Sparse PCA
-sparse PCAとは
が入力行列( 次元ベクトルが 個)として与えられたとき:
ただし、 (共分散行列)
ここで ノルムは で定義される
はベクトル列の 方向への射影と見ることができるので、射影のノルムの二乗和
の最大化と見ることができる。( )
s
S n × d d n
= Axx∗ argmax∥x =1,∥x =s∥
2
∥
0
x
T
A = S
1
n
S
T
L0 ∥x := #{ | ≠ 0}∥
0
xi xi
Sx x
Ax = ∥Sxx
T 1
n
∥
2
2
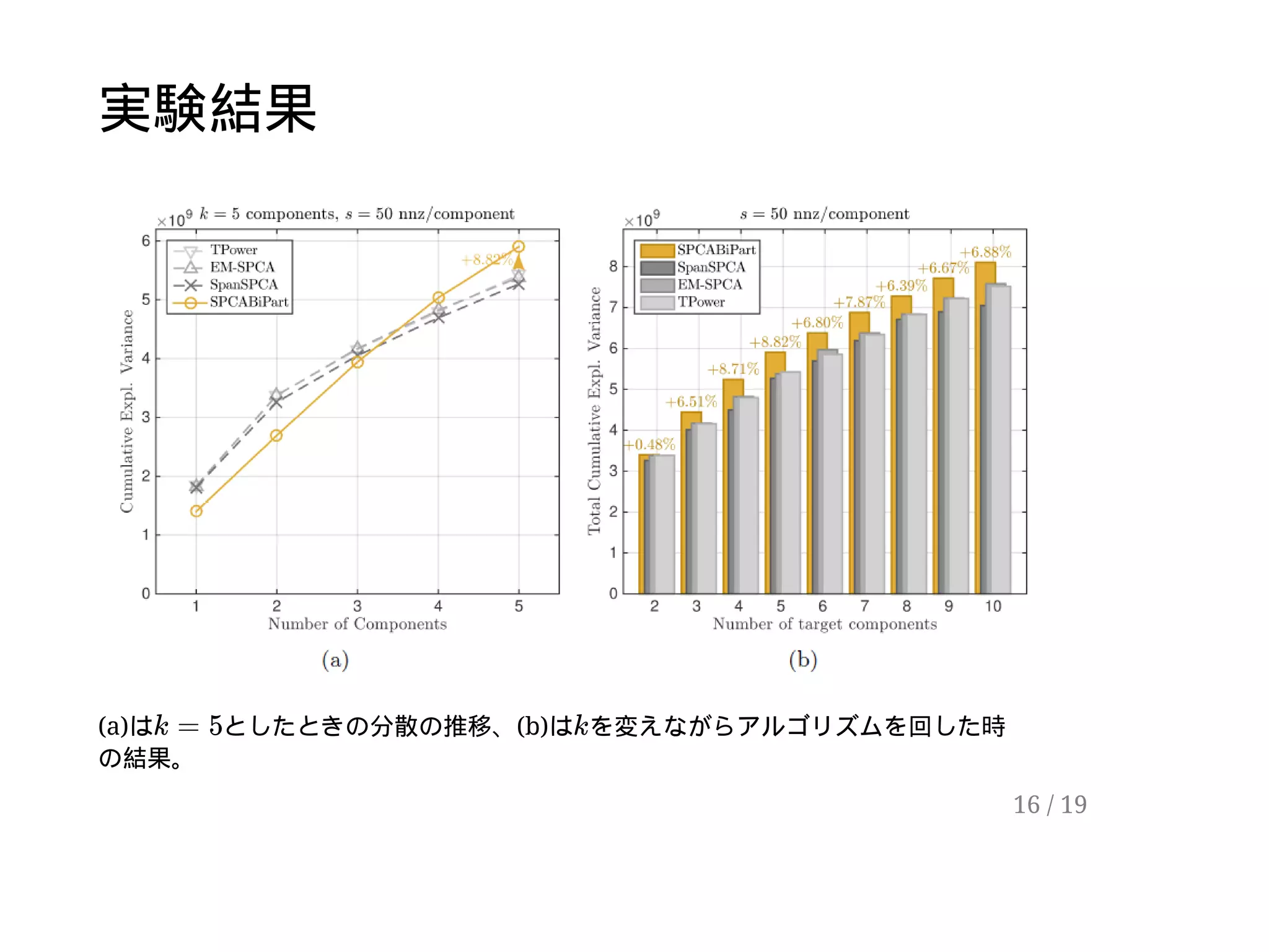
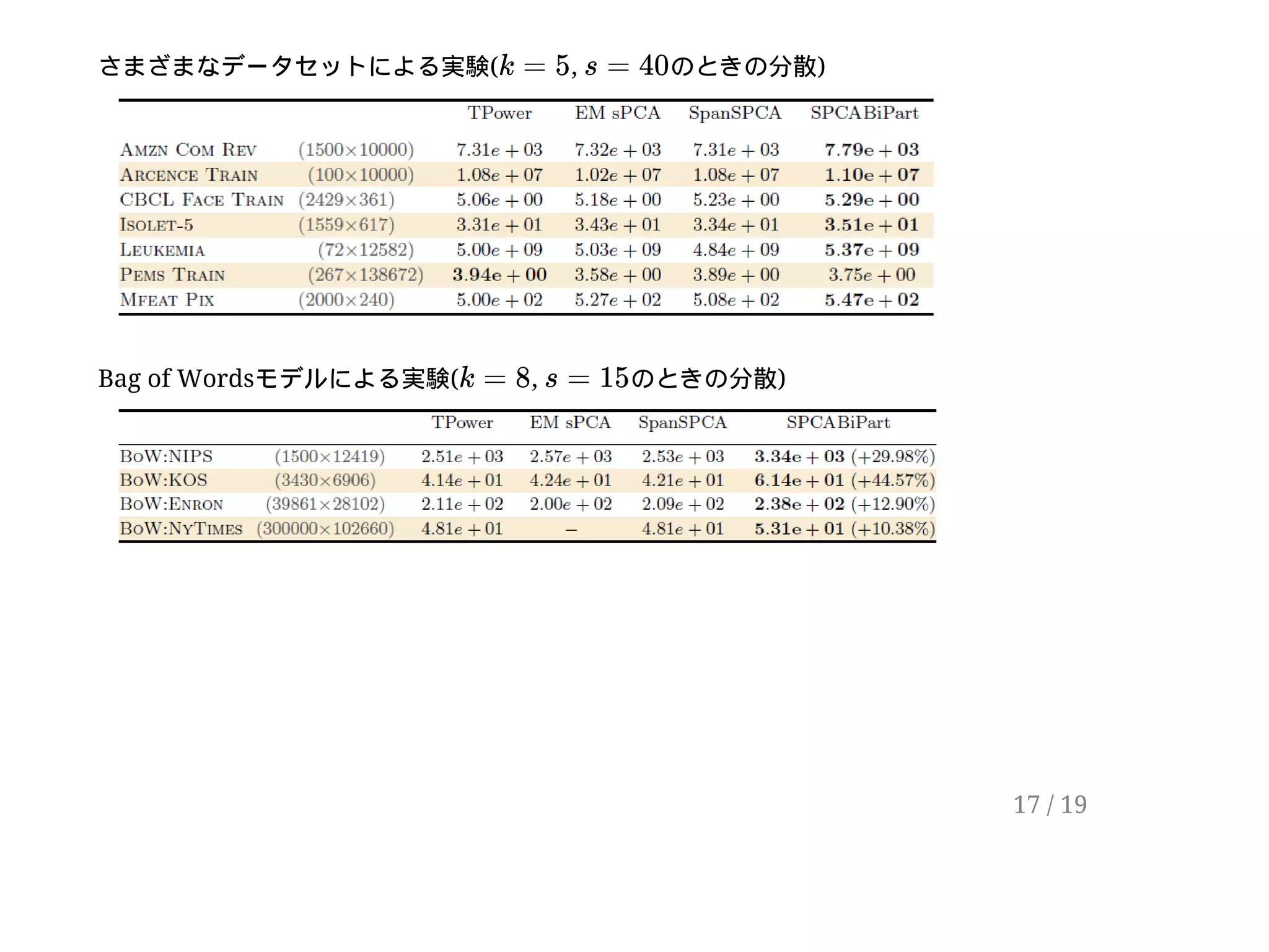
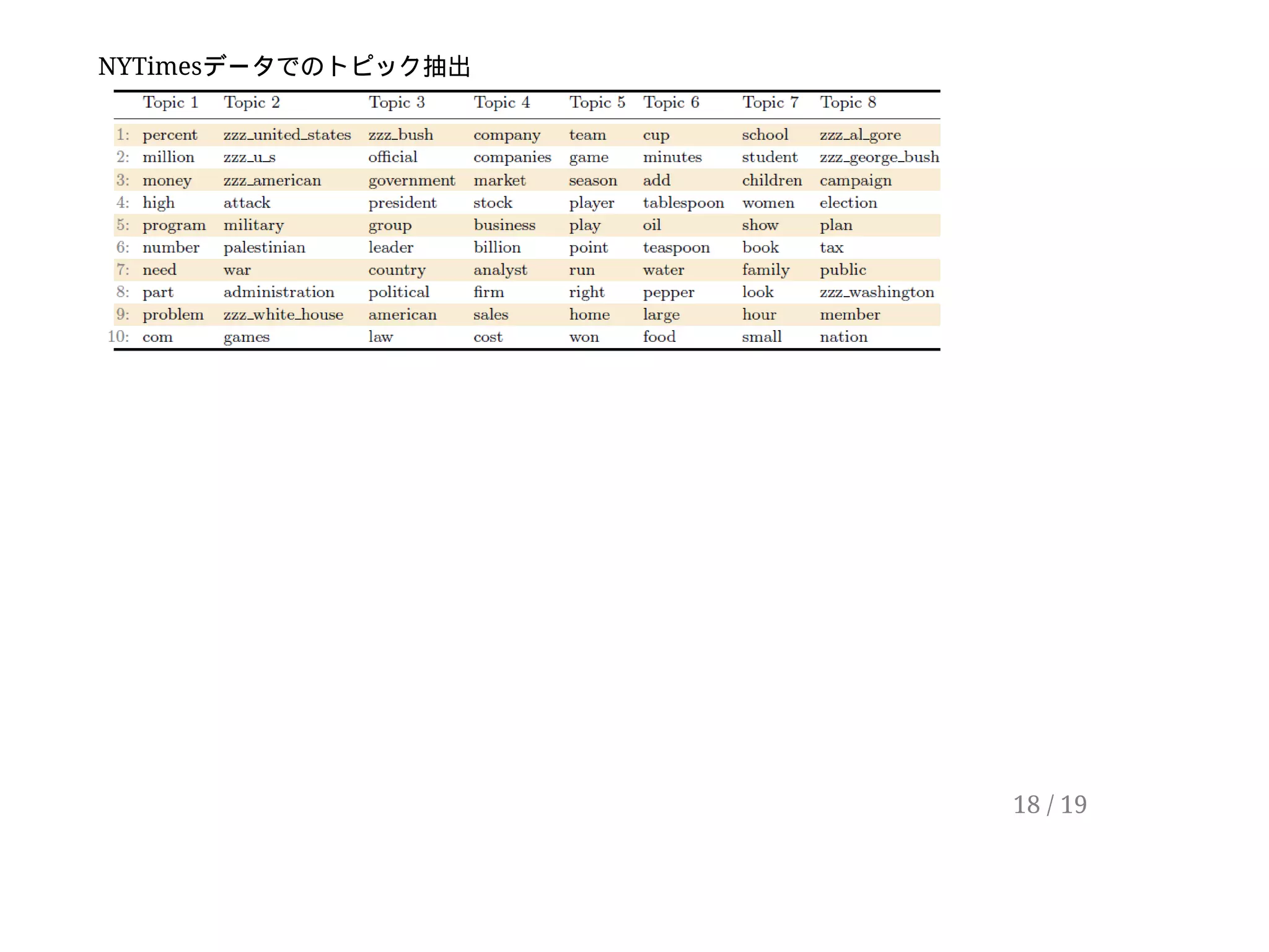
6 / 19
7.
Multi-component Sparse PCA
component-sparse PCAとは次で定義される:
ただし
k s
= Tr( AX)X∗ argmaxX∈Xk
X
T
:=Xk {X|X ∈ Mat(R; d, k), ∥ = 1, ∥ = s,X
j
∥
2
X
j
∥
0
Supp ∩ Supp = ∅, i, j ∈ {1, … , k}, i ≠ j}X
i
X
j
7 / 19
と固有値分解できるとき
(Cauchy-Schwartzの不等式)
しがって
ただし、 は のランク。
したがって
ただしは 次元曲面( ノルムの意味で)を表す。
A = U ΛU
T
Ax = (x, U c)x
T
max
c∈S
1
2
Λ
1/2
Tr( AX) = A = (X, UX
T
∑
j=1
k
X
jT
X
j
∑
j=1
k
max
∈C
j
S
r−1
2
Λ
1/2
C
j
)
2
r A
Tr( AX) = (X, Umax
X∈Xk
X
T
max
X∈Xk
max
∈C
j
S
r−1
2
∑
j=1
k
Λ
1/2
C
j
)
2
S
l
2
l L2
10 / 19
11.
アイデア
新たな変数 を導入
次元球面 をを網目状に分割して均等にを選び各 に対する最適化
を行う。いくつかの から最適なものを選ぶ
が小さければ の探索空間は十分に小さいので効率よい計算ができるはず
C
r − 1 S
r−1
2
C C
C
r C
11 / 19
12.
アルゴリズム
ここで は、 上の-net(曲面上の点列で、すべての要素の 近
傍内に他の要素があるようなもの)である。netの作り方は[Matoušek 2002]参照。
近似比:
計算量: で計算できる(論文中に証明あり)。
では、このargmaxの計算をどうするか?
( )Nϵ/2
S
r−1
2
S
r−1
2
ϵ/2 ϵ/2
Tr( A ) ≥ (1 − ϵ)Tr( A )X
^
T
X
^
X
T
∗
X∗
(r) + O(( ⋅ d(sk )TSVD
d
ϵ
)
rk
)
2
12 / 19
13.
argmaxの計算
であった。この解 を求めたい。 とおく。
ここでと定義すると(この はあらかじめわかるものではないので
注意)
(Cauchy-Schwartzの不等式)
を固定するとこの等式を満たす は確かに存在するので、最適な を求める
問題に帰着される。
Tr( AX) = ( , Umax
X∈Xk
X
T
max
X∈Xk
max
∈C
j
S
r−1
2
∑
j=1
k
X
j
Λ
1/2
C
j
)
2
X
^
U =Λ
1/2
C
j
W
j
:= SuppIj
X
^
j
Ij
( , ) = ( , ) ≤∑
j=1
k
X
^
j
W
j
∑
j=1
k
∑
i∈Ij
X
^
ij Wij ∑
j=1
k
∑
i∈Ij
Wij
Ij X
^
{ }Ij
13 / 19
14.
, という性質があった。したがって
は二部グラフ の重み付き完全マッチングと見ることができる。
ただし、, , ,
ここで を仮定していて、その場合の重み付き完全マッチングとは、 の
頂点をすべて尽くし、端点を共有しないような辺の集合で重みの和を最大にするも
の。
「 と の間の辺が採用される」ことは、「 に が含まれる」ことを意味する。
計算量は [Ramshaw and Tarjan 2012]
# = sIj ∩ = ∅Ii Ij
max
{ }Ij
∑
j=1
k
∑
i∈Ij
Wij
(U , V , E)
U = ∪
k
l=1
Ul | | = sUl V = { , , … , }v1 v2 vd E = U × V
|U | < |V | U
Uj vi Ij i
O(|E||U | + |U log |U |)|
2
14 / 19

![[論文解説]
Sparse PCA via Bipartite Matching
2016/1/20 @ ドワンゴセミナールーム
NIPS2015 論文読み会
加藤公一
1 / 19](https://image.slidesharecdn.com/sparsepcaviabipartitematching-160120065739/75/Sparse-pca-via-bipartite-matching-1-2048.jpg)










![アルゴリズム
ここで は、 上の -net(曲面上の点列で、すべての要素の 近
傍内に他の要素があるようなもの)である。netの作り方は[Matoušek 2002]参照。
近似比:
計算量: で計算できる(論文中に証明あり)。
では、このargmaxの計算をどうするか?
( )Nϵ/2
S
r−1
2
S
r−1
2
ϵ/2 ϵ/2
Tr( A ) ≥ (1 − ϵ)Tr( A )X
^
T
X
^
X
T
∗
X∗
(r) + O(( ⋅ d(sk )TSVD
d
ϵ
)
rk
)
2
12 / 19](https://image.slidesharecdn.com/sparsepcaviabipartitematching-160120065739/75/Sparse-pca-via-bipartite-matching-12-2048.jpg)

![, という性質があった。したがって
は二部グラフ の重み付き完全マッチングと見ることができる。
ただし、 , , ,
ここで を仮定していて、その場合の重み付き完全マッチングとは、 の
頂点をすべて尽くし、端点を共有しないような辺の集合で重みの和を最大にするも
の。
「 と の間の辺が採用される」ことは、「 に が含まれる」ことを意味する。
計算量は [Ramshaw and Tarjan 2012]
# = sIj ∩ = ∅Ii Ij
max
{ }Ij
∑
j=1
k
∑
i∈Ij
Wij
(U , V , E)
U = ∪
k
l=1
Ul | | = sUl V = { , , … , }v1 v2 vd E = U × V
|U | < |V | U
Uj vi Ij i
O(|E||U | + |U log |U |)|
2
14 / 19](https://image.slidesharecdn.com/sparsepcaviabipartitematching-160120065739/75/Sparse-pca-via-bipartite-matching-14-2048.jpg)
![スケッチを使ったアルゴリズム
前述のアルゴリズムでは計算量は のランク の指数になってしまう。そこで、
を低いランクの行列で近似して前述のアルゴリズムを適用する。
これは、 に対し、 とすることで、
となる解を確率 、計算量 で求めることができる。
A r A
ϵ ∈ (0, 1] r = O( log d)ϵ
−2
Tr( A ) ≥ Tr( A ) − s ⋅ ϵX¯
T
(r)
X¯
(r)
X
T
∗
X∗
1 − 1/poly(d) n
O(log(1/ϵ)/ )ϵ
2
15 / 19](https://image.slidesharecdn.com/sparsepcaviabipartitematching-160120065739/75/Sparse-pca-via-bipartite-matching-15-2048.jpg)







![2分木の演習問題[アルゴリズムとデータ構造]](https://cdn.slidesharecdn.com/ss_thumbnails/random-161021131409-thumbnail.jpg?width=640&height=640&fit=bounds)








































