More Related Content

PPTX
第7回 KAIM 金沢人工知能勉強会 回帰分析と使う上での注意事項 
PPT
130502 discrete choiceseminar_no.3 
PDF

PPTX
第13回 KAIM 金沢人工知能勉強会 混合した信号を分解する視点からみる主成分分析 
PPT
130418 discrete choiceseminar_no.1 
PPT
Model seminar shibata_100710 
PDF

PPT
130425 discrete choiceseminar_no.2 What's hot

PDF

PDF
![[PRML] パターン認識と機械学習(第3章:線形回帰モデル)](https://cdn.slidesharecdn.com/ss_thumbnails/prmlchapter3-171003081954-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[PRML] パターン認識と機械学習(第3章:線形回帰モデル) 
PDF

PDF

PDF

PDF

PPTX
Maximum Entropy IRL(最大エントロピー逆強化学習)とその発展系について 
PDF

PPTX

PDF
Similar to ラビットチャレンジレポート 機械学習

PPTX

PDF
![[DSO] Machine Learning Seminar Vol.2 Chapter 3](https://cdn.slidesharecdn.com/ss_thumbnails/chapter3slides-200226170409-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DSO] Machine Learning Seminar Vol.2 Chapter 3 ![[読会]Logistic regression models for aggregated data](https://cdn.slidesharecdn.com/ss_thumbnails/logisticregressionmodelsforaggregateddata-211229094148-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[読会]Logistic regression models for aggregated data 
PDF

PDF

PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節 潜在意味空間における分類問題 
PPT

PDF
「トピックモデルによる統計的潜在意味解析」読書会 4章前半 
PDF
2013.12.26 prml勉強会 線形回帰モデル3.2~3.4 
PPTX

PDF

PPTX

PDF
数理モデリングからはじめるPython数理最適化 PyData.Tokyo 2017/6/28 Retty Inc. Iwanaga Jiro 
PPTX
Rabbit challenge machine learning 
PDF

PDF

PPTX

PPTX

PDF
ラビットチャレンジレポート 機械学習
- 1.
- 2.
- 3.
- 4.
- 5.
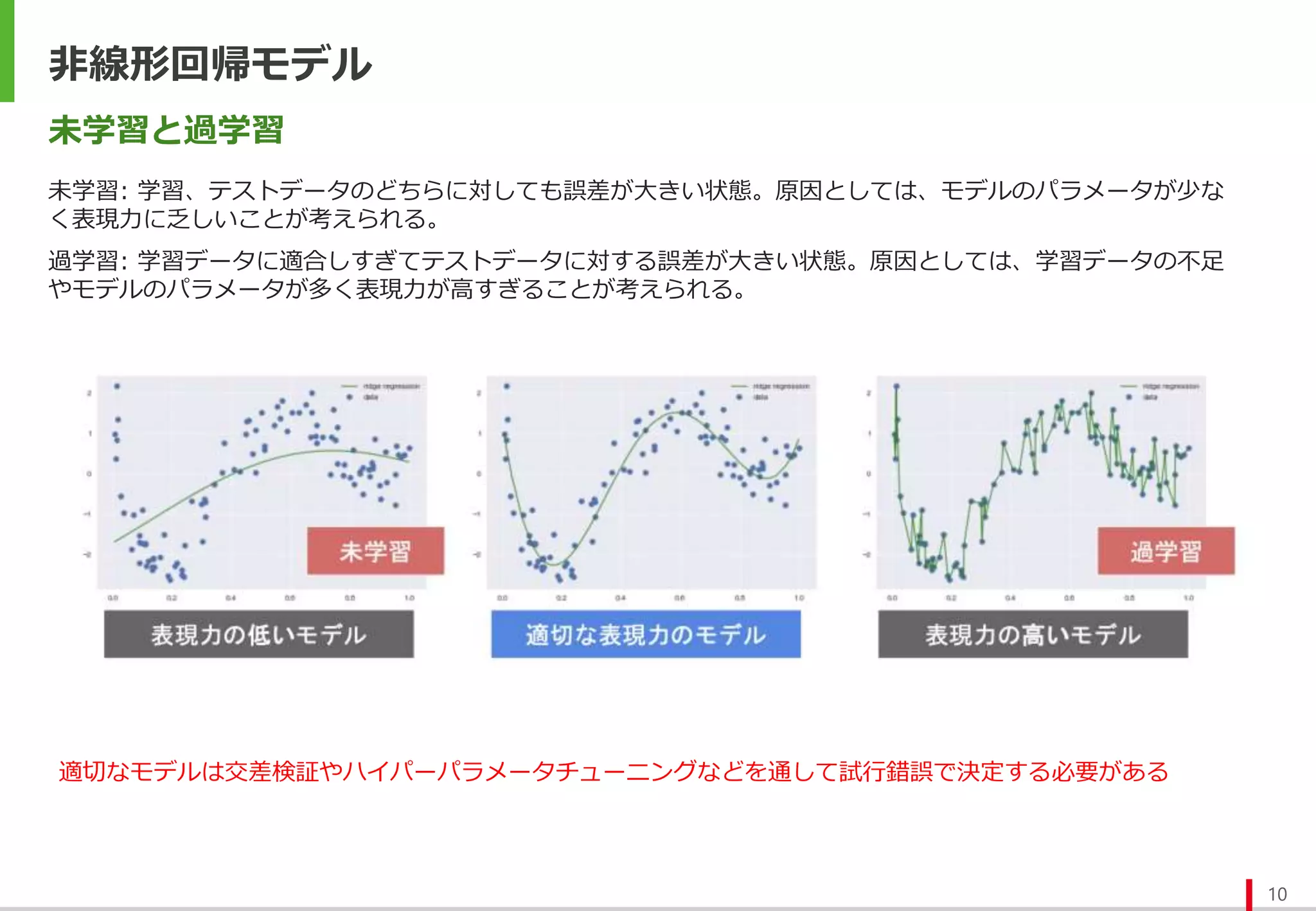
線形回帰モデル
5
パラメータの推定方法
最小二乗法: 実測値と予測値の差(残差) の二乗和が最小となるパラメータで推定する方法。
最尤法:誤差がある確率分布に従う確率変数と仮定し、その尤度関数を最大にするパラメータで推定する方法。
誤差が独立に正規分布に従うと仮定した場合、最尤法の結果と最小二乗法の結果は一致する。
𝐿𝑜𝑠𝑠(𝒘) =
𝑗=1
𝑚
(𝑦𝑗 − 𝑦𝑗)2
=
𝑗=1
𝑚
(𝑦𝑗 − 𝒘𝑻
𝒙𝑗 − 𝑤0)2
残差平方和の式
𝑦𝑗: 実測値
𝑦𝑗: 予測値
𝐿 𝒘 =
𝑗=1
𝑚
1
2𝜋𝜎
𝑒
−
(𝑦𝑗−𝑦𝑗)2
2𝜎2
=
1
(2𝜋𝜎)
𝑚
2
𝑒
−
𝑗=1
𝑚
(𝑦𝑗−𝒘𝑻𝒙𝑗−𝑤0)2
2𝜎2
尤度関数の式
機械学習の分野では、上式のようなパラメータ推定のために最小化する関数を損失関数や誤差関数と呼ぶ
尤度関数の対数をとると、残差平方和の符号をマイナスにして定数倍したものに定数項を加えたものになる
従って残差平方和を最小化する問題と尤度関数を最大にする問題は等価であることが分かる
𝑙 𝒘 = log𝐿 𝒘 = −
1
2𝜎2
𝑗=1
𝑚
𝑦𝑗 − 𝒘𝑻
𝒙𝑗 − 𝑤0
2
−
𝑚
2
log(2𝜋𝜎)
対数尤度関数の式
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
ロジスティック回帰モデル
14
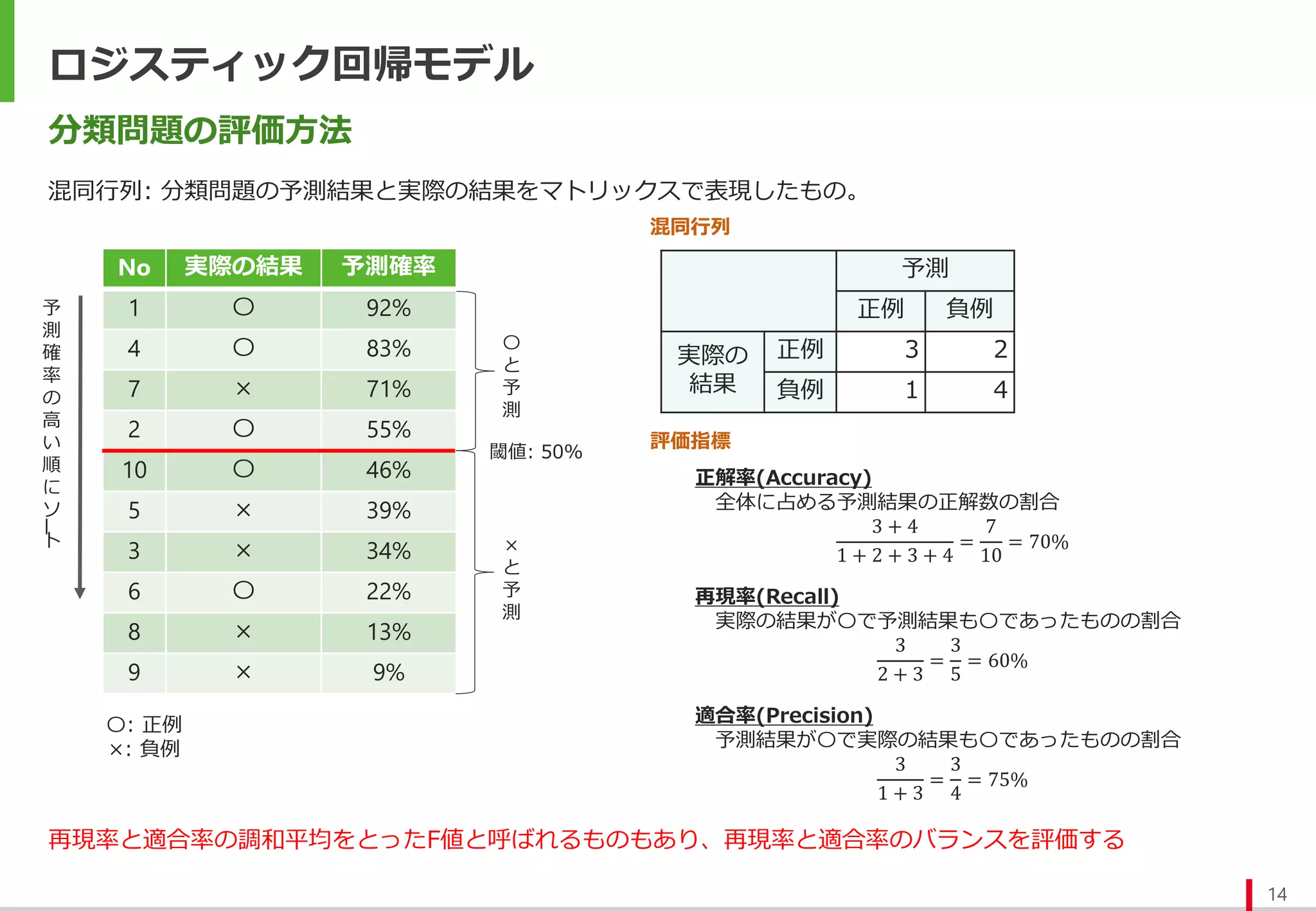
分類問題の評価方法
混同行列: 分類問題の予測結果と実際の結果をマトリックスで表現したもの。
予測
正例 負例
実際の
結果
正例3 2
負例 1 4
No 実際の結果 予測確率
1 〇 92%
4 〇 83%
7 × 71%
2 〇 55%
10 〇 46%
5 × 39%
3 × 34%
6 〇 22%
8 × 13%
9 × 9%
予
測
確
率
の
高
い
順
に
ソ
ー
ト
評価指標
〇
と
予
測
×
と
予
測
閾値: 50%
〇: 正例
×: 負例
正解率(Accuracy)
全体に占める予測結果の正解数の割合
3 + 4
1 + 2 + 3 + 4
=
7
10
= 70%
再現率(Recall)
実際の結果が〇で予測結果も〇であったものの割合
3
2 + 3
=
3
5
= 60%
適合率(Precision)
予測結果が〇で実際の結果も〇であったものの割合
3
1 + 3
=
3
4
= 75%
混同行列
再現率と適合率の調和平均をとったF値と呼ばれるものもあり、再現率と適合率のバランスを評価する
- 15.
- 16.
ロジスティック回帰モデル
16
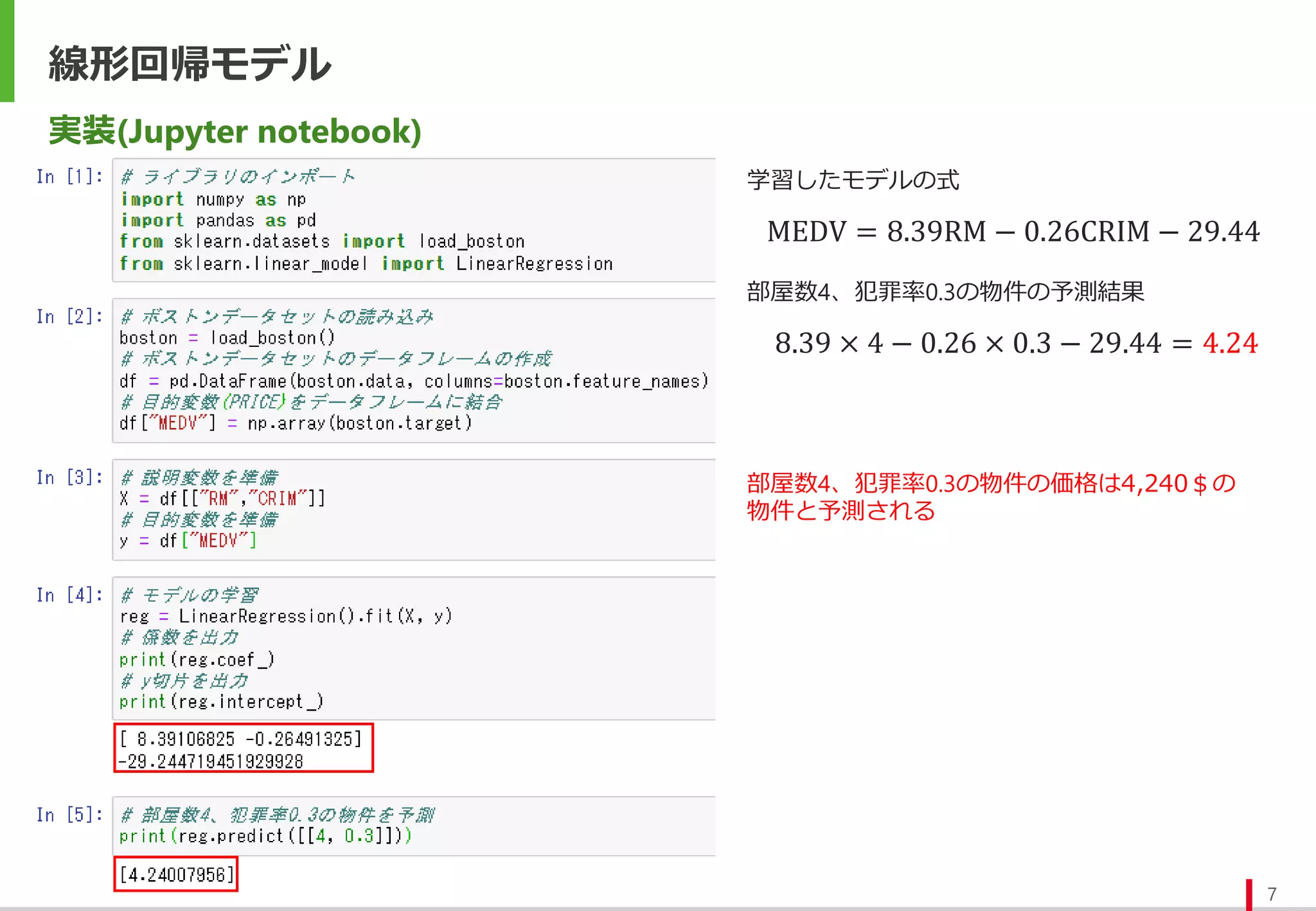
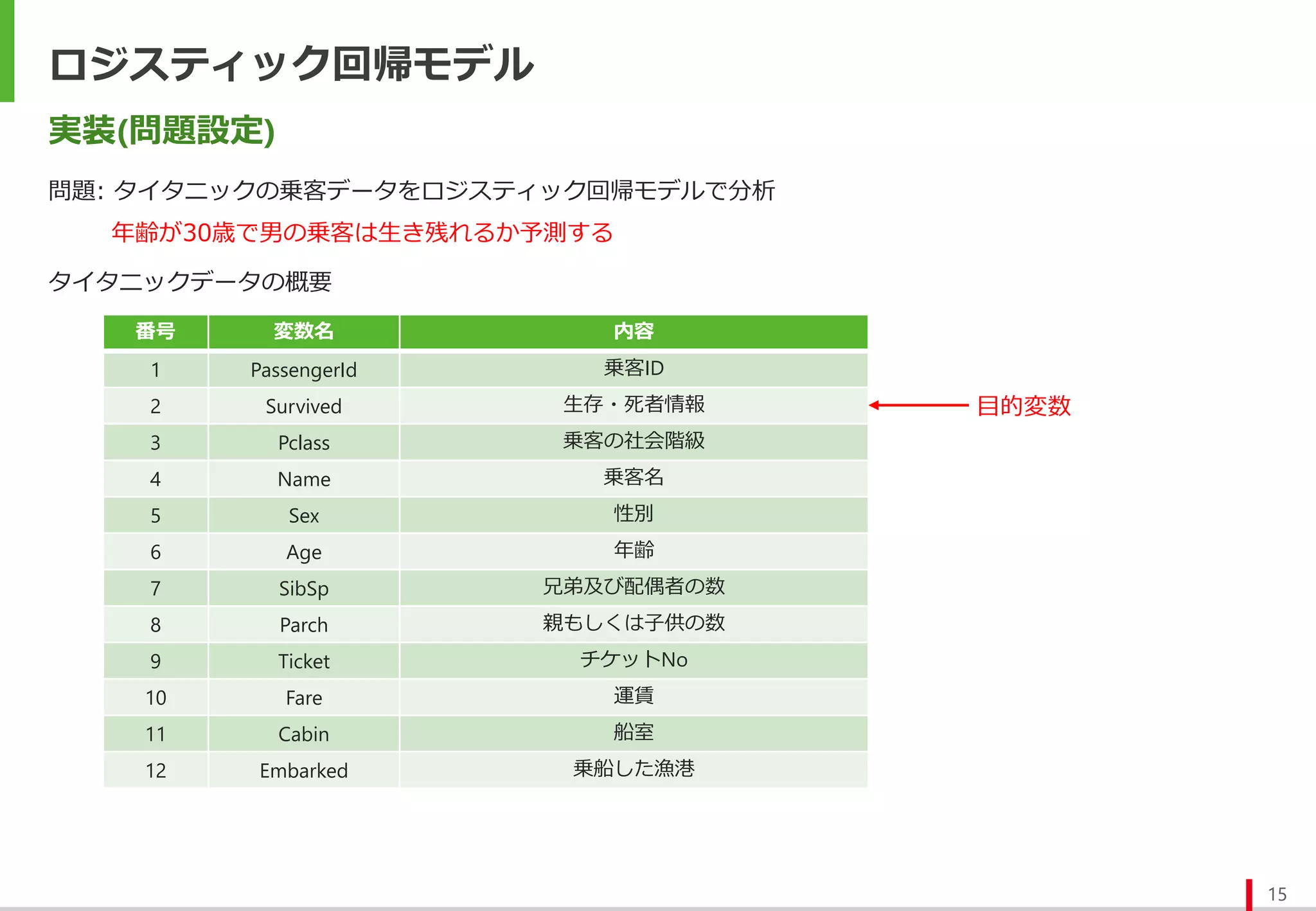
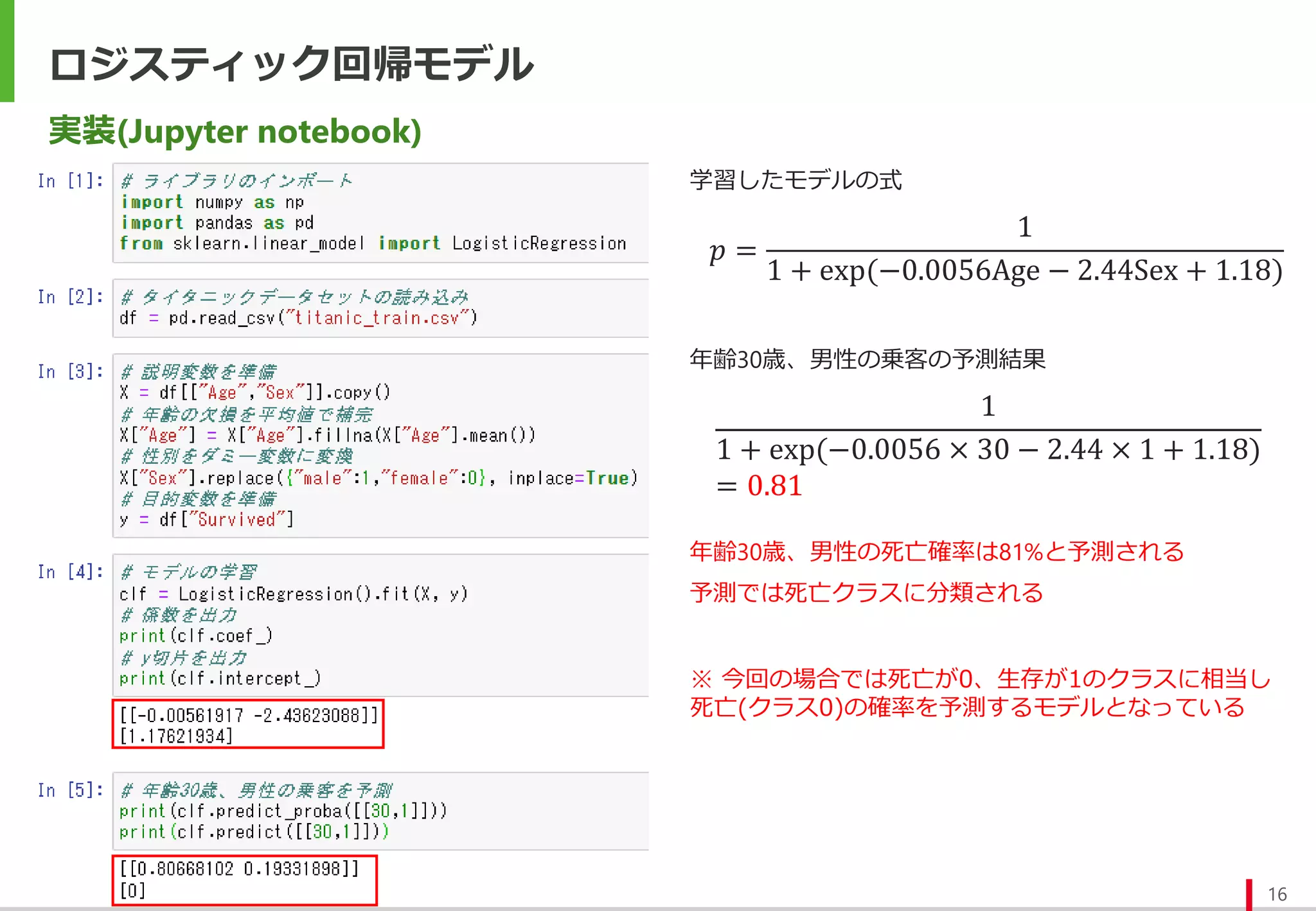
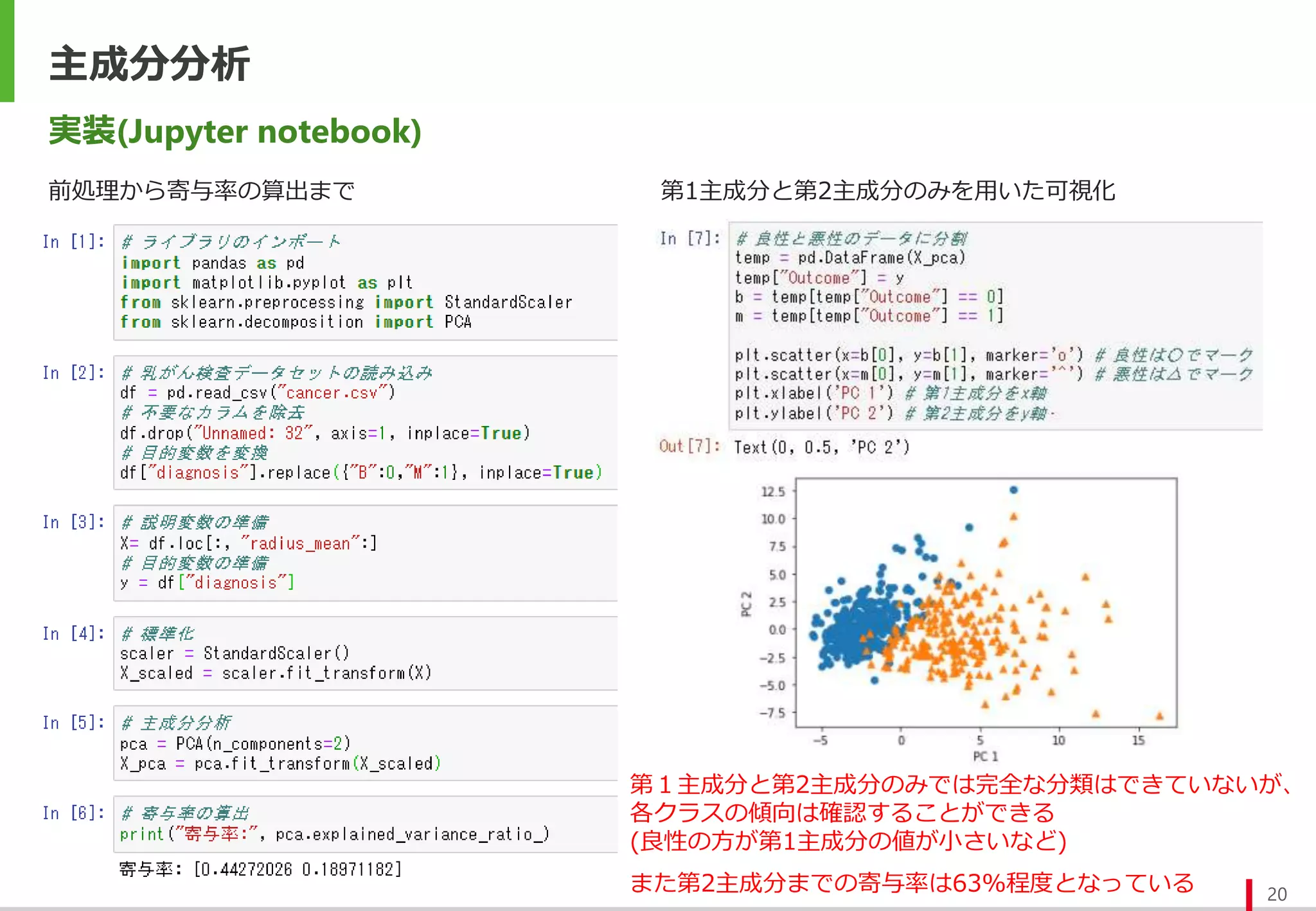
実装(Jupyter notebook)
𝑝 =
1
1+ exp(−0.0056Age − 2.44Sex + 1.18)
学習したモデルの式
1
1 + exp(−0.0056 × 30 − 2.44 × 1 + 1.18)
= 0.81
年齢30歳、男性の乗客の予測結果
年齢30歳、男性の死亡確率は81%と予測される
予測では死亡クラスに分類される
※ 今回の場合では死亡が0、生存が1のクラスに相当し
死亡(クラス0)の確率を予測するモデルとなっている
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.