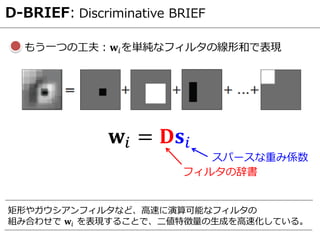
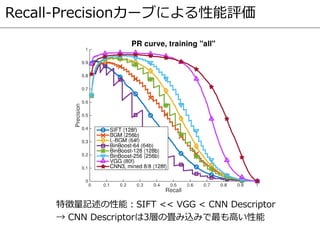
Hard negative andpositive mining
マッチングが困難なペアに対するCNNの更新
順伝播によりhard negative, positiveのペアを求める
hard negativeとhard positiveに対して再度逆伝播
Simo-serra, et al., “Discriminative Learning of Deep Convolutional Feature Point Descriptors”,
ICCV, 2015. ポスターより、図の一部を引用
• Consistent improvements over the state of the art.
• Trained in one dataset, but generalizes very well to scaling, rota-
tion, deformation and illumination changes.
• Computational efficiency (on GPU: 0.76 ms; dense SIFT: 0.14 ms).
Code is available: https:/ / github.com/ etrulls/ deepdesc-release
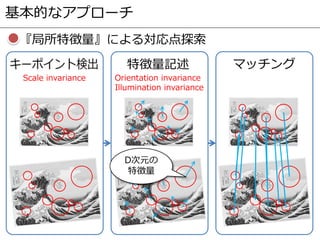
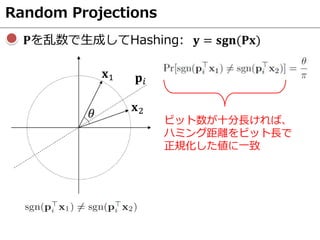
Key observation
1. We train a Siamese architecture with pairs of patches. We want
to bringmatching pairstogether and otherwise pull them apart.
2. Problem? Randomly sampled pairs are already easy to separate.
3. Solution: To train discriminative networks we use hard negative
and positive mining. This proves essential for performance.
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
positives (+, long blue segments) and sim-
ilar negatives (× , short red segments):
(d) Random sampling results in easy pairs.
(e) Mined pairs with harder correspondences.
(d) Random pairs
(e) Mined pairs
This allows us to train discriminative models with a small number
of parameters (∼45k), which also alleviates overfitting concerns.
Stride 2 3 4
Train on the M VS Dataset [1]. 64 × 64 grayscale pat
Statue of Liberty (LY, top), NotreDame (ND, center)
bottom). ∼150k points and ∼450k patches each ⇒ 10
and 1012
negative pairs⇒ Efficient exploration wit
Weminimizethehingeembedding loss. With 3D po
l(x1, x2)=
∥D(x1) − D(x2)∥2,
max(0, C − ∥D(x1) − D(x2)∥2),
This penalizes corresponding pairs that are placed
non-corresponding pairs that are less than C units a
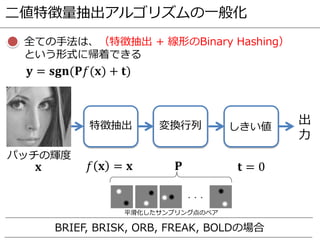
M ethodology: Train over two setsand test over third
with cross-validation. Metric: precision-recall (PR
haystack’ setting: pick 10k unique points and gen
tive pair and 1k negative pairs for each, i.e. 10k po
negatives. Results summarized by ‘Area Under the
Effect of mining
(a) Forward-propagate positives sp ≥ 128 and negat
(b) Pick the 128 with the largest loss (for each) and b
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, training LY+YO, test ND
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
PR curve, training LY+ND, test YO
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
0 0.1 0.2 0.3
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, tr
sp sn PR AUC
128 128 0.366
256 256 0.374
512 512 0.369
1024 1024 0.325
Table 1: (a) No mining.
Larger batches do not help.
sp sn rp rn Cos
128 256 1 2 20%
256 256 2 2 35%
512 512 4 4 48%
1024 1024 8 8 67%
Table 2: (b) Mining with rp =
The mining cost is incurred d
available: https:/ / github.com/ etrulls/ deepdesc-release
bservation
ain a Siamese architecture with pairs of patches. We want
ngmatching pairstogether and otherwisepull them apart.
em? Randomly sampled pairs are already easy to separate.
ion: To train discriminative networks we use hard negative
positive mining. This proves essential for performance.
points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
samples from [1], for illustration. Cor-
ing patchesareshown with samecolor:
bottom). ∼150k points
and 1012
negative pa
Weminimizethehing
l(x1, x2)=
m
This penalizes corres
non-corresponding p
M ethodology: Train o
with cross-validation
haystack’ setting: pic
tive pair and 1k nega
negatives. Results sum
Effect of mining
(a) Forward-propaga
(b) Pick the 128 with
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
(d) Random pairs
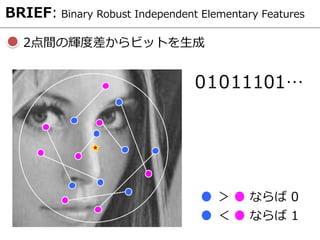
各パッチ画像の特徴量の距離空間
同じ色のパッチ
↓
対応点
赤:negativeペア
青:positiveペア
hard positive
hard negative
hard negativeとhard positiveに適したネットワークに更新
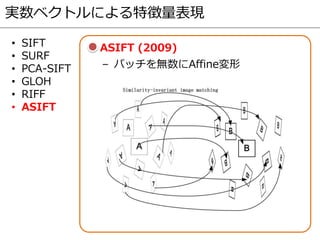
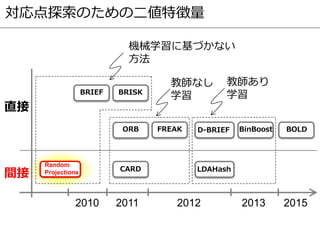
関連文献
— [SIFT]
David G.Lowe, "Distinctive image features from scale-Invariant
keypoints," IJCV2004
— [SURF]
Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool, “Speeded-
up robust features (SURF),” CVIU2008.
— [PCA-SIFT]
Yan Ke and Rahul Sukthankar, “PCA-SIFT: A more distinctive
representation for local image descriptors,” CVPR2004
— [GLOH]
Krystian Mikolajczyk and Cordelia Schmid, “A performance evaluation of
local descriptors,“ TPAMI2005
— [RIFF]
Gabriel Takacs, Vijay Chandrasekhar, Sam Tsai, David Chen, Radek
Grzeszczuk, and Bernd Girod, "Unified real-time tracking and recognition
with rotation-invariant fast features," CVPR2010
— [ASIFT]
Jean-Michel Morel and Guoshen Yu, "ASIFT: A new framework for fully
affine invariant image comparison" SIAM Journal on Imaging Sciences,
Vol. 2, No. 2, pp. 438-469, April 2009.
本資料では、下記に記載の論文から図を一部引用した。
102.
関連文献
— [BRIEF]
M.Calonder, V.Lepetit,and P.Fua, “BRIEF: Binary Robust Independent
Elementary Features,” ECCV2010
— [BRISK]
S.Leutenegger, M.Chli and R.Siegwart, "BRISK: Binary Robust Invariant
Scalable Keypoints,“ ICCV2011
— [ORB]
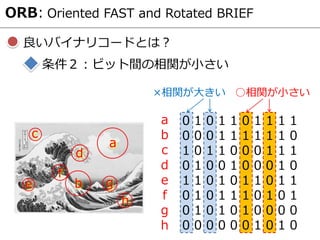
E.Rublee, V.Rabaud, K.Konolige and G.Bradsk, "ORB: an efficient
alternative to SIFT or SURF,“ ICCV2011
— [FREAK]
Alexandre Alahi, Raphael Ortiz, and Pierre Vandergheynst, “FREAK: Fast
retina keypoint," CVPR2012
— [D-BRIEF]
Tomasz Trzcinski and Vincent Lepetit, "Efficient discriminative projections
for compact binary descriptors," ECCV2012
— [BinBoost]
T. Trzcinski, M. Christoudias, V. Lepetit, and P. Fua, "Boosting binary
keypoint descriptors," CVPR2013
— [BOLD]
V. Balntas, L. Tang, and K. Mikolajczyk. BOLD - binary online learned
descriptor for efficient image matching. CVPR2015
本資料では、下記に記載の論文から図を一部引用した。
103.
関連文献
— [CARD]
M.Ambai andY.Yoshida, “Compact And Real-time Descriptors, ” in Proc.
ICCV2011
— [LDA Hash]
C. Strecha, A.M. Bronstein, M.M. Bronstein, and Pee. Fua, "LDAHash:
Improved matching with smaller descriptors," TPAMI2012
— [CNN Descriptor]
E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-
Noguer, "Discriminative learning of deep convolutional feature point
descriptors," ICCV2015
— [CNN Similarity]
S. Zagoruyko and N. Komodakis. Learning to compare image patches via
convolutional neural networks," CVPR2015
— [Spectral Affine SIFT]
Takahiro Hasegawa, Mitsuru Ambai, Kohta Ishikawa, Gou Koutaki, Yuji
Yamauchi, Takayoshi Yamashita, Hironobu Fujiyoshi, "Multiple-Hypothesis
Affine Region Estimation With Anisotropic LoG Filters," ICCV2015
本資料では、下記に記載の論文から図を一部引用した。

















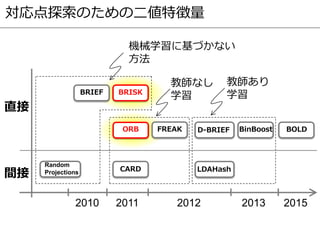
![手法 BRISK ORB
パッチ方向
推定
Local gradientの
平均ベクトル
Intensity Centroid
ペアの
選び方
規則的に決定 教師なし学習
BRIEFに Scale/Rotation Invariance を導入
Fast Corner Detector + BRIEF
BRISK: Binary Robust Invariant Scalable Keypoints. [ICCV2011]より図を引用
ORB: An Efficient Alternative to SIFT and SURF. [ICCV2011]より図を引用
BRISKとORB](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-23-320.jpg)
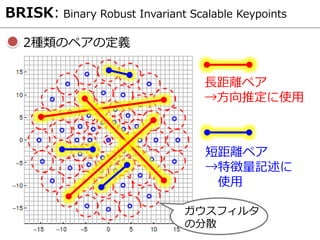




![Greedy Algorithmによるサンプリング位置の決定
ORB: Oriented FAST and Rotated BRIEF
[ 戦略 ]
パッチ内の考えられうる全てのペア(205590通り)について、
ビットの分散最大&ビット間の相関最小な256個のペアを選出
Step 1.
学習用画像を処理し、全ペアの
分散を求め、分散最大のペアを採用
Step 2.
残りのペアの中で、採用済みペア
と相関が低くかつ分散最大なもの
を採用
Step 3.
256個決まるまで、Step2を繰り返す](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-30-320.jpg)



































![深層学習を用いた手法
Discriminative Learning of Deep Convolutional
Feature Point Descriptors (CNN Descriptor)
[Simo-serra, ICCV2015]
Learning to Compare Image Patches via
Convolutional Neural Networks (CNN Similarity)
[Zagoruyko, CVPR2015]](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-74-320.jpg)

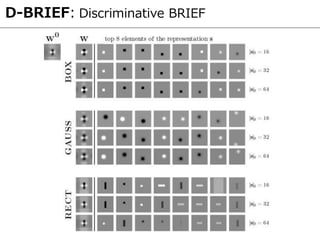
![CNN Descriptor [Simo-serra, ICCV2015]
CNNを利用したパッチ画像の特徴量抽出
畳み込み層のみを使用し,全結合層は使用しない
CNNの構成
入力:パッチ画像,出力:特徴量(128次元)
活性化関数:hyperbolic tangent
プーリング:L2プーリング
畳み込み層 (特徴抽出部)
特徴量](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-76-320.jpg)


![Hard negative and positive mining
マッチングが困難なペアに対するCNNの更新
順伝播によりhard negative, positiveのペアを求める
hard negativeとhard positiveに対して再度逆伝播
Simo-serra, et al., “Discriminative Learning of Deep Convolutional Feature Point Descriptors”,
ICCV, 2015. ポスターより、図の一部を引用
• Consistent improvements over the state of the art.
• Trained in one dataset, but generalizes very well to scaling, rota-
tion, deformation and illumination changes.
• Computational efficiency (on GPU: 0.76 ms; dense SIFT: 0.14 ms).
Code is available: https:/ / github.com/ etrulls/ deepdesc-release
Key observation
1. We train a Siamese architecture with pairs of patches. We want
to bringmatching pairstogether and otherwise pull them apart.
2. Problem? Randomly sampled pairs are already easy to separate.
3. Solution: To train discriminative networks we use hard negative
and positive mining. This proves essential for performance.
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
positives (+, long blue segments) and sim-
ilar negatives (× , short red segments):
(d) Random sampling results in easy pairs.
(e) Mined pairs with harder correspondences.
(d) Random pairs
(e) Mined pairs
This allows us to train discriminative models with a small number
of parameters (∼45k), which also alleviates overfitting concerns.
Stride 2 3 4
Train on the M VS Dataset [1]. 64 × 64 grayscale pat
Statue of Liberty (LY, top), NotreDame (ND, center)
bottom). ∼150k points and ∼450k patches each ⇒ 10
and 1012
negative pairs⇒ Efficient exploration wit
Weminimizethehingeembedding loss. With 3D po
l(x1, x2)=
∥D(x1) − D(x2)∥2,
max(0, C − ∥D(x1) − D(x2)∥2),
This penalizes corresponding pairs that are placed
non-corresponding pairs that are less than C units a
M ethodology: Train over two setsand test over third
with cross-validation. Metric: precision-recall (PR
haystack’ setting: pick 10k unique points and gen
tive pair and 1k negative pairs for each, i.e. 10k po
negatives. Results summarized by ‘Area Under the
Effect of mining
(a) Forward-propagate positives sp ≥ 128 and negat
(b) Pick the 128 with the largest loss (for each) and b
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, training LY+YO, test ND
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
Recall
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
PR curve, training LY+ND, test YO
SIFT
CNN3, mined 1/2
CNN3, mined 2/2
CNN3, mined 4/4
CNN3, mined 8/8
0 0.1 0.2 0.3
Precision
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
PR curve, tr
sp sn PR AUC
128 128 0.366
256 256 0.374
512 512 0.369
1024 1024 0.325
Table 1: (a) No mining.
Larger batches do not help.
sp sn rp rn Cos
128 256 1 2 20%
256 256 2 2 35%
512 512 4 4 48%
1024 1024 8 8 67%
Table 2: (b) Mining with rp =
The mining cost is incurred d
available: https:/ / github.com/ etrulls/ deepdesc-release
bservation
ain a Siamese architecture with pairs of patches. We want
ngmatching pairstogether and otherwisepull them apart.
em? Randomly sampled pairs are already easy to separate.
ion: To train discriminative networks we use hard negative
positive mining. This proves essential for performance.
points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
samples from [1], for illustration. Cor-
ing patchesareshown with samecolor:
bottom). ∼150k points
and 1012
negative pa
Weminimizethehing
l(x1, x2)=
m
This penalizes corres
non-corresponding p
M ethodology: Train o
with cross-validation
haystack’ setting: pic
tive pair and 1k nega
negatives. Results sum
Effect of mining
(a) Forward-propaga
(b) Pick the 128 with
(a) 12 points/ 132 patches with t-SNE [8]
(b) All pairs: pos/ neg
(c) “ Hard” pairs: pos/ neg
We take samples from [1], for illustration. Cor-
responding patchesareshown with samecolor:
(a) Representation from t-SNE [8]. Distance
encodessimilarity.
(b) Random sampling: similar (close) posi-
tivesand different (distant) negatives.
(c) We mine the samples to obtain dissimilar
(d) Random pairs
各パッチ画像の特徴量の距離空間
同じ色のパッチ
↓
対応点
赤:negativeペア
青:positiveペア
hard positive
hard negative
hard negativeとhard positiveに適したネットワークに更新](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-79-320.jpg)

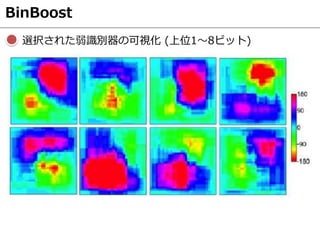
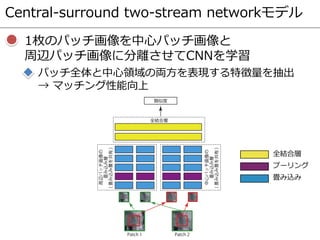
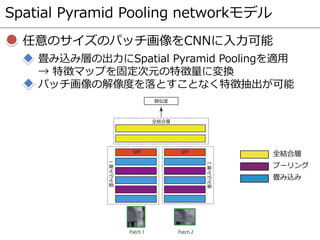
![CNN Similarity [Zagoruyko, CVPR2015]
CNNによりパッチ画像間の類似度を算出
畳み込み層で特徴抽出,全結合層で2枚のパッチ画像の
類似度を算出
CNNの構成
入力:パッチ画像,出力:パッチ画像間の類似度
活性化関数:Rectified Linear Unit (ReLU)
プーリング:Maxプーリング
5種類のCNNモデルを提案
2-channelモデル
Siameseモデル
Pseudo-siameseモデル
Central-surround two-stream networkモデル
Spatial Pyramid Pooling networkモデル](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-82-320.jpg)





![深層学習による特徴量表現 まとめ
学習でマイニング等の工夫を加えることで
特徴量記述の性能向上
特徴抽出と類似度をend-to-endで学習
特徴量記述の処理速度が課題
1つの特徴量記述に要する時間
CNN Descriptor (CPU) 4.81 [ms]
CNN Descriptor (GPU) 0.76 [ms]
SIFT 0.14 [ms]
今後の予想される展開
キーポイント検出も含めてend-to-endで学習
可視光カメラと赤外光カメラ間での対応点探索](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-90-320.jpg)



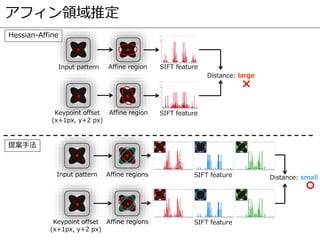
![従来のキーポイント検出
Rotation invariant
Scale invariant
Affine invariant
アフィン不変なキーポイント検出が
提案されていない
提案手法
[Hasegawa2015]](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-94-320.jpg)





![関連文献
— [SIFT]
David G. Lowe, "Distinctive image features from scale-Invariant
keypoints," IJCV2004
— [SURF]
Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool, “Speeded-
up robust features (SURF),” CVIU2008.
— [PCA-SIFT]
Yan Ke and Rahul Sukthankar, “PCA-SIFT: A more distinctive
representation for local image descriptors,” CVPR2004
— [GLOH]
Krystian Mikolajczyk and Cordelia Schmid, “A performance evaluation of
local descriptors,“ TPAMI2005
— [RIFF]
Gabriel Takacs, Vijay Chandrasekhar, Sam Tsai, David Chen, Radek
Grzeszczuk, and Bernd Girod, "Unified real-time tracking and recognition
with rotation-invariant fast features," CVPR2010
— [ASIFT]
Jean-Michel Morel and Guoshen Yu, "ASIFT: A new framework for fully
affine invariant image comparison" SIAM Journal on Imaging Sciences,
Vol. 2, No. 2, pp. 438-469, April 2009.
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-101-320.jpg)
![関連文献
— [BRIEF]
M.Calonder, V.Lepetit, and P.Fua, “BRIEF: Binary Robust Independent
Elementary Features,” ECCV2010
— [BRISK]
S.Leutenegger, M.Chli and R.Siegwart, "BRISK: Binary Robust Invariant
Scalable Keypoints,“ ICCV2011
— [ORB]
E.Rublee, V.Rabaud, K.Konolige and G.Bradsk, "ORB: an efficient
alternative to SIFT or SURF,“ ICCV2011
— [FREAK]
Alexandre Alahi, Raphael Ortiz, and Pierre Vandergheynst, “FREAK: Fast
retina keypoint," CVPR2012
— [D-BRIEF]
Tomasz Trzcinski and Vincent Lepetit, "Efficient discriminative projections
for compact binary descriptors," ECCV2012
— [BinBoost]
T. Trzcinski, M. Christoudias, V. Lepetit, and P. Fua, "Boosting binary
keypoint descriptors," CVPR2013
— [BOLD]
V. Balntas, L. Tang, and K. Mikolajczyk. BOLD - binary online learned
descriptor for efficient image matching. CVPR2015
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-102-320.jpg)
![関連文献
— [CARD]
M.Ambai and Y.Yoshida, “Compact And Real-time Descriptors, ” in Proc.
ICCV2011
— [LDA Hash]
C. Strecha, A.M. Bronstein, M.M. Bronstein, and Pee. Fua, "LDAHash:
Improved matching with smaller descriptors," TPAMI2012
— [CNN Descriptor]
E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-
Noguer, "Discriminative learning of deep convolutional feature point
descriptors," ICCV2015
— [CNN Similarity]
S. Zagoruyko and N. Komodakis. Learning to compare image patches via
convolutional neural networks," CVPR2015
— [Spectral Affine SIFT]
Takahiro Hasegawa, Mitsuru Ambai, Kohta Ishikawa, Gou Koutaki, Yuji
Yamauchi, Takayoshi Yamashita, Hironobu Fujiyoshi, "Multiple-Hypothesis
Affine Region Estimation With Anisotropic LoG Filters," ICCV2015
本資料では、下記に記載の論文から図を一部引用した。](https://image.slidesharecdn.com/prmu201512slideshare-151222104106/85/2015-12-PRMU-103-320.jpg)


























![[論文紹介] DPSNet: End-to-end Deep Plane Sweep Stereo](https://cdn.slidesharecdn.com/ss_thumbnails/20190212dpsnet-190830151623-thumbnail.jpg?width=640&height=640&fit=bounds)









![[CVPR読み会]BING:Binarized normed gradients for objectness estimation at 300fps](https://cdn.slidesharecdn.com/ss_thumbnails/bing-140725194514-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

























