2
CNN(Convolutional Neural Network)의역사
CNN은 1989년 LeCun이 발표한 논문 “Backpropagation applied to
handwritten zip code recognition”에서 처음 소개됨
2003년 Behnke의 논문 “Hierarchical Neural Networks for Image
Interpretation”
을 통해 일반화 됨
Simard의 논문 “Best Practices for Convolutional Neural Networks
Applied to Visual Document Analysis”에서 단순화
3.
3
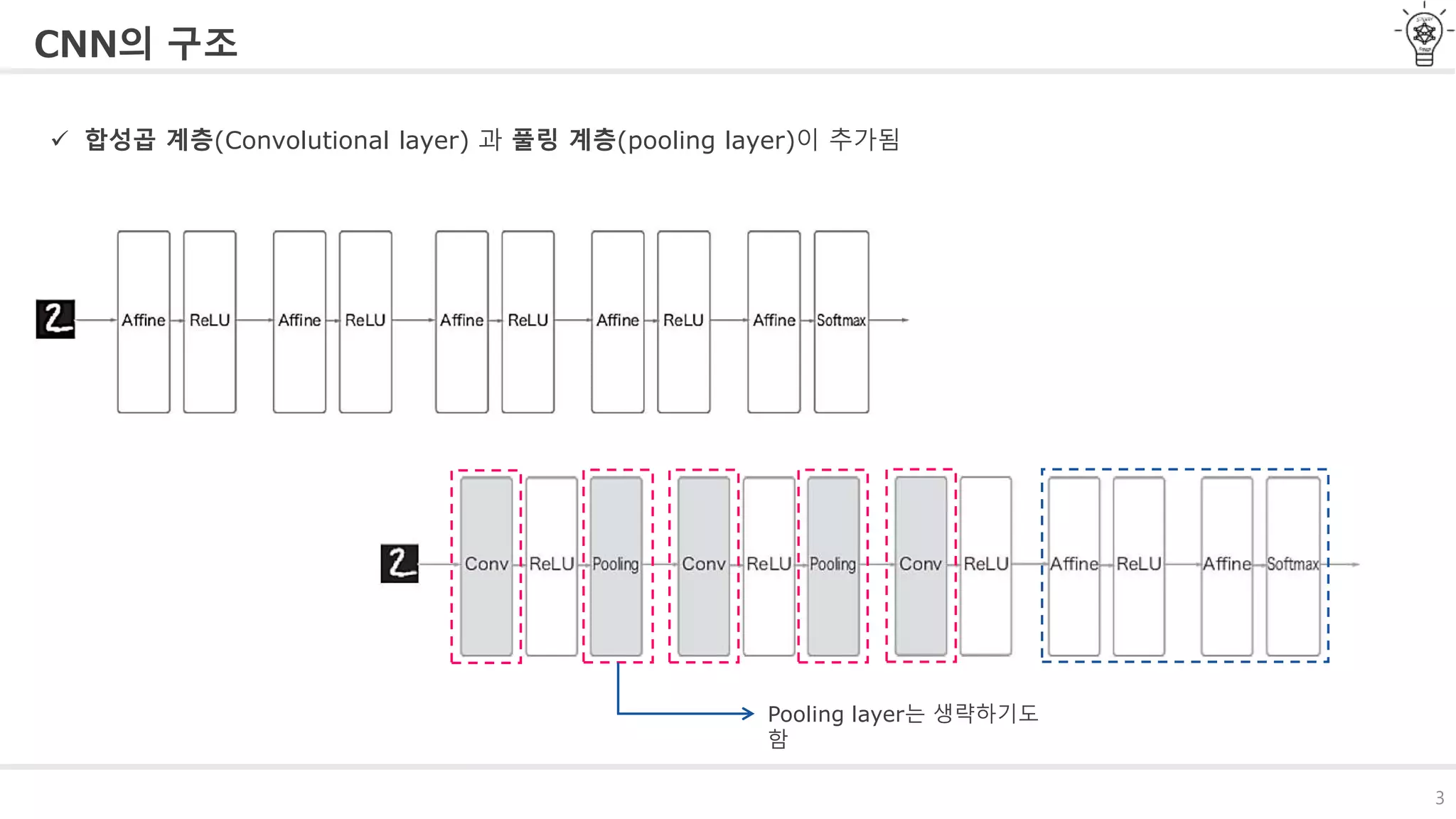
CNN의 구조
합성곱계층(Convolutional layer) 과 풀링 계층(pooling layer)이 추가됨
Pooling layer는 생략하기도
함
4.
4
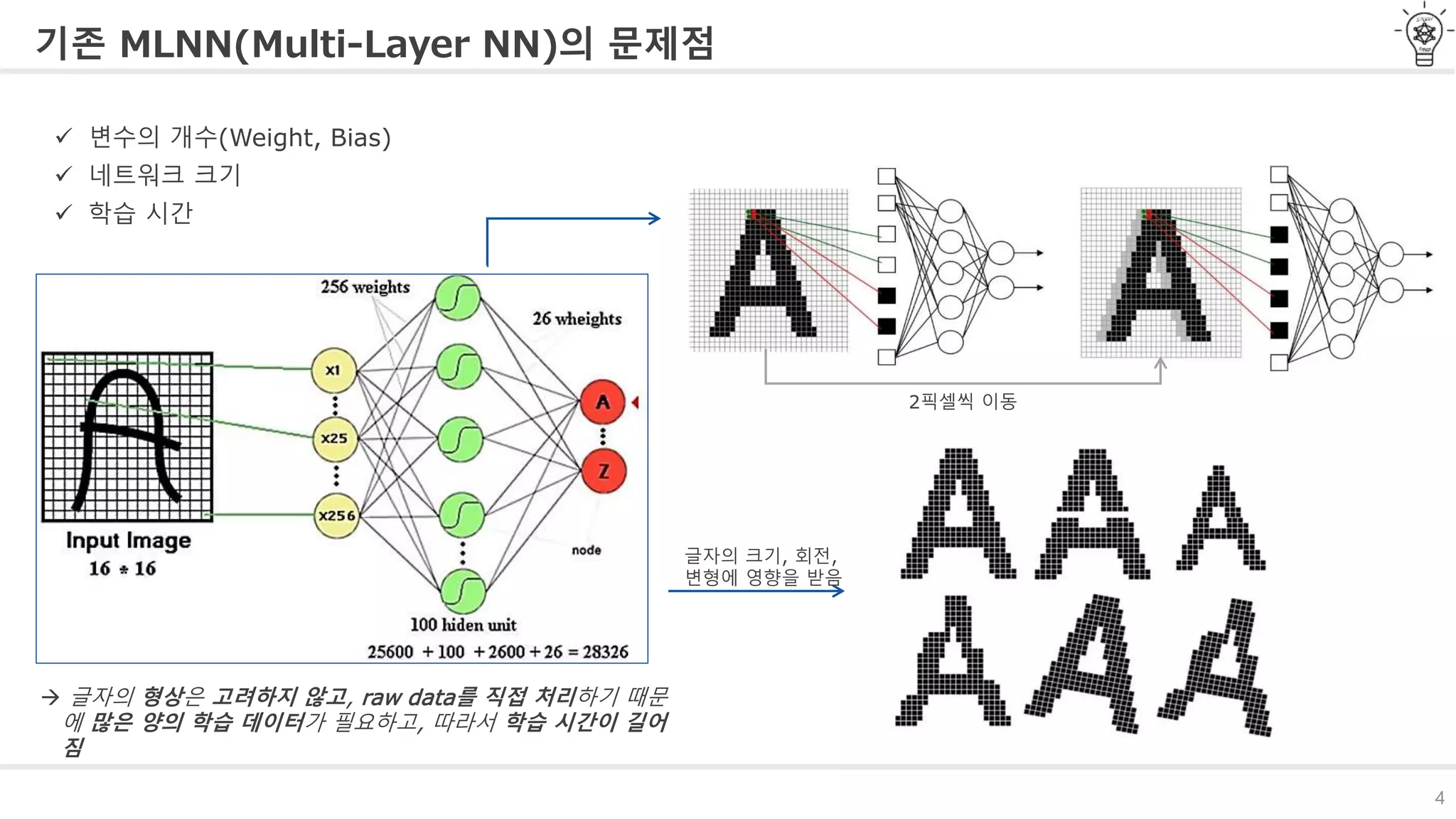
기존 MLNN(Multi-Layer NN)의문제점
변수의 개수(Weight, Bias)
네트워크 크기
학습 시간
글자의 형상은 고려하지 않고, raw data를 직접 처리하기 때문
에 많은 양의 학습 데이터가 필요하고, 따라서 학습 시간이 길어
짐
2픽셀씩 이동
글자의 크기, 회전,
변형에 영향을 받음
5.
5
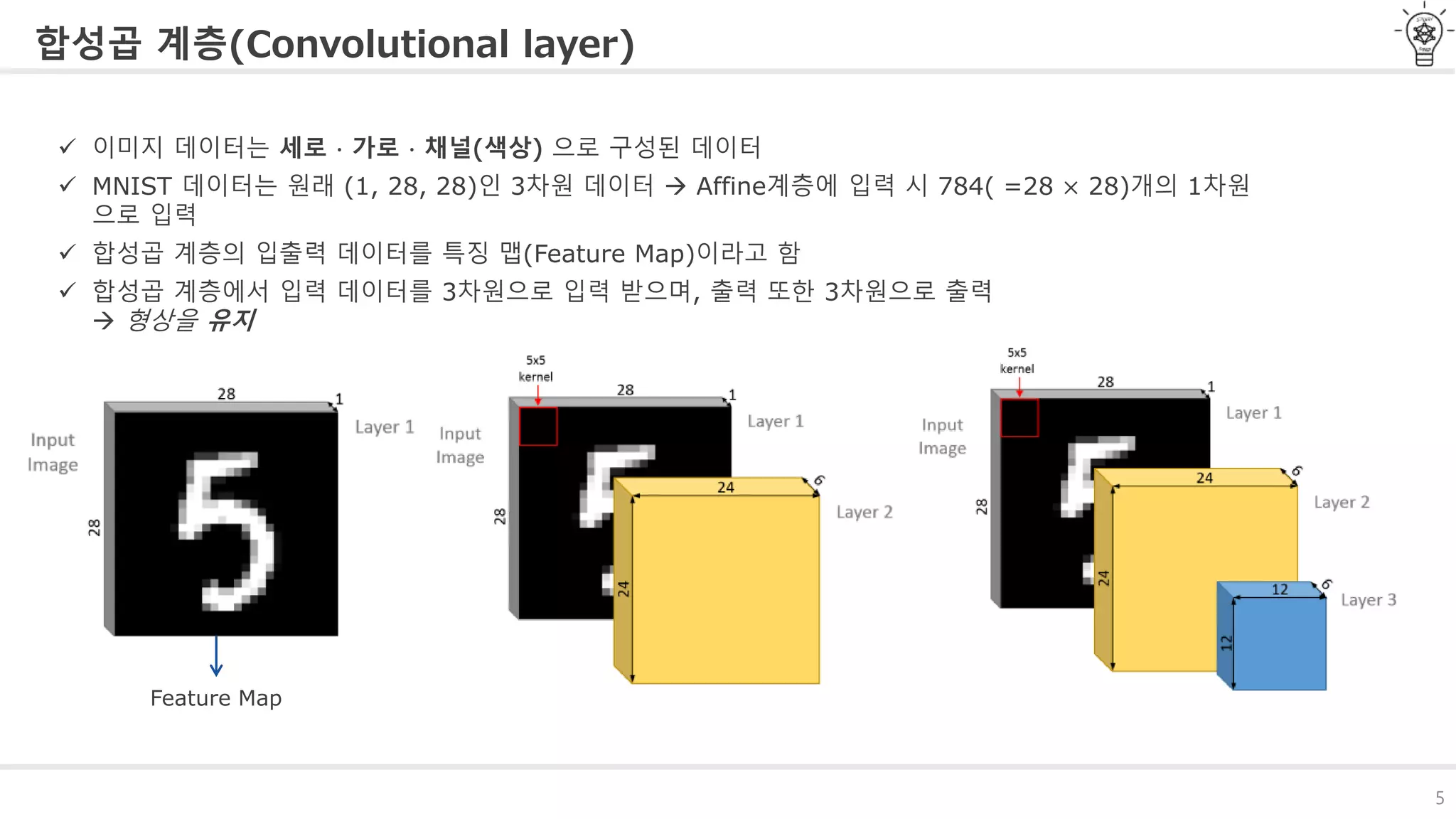
합성곱 계층(Convolutional layer)
이미지 데이터는 세로 ∙ 가로 ∙ 채널(색상) 으로 구성된 데이터
MNIST 데이터는 원래 (1, 28, 28)인 3차원 데이터 Affine계층에 입력 시 784( =28 × 28)개의 1차원
으로 입력
합성곱 계층의 입출력 데이터를 특징 맵(Feature Map)이라고 함
합성곱 계층에서 입력 데이터를 3차원으로 입력 받으며, 출력 또한 3차원으로 출력
형상을 유지
Feature Map
6.
6
합성곱 계층 -연산
합성곱 계층에서 연산 수행 필터(커널) 연산
데이터와 필터의 형상을 (높이height, 너비width)로 표기
윈도우window 를 일정 간격(Stride)으로 이동하며 계산
• 단일 곱셈-누산(FMA, Fused Multiply-Add)
1 ∗ 2 + 2 ∗ 0 + 3 ∗ 1 + 0 ∗ 0 + 1 ∗ 1 + 2 ∗ 2 + 3 ∗ 1 + 0 ∗ 0 + 1 ∗ 2 = 15
4
4
(3, 3)
Window
= 커널
필터의 parameter가
가중치(W)에 해당
7.
7
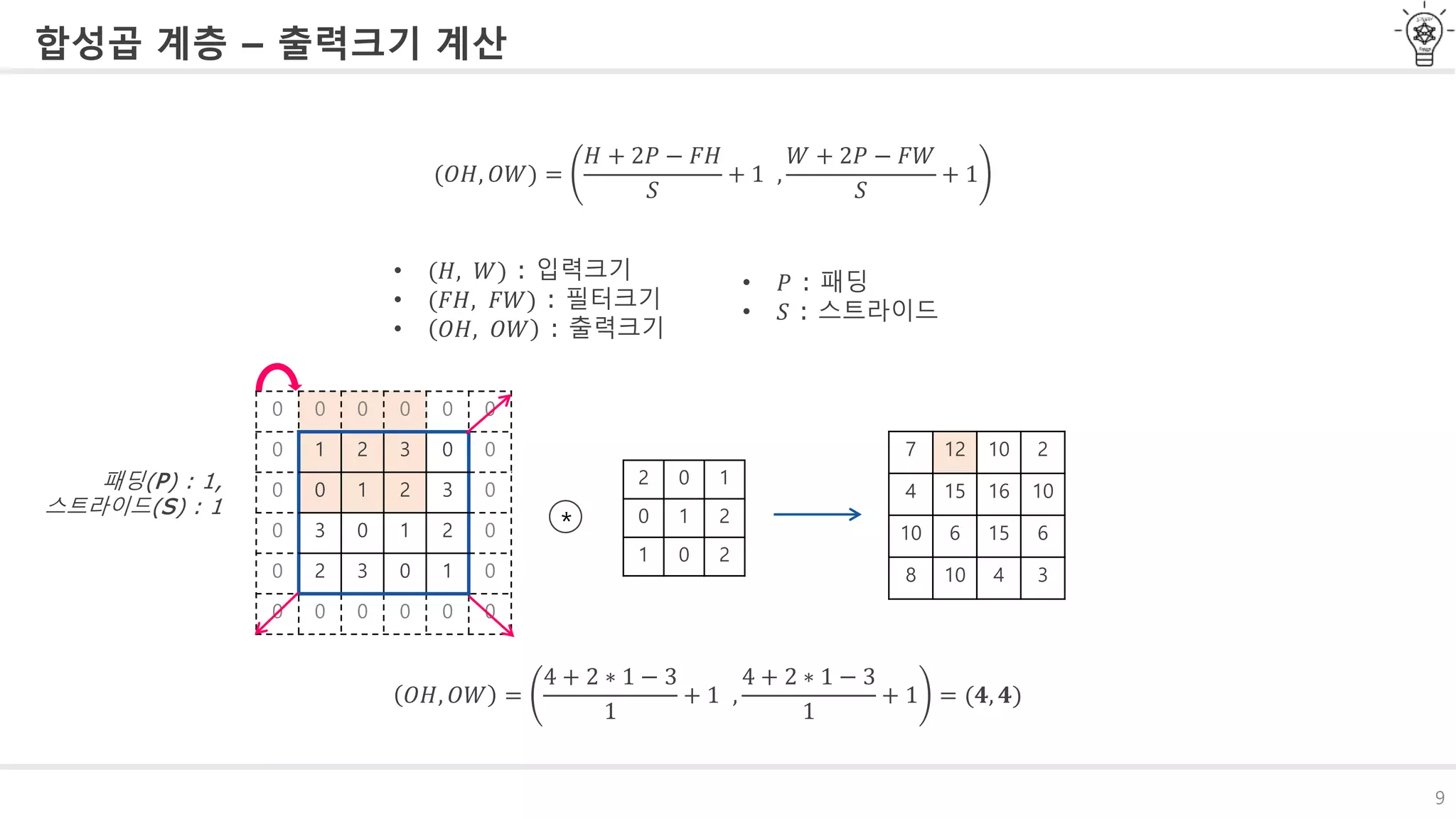
합성곱 계층 -패딩
합성곱 연산을 수행하기 전, 입력데이터 주변을 특정값으로 채우는 것을 패딩Padding이라고 함
패딩은 출력데이터의 공간적 크기(Spatial size)를 조절하기 위해 사용
패딩은 hyperparameter로 어떤 값으로 채울지 결정할 수 있음 보통 zero-padding을 주로 사용
0 0 0 0 0 0
0 1 2 3 0 0
0 0 1 2 3 0
0 3 0 1 2 0
0 2 3 0 1 0
0 0 0 0 0 0
2 0 1
0 1 2
1 0 2
**
7 12 10 2
4 15 16 10
10 6 15 6
8 10 4 3
1폭짜리 padding
Padding을 사용하는 이유는?
Padding을 사용하지 않을 경우, 데이터의 Spatial 크기는 Conv 레이어를 지날때 마다 작
아지게 되고, 가장자리의 정보들이 사라지게 된다.
8.
8
합성곱 계층 -스트라이드
필터를 적용하는 위치의 간격을 스트라이드stride라고
스트라이드는 출력 데이터의 크기를 조절하기 위해 사용
Stride 값은 어떤것이 좋을까?
보통 1과 같이 작은 값이 더 잘 작동한다. 또한, strid가 1일 경우 데이터의 spatial 크기는
Pooling
계층에서만 조절하게 할 수 있다.
11
합성곱 계층 –3차원 데이터의 연산
𝐶, 𝐻, 𝑊 𝐶, 𝐹𝐻, 𝐹𝑊 1, 𝑂𝐻, 𝑂𝑊
𝐶, 𝐻, 𝑊 𝐹𝑁, 𝐶, 𝐹𝐻, 𝐹𝑊 𝐹𝑁, 𝑂𝐻, 𝑂𝑊
FN개의 필터(가중치)를
사용해 FN 채널 수를 가지는
출력 데이터 생성
𝐹𝑁, 1, 1+ 𝐹𝑁, 𝑂𝐻, 𝑂𝑊
입력데이터
필터
편향
출력데이
터
12.
12
합성곱 계층 –배치 처리
𝑁, 𝐶, 𝐻, 𝑊 𝑁, 𝐹𝑁, 𝐶, 𝐹𝐻, 𝐹𝑊 𝑁, 𝐹𝑁, 𝑂𝐻, 𝑂𝑊 𝐹𝑁, 1, 1+ 𝑁, 𝐹𝑁, 𝑂𝐻, 𝑂𝑊
입력데이터
필터
편향
출력데이
터
N 개의 데이터 N 개의 데이터 N 개의 데이터
데이터의 차원을 늘려 4차원 데이터로 저장
(데이터 수, 채널 수, 높이, 너비)로 저장
13.
13
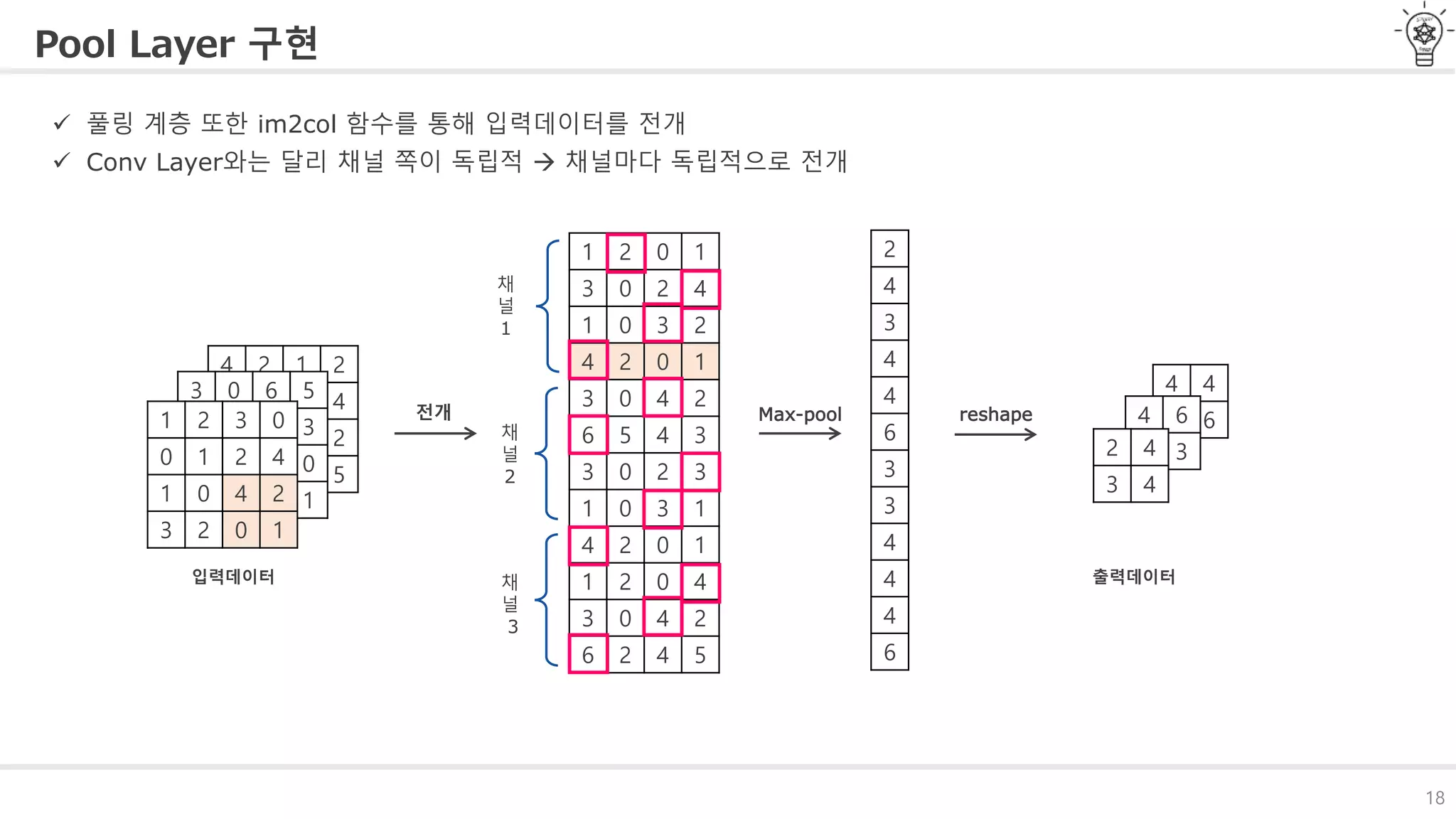
풀링 계층 (PoolingLayer)
데이터의 공간적 크기Spatial size를 축소하는데 사용
(보통)풀링의 윈도우 크기와 스트라이드는 같은 값으로 설정 (e.g 윈도우: 3X3, 스트라이드 : 3)
1 2 1 0
0 1 2 3
3 0 1 2
2 4 0 1
합성곱 계층(Conv Layer)에서도 Padding과 Stride를 통해 출력 데이터의 크기를 조절할 수 있는데?
Conv 레이어에서는 출력 데이터의 Spatial 크기를 입력데이터의 크기를 그대로 유
지하고,
Pooling 계층에서만 Spatial 크기를 조절할 수 있도록 한다.
2
1 2 1 0
0 1 2 3
3 0 1 2
2 4 0 1
2 3
1 2 1 0
0 1 2 3
3 0 1 2
2 4 0 1
2 3
4
1 2 1 0
0 1 2 3
3 0 1 2
2 4 0 1
2 3
4 2
Max-pooling
Stride = 2
14.
14
풀링 계층 -특징
학습해야 할 매개변수가 없다 최대값 or 평균값을 취하기 때문에
채널 수가 변하지 않는다 입력 데이터의 채널 수를 그대로 출력 데이터로
입력의 변화에 영향을 적게 받는다(강건하다)
채널 수 그대로!
1 2 0 7 1 0
0 9 2 3 2 3
3 0 1 2 1 2
2 4 0 1 0 1
6 0 1 2 1 2
2 4 0 1 8 1
9 7
6 8
1 1 2 0 7 1
3 0 9 2 3 2
2 3 0 1 2 1
3 2 4 0 1 0
2 6 0 1 2 1
1 2 4 0 1 8
9 7
6 8
15.
15
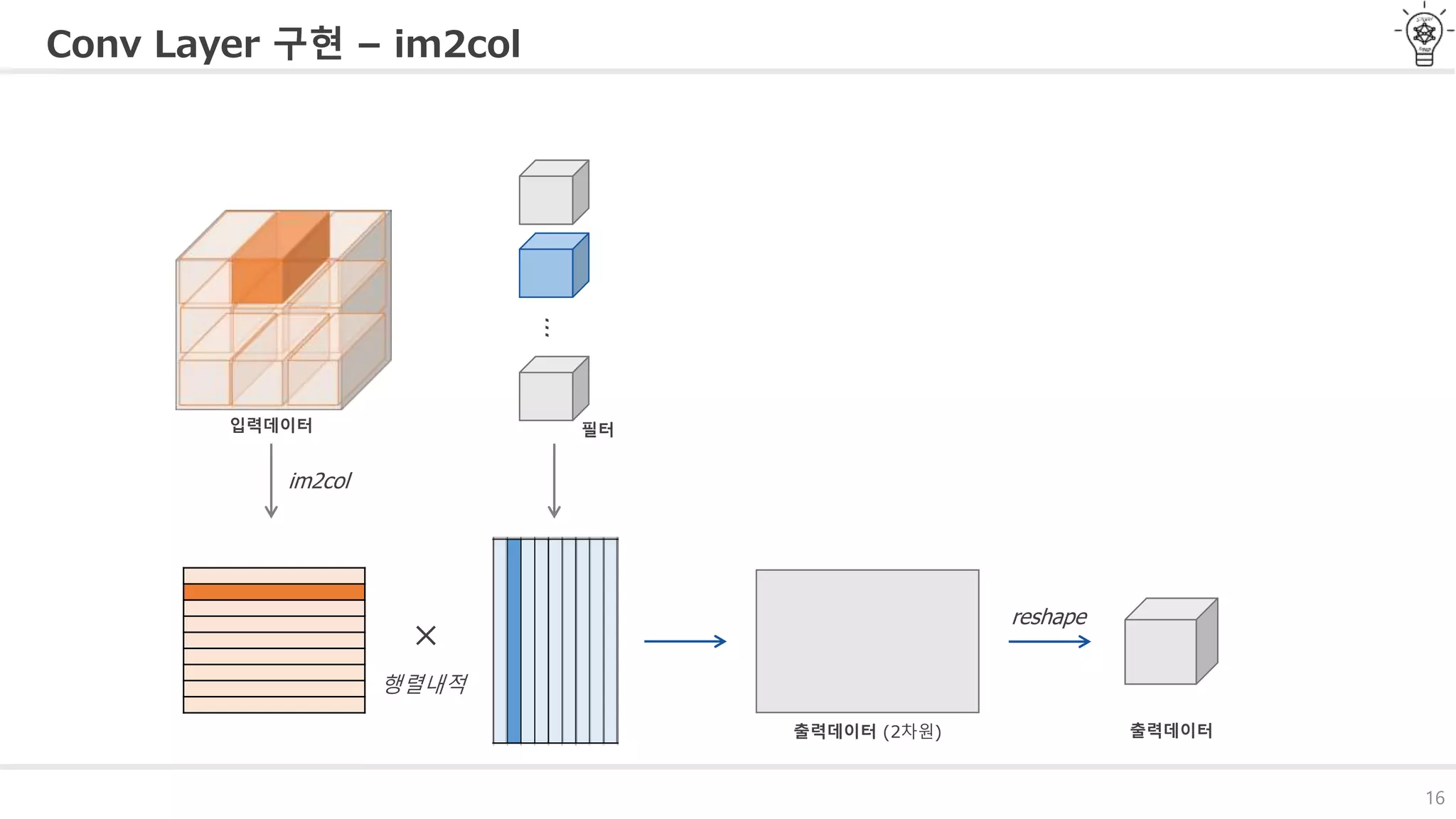
Conv Layer 구현– im2col
im2col 함수를 통해 입력데이터를 필터링(가중치 계산)하기 쉽도록 전개 Caffe, Chainer등에서 제공
Numpy 에서 for문 사용 방지
im2col을 적용하여 3차원의 데이터를 2차원으로 변환
im2col
20
CNN 시각화
앞의‘train_convent.py’ 예제 에서 필터의 형상 = (30, 1, 5, 5)
필터의 크기가 5 X 5며, 채널이 1개 회색조 이미지로 시각화 할 수 있음
‘visualize_filter.py’ 소스코드 확인 ConV계층에서의 가중치(필터) 시각화
학습 후 필터는 흰색에서 검은색으로 변화하는 필터와 Blob(국소적으로 덩어리진 영역) 등으로 변화
학습 전 학습 후
22
CNN 시각화 –층 깊이에 따른 정보
계층이 깊어질 수록 추출되는 정보는 더 추상화 됨
처음 층에는 단순한 에지 텍스처 사물의 일부
23.
23
CNN 종류 -LeNet
손글씨 숫자를 인식하는 네트워크, 1998년에 제안
합성곱 계층과 풀링 계층(단순 서브샘플링)으로 이루어짐
활성화 함수로 Sigmoid 함수 사용
24.
24
CNN 종류 -AlexNet
2012년 ImageNet ILSVRC에서 1위
활성화 함수로 ReLu 사용
LRN(Local Response Normalization) : 국소적 정규화 계층 사용
드롭아웃(Dropout) 사용
25.
25
CNN 종류 -GoogLeNet
• Convolution
• Pooling
• Softmax
• Concat/Normalize
2014년 ImageNet ILSVRC에서 1위
“Inception Module” 개념을 도입하여 네트워크의 파라미터 수를 대폭 줄임 9개의 Inception Module
AlexNet의 parameter 개수는 60M개, GoogLeNet은 4M개
#3 먼저, CNN의 역사에 대해 간단하게 살펴보겠습니다.
CNN은 1989년 LeCun이 발표한 논문 ~ 에서 처음 소개 되었습니다.
필기체 인식에서는 의미있는 결과가 나왔지만 범용화하는데는 미흡한 단계였습니다.
1998년도에 LeNet이라는 CNN 네트워크가 나오면서 2003년 논문 ~와 ~ 을 통해 단순화 되면서 CNN분야에 많은 연구가 진행되게 됩니다.
#4 CNN의 구조를 살펴보겠습니다.
저희가 3, 4, 5, 6장에서 구현했던 신경망은 모든 뉴런과 연결되어 있는 완전 연결 계층으로 이루어져 있었습니다.
이를 Affine 계층으로 5장에서 구현했었습니다.
CNN은 Affine계층이 아닌 그림과 같이 합성곱 계층과 풀링계층이 추가되어 이루어져 있습니다.
하지만 마지막에는 완전연결계층과 마찬가지로 Affine계층과 소프트맥스 계층을 일반적으로 사용합니다.
#5 기존의 Multi-Layer Neural Network의 문제점은
변수의 개수, 네트워크 크기, 학습시간 세가지 문제가 발생할 수 있습니다.
예를 들어 MLNN을 이용해서 그림과 같이 16 * 16 크기의 필기체를 인식하는
네트워크를 만든다고 하면, hidden layer가 한 층이고 100개의 뉴런을 가지고 있는 경우
이 네트워크에 필요한 가중치와 bias는 총 28326개가 필요합니다.
만약, hidden layer를 한층 더 사용할 경우 파라미터 개수는 엄청 많아지게 됩니다.
그리고, 그림과 같이 글자를 전체적으로 2픽셀씩 이동하게 되면 새로운 학습데이터로 처리해줘야 하는 문제점이 있습니다.
또한, 글자의 크기, 회전, 변형이 있게 되면, 이에 대한 새로운 학습데이터를 넣어줘야 하는 문제가 있습니다.
#6 이러한 문제를 해결하고자 만들어진것이 합성곱 계층입니다.
앞의 필기체나 MNIST 데이터 같은 이미지 데이터는 일반적으로 세로, 가로, 채널
이렇게 3차원으로 구성된 데이터입니다.
Affine 계층에서는 이 3차원 데이터를 1차원 데이터로 바꿔 입력했지만
합성곱에서는 3차원 데이터를 입력해줍니다.
#7 그럼, 합성곱 계층에서 연산이 어떻게 이루어지는지 알아보겠습니다.
데이터와 필터의 모양을 (높이, 너비)로 나타냅니다. 여기서 입력데이터는 (4, 4)
필터는 (3, 3)입니다. (높이, 너비)의 형태를 윈도우라고 부릅니다.
합성곱 연산은 필터의 윈도우를 일정한 간격으로 이동해가며 계산합니다.
그림을 통해 계산 방법을 알아보겠습니다. 합성곱 연산은 입력데이터와 필터간에
서로 대응하는 원소끼리 곱한 후 총합을 구합니다.
이것을 Fused Multiply-Add라고합니다.
마지막으로 bias는 필터를 적용한 후에 더해 줍니다.
#8 합성곱 연산을 수행하기전에 입력데이터 경계값을 늘려
특정값을 채운 후 연산을 수행하기도 합니다. 이를 패딩이라고 하는데
패딩은 출력데이터의 공간적크기 즉 사이즈를 조절하기 위해 사용됩니다.
패딩에서 채울 값들은 하이퍼파라미터로 사용자가 직접 조절할 수 있습니다.
보통 zero-padding을 사용합니다.
#9 스트라이드에 대해서 알아보겠습니다.
스트라이드는 입력데이터에 필터를 적용할 때 이동할 간격을
조절하는 것을 말합니다.
스트라이드는 출력데이터의 크기를 조절하기 위해 사용합니다.
#10 패딩과 스트라이드를 적용하고, 입력데이터와 필터의 크기가 주어졌을때,
출력 데이터의 크기를 구하는 식은 다음과 같습니다.
아래의 그림은 패딩 1 스트라이드 1 일때의 출력데이터 크기를 구한
예제입니다.
출력크기가 정수가 아닌 경우에는 에러가 발생할 수 있는데, 보통 딥러닝 프레임워크에서는
반올림을 통해 에러없이 작동하도록 합니다.
#11 지금까지는 2차원 모양의 합성곱 연산을 알아봤습니다.
이제는 3차원 데이터의 합성곱 연산을 알아보겠습니다.
그림에서 보듯이 3개의 채널을 가진 (4,4)입력데이터와 3개의 채널을 가진 (3,3)필터를
패딩 0 스트라이드 1로 합성곱 연산을 하였을때 1개의 채널을 가진 (2,2) 출력데이터를 얻게됩니다.
여기서 주의할 점은 입력데이터와 필터의 채널 수가 같아야 합니다.
이를 이해하기 쉽게 블록으로 생각해보면 아래의 그림과 같습니다.
CNN의 특징이 입출력 데이터의 형상을 유지한다고 했습니다. 그럼 출력데이터 또한 3차원으로 출력되게 하려면
어떻게 해야할까요?
#12 출력데이터를 3차원으로 출력되게 하기 위해서는 필터를 여러 개 사용하면 됩니다.
그림처럼 필터를 FN개 사용하면 출력데이터는 FN채널을 가지는 3차원 데이터가 됩니다.
마찬가지로 편향 또한 FN채널을 가지는 (FN, 1, 1)의 모양이 되는데,
계산할때는 브로드캐스팅 되어 계산됩니다.
#13 CNN 또한 배치처리를 통해 연산을 수행합니다.
배치처리를 수행하기 위해 3차원의 데이터를 한 차원 늘려
4차원의 데이터로 만든 다음 배치처리를 수행합니다.
#14 이때까지 합성곱 계층에 대해 알아봤습니다.
이제는 CNN의 또다른 계층인 풀링계층에 대해 알아보겠습니다.
풀링계층은 합성곱 계층의 패딩과 스트라이드처럼
데이터의 공간적 크기를 축소하는데 사용합니다.
합성곱 계층은 앞에서 잠깐 스트라이드를 1로 사용한다고 했을때 설명드린것 처럼
출력데이터의 크기를 입력데이터의 크기 그대로 유지하고, 풀링계층에서만
크기를 조절합니다.
아래의 그림은 풀링 종류 중 맥스풀링을 사용하여 처리한 예제입니다.
풀링에는 맥스풀링 말고도 average pooling이 있는데 해당영역의 평균값을 계산하는 방법입니다.
보통 이미지 인식 분야에서는 주로 맥스풀링을 사용합니다.
#15 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#16 합성곱 계층과 풀링계층을 파이썬으로 구현하는 방법에 대해 알아보겠습니다.
합성곱 연산을 수행할 때 3차원의 데이터를 필터링하기 쉽게 im2col함수를 사용하여 2차원으로 변환
합니다. 그림과 같이 필터가 적용되는 영역을 컬럼단위로 변환합니다.
그림에서는 스트라이드를 겹치지않게 설정했습니다.
#17 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#18 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#19 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#20 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#21 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#22 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#23 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#24 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#25 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.
#26 풀링계층의 특징은 3가지가 있는데
입력데이터에서 최대값 또는 평균값을 취하기 때문에
학습해야 할 매개변수가 없습니다.
또한 입력데이터의 채널수 그대로 출력데이터로 나오기때문에
채널수 변하지 않습니다.
마지막으로 그림처럼 입력데이터가 오른쪽으로 밀리는 경우가 있어도
맥스풀링에는 영향을 크게 미치지 않는 특징이 있습니다.












![17
Conv Layer 구현 – im2col
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""
다수의 이미지를 입력받아 2차원 배열로 변환한다(평탄화)
Parameters
------------
:param input_data: (데이터 수, 채널 수, 높이, 너비) 입력 데이터
:param filter_h: 필터의 높이 ,:param filter_w: 필터의 너비
:param stride: 스트라이드 , :param pad: - 패딩(padding)
:return: col: 2차원 배열
"""
N, C, H, W = input_data.shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col
x1 = np.random.rand(1, 3, 7, 7)
col1 = im2col(x1, 5, 5, stride = 1, pad = 0)
print(col1.shape) # (9, 75)
#결과
(9, 75)
• N = 1, C = 3, H = 7,
W = 7
• filter_h, filter_w = 5,
5
• out_h, out_w = 3, 3
• img == input_data :
True
• col.shape = (1,3,5,5,3)
• Slicing & indexing
x[start : stop : step]
x =
[0,1,2,3,4,5,6,7,8,9]
x[1 : 7 : 2] = [1, 3, 5]
0 1 2 3 4 5 6
0
1
2
3
4
5
6
예제
transpose(0, 4, 5, 1, 2,
3)
𝑁, 𝐶, 𝐹𝐻, 𝐹𝑊, 𝑂𝐻, 𝑂𝑊형상
인덱스 ( 0, 1, 2, 3, 4,
5 )
𝑁, 𝑂𝐻, 𝑂𝑊, 𝐶, 𝐹𝐻, 𝐹𝑊
( 0, 4, 5, 1, 2,
3 )
col.shape = (1, 3, 3, 3,
5, 5)](https://image.slidesharecdn.com/cnn-170518014544/75/Cnn-17-2048.jpg)












![[GomGuard] 뉴런부터 YOLO 까지 - 딥러닝 전반에 대한 이야기](https://cdn.slidesharecdn.com/ss_thumbnails/part1mlp2cnn-slidesharev-180308015531-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[컴퓨터비전과 인공지능] 7. 합성곱 신경망 2](https://cdn.slidesharecdn.com/ss_thumbnails/lec7convolutionnetworks2-210213150820-thumbnail.jpg?width=640&height=640&fit=bounds)





![[데이터 분석 소모임] Convolution Neural Network 김려린](https://cdn.slidesharecdn.com/ss_thumbnails/qjbtpgxtsksukja7q6eq-cnn-gimryeorin-240226120343-804ea096-thumbnail.jpg?width=640&height=640&fit=bounds)
![[컴퓨터비전과 인공지능] 7. 합성곱 신경망 1](https://cdn.slidesharecdn.com/ss_thumbnails/lec7convolutionnetwork-210207104334-thumbnail.jpg?width=640&height=640&fit=bounds)


![[신경망기초] 심층신경망개요](https://cdn.slidesharecdn.com/ss_thumbnails/nn10-180318142325-thumbnail.jpg?width=640&height=640&fit=bounds)





![[머가]Chap115 마코프체인몬테카를로](https://cdn.slidesharecdn.com/ss_thumbnails/chap115-170923012256-thumbnail.jpg?width=640&height=640&fit=bounds)
![[프선대]Chap02 랭크 역행렬-일차방정식](https://cdn.slidesharecdn.com/ss_thumbnails/chap02-171022095142-thumbnail.jpg?width=640&height=640&fit=bounds)
![[밑러닝] Chap06 학습관련기술들](https://cdn.slidesharecdn.com/ss_thumbnails/chap06-171119110341-thumbnail.jpg?width=640&height=640&fit=bounds)

![[머가]Chap11 강화학습](https://cdn.slidesharecdn.com/ss_thumbnails/chap11-170923012256-thumbnail.jpg?width=640&height=640&fit=bounds)