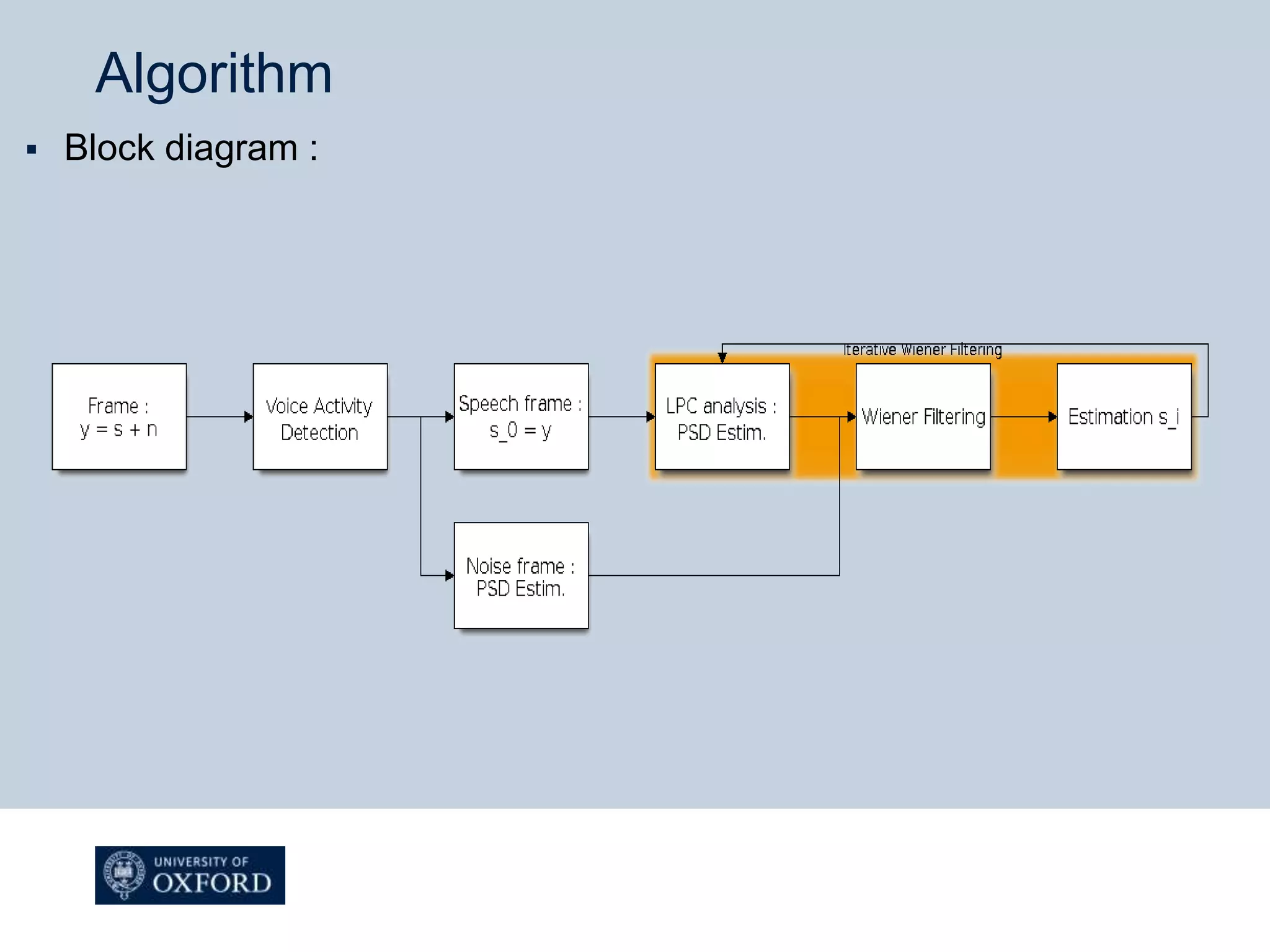
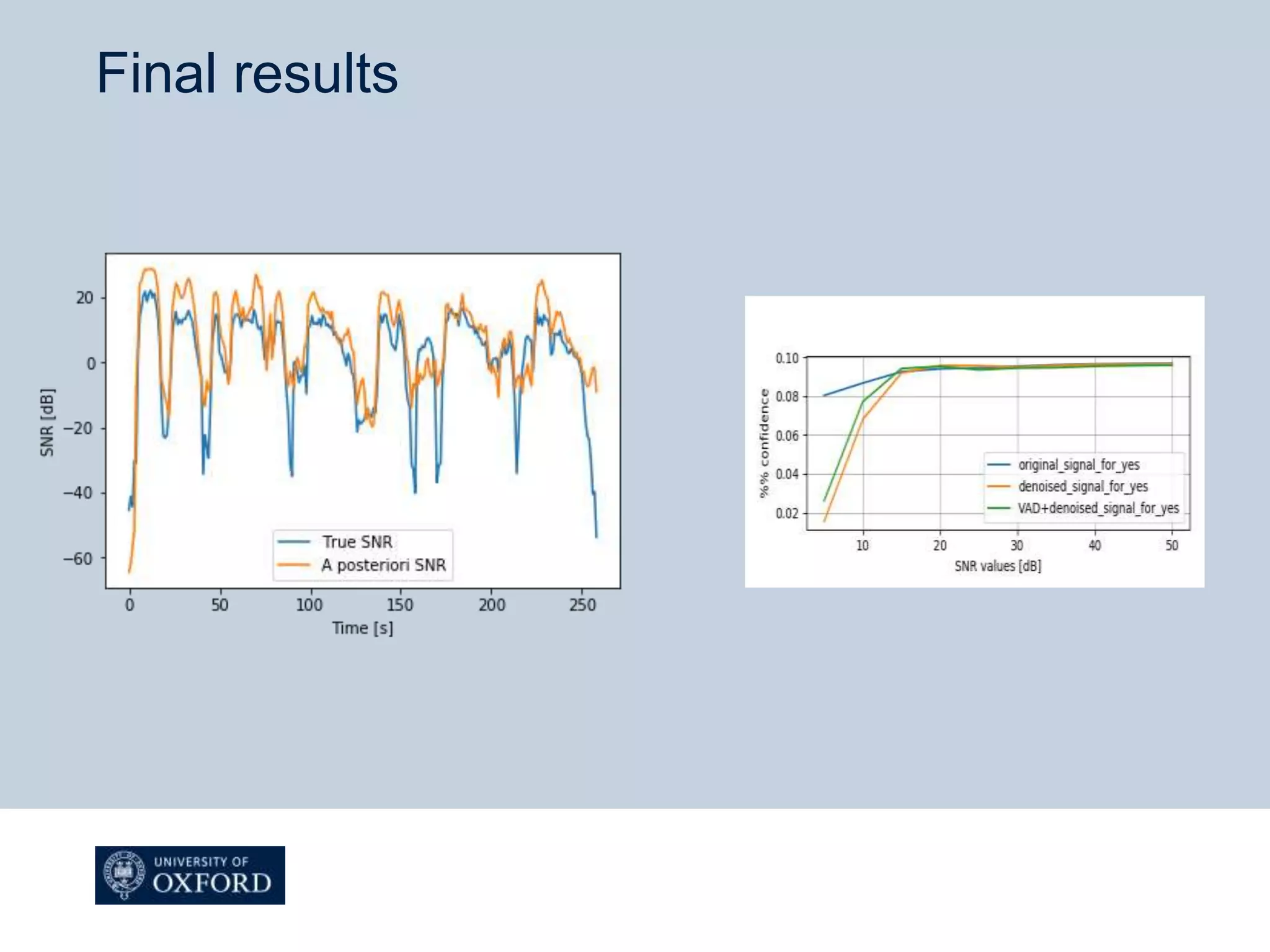
The document describes a Wiener filtering algorithm for noise suppression in speech signals. It involves estimating the noise and speech power spectral densities (PSDs) using a noise model and all-pole modeling of speech respectively. An iterative Wiener filter is then constructed using the PSD estimates. The algorithm is improved by adding a voice activity detector to estimate noise PSD only from non-speech frames. Evaluation shows the denoised speech has higher intelligibility and a posteriori SNR compared to noisy speech.