The document discusses splay trees, a type of self-adjusting binary search tree invented by Daniel Sleator and Robert Tarjan in 1985. Splay trees perform efficiently by moving recently accessed nodes closer to the root, balancing the tree and optimizing access times, though they can have a worst-case height of O(n). They are advantageous for use in caching and garbage collection but can present challenges in multi-threaded environments due to their dynamic structure.



![The splay tree was invented by Daniel
Sleator and Robert Tarjan in 1985.[1]
A splay tree is a self-adjusting binary search tree with the
additional property that recently accessed elements are
quick to access again. ., splay trees perform better than
other search trees, even when the specific pattern of the
sequence is unknown
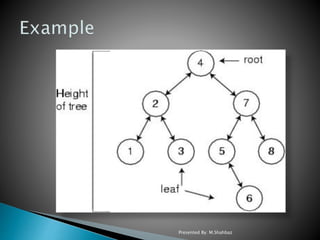
All normal operations on a binary search tree are combined
with one basic operation, called splaying.
oSplaying the tree for a certain element rearranges the
tree so that the element is placed at the root of the tree.
Presented By: M.Shahbaz](https://image.slidesharecdn.com/splaytreepresentation-180426154245/85/Splay-Tree-Presentation-Slides-3-320.jpg)