Downloaded 63 times




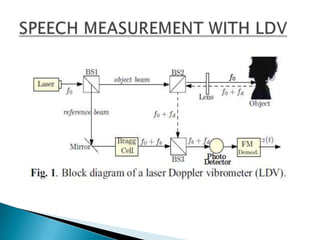
![ fd(t) = 2ν(t) cos(α)/λ
ν(t)=> instantaneous throat-vibrational
velocity
α => Angle between the object beam and the
velocity vector
λ =>laser wavelength.
LDV-output signal after an FM-demodulator
is
Z(t) = fb + [2Av cos(α)/λ].cos(2πfvt). (1)](https://image.slidesharecdn.com/speechmeasurementusinglaserdopplervibrometer-120330124203-phpapp01/85/Speech-measurement-using-laser-doppler-vibrometer-5-320.jpg)


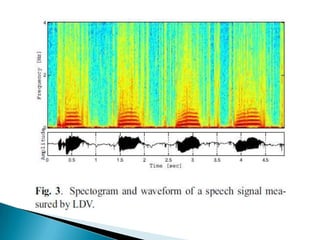





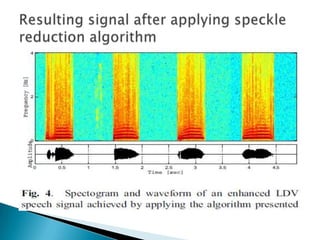

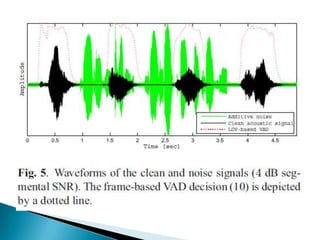

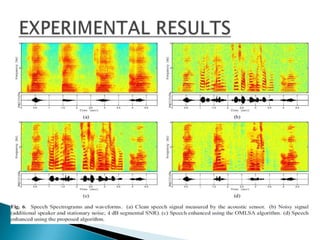





This document discusses using a laser Doppler vibrometer (LDV) sensor to remotely measure speech for speech enhancement in noisy environments. It presents a speech enhancement algorithm that uses the LDV measurements along with acoustic sensor measurements. The algorithm includes speckle noise suppression of the LDV signal, an LDV-based time-frequency voice activity detection, and spectral gain modification. Experimental results demonstrate the effectiveness of the proposed approach in suppressing highly non-stationary noise components.

















































































