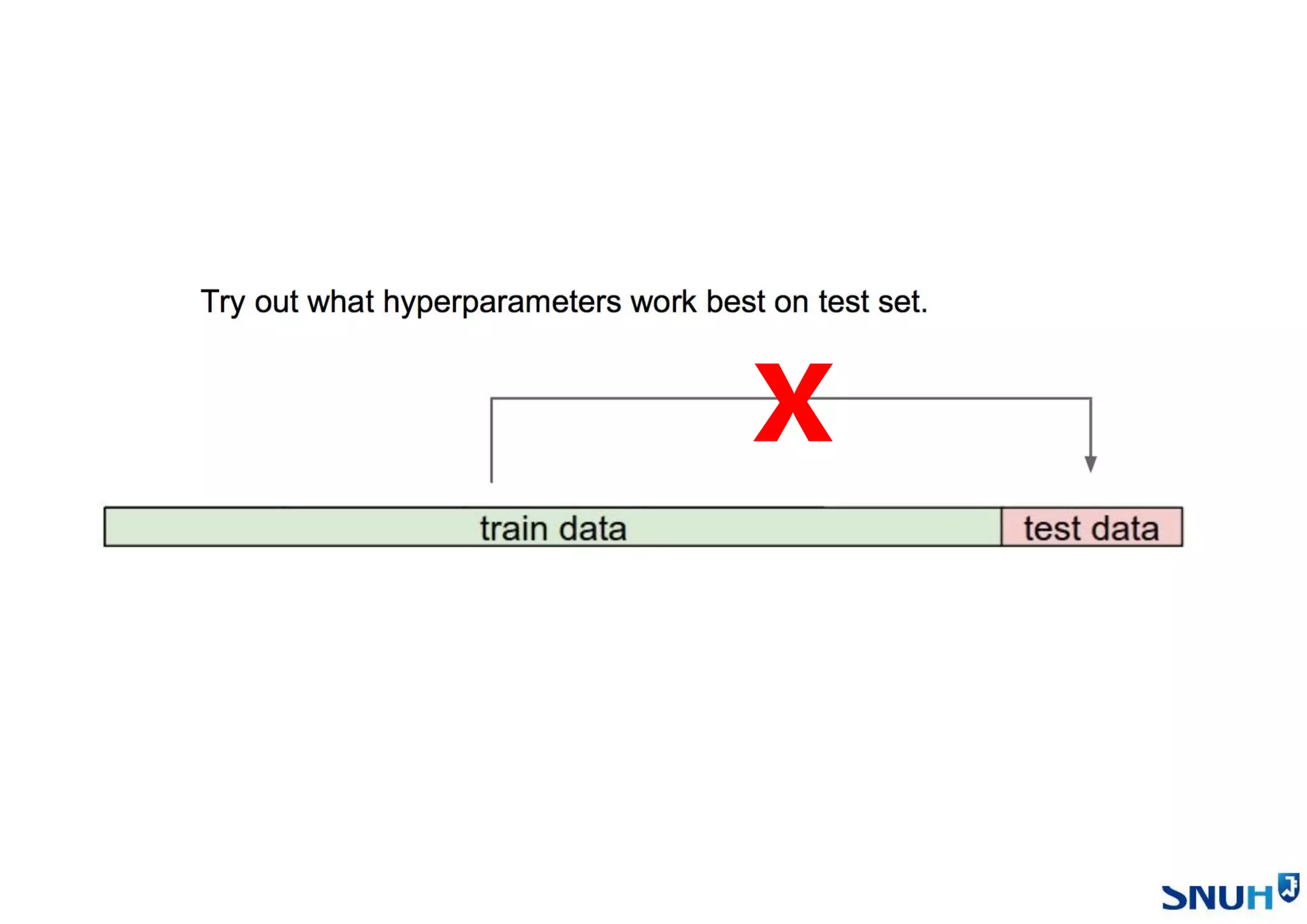
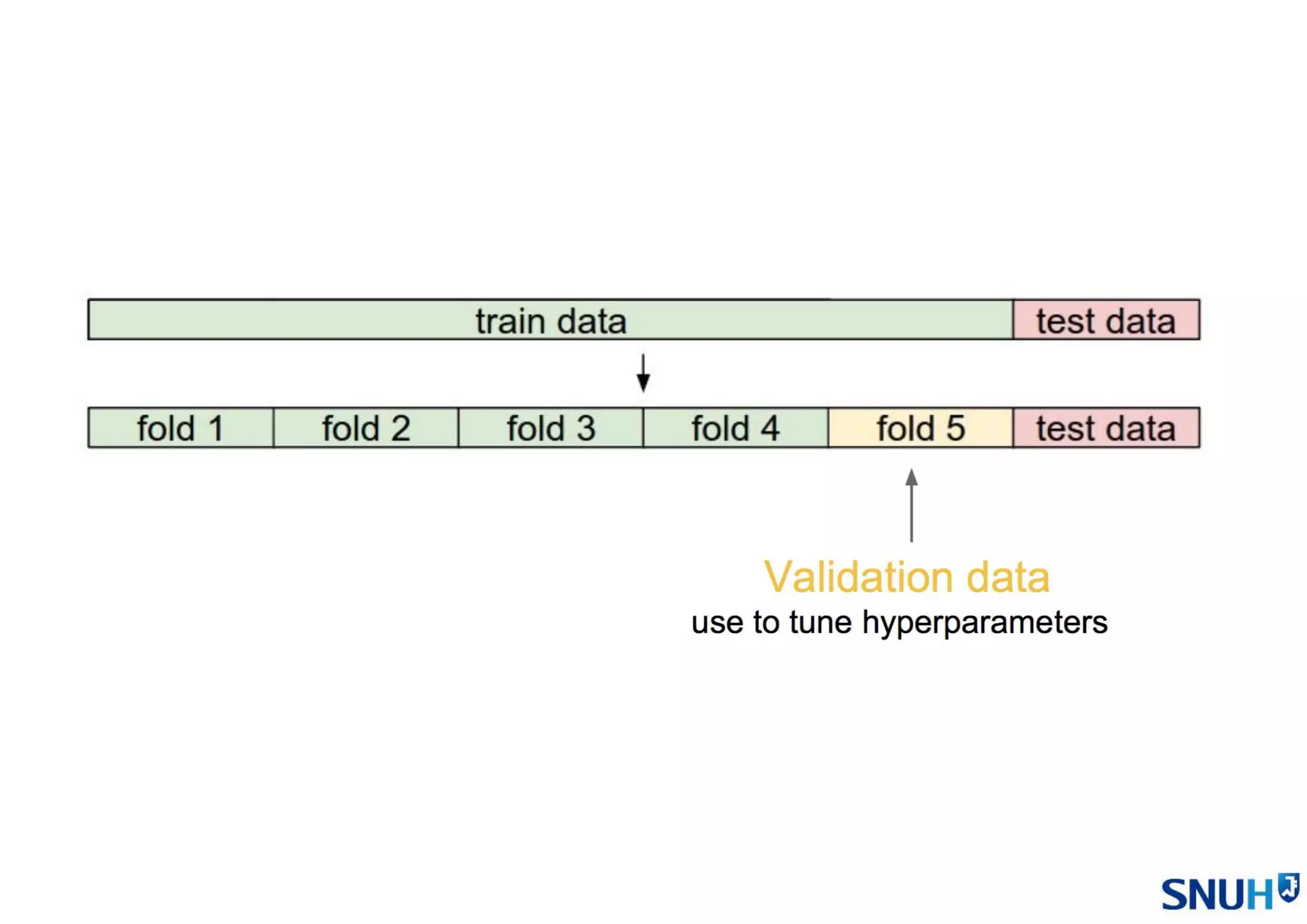
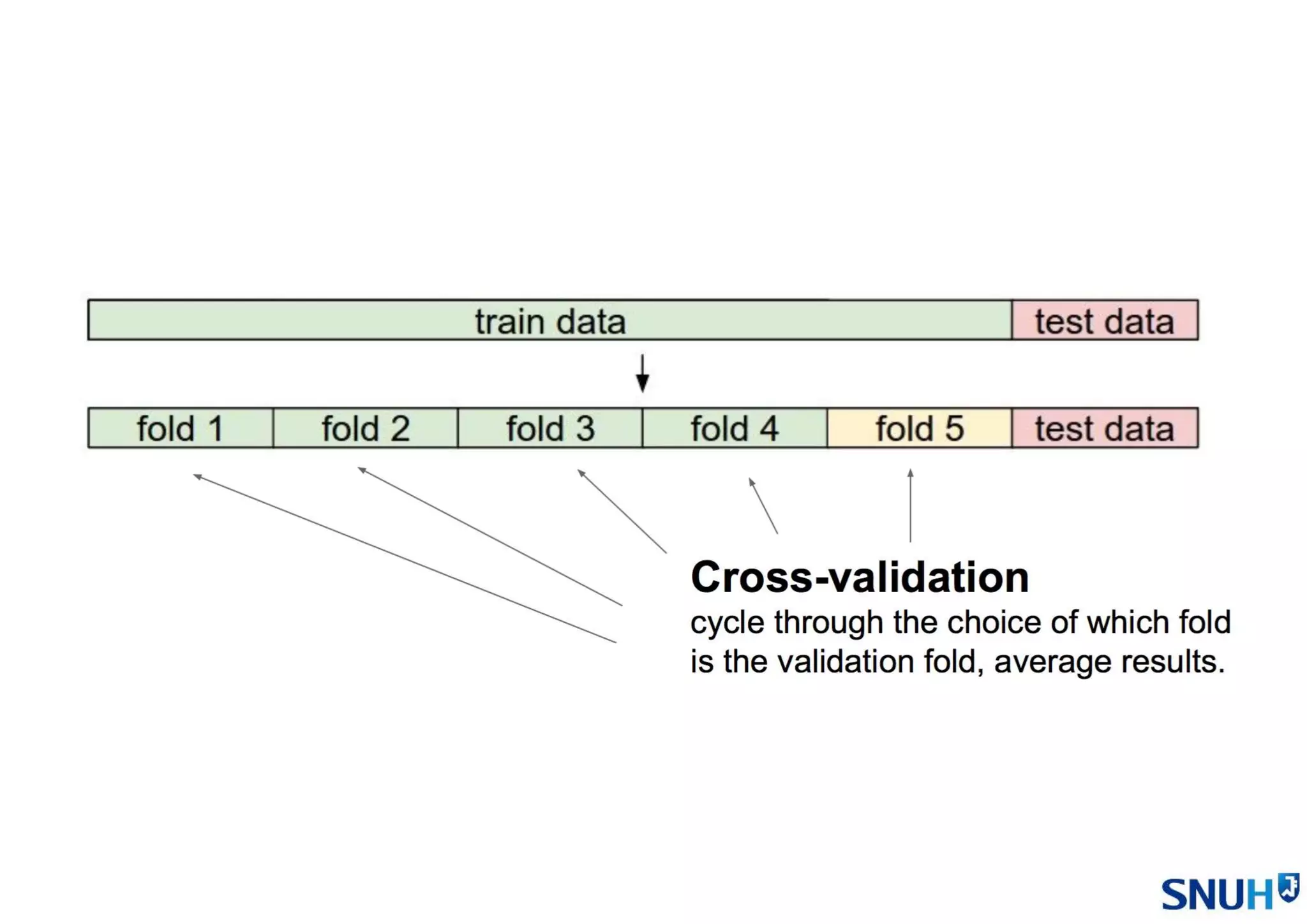
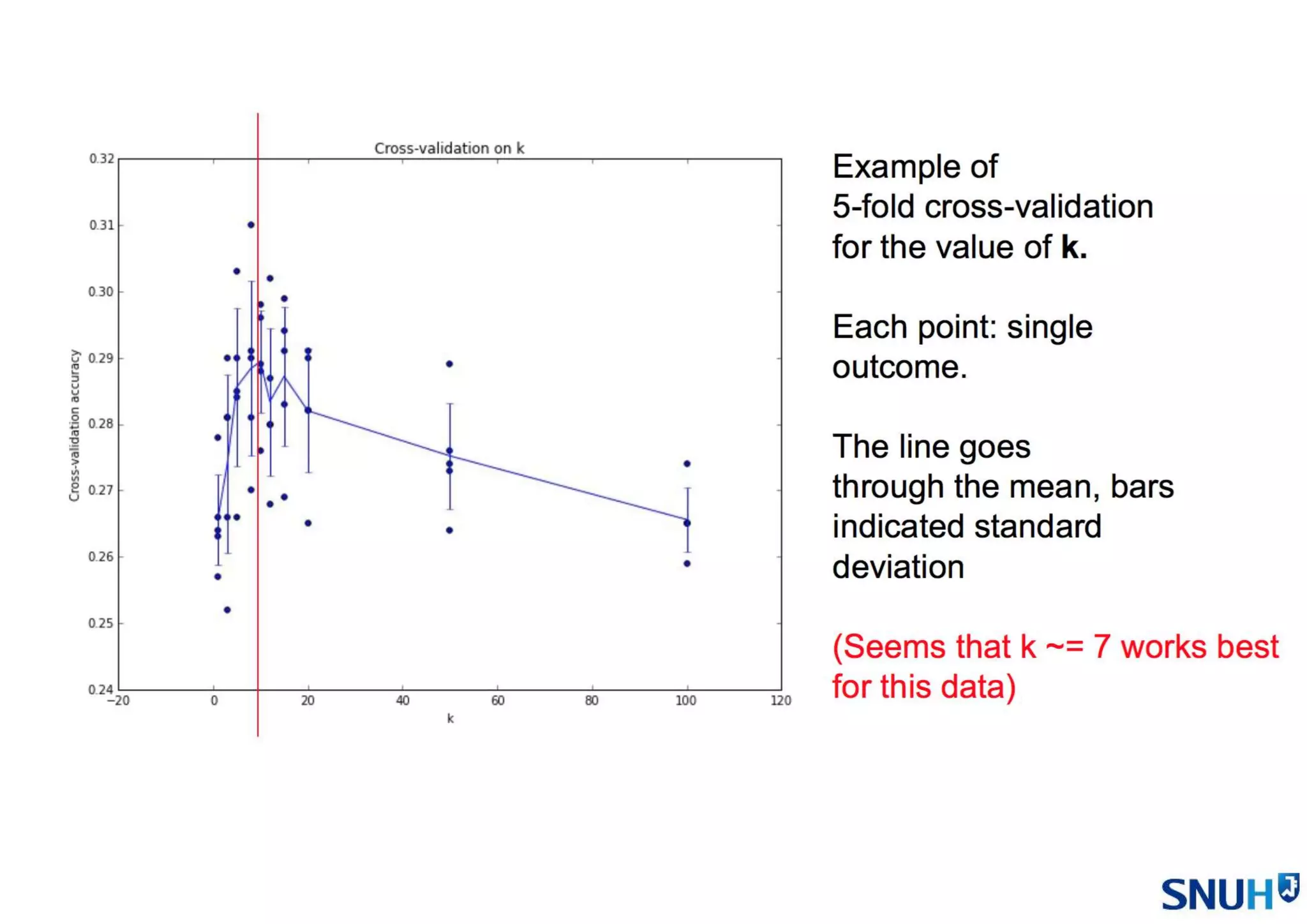
• Cross Validation
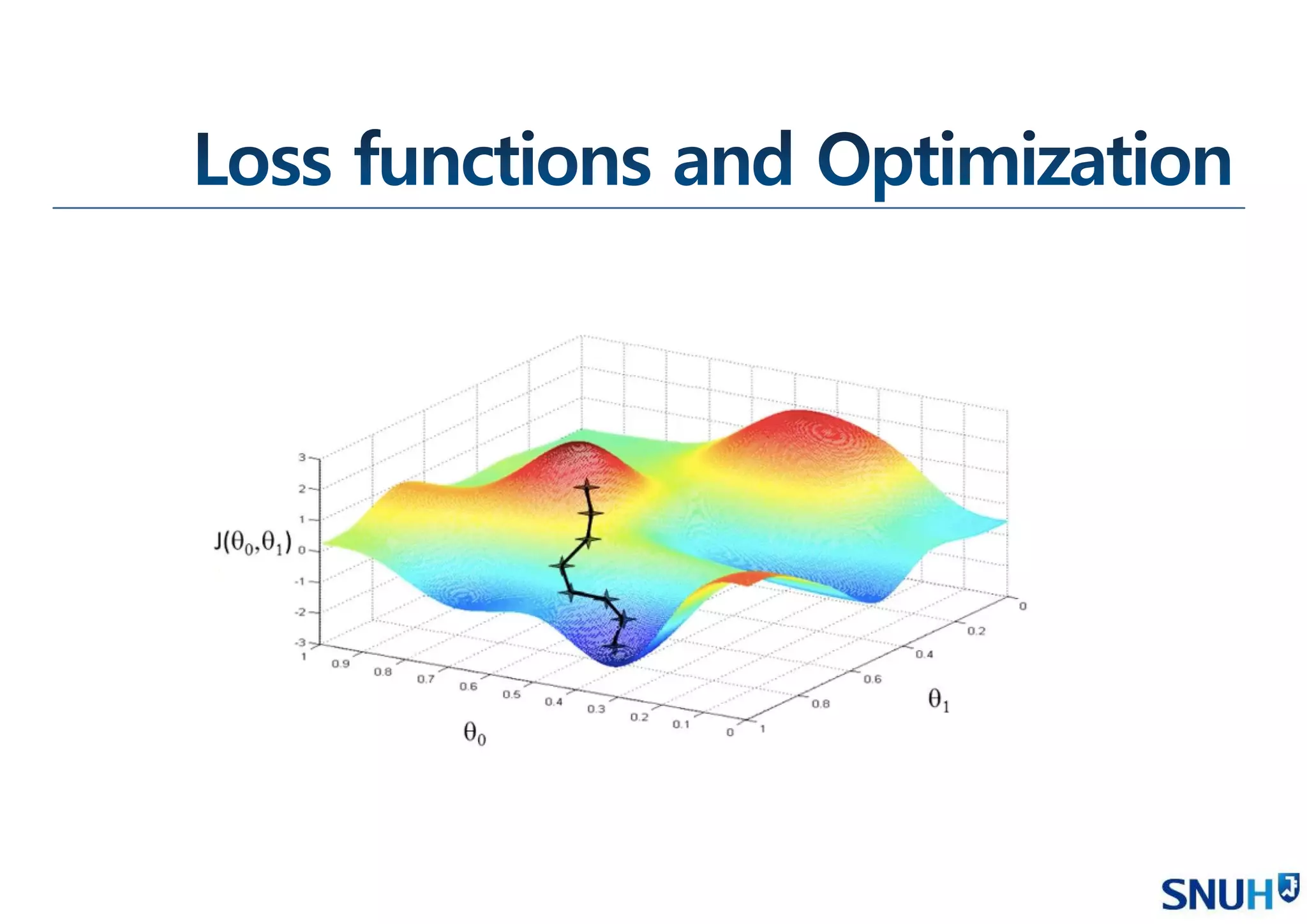
• Loss Function
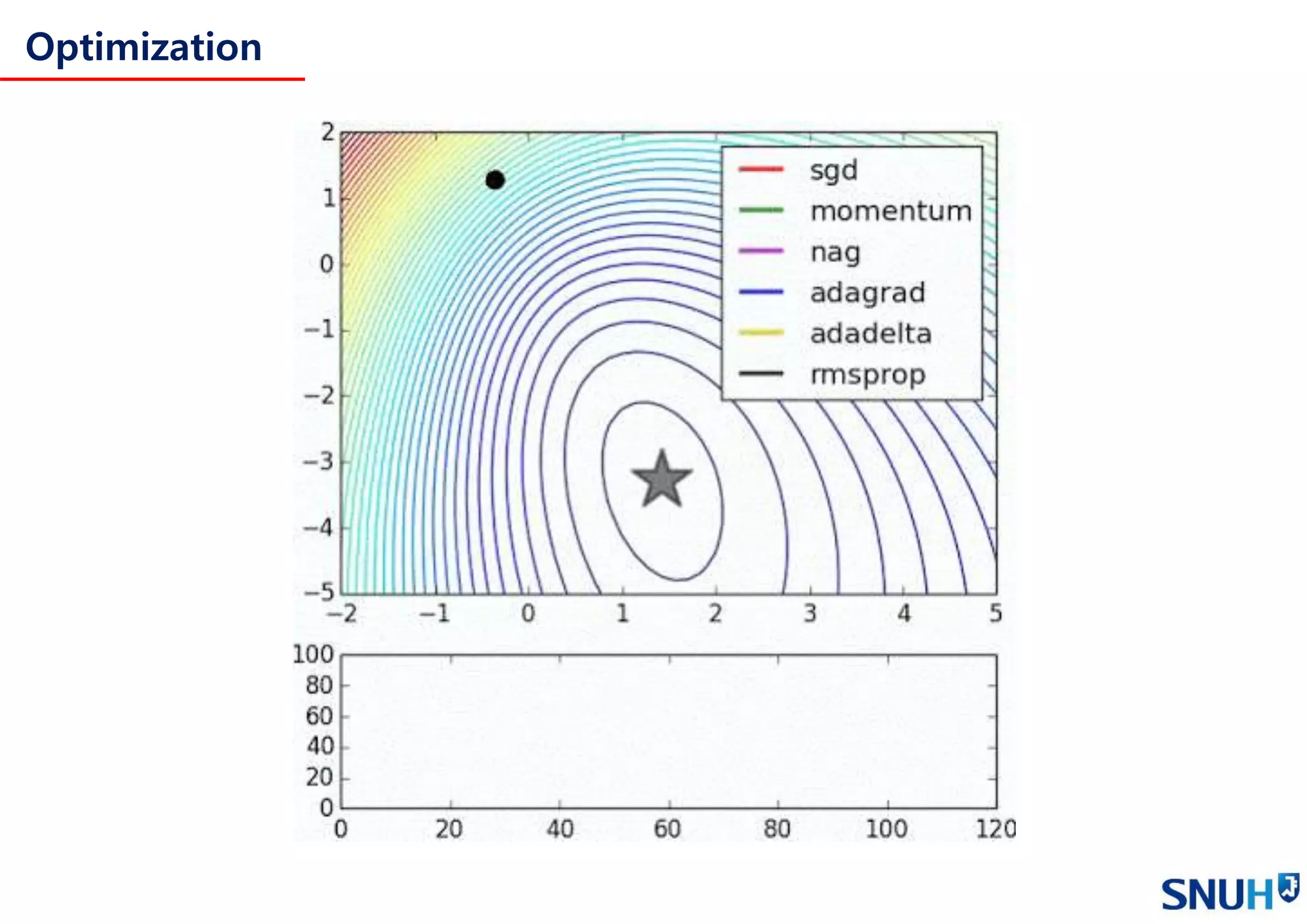
• Optimization
Gradient Descent
Mini-batch Gradient Descent
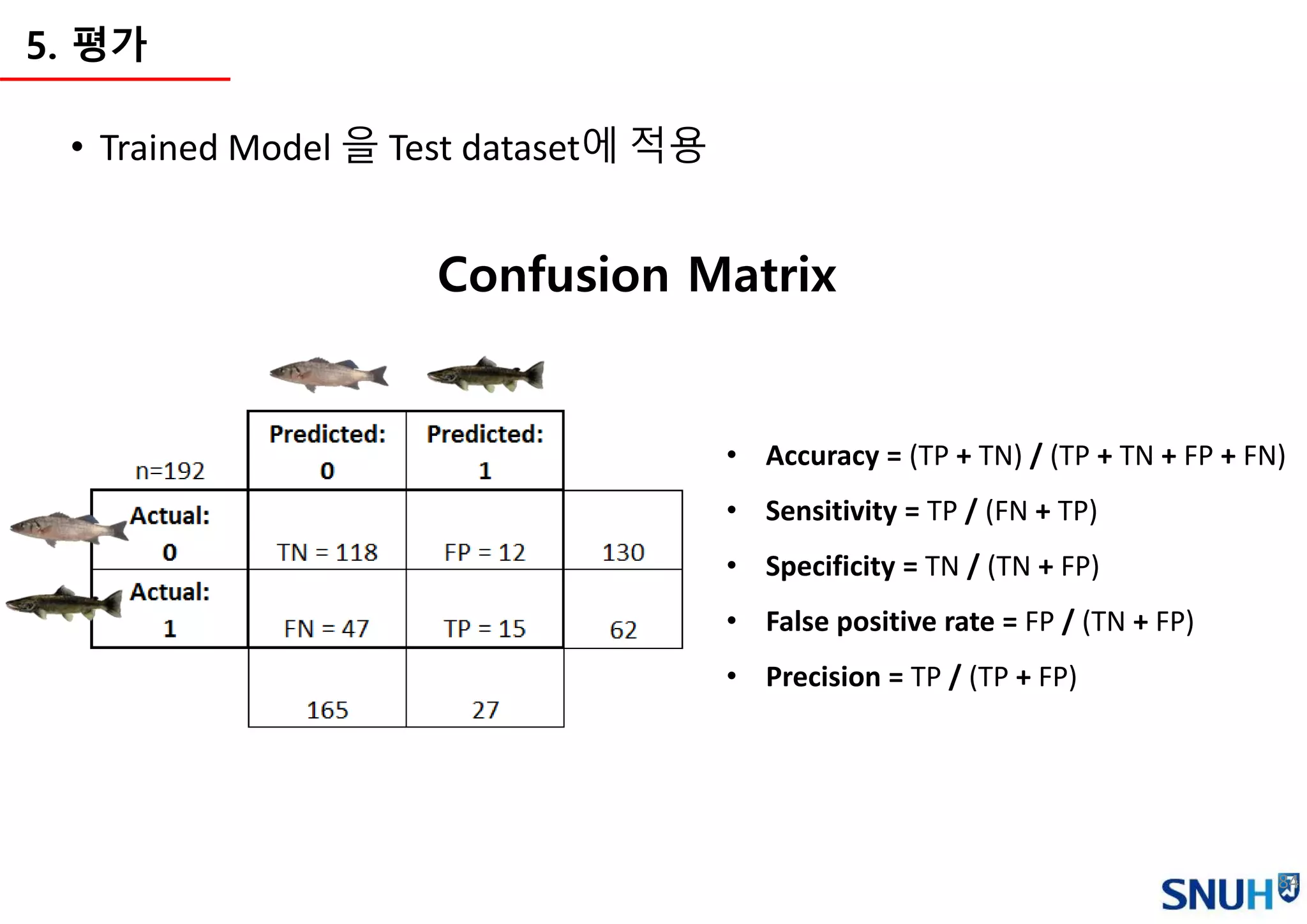
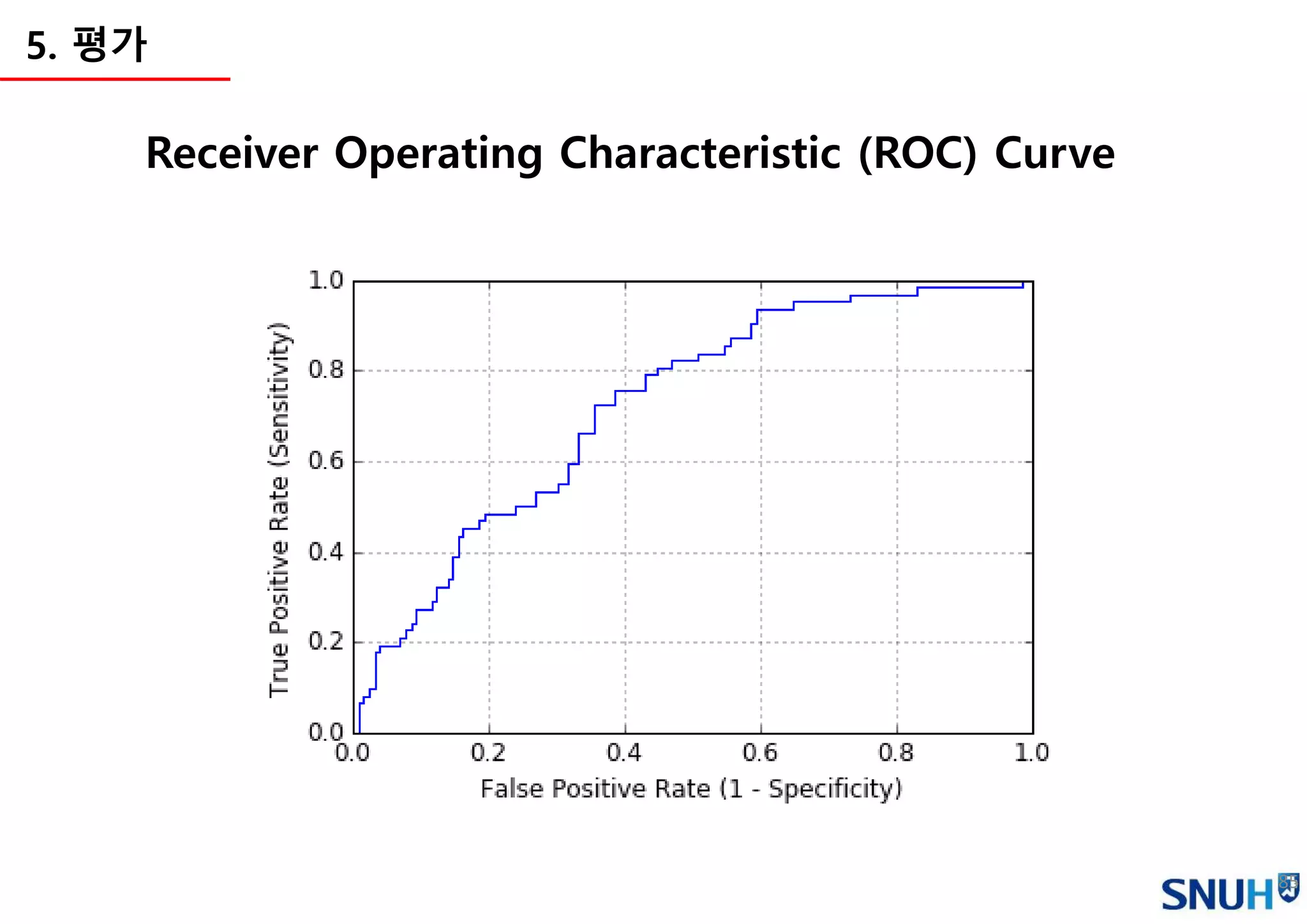
5. 평가
• N/A
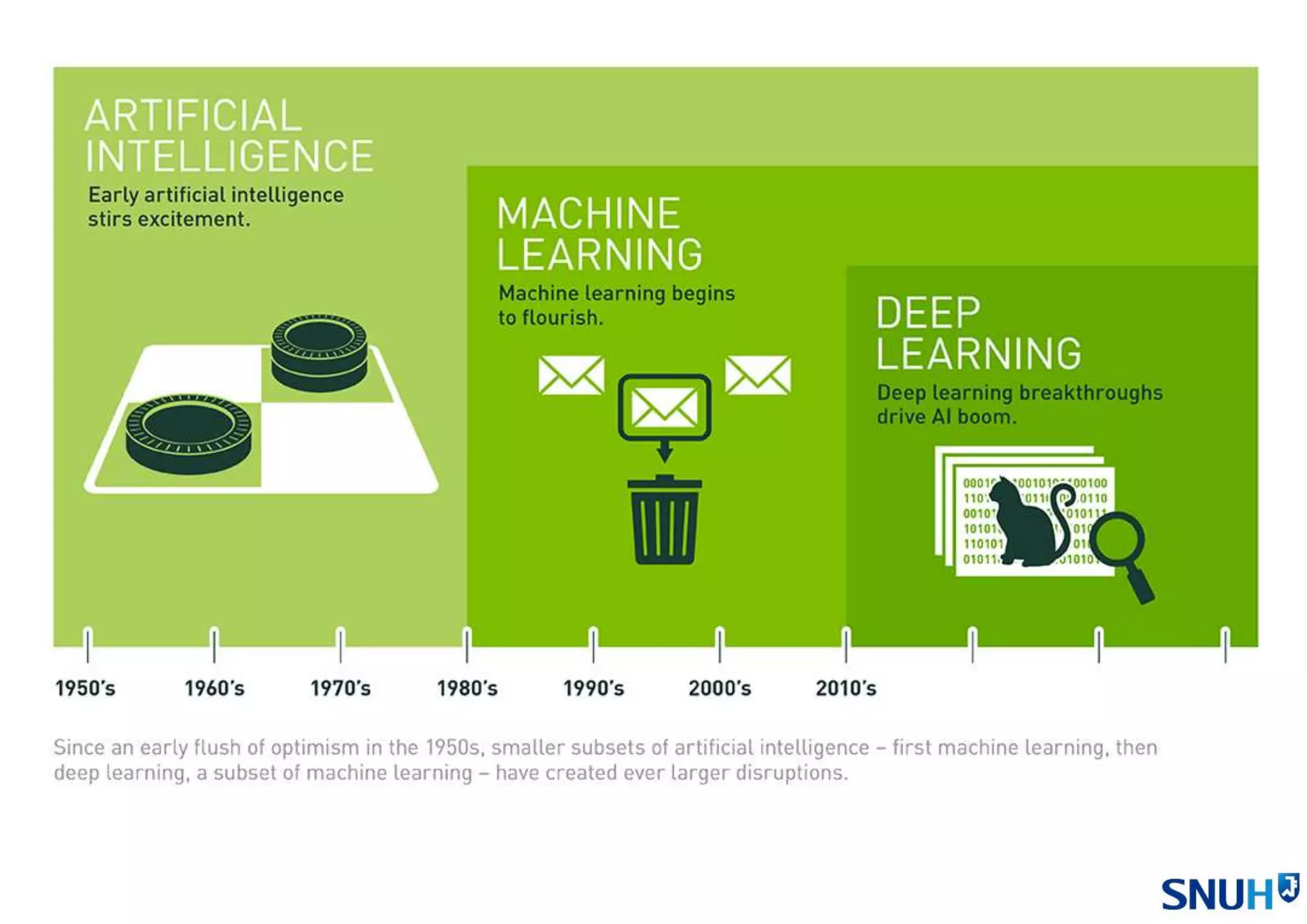
1. (p6) NVIDIA,“What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?”,
https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
2. (p8, p15, p18) Andrew L. Beam, machine learning and medicine, Deep Learning 101 - Part 1: History and Background,
https://beamandrew.github.io/deeplearning/2017/02/23/deep_learning_101_part1.html
3. (p9) Yann’s Homepage, http://yann.lecun.com/exdb/lenet/
4. (p11) The New York Times, “How Many Computers to Identify a Cat? 16,000”,
https://www.nytimes.com/2012/06/26/technology/in-a-big-network-of-computers-evidence-of-machine-
learning.html?_r=1&
5. (p12-14, p34-36, p87-110, p112-145, p149) Standford, CS231n, http://cs231n.stanford.edu/
6. (p16) Machine Learning Tutorial 2015 (NAVER)
7. (p17) AIRI 400, “인공지능의 개요, 가치, 그리고 한계” (김진형 박사)
8. (p19) CBINSIGHTS, “From Virtual Nurses To Drug Discovery: 106 Artificial Intelligence Startups In Healthcare”,
https://www.cbinsights.com/research/artificial-intelligence-startups-healthcare/
9. (p20) NEWSIS 기사, 구글 CEO "AI시대 맞춰 모든 제품 다시 생각 중“,
http://www.newsis.com/view/?id=NISX20170518_0014902945
10. (p21)Analytic Indai, “Infographic- Artificial Narrow Intelligence Vs. Artificial General Intelligence”,
https://analyticsindiamag.com/artificial-narrow-vs-artificial-general/
151.
11. (p22) WEFexpert panel interviews, press release, company website: A.T Kearney analysis
12. (p24) Machine Learning for Healthcare, MIT. Spring 2017, https://mlhc17mit.github.io/
13. (p25) Medium, AI in Healthcare: Industry Landscape, https://techburst.io/ai-in-healthcare-industry-landscape-
c433829b320c
14. (p27) 최윤섭의 Healthcare Innovation, “인공지능의 시대, 의사의 새로운 역할은”,
http://www.yoonsupchoi.com/2018/01/03/ai-medicine-12/
15. (p28-29) 최윤섭의 Healthcare Innovation, “인공지능은 의사를 대체하는가”,
http://www.yoonsupchoi.com/2017/11/10/ai-medicine-9/
16. (p30) Eric Topol Twitter, https://twitter.com/erictopol/status/931906798432350208
17. (p31) 동아일보, http://dimg.donga.com/wps/NEWS/IMAGE/2017/06/19/84945511.1.edit.jpg
18. (p32) 최윤섭의 Healthcare Innovation, “인공지능의 시대, 의사는 무엇으로 사는가”,
http://www.yoonsupchoi.com/2017/12/29/ai-medicine-11/
19. (p33) Medium, “Why AI will not replace radiologists” https://towardsdatascience.com/why-ai-will-not-replace-
radiologists-c7736f2c7d80
20. (p39, p70, p148) AIRI 400, “Machine Learning 기초” (이광희 박사)
21. (p40) ciokorea 인터뷰, “데이빗 마이어에게 듣는 머신러닝과 네트워크와 보안”, http://www.ciokorea.com/news/34370
22. (p41) Data Science Central, https://www.datasciencecentral.com/profiles/blogs/types-of-machine-learning-algorithms-
in-one-picture
23. (p42, p71-72) 모두의 연구소, “기계학습/머신러닝 기초”, http://www.whydsp.org/237
152.
24. (p43, p52,p54-56, p73) AIRI 400, 패턴인식-기계학습의 원리, 능력과 한계 (김진형 박사)
25. (p44-45) Pinterest, https://www.pinterest.co.uk/pin/53832158029479772/
26. (p53) BRILLIANT, Feature Vector, https://brilliant.org/wiki/feature-vector/
27. (p57) The NEJM, “Chocolate Consumption, Cognitive Function, and Nobel Laureates”,
http://www.nejm.org/doi/pdf/10.1056/NEJMon1211064
28. (p59) tSL, the Science Life, “빅데이터: 큰 용량의 역습 – 차원의 저주”, http://thesciencelife.com/archives/1001
29. (p60) Random Musings’ blog, https://dmm613.wordpress.com/author/dmm613/
30. (p63) Steemit, “A Tour of Machine Learning Algorithms”, https://steemit.com/science/@techforn10/a-tour-of-machine-
learning-algorithms
31. (p64)
• Deep Thoughts, “Demystifying deep”, https://devashishshankar.wordpress.com/2015/11/13/demystifying-deep-
neural-networks/
• Brian Dolhansky, “Artificial Neural Networks: Linear Multiclass Classification (part3)”,
http://briandolhansky.com/blog/2013/9/23/artificial-neural-nets-linear-multiclass-part-3
• Statistical Pattern Recognition Toolbox for Matlab, “Examples: Statistical Pattern Recognition Toolbox”,
https://cmp.felk.cvut.cz/cmp/software/stprtool/examples.html#knnclass_example
32. (p65) Xu Cui’s blog, SVM regression with libsvm, http://www.alivelearn.net/?p=1083
33. (p70)
• Sanghyukchun’s blog, Machine Learning 스터디 (7) Convex Optimization, http://sanghyukchun.github.io/63/
• Coursera, Machine Learning (Standford), https://ko.coursera.org/learn/machine-learning
153.
34. (p74) R,Pyrhon분석과 프로그래밍(by R Friend), [R 기계학습] 과적합(Over-fitting), Bias-Variance Trade-off (Delimma),
http://rfriend.tistory.com/189
35. (p76-79) 2nd Summer School on Deep Learning for Computer Vision Barcelona,
https://www.slideshare.net/xavigiro/training-deep-networks-d1l5-2017-upc-deep-learning-for-computer-vision
36. (p80-81) Medium, “Train/Test Split and Cross Validation in Python”, https://towardsdatascience.com/train-test-split-
and-cross-validation-in-python-80b61beca4b6
37. (p84-85) Ritchie Ng’s blog, “Evaluating a Classification Model”, https://www.ritchieng.com/machine-learning-evaluate-
classification-model/
38. (p86) “Getting Started with TensorFlow(2016), Giancarlo Zaccone, Packt”
39. (p103) WIKIPEDIA, “k-nearest neighbors algorithm”,
https://ko.wikipedia.org/wiki/K%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B
3%A0%EB%A6%AC%EC%A6%98
40. (p146) Deniz Yuret’s Homepage, “Alec Radford's animations for optimization algorithms”,
http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html
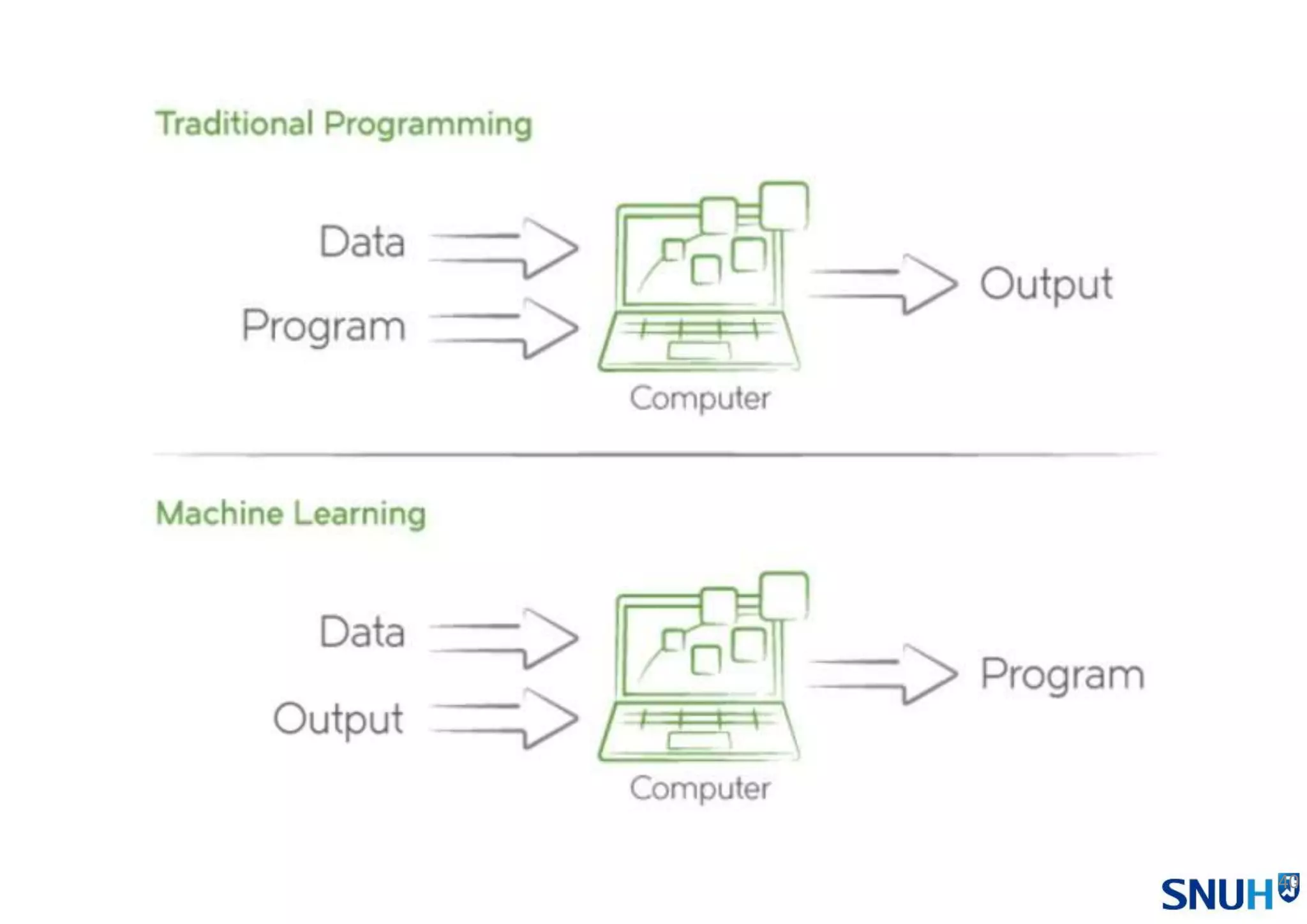
#41 동일한 문제를 놓고 다음과 같은 차이.
기존 프로그래밍 방법은 데이터와 알고리즘을 넣어 컴퓨터가 계산을 수행하고 나서 출력결과를 만들어 내는 과정으로 원하는 결과에 도달할 때까지 과정을 무한반복.
이에 반해 기계학습 알고리즘 접근법은 데이터와 출력결과를 넣게 되면 컴퓨터가 알고리즘을 만들어낸다. 알고리즘의 성능은 데이터의 양과 질에 달려있고, 얼마나 많은 학습을 반복하냐에 달려있다.


















































































![34. (p74) R,Pyrhon 분석과 프로그래밍(by R Friend), [R 기계학습] 과적합(Over-fitting), Bias-Variance Trade-off (Delimma),
http://rfriend.tistory.com/189
35. (p76-79) 2nd Summer School on Deep Learning for Computer Vision Barcelona,
https://www.slideshare.net/xavigiro/training-deep-networks-d1l5-2017-upc-deep-learning-for-computer-vision
36. (p80-81) Medium, “Train/Test Split and Cross Validation in Python”, https://towardsdatascience.com/train-test-split-
and-cross-validation-in-python-80b61beca4b6
37. (p84-85) Ritchie Ng’s blog, “Evaluating a Classification Model”, https://www.ritchieng.com/machine-learning-evaluate-
classification-model/
38. (p86) “Getting Started with TensorFlow(2016), Giancarlo Zaccone, Packt”
39. (p103) WIKIPEDIA, “k-nearest neighbors algorithm”,
https://ko.wikipedia.org/wiki/K%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B
3%A0%EB%A6%AC%EC%A6%98
40. (p146) Deniz Yuret’s Homepage, “Alec Radford's animations for optimization algorithms”,
http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html](https://image.slidesharecdn.com/deeplearningforai1-180720232122/75/Deep-Learning-for-AI-1-153-2048.jpg)



![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)




![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)






















