新技術研究会
本日紹介する情報検索評価指標一覧
! Mean ReciprocalRank(MRR) (RR)
! E.M. Voorhees (1999). "Proceedings of the 8th Text Retrieval Conference". TREC-8 Question
Answering Track Report. pp. 77–82.
! 平均適合率 (AP)
! ??
! nDCG
! Kalervo Jarvelin, Jaana Kekalainen: Cumulated gain-based evaluation of IR techniques.
ACM Transactions on Information Systems 20(4), 422–446 (2002) Cumulated gain-based
evaluation of IR techniques
! Rank-Biased Precision (RBP)
! MOFFAT Alistair (Univ. Melbourne, AUS); ZOBEL Justin (RMIT Univ., AUS), ACM Trans Inf
Syst (USA) 2009
! Expected reciprocal rank (ERR)
! Olivier Chapelle, Donald Metlzer, Ya Zhang, and Pierre Grinspan. 2009. Expected reciprocal
rank for graded relevance. In Proceedings of the 18th ACM conference on Information and
knowledge management (CIKM '09).
! Session DCG
! K. J̈arvelin, S. L. Price, L. M. L. Delcambre, and M. L. Nielsen. Discounted cumulated gain
based evaluation of multiple-query ir sessions. In ECIR, pages 4–15, 2008.
! Session ERR
! 現在執筆中の論文に記載予定
7
新技術研究会
Normalized Discounted CumulativeGain(NDCG)
Kalervo Jarvelin, Jaana Kekalainen: Cumulated gain-based evaluation of IR techniques. ACM Transactions on Information Systems 20(4), 422–446 (2002)
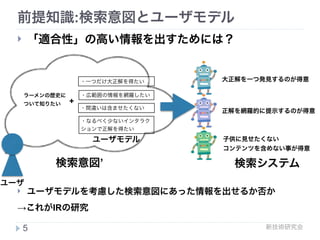
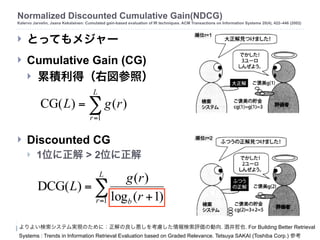
! とってもメジャー
! Cumulative Gain (CG)
! 累積利得(右図参照)
! Discounted CG
! 1位に正解 > 2位に正解
12
∑=
=
L
r
rgL
1
)()CG(
∑= +
=
L
r b r
rg
L
1 )1(log
)(
)DCG(
よりよい検索システム実現のために:正解の良し悪しを考慮した情報検索評価の動向. 酒井哲也. For Building Better Retrieval
Systems : Trends in Information Retrieval Evaluation based on Graded Relevance. Tetsuya SAKAI (Toshiba Corp.) 参考
新技術研究会
Expected reciprocal rankfor graded relevance(ERR)
Olivier Chapelle, Donald Metlzer, Ya Zhang, and Pierre Grinspan. 2009. In Proceedings of the 18th ACM conference on Information and knowledge management (CIKM '09).
! relevantの高いドキュメントが上位にあった場合、
閲覧を中止してしまう可能性を考慮したモデル
15
Expected Reciprocal Rank
[Chapelle et al CIKM09]
Query
Stop
Relevant?
View Next
Item
nosomewhathighly
black powder
ammunition
1
2
3
4
5
6
7
8
9
10
…
16.
新技術研究会
ERRの定義
・potision rで閲覧行動をstopする確率
但しRrはdocument r位のrelevanceであり
次の式で定義したとき
・ERRの定義は以下の通りとなる
16
Chapelleet al CIKM09]
rrankat
document"perfectthe"findingofUtility:(r)
1/r(r)
)positionatstopsuser(
1
1
rP
r
ERR
n
r
documentrtheofgraderelevance: th
rg
12gr
)positionatstopsuser(
1
1
rP
r
ERR
n
r
1
11
)1(
1 r
i
ri
n
r
RR
r
ERR
documertheofgraderelevance: th
rg
sP(user
2
12
docofrelevanceofProb. max
Rr g
g
r
r
ket. See text for discussion
dency among URLs on a search
form, the cascade model assume
results from top to bottom and
has a certain probability of bei
probability at position i.2
Onc
a document, he/she terminates
below this result are not exami
tion. It is of course natural to e
function of the relevance grade,
we will assimilate it to the oft
“relevance”. This generic versi
summarized in Algorithm 1.
Algorithm 1 The cascade user
Require: R1, . . . , R10 the relev
result page.
1: i = 1
2: User examines position i.
3: if random(0,1) ≤ Ri then
4: User is satisfied with the
stops.
5: else
6: i ← i + 1; go to 2
7: end if
Two instantiations of this m
[12, 8]. In the former, Ri is the
defined above for position-based
ability of click which can be int
the snippet. In that model, it is
ways satisfied after clicking. It c
the snippet looks attractive, bu
any relevant information on the
This is the reason why an exten
proposed in [8, Section 5], in w
satisfied after clicking. More pre
depending on the landing page
to the search result list after cli
1 have now to be understood as
the landing page.
In both models a document
ability Ri. The values Ri can
likelihood on the click logs. Al
the next section, the Ri values c
editorial grade of the URL. For
hood of a session for which the
position r is:
r−1
hood of a session for which the user is satisfi
position r is:
r−1Y
i=1
(1 − Ri)Rr,
2
The probability is in fact a function of the
d(i). However, for simplicity we shorten Rd
rrankat
document"perfectthe"findingofUtility:(r)
1/r(r)
)positionatstopsuser(
1
1
rP
r
ERR
n
r
1
11
)1(
1 r
i
ri
n
r
RR
r
ERR
documentrtheofgraderelevance: th
rg
positionatstopsP(user
2
12
docofrelevanceofProb. max
rRr g
g
r
r
g =4
rankingに対するdiscount
17.
新技術研究会
ERR 算出例
17
relevance
R
3/16
15/16
document
r
1
2
Algorithm2 Algorithm to compute the ERR metric (5) in
linear time.
Require: Relevance grades gi, 1 ≤ i ≤ n, and mapping
function R such as the one defined in (4).
p ← 1, ERR ← 0.
for r = 1 to n do
R ← R(gr)
ERR ← ERR + p · R/r
p ← p · (1 − R)
end for
return ERR
shown above it. The “effective” discount in ERR of docu-
ment at position r is indeed:
1
r
r−1Y
i=1
(1 − Ri).
Thus the more relevant the previous documents are, the
more discounted the other documents are. This diminish-
ing return property is desirable because it reflects real user
behavior.
Figure 3 summarizes our discussion up until this point.
The figure shows the connection between user models and
metrics. As the figure shows, most traditional measures,
such as DCG and RBP assume a position-based user brows-
ing model. As we have discussed, these models have been
shown to be poor approximations of actual user behavior.
the number of non-
Kth relevant docu
be useful for meas
gines [24]. Our met
support graded jud
browsing model th
the primary proble
the appropriate va
suming the user w
metric measures th
to be satisfied.
Second, ERR is c
metric [17]. Our m
and generalization
model as a user br
Zobel discuss the p
into RBP by mak
documents, the au
work. The combin
natural and provid
to set p a priori an
human judgments
as will be discussed
Third, suppose t
which corresponds
scenario it is easy t
E
ERR
3/16
3/16 + 13/16 * 15/16 * 1/2
= 291/512
step down
probability
13/16
13/16 * (1- 15/16)
= 13 / 240
……
ERR@2 = 291/512 + 3/16
新技術研究会
session DCG
K. J̈arvelin, S. L. Price, L. M. L. Delcambre, and M. L. Nielsen. Discounted cumulated gain based evaluation of multiple-query ir sessions. In ECIR, pages 4–15,
2008.
! session回数を考慮したdcg
20
Session DCG
[Järvelin et al ECIR 2008]
kenya cooking
traditional swahili
kenya cooking
traditional
2rel(r)
1
logb (r b 1)r 1
k
2rel(r)
1
logb (r b 1)r 1
k
1
logc (1 c 1)
DCG(RL1)
1
logc (2 c 1)
DCG(RL2)
to documents retrieved for later reformulations. For rank i
between 1 and k, there is no discount. For rank i between
k + 1 and 2k, the discount is 1/ logbq(2 + (bq 1)), where bq
is the log base. In general, if the document at rank i came
from the jth reformulation, then
sDG@i =
1
logbq(j + (bq 1))
DG@i
Session DCG is then the sum over sDG@i
sDCG@k =
mkX
i=1
2rel(i) 1
logbq(j + (bq 1)) logb(i + (b 1))
with j = b(i 1)/kc, and m the length of the session. We
use bq = 4. This implementation resolves a problem present
in the original definition by J¨arvelin et al. [6] by which docu-
ments in top positions of an earlier ranked list are penalized
more than documents in later ranked lists.
As with the standard definition of DCG, we can also com-
pute an “ideal” score based on an optimal ranking of docu-
ments in decreasing order of relevance to the query and then
normalize sDCG by that ideal score to obtain nsDCG@k.
nsDCG@k essentially assumes a specific browsing path:
ranks 1 through k in each subsequent ranked list, thereby
document c
was based o
ranked lists.
Figure 3
submissions
cases there i
the first que
rapid in bot
though Cen
lower recall
and 0.225 re
tional precis
e↵ectiveness
ranking they
We use th
in total) to
with norma
o↵ 10. We
2 · 10 = 20
used). Scat
nDCG@20 (
AP (esAP)
corresponds
sures are av
c c
c c
session回数に対するdiscount rankingに対するdiscount
新技術研究会
超最近の検索評価指標の動向
! Intent-Aware ExpectedReciprocal Rank
! L. Wang, P. N. Bennet and K. C-Thompson, Robust Ranking Mpodels via Risk-Sensitive
Optimazation. In Proc. of the SIGIR 2012. See also TREC WebTRAC 2013
! documentのrelevanceを考慮する際に
検索する意図(TOPIC)に適合しているかどうかを更に考慮
! Risk-sensitive Task(アダルトフィルタ)等の評価に使われ
る。
! Time-based calibration of effectiveness measures
! Mark D. Smucker. Department of Management Sciences. University of Waterloo,
Canada mark.smucker@uwaterloo.ca. Charles L. A. Clarke. School of Computer
Science(SIGIR 2012) Best PAPER
! 評価時間による検索有効性測定の補正
! 検索クエリの一文字目を入れただけでクエリサジェスチョン
したりその検索結果を提示したりするケースにも対応できる
23











![新技術研究会
Expected reciprocal rank for graded relevance(ERR)
Olivier Chapelle, Donald Metlzer, Ya Zhang, and Pierre Grinspan. 2009. In Proceedings of the 18th ACM conference on Information and knowledge management (CIKM '09).
! relevantの高いドキュメントが上位にあった場合、
閲覧を中止してしまう可能性を考慮したモデル
15
Expected Reciprocal Rank
[Chapelle et al CIKM09]
Query
Stop
Relevant?
View Next
Item
nosomewhathighly
black powder
ammunition
1
2
3
4
5
6
7
8
9
10
…](https://image.slidesharecdn.com/random-141201235755-conversion-gate01/85/slide-15-320.jpg)
![新技術研究会
ERRの定義
・potision rで閲覧行動をstopする確率
但しRrはdocument r位のrelevanceであり
次の式で定義したとき
・ERRの定義は以下の通りとなる
16
Chapelle et al CIKM09]
rrankat
document"perfectthe"findingofUtility:(r)
1/r(r)
)positionatstopsuser(
1
1
rP
r
ERR
n
r
documentrtheofgraderelevance: th
rg
12gr
)positionatstopsuser(
1
1
rP
r
ERR
n
r
1
11
)1(
1 r
i
ri
n
r
RR
r
ERR
documertheofgraderelevance: th
rg
sP(user
2
12
docofrelevanceofProb. max
Rr g
g
r
r
ket. See text for discussion
dency among URLs on a search
form, the cascade model assume
results from top to bottom and
has a certain probability of bei
probability at position i.2
Onc
a document, he/she terminates
below this result are not exami
tion. It is of course natural to e
function of the relevance grade,
we will assimilate it to the oft
“relevance”. This generic versi
summarized in Algorithm 1.
Algorithm 1 The cascade user
Require: R1, . . . , R10 the relev
result page.
1: i = 1
2: User examines position i.
3: if random(0,1) ≤ Ri then
4: User is satisfied with the
stops.
5: else
6: i ← i + 1; go to 2
7: end if
Two instantiations of this m
[12, 8]. In the former, Ri is the
defined above for position-based
ability of click which can be int
the snippet. In that model, it is
ways satisfied after clicking. It c
the snippet looks attractive, bu
any relevant information on the
This is the reason why an exten
proposed in [8, Section 5], in w
satisfied after clicking. More pre
depending on the landing page
to the search result list after cli
1 have now to be understood as
the landing page.
In both models a document
ability Ri. The values Ri can
likelihood on the click logs. Al
the next section, the Ri values c
editorial grade of the URL. For
hood of a session for which the
position r is:
r−1
hood of a session for which the user is satisfi
position r is:
r−1Y
i=1
(1 − Ri)Rr,
2
The probability is in fact a function of the
d(i). However, for simplicity we shorten Rd
rrankat
document"perfectthe"findingofUtility:(r)
1/r(r)
)positionatstopsuser(
1
1
rP
r
ERR
n
r
1
11
)1(
1 r
i
ri
n
r
RR
r
ERR
documentrtheofgraderelevance: th
rg
positionatstopsP(user
2
12
docofrelevanceofProb. max
rRr g
g
r
r
g =4
rankingに対するdiscount](https://image.slidesharecdn.com/random-141201235755-conversion-gate01/85/slide-16-320.jpg)
![新技術研究会
ERR 算出例
17
relevance
R
3/16
15/16
document
r
1
2
Algorithm 2 Algorithm to compute the ERR metric (5) in
linear time.
Require: Relevance grades gi, 1 ≤ i ≤ n, and mapping
function R such as the one defined in (4).
p ← 1, ERR ← 0.
for r = 1 to n do
R ← R(gr)
ERR ← ERR + p · R/r
p ← p · (1 − R)
end for
return ERR
shown above it. The “effective” discount in ERR of docu-
ment at position r is indeed:
1
r
r−1Y
i=1
(1 − Ri).
Thus the more relevant the previous documents are, the
more discounted the other documents are. This diminish-
ing return property is desirable because it reflects real user
behavior.
Figure 3 summarizes our discussion up until this point.
The figure shows the connection between user models and
metrics. As the figure shows, most traditional measures,
such as DCG and RBP assume a position-based user brows-
ing model. As we have discussed, these models have been
shown to be poor approximations of actual user behavior.
the number of non-
Kth relevant docu
be useful for meas
gines [24]. Our met
support graded jud
browsing model th
the primary proble
the appropriate va
suming the user w
metric measures th
to be satisfied.
Second, ERR is c
metric [17]. Our m
and generalization
model as a user br
Zobel discuss the p
into RBP by mak
documents, the au
work. The combin
natural and provid
to set p a priori an
human judgments
as will be discussed
Third, suppose t
which corresponds
scenario it is easy t
E
ERR
3/16
3/16 + 13/16 * 15/16 * 1/2
= 291/512
step down
probability
13/16
13/16 * (1- 15/16)
= 13 / 240
……
ERR@2 = 291/512 + 3/16](https://image.slidesharecdn.com/random-141201235755-conversion-gate01/85/slide-17-320.jpg)


![新技術研究会
session DCG
K. J ̈arvelin, S. L. Price, L. M. L. Delcambre, and M. L. Nielsen. Discounted cumulated gain based evaluation of multiple-query ir sessions. In ECIR, pages 4–15,
2008.
! session回数を考慮したdcg
20
Session DCG
[Järvelin et al ECIR 2008]
kenya cooking
traditional swahili
kenya cooking
traditional
2rel(r)
1
logb (r b 1)r 1
k
2rel(r)
1
logb (r b 1)r 1
k
1
logc (1 c 1)
DCG(RL1)
1
logc (2 c 1)
DCG(RL2)
to documents retrieved for later reformulations. For rank i
between 1 and k, there is no discount. For rank i between
k + 1 and 2k, the discount is 1/ logbq(2 + (bq 1)), where bq
is the log base. In general, if the document at rank i came
from the jth reformulation, then
sDG@i =
1
logbq(j + (bq 1))
DG@i
Session DCG is then the sum over sDG@i
sDCG@k =
mkX
i=1
2rel(i) 1
logbq(j + (bq 1)) logb(i + (b 1))
with j = b(i 1)/kc, and m the length of the session. We
use bq = 4. This implementation resolves a problem present
in the original definition by J¨arvelin et al. [6] by which docu-
ments in top positions of an earlier ranked list are penalized
more than documents in later ranked lists.
As with the standard definition of DCG, we can also com-
pute an “ideal” score based on an optimal ranking of docu-
ments in decreasing order of relevance to the query and then
normalize sDCG by that ideal score to obtain nsDCG@k.
nsDCG@k essentially assumes a specific browsing path:
ranks 1 through k in each subsequent ranked list, thereby
document c
was based o
ranked lists.
Figure 3
submissions
cases there i
the first que
rapid in bot
though Cen
lower recall
and 0.225 re
tional precis
e↵ectiveness
ranking they
We use th
in total) to
with norma
o↵ 10. We
2 · 10 = 20
used). Scat
nDCG@20 (
AP (esAP)
corresponds
sures are av
c c
c c
session回数に対するdiscount rankingに対するdiscount](https://image.slidesharecdn.com/random-141201235755-conversion-gate01/85/slide-20-320.jpg)


























![[DL輪読会]BERT: Pre-training of Deep Bidirectional Transformers for Language Und...](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20181019-181019010218-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)





















































