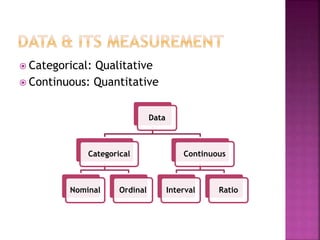
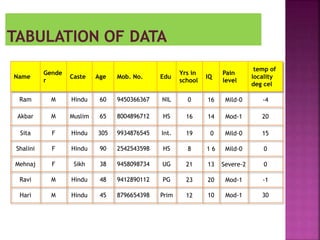
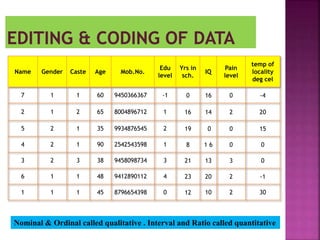
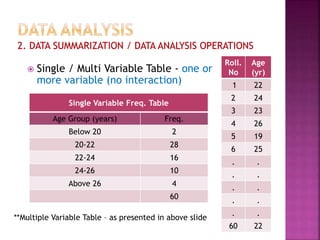
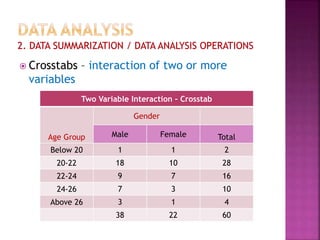
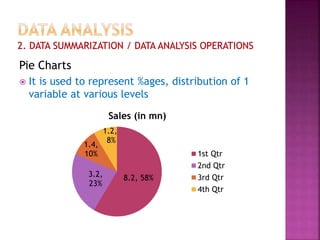
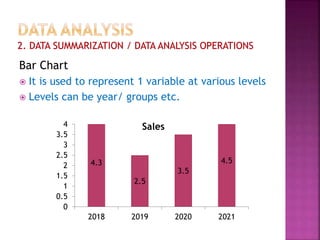
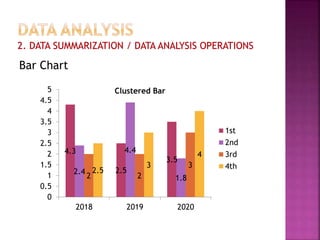
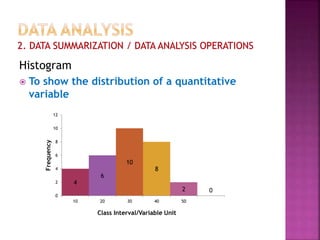
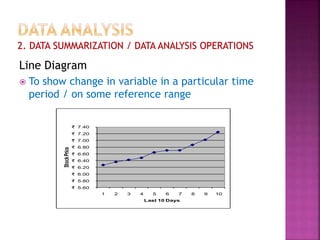
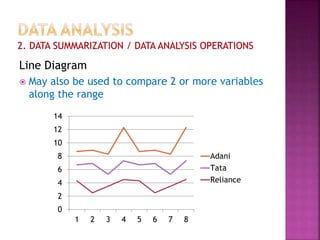
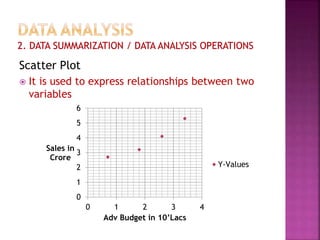
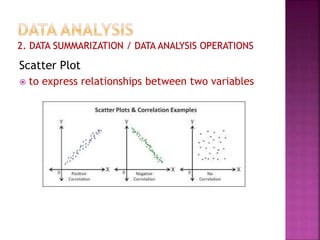
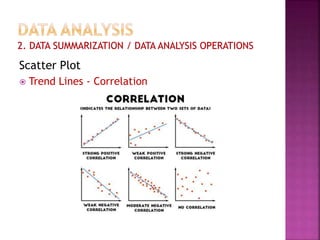
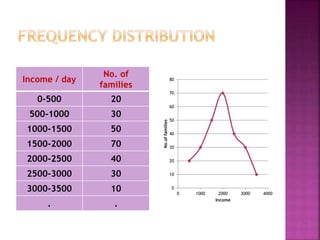
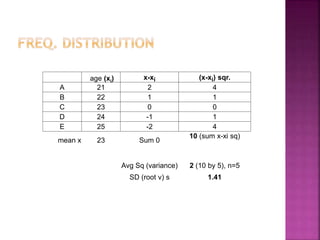
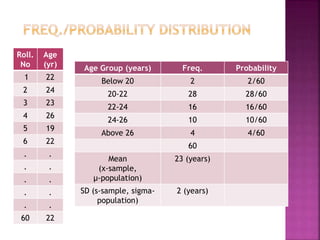
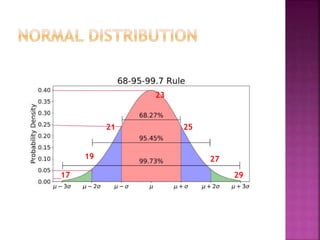
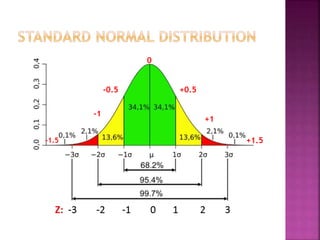
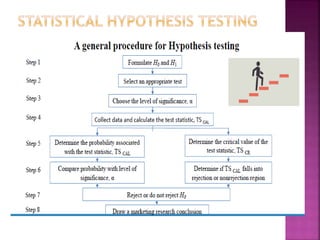
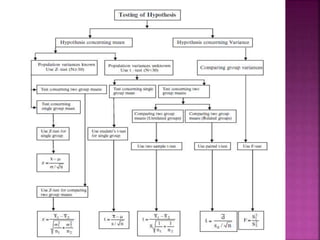
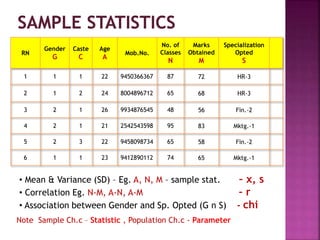
This document provides an overview of key concepts in data analysis and statistics. It defines different types of data (categorical, continuous) and variables (nominal, ordinal, interval, ratio). It then covers various steps in data analysis including data preparation, summarization, and descriptive and inferential statistical methods. Graphical representations like pie charts, bar graphs, histograms and scatter plots are also discussed. Hypothesis testing concepts like null/alternative hypotheses, p-values, and choosing test statistics based on data type are summarized.