Recommended
PPTX
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
3次元レジストレーション(PCLデモとコード付き)
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
PDF
cvpaper.challenge 研究効率化 Tips
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
PDF
自己教師学習(Self-Supervised Learning)
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
PDF
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
PDF
【論文読み会】Universal Language Model Fine-tuning for Text Classification
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PPTX
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
PDF
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
20160724_cv_sfm_revisited
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
PDF
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
PDF
PDF
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
PDF
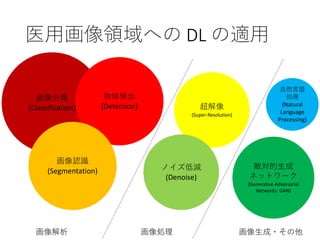
人工知能技術を用いた各医学画像処理の基礎 (2022/09/09)
PPTX
令和元年度 実践セミナー - Deep Learning 概論 -
More Related Content
PPTX
PDF
SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜
PDF
3次元レジストレーション(PCLデモとコード付き)
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PDF
PDF
PDF
cvpaper.challenge 研究効率化 Tips
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
What's hot
PDF
自己教師学習(Self-Supervised Learning)
PPTX
Swin Transformer (ICCV'21 Best Paper) を完璧に理解する資料
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
PDF
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
PDF
【論文読み会】Universal Language Model Fine-tuning for Text Classification
PDF
SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜
PPTX
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
PPTX
物体検出の歴史(R-CNNからSSD・YOLOまで)
PDF
PDF
PDF
BlackBox モデルの説明性・解釈性技術の実装
PPTX
20160724_cv_sfm_revisited
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
PDF
PPTX
[DL輪読会]Learning Latent Dynamics for Planning from Pixels
PDF
PDF
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
PPTX
PyTorchLightning ベース Hydra+MLFlow+Optuna による機械学習開発環境の構築
Similar to 人工知能を用いた医用画像処理技術
PDF
人工知能技術を用いた各医学画像処理の基礎 (2022/09/09)
PPTX
令和元年度 実践セミナー - Deep Learning 概論 -
PDF
PDF
[Japan Tech summit 2017] MAI 001
PDF
Deep learningの概要とドメインモデルの変遷
PDF
PDF
PDF
IVS CTO Night & Day 2016 Tech Talk - AI
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
東北大学 先端技術の基礎と実践_深層学習による画像認識とデータの話_菊池悠太
PPTX
PDF
[ビッグデータオールスターズ] クラウドサービス最新情報 機械学習/AIでこんなことまでできるんです! (Microsoft編)
PDF
PDF
[Developers Summit 2017] MicrosoftのAI開発機能/サービス
PDF
Akira shibata at developer summit 2016
PDF
画像認識モデルを自動的に作る。1日以内に。~Simple And Efficient Architecture Search for Convolutio...
PDF
PDF
PPTX
PDF
NVIDIA Seminar ディープラーニングによる画像認識と応用事例
More from Yutaka KATAYAMA
PPTX
PPTX
PPTX
PDF
PDF
Sparse coding Super-Resolution を用いた核医学画像処理
PPTX
人工知能を用いた医用画像処理技術 1. 2. Engineer・技師としての自己紹介
…………………………………… 開 発 業 ……………………………………
• 1998 年 : オートバイ用マフラーの開発・製造
• CAD/CAM を用いたマシニング
• オンラインショッピングシステム (cgi,JavaScript) の構築
…………………………………… 放射線技師 ……………………………………
• 2003 年: 大阪大学医学部附属病院 (Intern)
• 2004 年: 市立泉佐野りんくう総合医療センター (非常勤)
• 2006 年: 社会医療法人仙養会 北摂総合病院 (医療情報)
• 2007 年: 大阪市立大学医学部附属病院 (MI と MR)
• 2018 年: 人工知能研究会 (大阪市立大学放射線診断学・IVR 学) に Join
………………………………… 主な研究内容 …………………………………………………………………………………………………
• EGS4 を用いて低エネルギー領域の視野外 X 線のモンテカルロシミュレーション
• Bilateral Filter を用いた核医学画像の画質改善1
• Super-Resolution による放射線画像の高解像度化2
• Compressed Sensing を用いた CT の被曝低減処理
• 深層学習を用いた Detection/Classification
• 敵対的生成ネットワーク Generative Adversarial Networks (GAN) を用いた放射線画像の生成
• 敵対的生成ネットワーク Generative Adversarial Networks (GAN) を用いた音楽のスタイル変換
1) 片山 豊, 上田健太郎, 日浦慎作, 他.
骨シンチグラフィへのバイラテラルフィルタの適用.
日本放射線技術学会雑誌, 2013, 69.12: 1363-1371.
2) 片山 豊, 上田 健太郎, 日浦 慎作, 他.
PET 画像に対する超解像を用いたデノイズ手法の適用.
日本放射線技術学会雑誌, 2018, 74.7: 653-660.
3. 巷でよく言われる人工知能 (AI)
• yes/no の分類
• a, b, c, … の分類
⇒ 分類のためのモデル構築
• スパム分類
• ヒト・イヌ・ネコと言ったカテゴリへの画像分類
• AI に職が奪われる
• FAX すらなくならない
日本ではきっと起こらない
• アノテーションを行う
仕事を創造
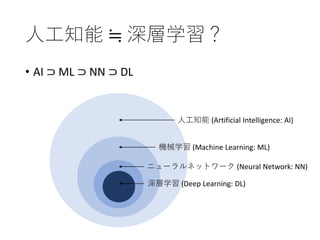
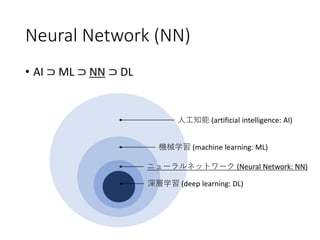
4. 人工知能 ≒ 深層学習?
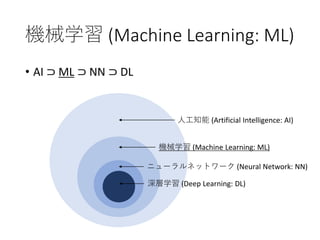
• AI ⊃ ML ⊃ NN ⊃ DL
人工知能 (Artificial Intelligence: AI)
機械学習 (Machine Learning: ML)
ニューラルネットワーク (Neural Network: NN)
深層学習 (Deep Learning: DL)
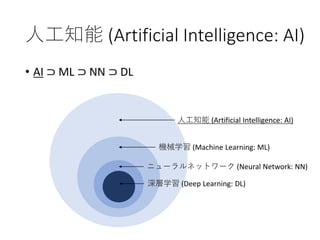
5. 人工知能 (Artificial Intelligence: AI)
• AI ⊃ ML ⊃ NN ⊃ DL
人工知能 (Artificial Intelligence: AI)
機械学習 (Machine Learning: ML)
ニューラルネットワーク (Neural Network: NN)
深層学習 (Deep Learning: DL)
6. 主な AI の定義
定義 人物
人工的に作られた人間のような知能,
ないしはそれを作る技術
松尾 豊
(東京大学大学院)
人工的に作られた,知能を持つ実態.
あるいはそれをつくろうとすることに
よって知能自体を研究する分野である
中島 秀之
(公立はこだて未来大学長)
人間の頭脳活動を極限まで
シミュレートするシステムである
長尾 真
(京都大学名誉教授)
引用:『深層学習教科書 ディープラーニング G 検定 公式テキスト』(出典:『人工知能学会誌』)
7. AI の種類
• 理想: 人間のように考えて行動できる AI
⇒ 汎用的な AI = AGI: Artificial General Intelligence
⇒ 強い AI (Strong AI)
• 現実: 人より巧みに行える物事が
予め定義された一つに限定
⇒ 弱い AI (Narrow AI)
K.I.T.T.@ナイトライダー
(1982-1986)
ドラえもん
(1969-1996)
則巻アラレ
(1981-1986)
Siri@Apple (2011-)
(自然言語処理)
8. AI の成果・事例
• 画像認識に関する主な事例
• 物体認識: 犬や猫の識別や,物体の意味の言語化など
• 不良品の検出: 製造業で作る部品などの検品など
• 異物混入の検出: 食品の製造ラインでの異物検出など
• 病変の検出: 医療用画像 (Xp や MMG など) から病変を見つけるなど
• 自動運転: 産業界で競争が激化している
• 音声認識に関する主な事例
• スマートスピーカー: Google Home や Amazon Echo など,
音声で問い掛けると,何らかの回答を話す製品
• 自然言語処理に関する主な事例
• チャット bot: Web サイト上で質問に対する適切な回答を
自動的に返し会話を成立させるもの (ex: 女子高生 AI「りんな」)
• ロボティクス (強化学習)に関する主な事例
• ゲームの自動対戦: 2015 年にプロ囲碁棋士を AI (AlphaGo) が破った
9. 10. 11. AI と人間
• AI
⇒ データを与えられた近傍のみ予測可能
• 人間
⇒ データを与えられてない領域でもある程度予測可能
内挿: 人間のプロ以上
外挿: 乳幼児未満
AI
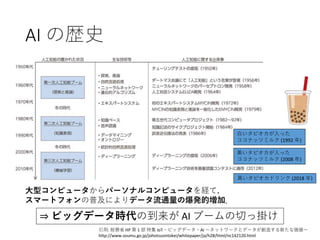
12. 13. AI の歴史
引用: 総務省 HP 第 1 部 特集 IoT・ビッグデータ・AI ~ネットワークとデータが創造する新たな価値~
http://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h28/html/nc142120.html
大型コンピュータからパーソナルコンピュータを経て,
スマートフォンの普及によりデータ流通量の爆発的増加.
⇒ ビッグデータ時代の到来が AI ブームの切っ掛け
白いタピオカが入った
ココナッツミルク (1992 年)
黒いタピオカが入った
ココナッツミルク (2008 年)
黒いタピオカドリンク (2018 年)
14. 機械学習 (Machine Learning: ML)
• AI ⊃ ML ⊃ NN ⊃ DL
人工知能 (Artificial Intelligence: AI)
機械学習 (Machine Learning: ML)
ニューラルネットワーク (Neural Network: NN)
深層学習 (Deep Learning: DL)
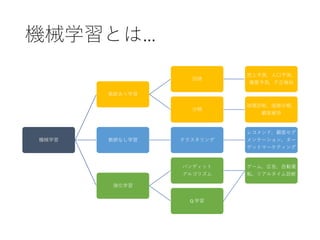
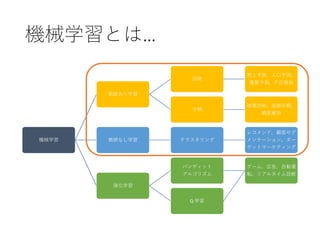
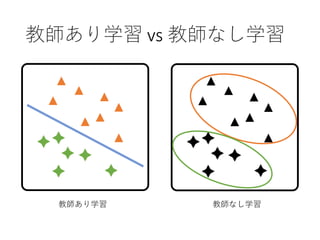
15. 16. 17. 18. 19. 教師あり学習 ⇒ 要教師データ
(Supervised Training)
• ラベリング済みのデータが与えられる学習方法
• “果物” について “色・重さ・種類” という要素を
学習することで,新しく入力された情報を予測
• 初期はこの分野の開発が最も発達
バナナ
リンゴ
ブドウ
訓練データ
未知の画像
機械学習アルゴリズム
画像はブドウ
20. 教師なし学習 ⇒ 自習
(Unsupervised Training)
• 出力データが学習時に与えられない学習方法
• 正解となる出力を与えず入力データから
規則性を発見していくのが特徴
• ラベリングされていないデータセットをもとに
機械が自ら学習を行うという仕組
購買データ
機械学習アルゴリズム
• レコメンデーション
• グルーピング
• 売上予測
21. 22. 23. 強化学習 ⇒ RIZAP
(Reinforcement Learning)
• 実行と失敗を繰り返す中で,
徐々に正しい方向を見いだすという学習方法
• 機械に単純なゲームをルールを教えずに実行
• 偶然に良い結果を出した時には報酬を与える
• 悪い結果の時には報酬なし or 罰を与える
• 報酬を最大限にすることを目標をするよう設定し
ゲームを複数回実行
• 最終的には最も効率よく正答にたどり着く方法にたどり着く
(ex: alphaGo)
24. 転移学習 (Transfer Learning)
• ある領域で学習させたモデルを
別の領域に適応させる技術
• 広くデータが手に入る領域で学習させたモデルを
少ないデータしかない領域に適応させたり,
シミュレータ環境で学習させたモデルを
現実に適応させたりする技術
• 学習データが増えた際にも追加で学習を行える
• 近年目覚ましい発達を遂げている
転移: “Transfer” or “Metastasis” ?
25. メタ学習 (Meta Learning)
• 学習方法を学習すること (Learning to Learn)
• コンピュータがデータから反復的に学習し,
人が気づいていなかったデータの中の
隠れた情報やパターンを見つけ出す
⇒ メタ学習は機械の学習能力を高めるのを
目的として,学習プロセスを学んでいく
⇒ Metastasis (転移) ではない!
26. Neural Network (NN)
• AI ⊃ ML ⊃ NN ⊃ DL
人工知能 (artificial intelligence: AI)
機械学習 (machine learning: ML)
ニューラルネットワーク (Neural Network: NN)
深層学習 (deep learning: DL)
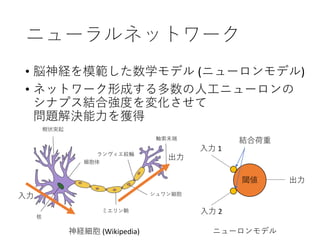
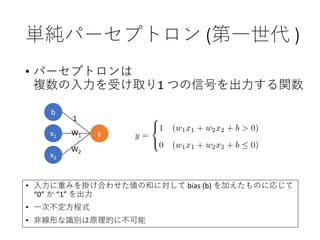
27. 28. 単純パーセプトロン (第一世代 )
• パーセプトロンは
複数の入力を受け取り1 つの信号を出力する関数
W1
W2
• 入力に重みを掛け合わせた値の和に対して bias (b) を加えたものに応じて
“0” か “1” を出力
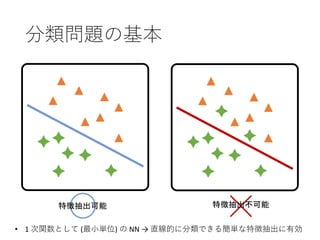
• 一次不定方程式
• 非線形な識別は原理的に不可能
b
x1 y
x2
1
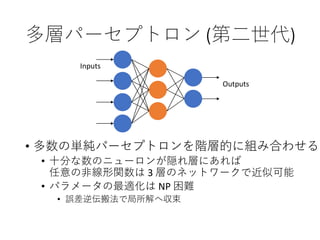
29. 30. 31. 多層パーセプトロン (第二世代)
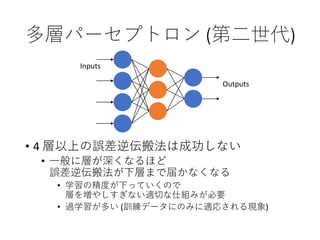
• 4 層以上の誤差逆伝搬法は成功しない
• 一般に層が深くなるほど
誤差逆伝搬法が下層まで届かなくなる
• 学習の精度が下っていくので
層を増やしすぎない適切な仕組みが必要
• 過学習が多い (訓練データにのみに適応される現象)
Inputs
Outputs
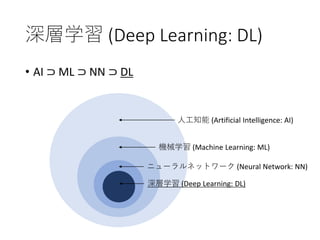
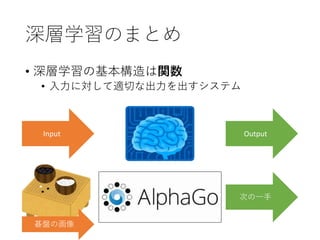
32. 深層学習 (Deep Learning: DL)
• AI ⊃ ML ⊃ NN ⊃ DL
人工知能 (Artificial Intelligence: AI)
機械学習 (Machine Learning: ML)
ニューラルネットワーク (Neural Network: NN)
深層学習 (Deep Learning: DL)
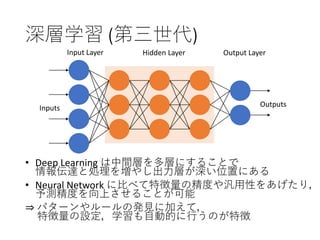
33. 深層学習 (第三世代)
• 多層 (4 層以上) の
ニューラルネットワークによる機械学習手法
• Deep Neural Network: DNN
• ありとあらゆる特徴を抽出可能
• 畳み込み層より特徴量を抽出
• 半自動で特徴量抽出が可能
深層学習 人工知能学会 深層学習手法の全体像 xiv
2 層: パーセプトロン
3 層: 階層型ニューラルネット
34. • Deep Learning は中間層を多層にすることで
情報伝達と処理を増やし出力層が深い位置にある
• Neural Network に比べて特徴量の精度や汎用性をあげたり,
予測精度を向上させることが可能
⇒ パターンやルールの発見に加えて,
特徴量の設定,学習も自動的に行うのが特徴
深層学習 (第三世代)
Inputs Outputs
Input Layer Hidden Layer Output Layer
35. 36. 深層学習のインパクト
• 2012 年には物体の認識率を競う
The ImageNet Large Scale Visual Recognition Challenge
(ILSVRC: 2010 年から始まった画像認識の競技会) で
Geoffrey Everest Hinton 率いるトロント大学が
深層学習によって圧勝 (画像識別精度 75 % → 96 %).
2012年以降の画像認識におけるエラー率の推移
37. 多層化 (4 層以上) による問題
• 勾配消失 (ニューラルネットワークの問題点)
• 複数の層を伝播していく過程で誤差情報が消失
• 活性化関数 (Rectified Linear Unit: ReLU) の使用
• 自己符号化器による事前学習で初期値設定
• 過学習 (過適合)
• 多層化によって複雑な事象をモデル化できるが
学習データにあまりに適合しすぎて
学習データ以外では正解率が低くなる現象
• 学習データだけに最適化されて汎用性がない状態
• アルゴリズムの改良とデータ量の増大
• 増大したデータを処理できるコンピュータの爆発的な性能向上
38. 過学習 (過適合)
• 精度が高い深層学習
• 学習データが少ないと過学習となり精度 100%
• 交差検証ができない
• 過学習 (過適合) を防ぐために正則化が必要
• 医療系 AI にありがちな精度が高すぎる研究は
データセットを再確認!
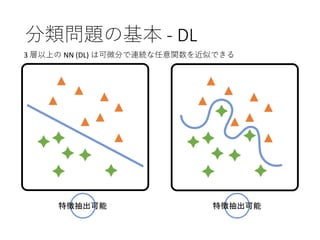
39. 40. 41. 42. AI による画像認識の仕組み
• 深層学習が登場前
• 用意したデータセットに対し,個別に特徴量を
ラベリング
⇒ 人の顔を学習させるのであれば,目,鼻および
口などを指定する必要があった.
• 深層学習の登場後
• 大量の画像パターンから特徴を自動的に抽出し,
学習モデルを作成
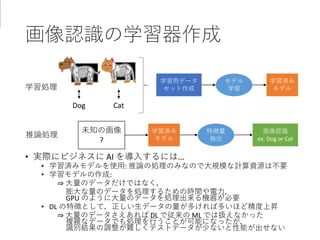
43. 44. 45. 画像認識の学習器作成
• 実際にビジネスに AI を導入するには…
• 学習済みモデルを使用: 推論の処理のみなので大規模な計算資源は不要
• 学習モデルの作成:
⇒ 大量のデータだけではなく,
膨大な量のデータを処理するための時間や電力,
GPU のように大量のデータを処理出来る機器が必要
• DL の特徴として,正しい生データの量が多ければ多いほど精度上昇
⇒ 大量のデータさえあれば DL で従来の ML では扱えなかった
複雑なデータでも処理を行うことが可能になったが,
識別結果の調整が難しくテストデータが少ないと性能が出せない
学習用データ
セット作成
学習済み
モデル
未知の画像
?
学習済み
モデル
画像認識
ex: Dog or Cat
学習処理
推論処理
Dog Cat
モデル
学習
特徴量
抽出
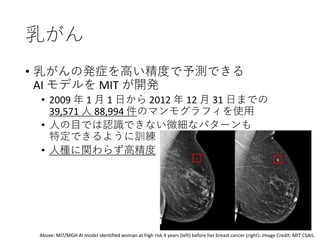
46. 乳がん
• 乳がんの発症を高い精度で予測できる
AI モデルを MIT が開発
• 2009 年 1 月 1 日から 2012 年 12 月 31 日までの
39,571 人 88,994 件のマンモグラフィを使用
• 人の目では認識できない微細なパターンも
特定できるように訓練
• 人種に関わらず高精度
Above: MIT/MGH AI model identified woman at high risk 4 years (left) before her breast cancer (right):.Image Credit: MIT CSAIL
47. 肺がん
A promising step forward for predicting lung cancer https://www.blog.google/technology/health/lung-cancer-prediction/
End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography Nature Medicine (2019)
• 肺がんの発症を高い精度で予測できる
AI モデルを Google が開発
• 匿名化された 45,856 件の胸部 CT スクリーニング
検査でがんが発見された症例
• Google の AI モデルは医師チームよりも
がんのケースを 5 %多く検知でき,
誤診率は 11 %低かった
48. 世界最大のデータセット
• Google は 2016 年に機械学習のためのデーセット
「Open Images」を初めてリリース.
• 2019 年 5 月 8 日に Open Images Dataset V5 を公開.
• Open Images Dataset V5 は 350 カテゴリにわたる
280 万個のセグメンテーションマスクが用意されている.
Google AI Blog: Announcing Open Images V5 and the ICCV 2019 Open Images Challenge
https://ai.googleblog.com/2019/05/announcing-open-images-v5-and-iccv-2019.html
49. 50. 51. データセットの作成
• 工学系の人は,
公開されている患者情報 (カルテ情報) しか
入手できずデータセットの作成ができない.
• 患者情報にアクセスできるのが医療職の
アドバンテージ (倫理委員会の許可が必須)
• 深層学習を用いた研究は工学系では安定期
• 深層学習を用いた研究は医療領域では臨床適用期
• 医療画像による病変検出は医師の代替でしかなく,
AI でないとできないことがない.
• 臨床としては意味があるが,
テクノロジーとしては面白さがない.
52. 53. 法律の解釈
• 平成 30 年 12 月 19 日
厚生労働省医政局医事課長通知文書
• 「人工知能 (AI) を用いた診断、
治療等の支援を行うプログラムの利用と
医師法第 17 条の規定との関係について」
• AI を用いた診断・治療支援を行うプログラムを利用
して
診療を行う場合についても、診断、治療等を行う主体は
医師であり、医師はその最終的な判断の責任を負う
こととなり、当該診療は医師法 第 17 条の医業として
行われるものであるので、十分ご留意をいただ
きたい。「診断責任は医師」
⇒ こう定義されたので医療 AI は動き出した
54. 55. 時流 - AI Winter is well on its way
• 米の AI 研究者の Filip Piekniewski 氏が,自身の
Blog で「AI 冬の時代がやってくる」と主張
https://blog.piekniewski.info/2018/05/28/ai-winter-is-well-on-its-way/
56. 時流 - AI Winter is well on its way
① Deep Learning の研究者たちの (ネット上での)
発言が少なくなった
② Deep Learning はスケールしていない
③ 自動走行技術は,まだまだ不完全
• 2012 年に AlexNet という DL のモデルが
世界中の AI 研究者に衝撃を与えた
• AlexNet のパラメータ数は 6000 万程度
• 最近のモデルのパラメータ数は AlexNet の 1000 倍以上
• 性能が 1000 倍以下
• 一部の研究者が主張するほど,DL が
指数関数的な進化を遂げていない
57. 時流 - Thomas Nield の主張
• AI の歴史
• 推論や検索に基づいた第 1 次 AI ブーム
• エキスパートシステムの開発が流行した第 2 次 AI ブーム
• これらのブームが終息した原因
• AI に対する過度な期待とその期待に便乗した AI の誇張
• AI で実現可能なことを実際より大きく見せることで期待を煽るが,
その期待に応えられない度にブームが終息
• 現在の AI ブームに煽動と誇張を見る同氏は,
この流行は2019年から2020年にかけて終息すると主張.
• ディープラーニングの流行がもたらした第 3 次 AI ブーム
• ディープラーニングの進化を加速するはずの学習データが
不足していること,さらにはディープラーニングをもってしても
計算複雑性理論から見て解決困難な問題は依然として解決が難しい
• AI を正しく活用するためにはディープラーニングの効用を妄信せず,
個々の問題にあった AI 技法を適用する
Thomas Nield
アメリカ大手航空会社サウスウエスト航空のビジネスコンサルタントを務めているとともに,
SQL や RxJava に関する入門書をオライリーから出版.
同氏が長文英文記事メディア Medium に投稿した記事の要約.
58. 時流 - 敵対的生成ネットワーク
• 2018 年頃は,AI バブルの様相を呈していた.
• 機械学習と呼んでいたものが,AI と名称変更する
だけで新規性に富んだテーマとして扱われる.
• AI を実現できるソフトウェアが開発され,
モデルの構築が簡便に実現可能な
プラットフォームが完成.
⇒ AI は安定期 (一般化) に突入.
• 敵対的生成ネットワーク (Generative adversarial
networks: GANs) を用いた研究が盛んになり,
新たな時流が生じた.
59. 時流 - 敵対的生成ネットワーク
• 2014 年にイアン・グッドフェローらによって
発表された教師なし学習で使用される人工知能
アルゴリズムの一種
• ゼロサムゲームフレームワークで
互いに競合する2つのニューラルネットワークの
システムによって実装
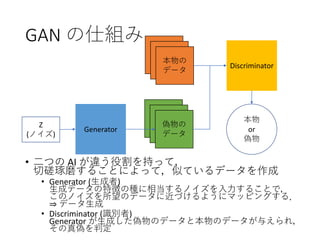
60. GAN の仕組み
• 二つの AI が違う役割を持って,
切磋琢磨することによって,似ているデータを作成
• Generator (生成者)
生成データの特徴の種に相当するノイズを入力することで,
このノイズを所望のデータに近づけるようにマッピングする.
⇒ データ生成
• Discriminator (識別者)
Generator が生成した偽物のデータと本物のデータが与えられ,
その真偽を判定
Z
(ノイズ)
Generator
Discriminator
本物
or
偽物
本物の
データ
本物の
データ
本物の
データ
偽物の
データ
偽物の
データ
偽物の
データ
61. 62. 63. 実際には存在しない顔写真
PHOTOGRAPHS BY CARL BERGSTROM AND JEVIN WEST/UNIVERSITY OF WASHINGTON;
PHILIP WANG/THISPERSONDOESNOTEXIST.COM
このアルゴリズムには,顔を入れ替えた偽の動画 (Deep Fake) と同等のコードを含む
64. 65. 66. 学習データを作成 (GAN)
• AI 技術を産業に応用する際の課題
• AI が学習するための教師データの不足
• CT や MRI から AI が病気を Detection しようにも
病気の画像が少なければ充分な学習ができず
システムの精度が上がりにくい
• 教師データの回転や移動によるデータ量の
水増しではなく GAN で学習データを生成
• 偏りやドメインシフトの影響が大きくなる
• GAN をドメイン適応用に開発することで
大規模データ間の違いを修正し,
さらに大きなデータベースを開発できる可能性がある?
67. AI は人間の医師よりも優秀?
• 2012 年以降の深層学習に関わる研究論文を調査
• AI による自動診断に関する研究論文は 2 万件以上存在
• 質の高いデータを AI に分析させたものと同じ画像を専門医にも
見せて比較している研究に絞って調べると 14 件該当
• 14 件の研究の中から病気を正確に診断した精度を算出すると,
医者が 86 %,AI は 87 %という精度
⇒ AI の医療への応用を研究した論文は内容が不十分
⇒ AI が人間を超えたと言うが実際には同等程度
Xiaoxuan Liu MBChB, Livia Faes MD, Aditya U Kale MBChB, et al.
A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging:
a systematic review and meta-analysis Lancet Digital Health 2019/09/25
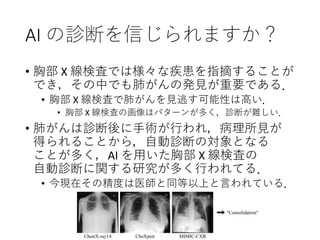
68. AI の診断を信じられますか?
• 胸部 X 線検査では様々な疾患を指摘することが
でき,その中でも肺がんの発見が重要である.
• 胸部 X 線検査で肺がんを見逃す可能性は高い.
• 胸部 X 線検査の画像はパターンが多く,診断が難しい.
• 肺がんは診断後に手術が行われ,病理所見が
得られることから,自動診断の対象となる
ことが多く,AI を用いた胸部 X 線検査の
自動診断に関する研究が多く行われてる.
• 今現在その精度は医師と同等以上と言われている.
69. AI の診断を信じられますか?
• AI の基本的な問題点
• AI のモデルを構築した学習データの違いによって
性能に違いが出るドメインシフト
• 同じ問題を解くために集めたはずのデータの分布領域
(ドメイン) にズレが生じていることで精度に影響が出る.
• 自分で集めたデータでは学習とテストが共にうまくが,
同じ問題用に集めた隣人のデータではうまくいかない現象.
• 汎化性能が高ければデータセットを変更しても
精度に影響が出ないはずだが,悪くなる現象.
• 大規模データベース 3 種類を同じモデル・環境で
学習させ,それぞれを別のデータベースで評価し
データセットの影響を評価
Eduardo H. P. Pooch∗, Pedro L. Ballester, Rodrigo C. Barros
Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification
arXiv:1909.01940v1 [eess.IV] 3 Sep 2019
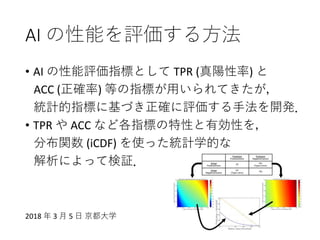
70. AI の性能を評価する方法
• AI の性能評価指標として TPR (真陽性率) と
ACC (正確率) 等の指標が用いられてきたが,
統計的指標に基づき正確に評価する手法を開発.
• TPR や ACC など各指標の特性と有効性を,
分布関数 (iCDF) を使った統計学的な
解析によって検証.
2018 年 3 月 5 日 京都大学
71. 機械学習エンジニア
• どのような課題でも深層学習で解決できると思ってる
勘違いをしている人は多い
• 深層学習で end-to-end に解ける問題は多くない
• 機械学習を使わずに解ける課題なら機械学習は使わない方がいい
• 良識のあるエンジニアを雇うと,機械学習を使うはずだった
プロジェクトに「機械学習は必要ない」となる
• テクノロジーに夢を見ていない老害
• 機械学習と深層学習が流行りすぎて「画像処理 = 深層学習」
• 方法が目的になっている傾向がある
• AI エンジニアは,
学習データやアルゴリズムの用意 (お膳立て) をして,
気持ちよく学習して頂くために働く召使い.
72. Web Application
• Googleは,Web ブラウザで
リアルタイムに人間の姿勢推定を
可能にする機械学習モデル「PoseNet」の
TensorFlow.js バーションをリリース
• PoseNet
• 映像中の人物から 1 つまたは複数のポーズを検出
• ToseorFlow.js
• Web ブラウザで実行できる
オープンソースの機械学習ライブラリ
• Google がオープンソースとして公開している
機械学習ライブラリ「TensorFlow」の JavaScript 版
• 実行環境は何でも良い!
73. 開発環境
• Ubuntu (Linux)
• GPU 付きの PC で,
本格的に Deep Learning を学び実践したい人向け
• Windows
• 使い慣れた環境を使いたい人にとって最良
• GPU が使え,TensorFlow や PyTorch なども使える
• Visual Studio で開発したい人には人気
• macOS (Mac)
• CPU を使って Deep Learning を試したい人向け
• 環境構築が必要!
74. 市販品
• 開発環境が事前に組み込まれているコンピュータ
• Deep Infinity (パソコン工房)
• DeepEye
• 高価だが,環境構築を行わなくて良い
⇒ 研究に集中できる
• DL 用 Framework を Download するだけで,
環境設定や整合性を気にすることなく
環境構築ができ,導入時間を大幅に短縮可能!
• 環境構築が不要!
75. AI と Python の親和性
• 2015 年以降,AI ブームにより
Python 関連書籍の売れ行きが好調
• AI 人気が Python 人気に直結しているのは,
AI システムを開発するプログラミング言語として
Python が最も使いやすい
• 今日のシステム開発においてはプログラムは
ゼロから書くのではなく,プログラムの共通部品を
集めた Library や特定用途向けの開発基盤である
Framework を活用して工数を抑えるのが一般的
• AI 分野の Library や Framework の充実度合いで,
Python は他のプログラミング言語を圧倒
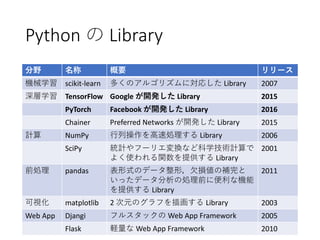
76. 77. Python の Library
分野 名称 概要 リリース
機械学習 scikit-learn 多くのアルゴリズムに対応した Library 2007
深層学習 TensorFlow Google が開発した Library 2015
PyTorch Facebook が開発した Library 2016
Chainer Preferred Networks が開発した Library 2015
計算 NumPy 行列操作を高速処理する Library 2006
SciPy 統計やフーリエ変換など科学技術計算で
よく使われる関数を提供する Library
2001
前処理 pandas 表形式のデータ整形,欠損値の補完と
いったデータ分析の処理前に便利な機能
を提供する Library
2011
可視化 matplotlib 2 次元のグラフを描画する Library 2003
Web App Djangi フルスタックの Web App Framework 2005
Flask 軽量な Web App Framework 2010
78. AI の勘違い (都市伝説)
• AI は人間の脳のように機能する
• 現在の AI は “弱い AI” ⇒ 決められた単一タスクのみ処理可能
• インテリジェントマシンは自ら学習する
• 学習には “問題の設定”と“適切なデータセットの提供” が必要
• AI は 100 % 客観的になれる
• AI は全てエンジニアによるデータとルールに基づいている
• データセットと結果を評価し,潜在的な偏見が生じず
次の学習サイクルに新しい知識と統合できるようする必要がある
• AI は定型業務を代替し得る
• AI の予測・分類・クラスタ化により的確な判断が可能
• 医療: 放射線科医よりも迅速に病気を発見
• 金融・保険業界: ロボアドバイザが資産管理や詐欺検出に利用
• FAX すらなくならない日本では,
定型業務の全てが AI に置き換わることはない
79. 近年の AI ブーム
• 誰もが AI を求めている?
• “AI” ではなく,“AI っぽい何か” を求めている
• “休憩するためにカフェに行く” のではなく,
“インスタ映えのためにカフェに行く”
• 前提が違うと話しが噛み合わない.
インスタ映えを目的に撮影していないので映えた写真ではない!
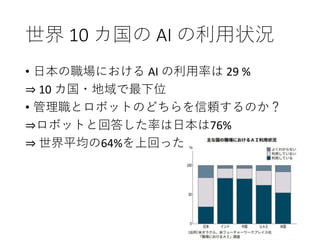
80. 世界 10 カ国の AI の利用状況
• 日本の職場における AI の利用率は 29 %
⇒ 10 カ国・地域で最下位
• 管理職とロボットのどちらを信頼するのか?
⇒ロボットと回答した率は日本は76%
⇒ 世界平均の64%を上回った
81. AI の課題
0 5 10 15 20 25 30 35 40 45
十分な量・質を備えたデータの取得
AI の精度が不十分
AI 活用リスクが大きい
メンテナンスコストが高い
AI 導入の目的が不明確
ベンダーとのコミュニケーションが困難
ベンダーの自社が属する業界への知識不足
従来の手法で ROI や評価基準が設定できず…
契約条件が不適当
AI 人材・知識不足
経営層の納得が得にくい
現場の納得が得にくい
適切なベンダー選定が困難
課題が不明瞭
その他
フェーズごとの課題
企画・立案段階 (n=381) 企画・立案終了~概念実証完了まで (n=381) 概念実証終了~実用化済み (n=381)
• 課題が不明瞭
• AI 導入の目的が不明瞭
• 十分な量・質を備えたデータが取得できていない
• AI の精度が不十分
• データの取得と課題の選出が問題.
• 特に医用データは医療関係者の介在が
なければ公開データ以外取得不可能.
引用:「平成30年度成果報告書 産業分野における人工知能及びその内の機械学習の活用状況及び人工知能技術の安全性に関する調査」
82. 機械学習エンジニアの不足
• 経済産業省は機械学習に関わる人材が
2020 年には 4.8 万人不足すると予測
• 2019 年 3 月に政府の AI 戦略が
年間 25 万人を目標に AI 人材を育成
• 教育再生会議が全ての大学生が
AI などの基礎的な素養を身につけられるように
標準カリキュラムを作成することを提言
• 高校教育
• AI などを理解するうえで必要な
「確率」「統計」「行列」などを確実に学ぶ
• 技術の発展に応じて教育内容を迅速に変えるため,
学習指導要領の一部改訂や教科書の一部訂正といった制度を活用
• 大学教育
• 産業界と協力しながら AI や数理,データサイエンスの分野で
求められる知識や技能を特定し,それを身につけられる
教育プログラムを国が認定する制度の創設
• 履修状況を採用活動やインターンシップなどに活用することを想定
83. AutoML
• 2017 年頃から AutoML が注目を集め出した
• ニューラルネットワークが
ニューラルネットワークを作り上げる
• 2018 年初頭,
Google が画像分類の Cloud AutoML をアルファ版公開
• Cloud AutoML は機械学習の専門家でなくても
高品質な画像分類モデルを生成できるというもの
⇒ Neural Architecture Search (NAS) の理論が背景にある
• NAS が従来のニューラルネットワーク設計との違い
⇒ NAS はニューラルネットワークのアーキテクチャ自体を最適化
84. 85. AI のコーディングについて
• 今や Tensorflow や Keras で
簡単に ML のコーディングが可能
⇒ "MatrixFlow" や "Prediction One" など,
誰でも簡単に AutoML で AI モデルを構築出来る
⇒ 誰でも AI を 1 から作れる時代
• 既存の AI サービスを
うまくビジネスに落とし込むかが重要な時代にシフト
• “機械学習の基礎を理解” した上で AI を使いこな
し,
“必要な時にはツールで対応しきれない部分を
自ら作成して補い,それぞれの課題に対応
出来るような人材の育成が重要と考える.
86. 医療系 DL,AI をしたい方へ
• Neural Network Console (ソニー株式会社)
• Azure Machine Learning Studio (Microsoft)
• MatrixFlow (株式会社 MatrixFlow)
• Cloud AutoML (Google)
• Coding の必要がなく GUI でモデルの構築が可能.
• 環境構築が不要または簡単に完了.
• Coding についての学習を省くことができるので,
DL の基礎となる数学や統計を学べる.
• 医用画像に対する AI の運用は,教師データの作成に
医用情報が必要となるため,Medical が介入する必要があ
る.
• 特に Classification,Detection,Segmentation
• データクリーニングに多くの時間を費やす必要がある.
• 研究 < 臨床 となっており,目新しさよりも安定を求める傾向.
• 医療系 AI を医療人が行うことに一定の需要はある.
87. Editor's Notes #31 パーセプトロンを複数接続したもの.
個々のパーセプトロンでは,人間の神経細胞と同様に,入力された値をもとに情報の修飾 (数学的な計算) を行い,他のパーセプトロンに伝達することが行われている.
この情報の修飾により,入力された情報の「特徴」が認識される.
旧来は,コンピュータの能力に限界があり,ニューラルネットワークの層を増やすことができなかった.
そのため,パーセプトロン同士の接続が (人間の神経回路に比べて) 単純であり,特徴を十分に学習させることができない問題があった. #32 パーセプトロンを複数接続したもの.
個々のパーセプトロンでは,人間の神経細胞と同様に,入力された値をもとに情報の修飾 (数学的な計算) を行い,他のパーセプトロンに伝達することが行われている.
この情報の修飾により,入力された情報の「特徴」が認識される.
旧来は,コンピュータの能力に限界があり,ニューラルネットワークの層を増やすことができなかった.
そのため,パーセプトロン同士の接続が (人間の神経回路に比べて) 単純であり,特徴を十分に学習させることができない問題があった. #35 近年のコンピューターの著しい能力向上,そして情報修飾 (数学的な計算) 方法のブレークスルーなどがあり,ニューラルネットワークの層を増やしたモデルの構築が可能となった.
ディープニューラルネットワークでは,より人間の神経回路に近いパーセプトロンの接続を行うことができる.これにより入力された情報から,より多くの特徴を認識できるようになり,機械学習の精度が飛躍的に向上した.
#48 複数のCT画像から作った3DモデルをAIで解析 #64 これらの顔は, NVIDIA の研究者らが 2018 年に開発した技術を利用して生み出された.
1 週間にわたる膨大な顔写真のデータセットを用いた訓練を経て,ニューラルネットワークは視覚的なパターンを模倣し,本物そっくりでありながら実在しない人たちの画像を出力できるようになった.




























![標準ディジタル画像
データベース[胸部腫瘤陰影像]
• JSRT が公開している “標準ディジタル画像
データベース[胸部腫瘤陰影像]” が必須
http://imgcom.jsrt.or.jp/download/
http://imgcom.jsrt.or.jp/minijsrtdb/](https://image.slidesharecdn.com/machinelearning-191209215037/85/slide-49-320.jpg)

















![AI の診断を信じられますか?
• AI の基本的な問題点
• AI のモデルを構築した学習データの違いによって
性能に違いが出るドメインシフト
• 同じ問題を解くために集めたはずのデータの分布領域
(ドメイン) にズレが生じていることで精度に影響が出る.
• 自分で集めたデータでは学習とテストが共にうまくが,
同じ問題用に集めた隣人のデータではうまくいかない現象.
• 汎化性能が高ければデータセットを変更しても
精度に影響が出ないはずだが,悪くなる現象.
• 大規模データベース 3 種類を同じモデル・環境で
学習させ,それぞれを別のデータベースで評価し
データセットの影響を評価
Eduardo H. P. Pooch∗, Pedro L. Ballester, Rodrigo C. Barros
Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification
arXiv:1909.01940v1 [eess.IV] 3 Sep 2019](https://image.slidesharecdn.com/machinelearning-191209215037/85/slide-69-320.jpg)
















![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)







![[ビッグデータオールスターズ] クラウドサービス最新情報 機械学習/AIでこんなことまでできるんです! (Microsoft編)](https://cdn.slidesharecdn.com/ss_thumbnails/20161218dotsbigdataazureai-161218054508-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Developers Summit 2017] MicrosoftのAI開発機能/サービス](https://cdn.slidesharecdn.com/ss_thumbnails/20170216devsumiai-170302021003-thumbnail.jpg?width=640&height=640&fit=bounds)











