Recommended
PDF
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
PDF
PDF
การใช้โปรแกรม Access เบื้องต้น
PDF
ความรู้พื้นฐานเกี่ยวกับฐานข้อมูล
PDF
PDF
PPTX
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
PPTX
PDF
ความรู้ทั่วไปเกี่ยวกับระบบฐานข้อมูล
PDF
PDF
PDF
PDF
Lecture1 การประมวลผลข้อมูล และฐานข้อมูล
PDF
PDF
ความรู้พื้นฐานเกี่ยวกับระบบฐานข้อมูล
PDF
PPTX
PDF
งานคอมนางสาว มลทิรา เอกกุล เรื่อง เทคโนโลยีการสื่อสาร
PPTX
PDF
DOCX
หน่วยที่ 3 ระบบฐานข้อมูลเชิงสัมพันธ์
PPTX
PDF
PPT
PPT
PPT
PPT
DOC
DOC
PPT
More Related Content
PDF
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
PDF
PDF
การใช้โปรแกรม Access เบื้องต้น
PDF
ความรู้พื้นฐานเกี่ยวกับฐานข้อมูล
PDF
PDF
PPTX
บทที่ 1 แนวคิดทั่วไปเกี่ยวกับฐานข้อมูล
PPTX
What's hot
PDF
ความรู้ทั่วไปเกี่ยวกับระบบฐานข้อมูล
PDF
PDF
PDF
PDF
Lecture1 การประมวลผลข้อมูล และฐานข้อมูล
PDF
PDF
ความรู้พื้นฐานเกี่ยวกับระบบฐานข้อมูล
PDF
PPTX
PDF
งานคอมนางสาว มลทิรา เอกกุล เรื่อง เทคโนโลยีการสื่อสาร
PPTX
PDF
DOCX
หน่วยที่ 3 ระบบฐานข้อมูลเชิงสัมพันธ์
PPTX
PDF
Viewers also liked
PPT
PPT
PPT
PPT
DOC
DOC
PPT
PPT
DOCX
PPT
DOCX
óRavázlat magyar nyelvtan 9. b.
DOC
Digitális óravázlat NAGY Judit
PDF
DOCX
Digit oravzlat minta saci
PPTX
PPT
PPT
PPTX
Portfólióvédés - prezentáció - pedagógiai hitvallás
Similar to นาย ทศพล จอมใจ
PPTX
PPTX
PPTX
PDF
PDF
PDF
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
PDF
นางสาว หัทยา เชื้อสมเกียรติ ม.5 pp
PPTX
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
PPTX
นวลลออ ถาวรโรจน์เสถียร เลขที่20 ม.5
ODP
ODP
PPT
PDF
หน่วยที่ 1เรื่อง การจัดการข้อมูล ธนพงษ์ น่านกร ม.5
PDF
PPT
นางสาวศศิพร สิทธิมงคล ม.5
DOCX
Bacic MySql & script Sql for jhcis
PDF
PDF
บทที่3การสร้างตารางฐานข้อมูล
PDF
นาย ทศพล จอมใจ 2. หนวยการเรียนรูที่ 1 เทคโนโลยีการสื่อสาร
การเรียนรูที่ 1วัตถุประสงคของการจัดการขอมูล หนวย
ขอมูลและเขตขอมูลคีย .
การเรียนรูที่ 2 ชนิดขอมูลและประเภทของแฟมขอมูล
การเรียนรูที่ 3 ลักษณะการประมวลผลขอมูล
การเรียนรูที่ 4 แฟมโปรแกรมและแฟมขอมูล
หนวยการเรียนรูที่ 2 โครงสรางขอมูล
การเรียนรูที่ 5 ชนิดของโครงสรางขอมูล
การเรียนรูที่ 6 ลักษณะของขอมูล
การเรียนรูที่ 7 การเรียงลําดับขอมูล
การเรียนรูที่ 8 การคนหาขอมูล
3. หนวยการเรียนรูที่ 1 เทคโนโลยีการสื่อสาร
การเรียนรูที่ 1วัตถุประสงคของการจัดการขอมูล หนวยขอมูลและเขต
ขอมูลคีย .
วัตถุประสงคในการจัดการขอมูล
1. การเก็บขอมูล ตองเก็บขอมูลเพื่อใหสามารถนํากลับมาใชไดในภายหลัง
2. การจัดขอมูล ตองจัดขอมูลใหอยูในรูปแบบที่สามารถเรียกใชงานได
อยางมีประสิทธิภาพ
3. การปรับปรุงขอมูล ตองปรับขอมูลใหมีความถูกตองสมบูรณอยูเสมอ
4. การปกปองขอมูล ตองปกปองขอมูลจากการทําลาย ลักลอบใช หรือ
แกไขโดยมิชอบ รวมทั้งปกปองขอมูลจากอุบัติเหตุที่อาจเกิดจากวินาศภัย หรือ
ความบกพรองภายในระบบคอมพิวเตอร
หนวยขอมูล (DATA UNITS)
4. หนวยของขอมูลคอมพิวเตอรสามารถจัดเรียงเปน
ลําดับชั้นเล็กไปขนาดใหญไดดังนี้
1.บิต (bit)
เลขฐาน 2 หนึ่งหลักซึ่งมีคาเปน 0 หรือ 1
2.ตัวอักษร (charecter)
กลุมของบิตสามารถแทนคาตัวอักษรได ในชุดอักขระ ASCII 1 ไบต (
8 บิต) แทนตัวอักษรตัว 1 ตัว เชน 01000001 แทนตัวอักษร A ในปจจุบันมี
ชุดอักขระที่ใชเลขฐานสอง 16 บิต แทนคาตัวอักษร คือ รหัส Unicode เชน
0000 0000 1110 0110 แทนอักษรตัว ?
3.เขตขอมูล (Field)
ซึ่งประกอบดวยกลุมตัวอักษรที่แทนขอเท็จจริง
4.ระเบียน (Record)
ระเบียน คือโครงสรางขอมูลที่แทนตัววัตถุชิ้นหนึ่ง เชน ระเบียนขอมูล
นักศึกษาเลขทะเบียน 431999999
5. 5.แฟม (file)
ตารางที่เปนกลุมของระเบียนที่มีโครงสรางเดียวกัน เชน ตารางการ
สั่งซื้อสินคาของลูกคา
6.ฐานขอมูล (Database)
กลุมของตาราง (และความสัมพันธ)
การเรียงลําดับชั้นของหนวยขอมูลดังนี้
เขตขอมูลคีย (Key field) คือเขตขอมูลที่ใชสําหรับระบุระเบียนขอมูลอยาง
เฉพาะเจาะจงขอมูลที่อยูในเขตขอมูลนี้จะไมซ้ํากับระเบียนอื่น ๆ เชน
แฟมขอมูลพนักงานอาจใชเลขที่พนักงานเปนตัวระบุระเบียบ
6. การเรียนรูที่ 2 ชนิดขอมูลและประเภทของแฟมขอมูล
ชนิดของขอมูล
ขอมูลที่ตองการจัดเก็บนั้นอาจจะมีรูปแบบไดหลายอยาง รูปแบบสําคัญ ๆ ไดแก
3.1 ขอมูลแบบรูปแบบ (formatted data) เปนขอมูลที่รวมอักขระซึ่งอาจ
หมายถึงตัวอักษร ตัวเลข ซึ่งเปนรูปแบบที่แนนอน ในแตละระเบียน ทุกระเบียนที่อยูใน
แฟมขอมูลจะมีรูปแบบที่เหมือนกันหมด ขอมูลที่เก็บนั้นอาจเก็บในรูปของรหัสโดยเมื่อ
อานขอมูลออกมาอาจจะตองนํารหัสนั้นมาตีความหมายอีกครั้ง เชน แฟมขอมูลประวัติ
นักศึกษา
3.2 ขอมูลแบบขอความ (text)เปนขอมูลที่เปนอักขระในแบบขอความ ซึง
อาจหมายถึงตัวอักษร ตัวเลข สมการฯ แตไมรวมภาพตาง ๆ นํามารวมกันโดยไมมี
รูปแบบที่แนนอนในแตละระเบียน เชน ระบบการจัดเก็บขอความตาง ๆ ลักษณะการ
จัดเก็บแบบนี้จะไมตองนําขอมูลที่เก็บมาตีความหมายอีก ความหมายจะถูกกําหนดแลว
ในขอความ
3.3 ขอมูลแบบภาพลักษณ (images) เปนขอมูลที่เปนภาพ ซึ่งอาจเปนภาพ
กราฟที่ถูกสรางขึ้นจากขอมูลแบบรูปแบบรูปภาพ หรือภาพวาด คอมพิวเตอรสามารถ
เก็บภาพและจัดสงภาพเหลานี้ไปยังคอมพิวเตอรอื่นได เหมือนกับการสงขอความ โดย
คอมพิวเตอรจะทําการแปลงภาพเหลานี้ ซึ่งจะทําใหคอมพิวเตอรสามารถที่จะปรับ
ขยายภาพและเคลื่อนยายภาพเหลานั้นไดเหมือนกับขอมูลแบบขอความ
7. 3.4 ขอมูลแบบเสียง (audio) เปนขอมูลที่เปนเสียง ลักษณะ
ของการจัดเก็บก็จะเหมือนกับการจัดเก็บขอมูลแบบภาพ คือ
คอมพิวเตอรจะทําการแปลงเสียงเหลานี้ใหคอมพิวเตอรสามารถนําไป
เก็บได ตัวอยางไดแก การตรวจคลื่นหัวใจ จะเก็บเสียงเตนของหัวใจ
3.5 ขอมูลแบบภาพและเสียง (video) เปนขอมูลที่เปนเสียง
และรูปภาพ ทีถูกจัดเก็บไวดวยกัน เปนการผสมผสานรูปภาพและเสียง
่
เขาดวยกัน ลักษณะของการจัดเก็บขอมูล คอมพิวเตอรจะทําการแปลง
เสียงและรูปภาพนี้ เชนเดียวกับขอมูลแบบเสียงและขอมูลแบบภาพ
ลักษณะซึ่งจะนํามารวมเก็บไวในแฟมขอมูลเดียวกัน
8. ประเภทของแฟมขอมูล
ประเภทของแฟมขอมูลจําแนกตามลักษณะของการใชงานไดดังนี้
6.1แฟมขอมูลหลัก (master file)แฟมขอมูลหลักเปนแฟมขอมูลที่บรรจุ
ขอมูลพื้นฐานที่จําเปนสําหรับระบบงาน และเปนขอมูลหลักที่เก็บไวใชประโยชน
ขอมูลเฉพาะเรื่องไมมีรายการเปลี่ยนแปลงในชวงปจจุบัน มีสภาพคอนขางคงที่ไม
เปลี่ยนแปลงหรือเคลื่อนไหวบอยแตจะถูกเปลี่ยนแปลงเมื่อมีการสิ้นสุดของขอมูล
เปนขอมูลที่สําคัญที่เก็บไวใชประโยชน ตัวอยาง เชน แฟมขอมูลหลักของ
นักศึกษาจะแสดงรายละเอียดของนักศึกษา ซึ่งมี ชื่อนามสกุล ที่อยู ผลการศึกษา
แฟมขอมูลหลักของลูกคาในแตละระเบียนของแฟมขอมูลนี้จะแสดงรายละเอียด
ของลูกคา เชน ชื่อสกุล ที่อยู หรือ ประเภทของลูกคา
6.2 แฟมขอมูลรายการเปลี่ยนแปลง (transaction file)แฟมขอมูล
รายการเปลี่ยนแปลงเปนแฟมขอมูลที่ประกอบดวยระเบียนขอมูลที่มีการเคลื่อนไหว
ซึ่งจะถูกรวบรวมเปนแฟมขอมูลรายการเปลี่ยนแปลงที่เกิดขึ้นในแตละงวดในสวนที่
เกี่ยวของกับขอมูลนั้น แฟมขอมูลรายการเปลี่ยนแปลงนี้จะนําไปปรับรายการใน
แฟมขอมูลหลัก ใหไดยอดปจจุบัน ตัวอยางเชน แฟมขอมูลลงทะเบียนเรียนของ
นักศึกษา
9. 6.3 แฟมขอมูลตาราง (table file)แฟมขอมูลตารางเปนแฟมขอมูลที่มี
คาคงที่ ซึ่งประกอบดวยตารางที่เปนขอมูลหรือชุดของขอมูลที่มีความเกี่ยวของกันและ
ถูกจัดใหอยูรวมกันอยางมีระเบียบ โดยแฟมขอมูลตารางนี้จะถูกใชในการประมวลผล
กับแฟมขอมูลอื่นเปนประจําอยูเสมอ เชน ตารางอัตราภาษี ตารางราคาสินคา
ตัวอยางเชน ตารางราคาสินคาของบริษัทขายอะไหลเครื่องคอมพิวเตอรดังนี้
รหัสสินคา รายชื่อสินคา ราคา
51 จอภาพ 4,500
52 แปนพิมพ 1,200
53 แรม 4 M 4,500
54 แรม 8 M 7,000
55 กระดาษตอเนื่อง 500
56 แฟมคอมพิวเตอร 200
ในแฟมขอมูลนี้จะประกอบดวยระเบียนแฟมขอมูลตารางของสินคาที่มีฟลดตางๆ
ไดแก รหัสสินคา รายชื่อ สินคา และราคาสินคาตอหนวย แฟมขอมูลตารางรายการ
สินคา จะใชรวมกับแฟมขอมูลหลายแฟมขอมูลในระบบสินคา ไดแก แฟมขอมูล
คลังสินคา (inventory master file) แฟมขอมูลใบสั่งซื้อของลูกคา (customer order
master file) และแฟมขอมูลรายการสิตคาของฝายผลิต (production master file) มี
ขอควรสังเกตวาแฟมขอมูลตาราง แฟมขอมูลรายการเปลี่ยนแปลง และแฟมขอมูล
หลัก ทั้ง 3 แฟม จะมีฟลดที่เกี่ยวกับตัวสินคารวมกัน คือ ฟลดรหัสสินคา (product
code) ฟลดรวมกันนี้จะเปนตัวเชื่องโยงระหวางแฟมขอมูลตารางกับแฟมขอมูลอื่น ๆ
ทั้งหมดที่ตองการจะใชคาของฟดลรายชื่อสินคา (product description) และราคา
สินคา (product price) จากแฟมขอมูลตาราง
10. การจัดแฟมขอมูลแบบนี้จะทําใหประหยัดเนื้อที่ในอุปกรณเก็บ
ขอมูลของแฟมขอมูลหลัก กลาวคือในแฟมขอมูลหลักไมตองมี 2 ฟลด
คือ ฟลดรายการสินคาและฟลดราคาสินคา มีแตเพียงฟลดรหัสสินคาก็
เพียงพอแลว เมื่อใดที่ตองการใชฟลดรายการสินคาในการแสดงผลก็อาน
คาออกมาจากแฟมขอมูลตารางได นอกจากนั้นยังเปนการลดความ
ซ้ําซอนของขอมูลและเมื่อผูใชระบบตองการเปลี่ยนแปลงรายการสินคา
หรือราคาสินคาก็จะเปลี่ยนในแฟมขอมูลตารางทีเดียว โดยไมตองไป
เปลี่ยนแปลงในแฟมขอมูลอื่น
6.4 แฟมขอมูลเรียงลําดับ (sort file)แฟมขอมูลเรียงลําดับ
เปนการจัดเรียงระเบียนที่จะบรรจุในแฟมขอมูลนั้นใหม โดยเรียง
ตามลําดับคาของฟลดขอมูลหรือคาของขอมูลคาใดคาหนึ่งในระเบียนนัน ้
ก็ได เชน จัดเรียงลําดับตาม วันเดือนป ตามลําดับตัวอักขระเรียงลําดับ
จากมากไปหานอยหรือจากนอยไปหามาก เปนตน
แฟมขอมูลรายงาน (report file)เปนแฟมขอมูลที่ถูกจัดเรียง
ระเบียบตามรูปแบบของรายงานที่ตองการแลวจัดเก็บไวในรูปของ
แฟมขอมูล ตัวอยาง เชน แฟมขอมูลรายงานควบคุมการปรับเปลี่ยนขอมูล
ที่เกิดขึ้นในขณะปฏิบัติงานแตละวัน
11. การเรียนรูที่ 3 ลักษณะการประมวลผลขอมูล
ขอมูลและการประมวลผลขอมูล
ขอมูล คือขอเท็จจริงที่เราสนใจ สวน สารสนเทศ คือขอมูลที่ผานการ
ประมวลผลดวยวิธีการที่เหมาะสมถูกตอง จนไดรูปแบบผลลัพธ ตรงความตองการ
ของผูใช
ขอมูลที่จะนํามาประมวลผลใหเปนสารสนเทศ จะตองมีคุณสมบัติพื้นฐาน
ดังตอไปนี้
ความถูกตอง หากมีการเก็บรวบรวมขอมูลและขอมูลเหลานั้นเชื่อถือไมได จะ
ทําใหเกิดผลเสียหายมาก ผูใชจะไมกลาอางอิงหรือนําเอาไปใชประโยชน ซึ่งเปน
เหตุใหการตัดสินใจของผูบริหารขาดความแมนยํา และมีโอกาสผิดพลาดได
โครงสรางขอมูลที่ออกแบบตองคํานึงถึงกรรมวิธีการดําเนินงานเพื่อใหไดความถูก
ตองแมนยํามากที่สุด โดยปกติความผิดพลาดของการประมวลผลสวนใหญ มาจาก
ขอมูลที่ไมมีความถูกตองซึ่งมีสาเหตุมาจากคนหรือเครื่องจักร การออกแบบระบบ
จึงตองคํานึงถึงในเรื่องนี้
ความรวดเร็วและเปนปจจุบัน การไดมาของขอมูลจําเปนตองใหทันตอความ
ตองการของผูใช มีการตอบสนองตอผูใชไดเร็ว ตีความหมายสารสนเทศไดทันตอ
เหตุการณหรือความตองการ มีการออกแบบระบบการเรียกคนและรายงาน ตาม
ความตองการของผูใช
ความสมบูรณ ความสมบูรณของสารสนเทศขึ้นกับการรวบรวมและวิธีการทาง
ปฏิบัติ ในการดําเนินการจัดทําสารสนเทศ ตองสํารวจและสอบถามความตองการ
ของผูใช เพื่อใหไดขอมูลที่มีความสมบูรณเหมาะสม
12. ความชัดเจนกะทัดรัด การจัดเก็บขอมูลตองใชพื้นที่ในการจัดเก็บขอมูลมาก จึง
จําเปนตองออกแบบโครงสรางขอมูลใหกะทัดรัด สื่อความหมายได มีการใชรหัสหรือ
ยอขอมูลใหเหมาะสม เพื่อที่จะจัดเก็บเขาไวในระบบคอมพิวเตอร
ความสอดคลอง ความตองการเปนเรื่องสําคัญ ดังนั้นจึงตองมีการสํารวจเพื่อหา
ความตองการของหนวยงานและองคการ ดูสภาพการใชขอมูล ความลึกหรือความ
กวางของขอบเขตขอมูล ที่สอดคลองกับความตองการ
ในการนําขอมูลไปใชประโยชน หรือการทําขอมูลใหเปนสารสนเทศ ที่จะ
นําไปใชประโยชนได จําเปนตองมีการประมวลผลขอมูลกอน การประมวลผลขอมูล
เปนกระบวนการที่มีกระบวนการยอยหลายอยาง ประกอบกันคือ
การรวบรวมขอมูล
การแยกแยะ
การตรวจสอบความถูกตอง
การคํานวณ
การจัดลําดับหรือการเรียงลําดับ
การรายงานผล
การสื่อสารขอมูลหรือการแจกจายขอมูลนั้น
การประมวลผลขอมูล จึงเปนกิจกรรมที่มีความสําคัญ เพราะขอมูลที่มีอยู รอบๆ ตัว
เรามีเปนจํานวนมากในการใชงานจึงตองมีการประมวลผล เพื่อใหเกิดประโยชน
กิจกรรมหลักของการใหไดมาซึ่งสารสนเทศ จึงประกอบดวยกิจกรรมการ เก็บ
รวบรวมขอมูล ซึ่งตองมีการตรวจสอบ ความถูกตองดวย กิจกรรมการประมวลผลซึ่ง
อาจจะเปนการแบงแยกขอมูล การจัดเรียงขอมูล การคํานวณ และกิจกรรมการเก็บ
รักษาขอมูลซึ่งอาจตอง มีการทําสําเนา ทํารายงาน เพื่อแจกจาย
13. วิธีการประมวลผล มี 2 ลักษณะ คือ
(1) การประมวลผลแบบเชื่อมตรง (online processing)
หมายถึง การทํางานในขณะที่ขอมูลวิ่งไปบนสายสัญญาณเชื่อมตอจากเครื่อง
ปลายทาง (terminal) ไปยังฐานขอมูลของเครื่องหลักที่ใชในการประมวลผล
การประมวลผลแบบเชื่อมตรงจึงเปนการประมวลผลโดยทันทีทันใด เชน การ
จองตั๋วเครื่องบิน การซื้อสินคาในหางสรรพสินคา การฝากถอนเงินเอทีเอ็ม การ
ประมวลผลแบบเชื่อมตรงจึงเปนวิธีที่ใชกันมากวิธีหนึ่ง
(2) การประมวลผลแบบกลุม (batch processing)
หมายถึง การประมวลผลในเรื่องที่สนใจเปนครั้งๆ เชน เมื่อตองการทราบขอมูล
ผลสํารวจความนิยมของประชาชนตอการเลือกตั้งสมาชิกสภาผูแทน หรือที่
เรียกวา โพล (poll) ก็มีการสํารวจขอมูลเพื่อเก็บรวบรวมขอมูล เมื่อเก็บรวบรวม
ขอมูลไดแลวก็นํามาปอนเขาเครื่องคอมพิวเตอร แลวนําขอมูล นั้นมาประมวลผล
ตามโปรแกรมที่ไดกําหนดไว เพื่อรายงานหรือสรุปผลหาคําตอบ กรณีการ
ประมวลผลแบบกลุมจึงกระทําในลักษณะเปนครั้งๆ เพื่อใหไดผลลัพธโดย
จะตองมีการรวบรวมขอมูลไวกอน
14. การเรียนรูที่ 4 แฟมโปรแกรมและแฟมขอมูล
แฟมโปรแกรมและแฟมขอมูล
ถาจะแบงประเภทของแฟมในคอมพิวเตอรอีกนัยหนึ่ง อาจแบงเปนแฟม
โปรแกรม และ แฟมขอมูล แฟมโปรแกรมประกอบดวยชุดคําสั่งตางๆ ที่ทํางาน
อยางใดอยางหนึ่งเชน โปรแกรมประมวลคํา (word processor) ใชสําหรับ
พิมพเอกสารและจัดรูปแบบขอความ และโปรแกรมบีบอัดขอมูล
(compression utility) ใชสําหรับบีบอัดขอมูลที่มีขนาดเล็กลง เปนตน
แฟมที่จัดเก็บหรือบันทึกโดยโปรแกรมเหลานี้ จัดเปนประเภทแฟมขอมูล
ซึ่งตามปกติจะมีสวนขยาย (file extension) เปนตัวบอกประเภทเชน เอกสาร
ที่สรางดวยโปรแกรมประมวลคํา Microsoft Word จะมีสวนขยายหลักเปน
.doc สวนแฟมขอมูลที่สรางดวยโปรแกรมบีบอัดขอมูล Winzip จะมีสวนขยาย
เปน .zip เปนตน ที่กลาววาสวนขยายหลักหมายความวา โปรแกรมหนึ่งอาจ
สรางแฟมขอมูลที่มีสวนขยายไดหลายหยาง ตัวอยางโปรแกรมลักษณะนี้
ไดแก Microsoft Word2000 ซึ่งสามารถสรางแฟมขอมูลที่มีสวนขยายเปน
.doc .htm .html .rtf .txt .mcw และ .wps แต จะเปนสวนขยายหลักเปน
.doc
15. แฟมขอมูลบางประเภทสรางและเปดดวยโปรแกรมใดโปรแกรมหนึ่ง
โดยเฉพาะ เชนแฟมที่สรางดวยโปรแกรมแตงภาพ Adobe Photoshop ซึ่งมีสวน
ขยายเปน .psd ในขณะที่แฟมขอมูลบางประเภทเปนประเภทที่มีรูปแบบมาตรฐาน
ที่สามารถสรางและเปดไดโดยโปรแกรมตางๆ เชน ประเภทแฟม Bitmap ( BMP)
Graphics Interchange Format (GIF) และ Joint Photographic Experts
Group (JPEG) สามารถสรางและเปดแกไขไดโดย Windows PaintBrush ,
Adobe Photoshop หรือ Microsoft Photo Editor ก็ได แฟมที่มีรูปแบบมาตรฐาน
เหลานี้มีประโยชนมากในการแลกเปลี่ยนขอมูลระหวางโปรแกรมตางๆ
แฟมโปรคแกรมที่ประกอบดวยชุดคําสั่งที่ทํางานได ไดแกประเภท .exe ,
.com , .bat , .dll
16. 17. เปนโครงสรางขอมูลที่ใชโดยทั่วไปในภาษาคอมพิวเตอร แบงออกเปน 2 ประเภท
1.ขอมูลเบื้องตน (Primitive Data Types)
- จํานวนเต็ม (Integer)
- จํานวนทศนิยม (Floating point)
- ขอมูลบูลีน (Boolean)
- จํานวนจริง (Real)
- ขอมูลอักขระ (Character)
2.ขอมูลโครงสราง (Structure Data Types)
- แถวลําดับ (Array)
- ระเบียนขอมูล (Record)
- แฟมขอมูล (File)
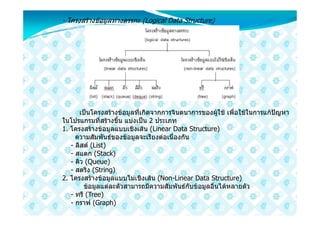
18. - โครงสรางขอมูลทางตรรกะ (Logical Data Structure)
เปนโครงสรางขอมูลที่เกิดจากการจินตนาการของผูใช เพื่อใชในการแกปญหา
ในโปรแกรมที่สรางขึ้น แบงเปน 2 ประเภท
1. โครงสรางขอมูลแบบเชิงเสน (Linear Data Structure)
ความสัมพันธของขอมูลจะเรียงตอเนื่องกัน
- ลิสต (List)
- สแตก (Stack)
- คิว (Queue)
- สตริง (String)
2. โครงสรางขอมูลแบบไมเชิงเสน (Non-Linear Data Structure)
ขอมูลแตละตัวสามารถมีความสัมพันธกับขอมูลอื่นไดหลายตัว
- ทรี (Tree)
- กราฟ (Graph)
19. 3. การดําเนินการกับโครงสรางขอมูล(Data Structure Operation)
วิธีดําเนินการกับขอมูลที่นิยมใชกันมากมี 4 แบบ คือ
1. การเขาถึงเรคคอรด (Traversing)
2. การคนหา (Searching)
3. การเพิ่ม (Inserting)
4. การลบ (Deleting)
ยังมีการจัดการกับขอมูลอีก 2 อยาง คือ
1. การเรียงขอมูล (Sorting)
2. การรวมขอมูล (Merging)
4. การแทนที่ขอมูลในหนวยความจํา
มีอยู 2 วิธี คือ
การแทนที่ขอมูลแบบสแตติก (Static Memory Representation)
เปน การแทนที่ขอมูลที่มีการจองเนื้อที่แบบคงที่แนนอน ตองมีการกําหนด
ขนาดกอนการใชงาน แตมีขอเสีย คือ ไมสามารถปรับขนาดใหเพิ่มขึ้นหรือลดลงได
โครงสรางขอมูลที่มีการแทนที่หนวยความจําหลักแบบสแตติก คือแถวลําดับ (Array)
การแทนทีขอมูลแบบไดนามิก (Dynamic Memory Representation)
เปน การแทนที่ขอมูลที่ไมตองจองเนื้อที่ ขนาดของเนื้อที่ยืดหยุนได ตามความ
ตองการของผูใช โครงสรางขอมูลที่มีการแทนที่หนวยความจําหลักแบบไดนามิก คือ
ตัวชี้หรือพอยเตอร (Pointer)
20. 5. ลักษณะของโปรแกรมแบบที่มีโครงสรางที่ดี
5.1 โครงสรางโปรแกรมแบบคําสั่งตามลําดับ
เปน โครงสรางพื้นฐานที่ประกอบดวยคําสั่งทั่วๆไป เปนโครงสรางที่มี
ลักษณะการทํางานแบบเรียงลําดับ คือ จะทํางานตั้งแตตนจนจบโดยไมมีการ
ขามขันตอนใดๆ
้
5.2 โครงสรางโปรแกรมแบบมีการตัดสินใจ (Decision)
มี การตรวจสอบเงื่อนไข เพื่อตัดสินใจวาจะทําการประมวลผลสวนใด โดย
ผลลัพธของเงื่อนไขจะมีคาของความเปนไปไดอยู 2 ลักษณะ คือ จริงและเท็จ
เทานั้น
5.3 โครงสรางโปรแกรมแบบเปนวงจรปด (Loop)
มีลักษณะการทํางานซ้ําๆกัน อยูในสวนใดสวนหนึ่งของโปรแกรม
6. อัลกอริทึม (Algorithm)
อัลกอรึทึม คือ วิธีการแกปญหาตางๆ อยางมีระบบ มีลําดับขั้นตอนตั้งแต
ตนจนไดผลลัพธ สามารถเขียนไดหลายแบบ การเลือกใชตองเลือกใชขั้นตอนวิธี
ที่เหมาะสม กระชับ และรัดกุม
อัลกอริทึมที่นิยมใชกันมาก ไดแก
1. อัลกอริทึมแบบแตกยอย (Divide and conquer)
2. อัลกอริทึมแบบเคลื่อนที่ (Dynamic Programming)
3. อัลกอริทึมแบบทางเลือก (Greedy Algorithm)
21. การเขียนผังงาน (Flowchart)
Flow Chart เปนการอธิบายขั้นตอนการประมวลผลโดยใชสัญลักษณใน
การแสดงความหมาย การใชกรอบรูปสัญลักษณที่สื่อความหมาย อธิบาย
ขั้นตอนการทํางาน
การเขียนรหัสเทียม (Pseudo Code)
Pseudo Code การอธิบายขั้นตอนการประมวลผลโดยใชวลีภาษาอังกฤษ
ในการแสดงอธิบาย ใชคําสั้นๆ กะทัดรัด อธิบายขั้นตอนการทํางานของ
โปรแกรม
พัฒนาการของภาษาโปรแกรม
- ภาษาเครื่อง (Machine Language)
- ภาษาแอสเซมบลี (Assembly Language)
- ภาษาระดับสูง (High Level Language)
- ภาษายุคที่ 4 (Fourth Generation Language หรือ 4GL)
การบํารุงรักษาโปรแกรม (Program Maintenance)
หมาย ถึง การแกไขขอผิดพลาดที่พบระหวางการทดสอบหรือระหวาง
การใชงาน ซึ่งอาจเปนการเปลี่ยนขอมูลที่ตองการใชใหมการปรับปรุงขอมูล ให
ทันเหตุการณอยูเสมอ การปรับเปลี่ยนโครงสรางบนหนาจอ เปนตน
22. การเรียนรูที่ 6 ลักษณะของขอมูล
ลักษณะของขอมูลที่ดี
ขอมูลที่ดีควรเปนขอมูลที่มีคุณลักษณะดังตอไปนี้
• ขอมูลที่มีความถูกตองและเชื่อถือได (accuracy) ขอมูลจะมีความถูกตองและเชื่อถืไดมาก
นอยเพียงใดนั้น ขึ้นกับวิธีการที่ใชในการควบคุมขอมูลนําเขา และการควบคุมการประมวลผล
การควบคุมขอมูลนําเขาเปนการกระทําเพื่อใหเกิดความมั่นใจวาขอมูลนําเขามีความถูกตอง
เชื่อถือได เพราะถาขอมูลนําเขาไมมีความถูกตองแลวถึงแมจะใชวิธีการวิเคราะหและ
ประมวลผลขอมูลที่ดีเพียงใด ผลลัพธที่ไดก็จะไมมีความถูกตอง หรือนําไปใชไมได ขอมูล
นําเขาจะตองเปนขอมูลที่ผานการตรวจสอบวาถูกตองแลว ขอมูลบางอยางอาจตองแปลงให
อยูในรูปแบบที่เครื่องคอมพิวเตอรสามารถเขาใจไดอยางถูกตอง ซึ่งอาจตองพิมพขอมูลมา
ตรวจเช็คดวยมือกอน การประมวลผลถึงแมวาจะมีการตรวจสอบขอมูลนําเขาแลวก็ตาม ก็
อาจทําใหไดขอมูลที่ผิดพลาดได เชน เกิดจากการเขียนโปรแกรมหรือใชสูตรคํานวณ
ผิดพลาดได ดังนั้นจึงควรกําหนดวิธีการควบคุมการประมวลผลซึ่งไดแก การตรวจเช็คยอด
รวมที่ไดจากการประมวลผลแตละครั้ง หรือการตรวจสอบผลลัพธที่ไดจากการประมวลผล
ดวยเครื่องคอมพิวเตอรกับขอมูลสมมติที่มีการคํานวณดวยวามีความถูกตองตรงกันหรือไม
• ขอมูลตรงตามความตองการของผูใช (relevancy) ไดแก การเก็บเฉพาะขอมูลที่ผูใช
ตองการเทานั้น ไมควร เก็บขอมูลอื่น ๆ ที่ไมจําเปนหรือไมเกี่ยวของกับการใชงาน เพราะจะ
ทําใหเสียเวลาและเสียเนื้อที่ในหนวยเก็บขอมูล แตทั้งนี้ขอมูลที่เก็บจะตองมีความครบถวน
สมบูรณดวย
• ขอมูลมีความทันสมัย (timeliness) ขอมูลที่ดีนั้นนอกจากจะเปนขอมูลที่มีความถูกตอง
เชื่อถือไดแลวจะ ตองเปนขอมูลที่ทันสมัย ทั้งนี้เพื่อใหผูใชสามารถนําเอาผลลัพธที่ไดไป
ใชไดทันเวลา นั่นคือจะตองเก็บขอมูลไดรวดเร็วเพื่อทันความตองการของผูใช
23. การเรียนรูที่ 7 การเรียงลําดับขอมูล
การเรียงลําดับขอมูล
การเรียงลําดับขอมูลเปนเรื่องสําคัญมากเรื่องหนึ่งเนื่องจากทําใหผูตองการใชขอมุ
ลเชน ผูบริหาร,ผูปฏิบัติงาน (พนักงาน) สามารถทําความเขาใจกับขอมูลหรือทําการ
คนหาขอมูลไดงายและเร็วยิ่งขึ้นตามที่ตองการ
ประเภทของการจัดการจัดเรียงขอมูลในระบบคอมพิวเตอร แบงเปน 2 ประเภทคือ
1. Internal Sorting คือ การเรียงลําดับขอมูลโดยเก็บไวในหนวยความจําหลัก
และขอมูลของสมาชิกจะถูกเก็บ อยูในโครงสรางอะเรย
2. External Sorting คือ การเรียงลําดับขอมูลโดยเก็บไวในหนวยความจําสํารอง
ขอมูลสวนใหญมีจํานวนมาก จึงไม สามารถเก็บไวในหนวยความจําหลักไดทั้งหมด
ในหัวขอการเรียงลําดับ นี้จะอธิบายวิธีการเรียงลําดับขอมูลในแตละวิธีโดยสรุปอยาง
ยอ ๆ เพื่อใชเปนแนวทางในการศึกษาใน ระดับชั้นสูงขึ้นไป คงจะไมไดกลาวถึงวิธีการ
ขั้นตอนในการจัดเรียงอยางละเอียดแตจะพยายามชี้ใหเห็นถึงจุดเดนตาง ๆ ของการ
จัด เรียงลําดับในแตละวิธี
วิธีหรือชนิดของการเรียงลําดับ มีวิธีตาง ๆ ที่มักจะไดพบโดยทั่วไปดังนี้
1. SELECTION SORT
2. INSERTION SORT / LINEAR INSERTION SORT
3. BUBBLE SORT
4. SHELL SORT
5. BUCKET SORT /RADIX SORT
6. QUICK SORT
7. HEAP SORT / TREE SORT
24. 1. การเรียงลําดับแบบเลือก (Selection Sort)
เปนวิธีที่งายที่สุดในการเรียงลําดับขอมูล โดยเริ่มจาก
- หาตําแหนงของขอมูลที่มีคานอยที่สุดแลวสลับคาของตําแหนงขอมูลนั้นกับคา
ขอมูลในตําแหนง A(1) จะได A(1) มีคานอยที่สุด
- หาตําแหนงของขอมูลที่มีคานอยที่สุดในกลุม A(2), A(3),....,A(n) แลวทํากับ
สลับคาขอมูลในตําแหนง A(2) อยางนี้เรื่อยไปจน กระทั่งไมเกิน N-1 รอบ ก็จะได
ขอมูลที่เรียงลําดับจากนอยไปมาก
2. การเรียงลําดับแบบแทรก (Insertion Sort)
หลักการ คือ
1. อานขอมุลที่ตองการเรียงลําดับเขามาทีละตัวโดยเริ่มจากตัวแรกกอน และหา
ตําแหนงของขอมูลที่ควรจะอยู
2. หาที่วางสําหรับขอ 1.
3. Insert หรือแทรกขอมูล ณ ตําแหนงในขอ 2.
3. การเรียงลําดับแบบบับเบิล (Bubble Sort)
วิธัการเรียงลําดับแบบบับเบิลจะทําการเปรียบเทียบขอมูลที่อยูในตําแหนงที่ติดกัน ถา
ขอมูลไมอยูใลําดับที่ถูกตอง ก็จะทําการสลับตําแหนงของขอมูลที่เปรียบเทียบโดยที่
การเปรียบเทียบจะเริ่มที่ตําแหนงที่ 1 กับตําแหนงที่ 2 กอน ตอไปนี้เทียบกับ ตําแหนง
ที่ 2 และตําแหนงที่ 3 จนถึงตําแหนงที่จัดเรียงแลว จากนั้นจะกลับไปเริ่มตนการ
เปรียบเทียบอีกจนกระทั่งจัดเรียง เรียบรอยหมดทุกตําแหนง
ในวิธีแบบ Bubble Sort คาในการเปรียบเทียบที่นอยที่สุดหรือมากที่สุด จะลอยขึ้น
ขางบน เหมือนกับฟองอากาศ
25. 4. การรียงลําดับแบบเชลล(shell sort)
เปนรูปแบบของการ sort ขอมูลโดยการนําเอาขอดีของการคนหาขอมูลแบบ
แทรกและแบบเลือกและหลีกเลี่ยง การเกิดปญหาของทั้งแบบแทรกและแบบ
เลือก ซึ่งการเปรียบเทียบขอมูลในการเรียงลําดับแบบแทรก โดยการ
เปรียบเทียบ ขอมูลที่อยูไกลออกไป ซึ่งจะทําใหเราสามารถเรียงดับขอมูลใน
ตําแหนงที่อยูไกลออกไปหลังจากนั้นก็จะเรียงลําดับขอมูล ที่อยูใกลกันเขามา
(กวาในครั้งแรก) และความหางของขอมูลที่เปรียบเทียบก็จะนอยลงจนเหลือ
1
วิธีนี้คิดคนเมื่อป ค.ศ.1959 โดย ดี.แอล.เชลล(D.L.SHELL) เรียกวา การ
เรียงลําดับแบบเชลล(shell sort)
5. การเรียงลําดับโดยการใชฐานเลข(radix sort)
การเรียงลําดับแบบนี้การเรียงลําดับ จะอยูบนพื้นฐานของการแทนตําแหนง
ของตัวเลขที่ตองการนํามาเรียงลําดับ จะเริ่มจากตัวที่มีเลขนัยสําคัญสูงที่สุด
ดําเนินจนกระทั่งถึงตัวเลขที่มีเลขนัยสําคัญต่ําสุด การเรียงลําดับในวิธีนี้การ
เรียงลําดับ จะเรียงจากตัวเลขที่มีนัยสําคัญนอยที่สุดกอน เมื่อตัวเลขทั้งหมด
ถูกนํามาเรียงลําดับตามเลขนัยสําคัญที่สูงขึ้น ตัวเลขที่เหมือนกัน ในตําแหนง
นน จะตางกันในตําแหนงของเลขนัยสําคัญที่นอยกวา การประมวลผลแบบนี้จะ
ประมวลผลกับขอมูลทั้งหมดได โดยที่ไมตองมีการแบงขอมูลแบบกลุมยอย
26. 6. การเรียงลําดับอยางเร็ว(quick sort)
ถูกสรางและตั้งชื่อโดย ซี.เอ.อาร.ฮารเวร (C.A.R HOARE) การเรียงลําดับ
อยางเร็ว จะแบงขอมูลเปนสองกลุม โดยใน การจัดเรียงจะเลือกขอมุลตัวใดตัว
หนึ่งออกมา ซึ่งจะเปนตัวที่แบงขอมูลออกเปนสองกลุม โดยกลุมแรกจะตองมี
ขอมูลนอยกวา ตัวแบง และกลุมที่มีขอมูลนอยกวาตัวแบง และอีกกลุมจะมี
ขอมูลที่มากกวาตัวแบง ซึ่งเราเรียกตัวแบงวา ตัวหลัก(pivot) ในการเลือกตัว
หลักจะมีอิสระในการเลือกขอมูลตัวใดก็ไดที่เราตองการ การเรียงลําดับแบบ
เร็วเหมาะกับขอมูลที่มีการเรียกซ้ํา
7.การเรียงลําดับฮีพ(heapsort)
เปนการเรียงลําดับที่อยูบนพื้นฐานบนพื้นฐานของโครงสรางแบบไบนารี จะ
ดําเนินการ 2 ขั้นตอน คือ
1. การจัดขอมูลในอะเรยใหสอดคลองกับความตองการของฮีพ
2. การขจัดหนือการเคลื่อนยายขอมูลในตําแหนงสูงสุดหรือตําแหนงยอด
ของของฮีพออกไปและสนับสนุนขอมูลขอมูล ตัวอื่นไปแทนตําแหนงนั้น
27. การเรียนรูที่ 8 การคนหาขอมูล
การคนหาขอมูล (searching)
การคนหาคําตอบ หรือการคนหาขอมูลในทางคอมพิวเตอรมักจะกระทําบน
โครงสรางขอมูลแบบตนไม และกราฟ ทั้งนี้เพราะโครงสรางขอมูลในลักษณะนี้
สามารถทําใหการคนหาทําไดสะดวกและสามารถพลิกแพลงการคนหาไดงาย ใน
ความเปนจริงแลว การคนหาขอมูลบางครั้งสามารถกระทําบนโครงสรางขอมูลชนิด
อื่นก็ไดเชน อาเรย แสตก และคิว แตการจัดขอมูลในโครงสรางเชนนี้ มีขอจํากัดใน
การคนหาขอมูลมาก การคนหาทําไดแบบเรียงลําดับ(Sequencial Search) เทานั้น
ซึ่งใชไดกับขอมูลที่มีขนาดเล็ก ดังนั้นในการคนหาขอมูลที่มีขนาดใหญ กอนการ
คนหา หรือระหวางการคนหา ขอมูลที่จะถูกคนจะตองถูกจัดใหอยูในรูปแบบของ
ตนไม หรือกราฟเทานั้น การคนหาขอมูลบนโครงสรางตนไมและกราฟสามารถจํ
าแนกได 2 แบบคือ การคนหาแบบไบลด(Blind Search) และการคนหาแบบฮิวริ
สติก(Heuristic Search)
28. การคนหาแบบไบลด(Blind Search)
การคนหาแบบไบลด(Blind search) เปนการคนหาแบบที่เดินทางจากโหนดหนึ่ง
ไปยังอีกโหนดหนึ่ง โดยอาศัยทิศทางเปนตัวกําหนดการคนหา ไมตองมีขอมูลอะไรมา
ชวยเสริมการตัดสินใจวาจะเดินทางตอไปอยางไร หรือกลาวอยางงาย ๆ คือการจะ
หยิบขอมูลใดมาชวยในการคนหาตอไป ไมตองอาศัยขอมูลใด ๆ ทั้งสิ้น นอกจาก
ทิศทางซึ่งเปนรูปแบบตายตัว การคนหาแบบไบลดสามารถแบงยอยไดดังนี้ คือ การ
คนหาทั้หมด และการคนหาบางสวน
- การคนหาทั้งหมด(exhaustive search) คือ การคนหาทั้งหมดของปริภูมิสถานะ
- การคนหาบางสวน (partial search) การคนหาเพียงบางสวนของปริภูมิสถานะ
ซึ่งในความเปนจริงการคนหาสวนมากใชการคนหาเฉพาะบางสวนเทานั้นเนื่องจาก
ปริภูมิสถานะมักมีขนาดใหญ เทาใหไมสามารถคนหาไดทั้งหมด ดังนั้นจึงมีความ
เปนไปไดวาคําตอบที่ไดอาจไมใชคําตอบที่ดีที่สุด การคนหาแบบนี้สามารถแบงได
เปน 2 ประเภทคือ การคนหาแบบลึกกอน(Depth first search) และการคนหาแบบ
กวางกอน (Breadth first search)
การคนหาแบบลึกกอน(Depth first search)
การคนหาแบบลึกกอนเปนการคนหาที่กําหนดทิศทางจากรูปของโครงสราง
ตนไม ที่เริ่มตนจากโหนดราก(Root node) ที่อยูบนสุด แลวเดินลงมาใหลึกที่สุด เมื่อ
ถึงโหนดลางสุด(Terminal node) ใหยอนขึ้นมาที่จุดสูงสุดของกิ่งเดี่ยวกันที่มีกิ่งแยก
และยังไมไดเดินผาน แลวเริ่มเดินลงจนถึงโหนดลึกสุดอีก ทําเชนนี้สลับไปเรื่อยจนพบ
โหนดที่ตองการหาหรือสํารวจครบทุกโหนดแลวตามรูปที่ 1 การคนหาแบบลึกกอนจะมี
ลําดับการเดินตามโหนดดังตัวเลขที่กํากับไวในแตละโหนด
29. รูปที่ 1 ลําดับการเดินทางบนโหนดของการคนหาแบบลึกกอนบนโครงสรางตนไม
ดังที่ไดกลาวมาแลววา โครงสรางขอมูลที่ใชสําหรับการคนหานี้สามารถ
ใชกับโครงสรางกราฟไดดวย โดยอาศัยหลักการเดียวกัน แตสําหรับการเดินทาง
บนกราฟนั้นจะไมมีโหนดลึกสุดดังนั้นการเดินทางบนกราฟจะตองปรับวิธีการเปน
ดังนี้ โดยเริ่มจาก
โหนดเริ่มตน จากนั้นใหนําโหนดที่อยูติดกับโหนดที่กําลังสํารวจอยู(ที่ยังไมไดทํา
การสํารวจและยังไมไดอยูในแสต็กมาใสแสต็ก) มาเก็บไวในสแต็กเมื่อสํารวจโหนด
นั้นเสร็จ ใหพอพ(pop) ตัวบนสุดของโหนดออกมาทําการสํารวจ แลวนําโหนด
ขางเคียงทั้งหมดที่ยังไมไดสํารวจมาตอทายแสต็ก แลวพอพตัวบนสุดออกมา
สํารวจ ทําเชนนี้เรื่อย ๆ จนกระทั้งพบโหนดที่ตองการ หรือสํารวจครบทุดโหนด
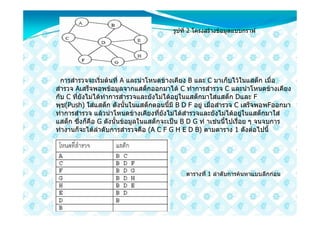
30. รูปที่ 2 โครงสรางขอมูลแบบกราฟ
การสํารวจจะเริ่มตนที่ A และนําโหนดขางเคียง B และ C มาเก็บไวในแสต็ก เมื่อ
สํารวจ Aเสร็จพอพขอมูลจากแสต็กออกมาได C ทําการสํารวจ C และนําโหนดขางเคียง
กับ C ที่ยังไมไดทําการสํารวจและยังไมไดอยูในแสต็กมาใสแสต็ก Dและ F
พุช(Push) ใสแสต็ก ดังนั้นในแสต็กตอนนี้มี B D F อยู เมื่อสํารวจ C เสร็จพอพFออกมา
ทําการสํารวจ แลวนําโหนดขางเคียงที่ยังไมไดสํารวจและยังไมไดอยูในแสต็กมาใส
แสต็ก ซึ่งก็คือ G ดังนั้นขอมูลในแสต็กจะเปน B D G ทํ าเชนนี้ไปเรื่อย ๆ จนจบการ
ทํางานก็จะไดลําดับการสํารวจคือ (A C F G H E D B) ตามตาราง 1 ดังตอไปนี้
ตารางที่ 1 ลําดับการคนหาแบบลึกกอน
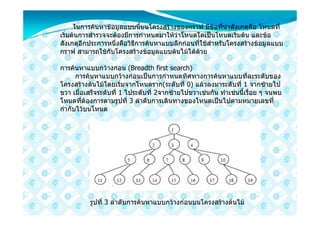
31. 32. 33. การสํารวจเริ่มตนที่ A นําโหนดขางเคียง B C ไวในคิว เมื่อสํารวจ A เสร็จ นําขอมูล
ในคิว คือ Bออกมาสํารวจ แลวนําขอมูลขางเคียงคือ D E ใสคิว ตอนนี้คิวจะมี B D
E อยู แลวนํา B ออกมาสํารวจทําเชนนี้เรื่อย ๆ จะไดลําดับการสํารวจขอมูลคือ (A
B C D E F G H) ตามตารางที่ 2
ตาราง 2 ลําดับการคนหาแบบกวางกอน
เชนเดียวกับการคนหาแบบลึกกอน การคนหาแบบกวางกอนโดยใชโครงสราง
ขอมูลคิวมาชวยตองมีการกําหนดโหนดเริ่มตน และวิธีการนี้สามารถใชไดกับ
ขอมูลบนโครงสรางแบบตนไมดวย
34. ตารางเปรียบเทียบ การคนหาแนวลึกกอนและแนวกวางกอน
การคนหาแนวลึกกอน การคนหาแนวกวางกอน
1.ใชหนวยความจํานอยกวา 1.ใชหนวยความจํามากเพราะ
เพราะวาสถานะในเสนทางคนหา ตองเก็บสถานะไวทุกตัวเพื่อ
ปจจุบันเทานั้นที่ถูกเก็บ(ในขณะ หาเสนทางจากสถานะเริ่มตน
ใดๆ จะเก็บเสนทางเดียว พอจะ ไปหาคําตอบ
ไปเสนทางอื่นเสนทางที่ผานมาก็
ไมจําเปนตองเก็บ)
2. อาจจะติดเสนทางที่ลึกมาก 2. จําไมติดเสนทางที่ลึกมาก
โดยไมพบคําตอบ เชนในกรณีที่ ๆ โดยไมพบคําตอบ
เสนทางนั้นไมมีคําตอบและเปน
เสนทางที่ยาวไมสิ้นสุด จะทําไม
สามารถไปเสนทางอื่นได
3. ถาคําตอบอยูในระดับ n+1 3. ถาคําตอบอยูในระดับ
สถานะอื่นทุกตัวที่ระดับ 1ถึง n+1 สถานะทุกตัวที่ระดับ 1
ระดับ n ไมจําเปนตองถูกกระจาย ถึงระดับ n จะตองถูกกระจาย
จนหมด จนหมด ทําใหมีสถานะที่ไม
จําเปนในเสนทางที่จะไปสู
คําตอบถูกกระจายออกดวย
4. เมื่อพบคําตอบไมสามารถ 4. ถามีคําตอบจะรับประกันได
รับประกันไดวาเสนที่ไดเปน วาจะพบคําตอบแน ๆ และจะ
เสนทางที่สั้นที่สุดหรือไม ไดเสนทางสั้นที่สุดดวย
35. การคนหาแบบฮิวริสติก(Heuristic Search)
การคนหาคําตอบอาศัยวิธีการทางฮิวริสติก (heuristic search) มีความ
ความแตกตางจากการคนหาขอมูลแบบธรรมดาและแบบฮิวริสติกนั้นอยูที่การ
คนหาขอมูลธรรมดา ผูที่ทําการคนขอมูลจะตองตรวจสอบขอมูลทีละตัวทุกตัวจน
ครบ แตฮิวริสติกจะไมลงไปดู ขอมูลทุกตัว วิธีการนี้จะเลือกไดคําตอบที่เหมาะสม
ใหกับการคนหา ซึ่งมีขอดีคือ สามารถทําการ คนหาคําตอบจาก ขอมูลที่มีขนาด
ใหญมาก ๆ ได แตมีขอเสียคือคําตอบที่ไดเปนเพียงคําตอบที่ดี เทานั้นไมแนวา
จะดีที่สุด แตเนื่องจากวาปญหาในบางลักษณะนั้นใหญมาก และเปนไปไมไดที่จะ
ทํา การคนหาดวยวิธี ธรรมดากระบวนการของฮิวริสติกจึงเปนสิ่งที่จําเปนในเรื่อง
ของฮิวริสติกนั้น นอกจากจะมีการคนหาแบบฮิวริสติกแลว ยังมีอีกสิ่งหนึ่งที่สําคัญ
คือ ฮิวริสติกฟงกชัน (heuristic function) ซึ่งหมายถึงฟงกชันที่ทําหนาที่ในการ
วัดขนาดของความเปน ไปไดในการแกปญหาซึ่งจะแสดงดวยตัวเลข วิธีการ
ดังกลาวจะกระทํ าไดโดยการพิจารณาถึงวิธีการ (aspects) ตาง ๆ ที่ใชในการ
แกปญหา ณ สถานะหนึ่งวาจะสามารถแกปญหาไดตามที่ตองการหรือไม โดย
กําหนดเปนนํ้าหนักที่ใหกับการแกปญหาของแตละวิธี นํ้าหนักเหลานี้จะถูกแสดง
ดวยตัวเลขที่กํากับไวกับโหนดตาง ๆ ในกระบวนการ คนหา และคาเหลานี้จะเปน
ตัวที่ใชในการประมาณความเปนไปไดวาเสนทางที่ผานโหนดนั้นจะมี ความ
เปนไปไดในการนําไปสูหนทางการแกปญหาไดมากนอยแคไหน
36. จุดประสงคที่แทจริงของฮิวริสติก ฟงกชันก็คือ การกํากับทิศทางของ
กระบวนการคนหา เพื่อใหอยูในทิศทางที่ไดประโยชนสูงสุด โดยการบอกวาเรา
ควรเลือกเดินเสนทางไหนกอน ในกรณีที่มีเสน ทางมากกวาหนึ่งเสนทางตอง
เลือกกระบวนการคนหาแบบฮิวริสติก โดยปกติแลวจะตองอาศัยฮิวริสติกฟงกชัน
ทําใหการแกปญหาหนึ่ง ๆ จะดีหรือไม ก็ขึ้นอยูกับฮิวริสติกฟงกชันดังนั้นการ
คนหาแบบนี้จึงไมมีอะไรเปนหลักประกันวาจะไดสิ่งที่ไมดีออกมาดวยเหตุนี้เอง
เราจึงเรียกการ คนหาแบบฮิวริสติกนี้วา Weak Methods หรือจะกลาวอีกนัยหนึ่ง
คือ Weak Methodsเปนกระบวนการควบคุมโดยทั่วไป (general-
purpose control stategies) ซึ่งการคนหาแบบนี้ สามารถแบงไดเปน
37. การคนหาแบบปนเขา(Hill climbing)
ฟงกชันฮิวริสติกสามารถนํามาชวยในกระบวนการคนหาเพื่อใหไดคําตอบอยาง
รวดเร็วและมีประสิทธิภาพ วิธีการที่จะนําฟงกชันฮิวริสติกมาใชมีหลายวิธีดวยกัน
ขึ้นอยูกับวาจะใชในลักษณะใด เชนเลือกสถานะที่มีคาฮิวริสติกดีขึ้น แลวเดินไปยัง
สถานะนั้นเลยโดยไมตองสนใจสถานะที่มีคาฮิวริสติกแยกวาสถานะปจจุบันหรือวาจะ
เก็บสถานะทุกตัวไวแมวาคาฮิวริสติกจะแยลงแลวพิจารณาสถานะเหลานี้ทีหลัง เปน
ตน ในสวนตอไปนี้จะกลาวถึงอัลกอริทึมตาง ๆ ที่นําฟงกชันฮิวริสติกมาชวยในการ
คนหาคําตอบ โดยเริ่มจากอัลกอริทึมปนเขา (Hill climbing algorithm)
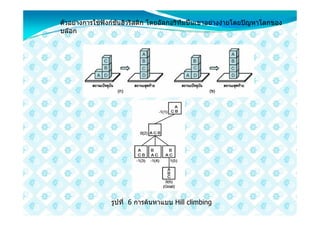
รูปที่ 5 แสดงลักษณะการคนหาแบบ Hill climbing
การคนหาแบบฮิลไคลบิง(Hill climbing) เปนวิธีการคนหาขอมูลที่มีลักษณะ
คลายกับการปนภูเขา การที่นักปนภูเขาจะเดินทางไปถึงยอดภูเขา นักปนเขาจะตอง
มองกอนวายอดเขาอยูที่ใด แลวนักปนเขาจะตองพยายามไปจุดนั้นใหได ลองนึก
ภาพของการปนภูเขาโลนที่มองเห็นแตยอด และนักปเขากําลังปนภูเขาอยูเบื้องลาง
ที่มีเสนทางเต็มไปหมด เพื่อที่จะเดินทางไปถึงยอดภูเขาโดยเร็วที่สุด นักปน
เขาจะมองไปที่ยอดเขาแลวสังเกตวาทิศทางใดที่เมื่อปนแลวจะยิ่งใกลยอดเขา และ
หลีกเลี่ยงทิศทางที่เมื่อไปแลวจะทําใหตัวเองหางจากยอดเขา นักปนเขาจะตองทํา
เชนนี้ไปเรื่อย ๆ จนกระทั่งถึงยอดเขา
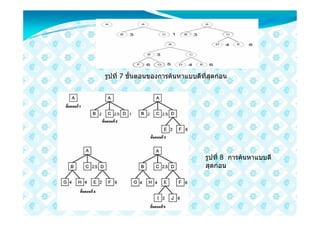
38. 39. ตัวเลข h(i) ในรูปแสดงวา สถานะที่ i มีคาฮิวริสติกเทากับ h จากรูจะเห็นไดวา
เริ่มตนจากสถานะที่ 1 ที่มีคาฮิวริสติกเทากับ -1 อัลกอริทึมปนเขาใชตัวกระทําการเพื่อ
สรางสถานะลูกตัวแรกของสถานะที่ 1 แลววัดคาฮิวริสติกได 0 ซึ่งมีคาดีขึ้น ถาสังเกตจาก
รูปที่ จะพบวาสถานะที่ 1 มีสถานะลูกทั้งหมด 3 ตัว แตในกรณีของอัลกอริทึมปนเขานี้
เมื่อไดสถานะลูกตัวแรกซึ่งมีคาอิวริสติกดีขึ้น อัลกอริทึมจะไมสรางสถานะลูกที่เหลืออีก 2
ตัว และจะไมยอนกลับมาที่สถานะลูกทั้ง 2 นี้ แมวาหลังจากนี้อัลกอริทึมจะคนไมพบ
คําตอบกลาวคือเปนการตัดทางเลือกทิ้ง ซึ่งการทําเชนนี้แมวาจะมีโอกาสไมพบคําตอบแต
ก็มีขอดีที่เปนการชวยลดเวลาอยางมาก จากนั้นอัลกอริทึมมาสถานะที่ 2 แลวเริ่มสราง
สถานะลูกไดสถานะที่ 3 ที่มีคาฮิวริสติก -1 ซึ่งแยลงในกรณีที่แยลงเชนนี้ อัลกอริทึมจะไม
ไปยังสถานะลูกตัวนี้และสรางสถานะลูกตัวตอไปโดยใชตัวกระทําการที่เหลือไดสถานะที่ 4
มีคาฮิวริสติกเทากับ -1 ไมดีขึ้นเชนกันจึงสรางสถานะลูกตัวถัดไป เปนสถานะที่5 มีคาฮิวริ
สติกเทากับ 1 เปนคาที่ดีขึ้น อัลกอริทึมจะมายังสถานะนี้และคนพบคําตอบในที่สุด
อัลกอริทึมปนเขานี้จะมีประสิทธิภาพมากดังเชนแสดงในตัวอยางนี้ซึ่งกระจาย
สถานะทั้งสิ้นเพียง 6 ตัวแลวพบคําตอบ เปรียบเทียบกับอัลกอริทึมการคนหาแนวกวาง
กอนซึ่งใชสถานะทั้งสิ้นถึง 11 ตัว อยางไรก็ดีอัลกอริทึมนี้จะมีประสิทธิภาพมาก ถาใช
ฟงกชันฮิวริสติกที่ดีมาก ๆ ในกรณีที่ฟงกชันฮิวริสติกไมดีนัก อัลกอริทึมนี้ก็อาจหลง
เสนทางได และอาจไมพบคําตอบแมวาปริภูมิที่กําลังคนหามีคําตอบอยูดวยก็ตาม สาเหตุ
การหลงเสนทางประการหนึ่งมาจากการเลือกสถานะลูก ซึ่งอัลกอริทึมจะไมไดพิจารณา
สถานะลูกทุกตัวโดยเมื่อพบสถานะลูกตัวใดที่ดีขึ้นก็จะเลือกทางนั้น อัลกอริทึมนี้สามารถ
ดัดแปลงเล็กนอยใหพิจารณาสถานะลูกทุกตัวใหครบกอน แลวเลือกสถานะลูกตัวที่มีคาฮิว
ริสติกสูงสุด เมื่อทําเชนนี้ก็จะทําใหอัลกอริทึมไดพิจารณาเสนทางที่ดีที่สุด ณ ขณะหนึ่ง ๆ
ไดดีขึ้นเราเรียกอัลกอริทึมที่ดัดแปลงนี้วาอัลกอริทึมปนเขาชันสุด (Steepest ascent hill
climbing)
40. การคนหาดีสุดกอน(Best-first search)
เปนกระบวนการคนหาขอมูลที่ไดนําเอาขอดีของทั้งการคนหาแบบลึกกอน
(Depth firstsearch) และการคนหาแบบกวางกอน(Breadth first search) มา
รวมกันเปนวิธีการเดียว โดยที่แตละขั้นของการคนหาในโหนดลูกนั้น การคนหาแบบดี
ที่ดีกอนจะเลือกเอา โหนดที่ดีที่สุด (most promising)และการที่จะทราบวาโหนดใด
ดีที่สุดนี้สามารถทําไดโดยอาศัยฮิวริสติกฟงกชัน ซึ่งฮิวริสติก ฟงกชันนี้จะทําหนาที่
เหมือนตัววัดผล และใหผลของการวัดนี้ออกมาเปนคะแนน รูปที่ 2.7 เปนตัวอยาง
ของการคนหาแบบดีที่สุดกอน ขั้นตอนนี้เริ่มจากตอน 1 สรางโหนดราก(root
node) ในขั้นตอน 2สรางโหนดลูกB และ C แลวตรวจสอบโหนด B และ C ดวยฮิวริ
สติกฟงกชัน ไดผลออกมาเปนคะแนนคือ 3 และ 1ตามลํ าดับ จากนั้นใหเลือก
โหนด C เปนโหนดตอไปที่เราสนใจ เพราะมีคานอยกวา (หมายเหตุ ในการเลือกนี้จะ
เลือกคามากสุด หรือนอยสุดก็ได ขึ้นอยูกับลักษณะของปญหา) แลวสรางโหนด ลูก
ใหกับโหนด C ในขั้นตอน 3 ไดโหนด D และ Eแลวตรวจสอบคะแนน
ได 4 และ 6 ตามลํ าดับ จากนั้นทํ าการเปรียบเทียบคาของโหนดทายสุด หรือ
เทอรมินอล โหนด(terminal node) ทุกโหนด วาโหนด ใดมีคาดีที่สุด ในที่นี้จะตอง
เลือกโหนด B เพราะมีคะแนนเพียง 3 (เลือกคะแนนตํ่าสุด) แลวสรางโหนด ลูกตาม
ขั้นตอน 4 ได F และ G แลวตรวจ สอบคะแนนได 6 และ 5 คะแนนตามลํ าดับ ทํา
เชนนี้เรื่อย ๆ จนพบคําตอบหรือจนไมสามารถ สรางโหนดตอไปไดอีก
41. 42. อัลกอริธึม: การคนหาแบบดีที่สุดกอน
1. เริ่มดวย OPEN ที่มีเพียงโหนดเริ่มตน
2. ทําจนกวาจะพบเปาหมาย หรือวาไมมีโหนดเหลืออยูใน OPEN
� เลือกโหนดที่ดีที่สุดใน OPEN
� สรางโหนดลูกใหกับโหนดที่ดีที่สุดนั้น
� สําหรับโหนดลูกแตละตัวใหทําดังตอไปนี้
i) ถาโหนดนั้นยังไมเคยถูกสรางมากอนหนานั้น ใหตรวจสอบคาของมัน
โดย
ใชฮิวริสติกฟงชัน แลวเพิ่มเขาไปใน OPEN แลวบันทึกวาเปน
โหนดแม
ii) ถาโหนดนั้นถูกสรางมากอนหนานี้แลว ใหเปลี่ยนโหนดแมของมัน ถา
เสน
ทางใหมที่ไดดีกวาโหนดแมตัวเดิม ในกรณีนี้ ใหปรับเปลี่ยนคา
ตามเสน
ทางที่อาจจะเกิดขึ้น
43. การคนหาแบบ Greedy (Greedy Algorithm)
กรีดีอัลกอริธึม เปนการคนหาแบบดีที่สุดกอน(Best first search) ที่งายที่สุด
หลักการของการคนหาแบบนี้คือ การเลือกโหนดที่ดีที่สุดตลอดเวลาอัลกอริธึม กรีดี
1. เลือกโหนดเริ่มตนมาหนึ่งโหนด
2. ใหโหนดที่เลือกมานี้เปนสถานะปจจุบัน
3. ใหทําตามขบวนการขางลางนี้จนกวาจะไมสามารถสรางโหนดลูกไดอีก
3.1 สรางสถานะใหมที่เปนโหนดลูกที่เปนไปไดทั้งหมดจากสถานะปจจุบัน
3.2 จากสถานะใหมที่สรางขึ้นมาทั้งหมด ใหเลือกสถานะ หรือ โหนดลูก ที่ดี
ที่สุดออกมาเพียงโหนดเดียว
4. กลับไปที่ขึ้นตอนที่ 2
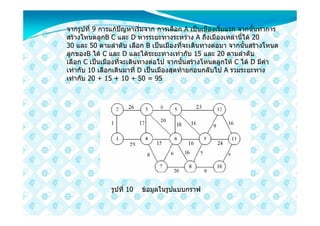
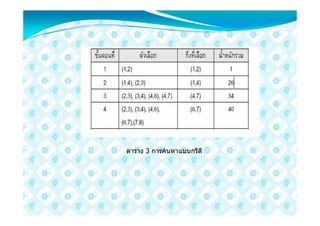
ตัวอยาง จากเรื่องการเดินทางของเซลแมนที่จะตองเดินทางไปยังเมือง A B C D ซึ่ง
มีระยะทางตามตารางที่ 3 เราจะแกปญหานี้ดวยวิธีการของกรีดีบาง
รูปที่ 9 การแกปญหาการ
เดินทางของเซลแมนดวยกรีดี
อัลกอริธึม
44. จากรูปที่ 9 การแกปญหาเริ่มจาก การเลือก A เปนเมืองเริ่มแรก จากนั้นทําการ
สรางโหนดลูกB C และ D หารระยะทางระหวาง A ถึงเมืองเหลานี้ได 20
30 และ 50 ตามลําดับ เลือก B เปนเมืองที่จะเดินทางตอมา จากนั้นสรางโหนด
ลูกของB ได C และ D และไดระยะทางเทากับ 15 และ 20 ตามลําดับ
เลือก C เปนเมืองที่จะเดินทางตอไป จากนั้นสรางโหนดลูกให C ได D มีคา
เทากับ 10 เลือกเดินมาที่ D เปนเมืองสุดทายกอนกลับไป A รวมระยะทาง
เทากับ 20 + 15 + 10 + 50 = 95
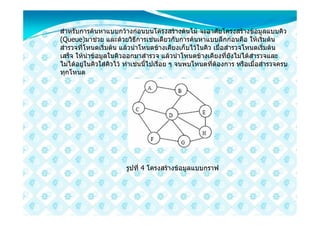
รูปที่ 10 ขอมูลในรูปแบบกราฟ
45. 46. การคนหาแบบ A*
การคนหาแบบ A* เปนอีกแบบของการคนหาแบบดีที่สุดกอน วิธีการเลือก
โหนดที่จะใชในการดําเนินการตอจะพิจารณาจากโหนดที่ดีที่สุด แตในกรณี
ของ A* นี้จะมีลักษณะพิเศษกวาคือ ในสวนของฮิวริสติกฟงกชัน ในกรณีของการ
คนหาแบบดีที่สุดกอนนั้น คาที่ไดจากฮิวริสติก ฟงกชัน จะเปนคาที่วัดจาก โหนด
ปจจุบัน แตในกรณีของ A* คาของฮิวริสติก ฟงกชัน จะวัดจากคา 2 คาคือ คาที่วัด
จากโหนดปจจุบันไปยังโหนดราก และจากโหนดปจจุบันไปยังโหนดเปาหมาย ถา
เราใหตัวแปร f แทนคาของฮิวริสติก ฟงกชัน g เปนฟงกชันที่ใชวัดคา cost จาก
สถานะเริ่มตนจนถึงสถานะปจจุบัน h' เปนฟงกชันที่ใชวัดคา cost จาก
สถานะปจจุบันถึงสถานะเปาหมาย ดังนั้น
f = g + h’
อัลกอริทึม A* (A* Search) เปนการขยายอัลกอริทึมดีสุดกอนโดยพิจารณา
เพิ่มเติมถึงตนทุนจากสถานะเริ่มตนมายังสถานะปจจุบันเพื่อใชคํานวณคาฮิวริสติก
ดวย ในกรณีของอัลกอริทึม A* เราตองการหาคาต่ําสุดของฟงกชัน f'ของ
สถานะ s นิยามดังนี้
f'(s)=g(s)+h'(s)
โดยที่ g คือฟงกชันที่คํานวณตนทุนจากสถานะเริ่มตนมายังสถานะปจจุบัน h' คือ
ฟงกชันที่ประมาณตนทุนจากสถานะปจจุบันไปยังคําตอบ ดังนั้น f' จึงเปนฟงกชันที่
ประมาณตนทุนจากสถานะเริ่มตนไปยังคําตอบ (ยิ่งนอยยิ่งดี) เรามองไดวา
ฟงกชัน h' คือฟงกชันฮิวริสติกที่เราเคยใชในการคนหาอื่น ๆ กอนหนานี้เชน
อัลกอริทึมปนเขา อัลกอริทึมดีสุดกอน เปนตน
47. ในที่นี้เราใสเครื่องหมาย ' เพื่อแสดงวาฟงกชันนี้เปนฟงกชันประมาณของฟงกชัน
จริงที่ไมรู (เราทําไดแคประมาณวา h' คือตนทุนจากสถานะปจจุบันไปยังคําตอบ
เราจะรูตนทุนจริงก็ตอเมื่อเราไดทําการคนหาจริงจนไปถึงคําตอบ
แลว) สวน g เปนฟงกชันที่คํานวณตนทุนจริงจากสถานะเริ่มตนมายัง
สถานะปจจุบัน (จึงไมไดใสเครื่องหมาย ' ) เพราะเราสามารถหาตนทุนจริงได
เนื่องจากไดคนหาจากสถานะเริ่มตนจนมาถึงสถานะปจจุบันแลว สวน f' ก็เปน
เพียงแคฟงกชันประมาณโดยการรวมตนทุนทั้งสอง คือ h' กับ g
อัลกอริทึม A* จะทําการคนหาโดยวิธีเดียวกันกับอัลกอริทึมดีสุดกอนทุก
ประการ ยกเวน ฟงกชันฮิวริสติกที่ใชเปลี่ยนมาเปน f' (ตางจากอัลกอริทึมดีสุด
กอนที่ใช h') โดยการใช f' อัลกอริทึม A* จึงใหความสําคัญกับสถานะหนึ่ง ๆ 2
ประการ คือ (1) สถานะที่ดีตองมี h' ดีคือตนทุนเพื่อจะนําไปสูคําตอบหลังจากนี้
ตองนอย และ (2) ตนทุนที่จายไปแลวกวาจะถึงสถานะนี้ (g) ตองนอยดวย เรา
จึงไดวา A* จะคนหาเสนทางที่ใหตนทุนโดยรวมนอยที่สุดตามคา f' ซึ่งตางจาก
อัลกอริทึมดีสุดกอน ที่เนนความสําคัญของสถานะที่ตนทุนหลังจากนี้ที่จะนําไปสู
คําตอบตองนอย โดยไมสนใจวาตนทุนที่จายไปแลวกวาจะนํามาถึงสถานะนี้ตอง
เสียไปเทาไหร
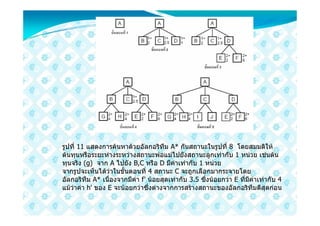
48. รูปที่ 11 แสดงการคนหาดวยอัลกอริทึม A* กันสถานะในรูปที่ 8 โดยสมมติให
ตนทุนหรือระยะหางระหวางสถานะพอแมไปยังสถานะลูกเทากับ 1 หนวย เชนตน
ทุนจริง (g) จาก A ไปยัง B,C หรือ D มีคาเทากับ 1 หนวย
จากรูปจะเห็นไดวาในขั้นตอนที่ 4 สถานะ C จะถูกเลือกมากระจายโดย
อัลกอริทึม A* เนื่องจากมีคา f' นอยสุดเทากับ 3.5 ซึ่งนอยกวา E ที่มีคาเทากับ 4
แมวาคา h' ของ E จะนอยกวาซึ่งตางจากการสรางสถานะของอัลกอริทึมดีสุดกอน
49.

































































![Arany Toldi[1]](https://cdn.slidesharecdn.com/ss_thumbnails/aranytoldi1-100113081053-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



































