Download as PDF, PPTX










![Broadcasting
>>> import numpy as np
>>> a=np.array([0,1,2])
>>> a*3
array([0, 3, 6])
>>> b=np.array([1,4,9])
>>> np.sqrt(b)
array([ 1., 2., 3.])
A function which is applied to each element when applied to an array is called
a universal function.
11 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-11-320.jpg)
![Broadcasting (2D)
>>> import numpy as np
>>> a=np.arange(9).reshape((3,3))
>>> b=np.array([1,2,3])
>>> a
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> b
array([1, 2, 3])
>>> a*b
array([[ 0, 2, 6],
[ 3, 8, 15],
[ 6, 14, 24]])
12 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-12-320.jpg)
![Indexing
>>> import numpy as np
>>> a=np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> indices=np.arange(0,10,2)
>>> indices
array([0, 2, 4, 6, 8])
>>> a[indices]=0
>>> a
array([0, 1, 0, 3, 0, 5, 0, 7, 0, 9])
>>> b=np.arange(100,600,100)
>>> b
array([100, 200, 300, 400, 500])
>>> a[indices]=b
>>> a
array([100, 1, 200, 3, 300, 5, 400, 7, 500, 9])
13 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-13-320.jpg)


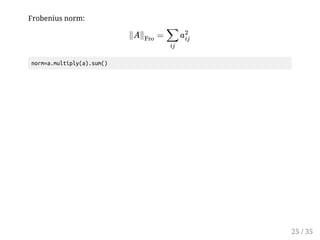
![scipy.sparse
The class scipy.sparse has mainly three types as expressions of a sparse
matrix. (There are other types but not mentioned here)
lil_matrix : convenient to set data; setting a[i,j] is fast
csr_matrix : convenient for computation, fast to retrieve a row
csc_matrix : convenient for computation, fast to retrieve a column
Usually, set the data into lil_matrix, and then, convert it to csc_matrix or
csr_matrix.
For csr_matrix, and csc_matrix, calcutaion of matrices of the same type is fast,
but you should avoid calculation of different types.
16 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-16-320.jpg)
![Use case
>>> from scipy.sparse import lil_matrix, csr_matrix
>>> a=lil_matrix((3,3))
>>> a[0,0]=1.; a[0,2]=2.
>>> a=a.tocsr()
>>> print a
(0, 0) 1.0
(0, 2) 2.0
>>> a.todense()
matrix([[ 1., 0., 2.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> b=lil_matrix((3,3))
>>> b[1,1]=3.; b[2,0]=4.; b[2,2]=5.
>>> b=b.tocsr()
>>> b.todense()
matrix([[ 0., 0., 0.],
[ 0., 3., 0.],
[ 4., 0., 5.]])
>>> c=a.dot(b)
>>> c.todense()
matrix([[ 8., 0., 10.],
[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> d=a+b
>>> d.todense()
matrix([[ 1., 0., 2.],
[ 0., 3., 0.],
[ 4., 0., 5.]]) 17 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-17-320.jpg)
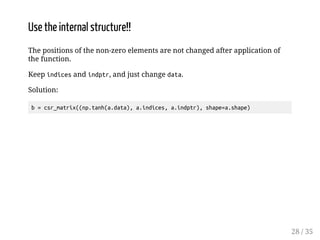
![Internal structure: csr_matrix
>>> from scipy.sparse import lil_matrix, csr_matrix
>>> a=lil_matrix((3,3))
>>> a[0,1]=1.; a[0,2]=2.; a[1,2]=3.; a[2,0]=4.; a[2,1]=5.
>>> b=a.tocsr()
>>> b.todense()
matrix([[ 0., 1., 2.],
[ 0., 0., 3.],
[ 4., 5., 0.]])
>>> b.indices
array([1, 2, 2, 0, 1], dtype=int32)
>>> b.data
array([ 1., 2., 3., 4., 5.])
>>> b.indptr
array([0, 2, 3, 5], dtype=int32)
18 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-18-320.jpg)
![Internal structure: csc_matrix
>>> from scipy.sparse import lil_matrix, csr_matrix
>>> a=lil_matrix((3,3))
>>> a[0,1]=1.; a[0,2]=2.; a[1,2]=3.; a[2,0]=4.; a[2,1]=5.
>>> b=a.tocsc()
>>> b.todense()
matrix([[ 0., 1., 2.],
[ 0., 0., 3.],
[ 4., 5., 0.]])
>>> b.indices
array([2, 0, 2, 0, 1], dtype=int32)
>>> b.data
array([ 4., 1., 5., 2., 3.])
>>> b.indptr
array([0, 1, 3, 5], dtype=int32)
19 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-19-320.jpg)

![from scipy.sparse import lil_matrix, csr_matrix
import numpy as np
from timeit import timeit
def set_lil(n):
a=lil_matrix((n,n))
for i in xrange(n):
a[i,i]=2.
if i+1n:
a[i,i+1]=1.
return a
def set_csr(n):
data=np.empty(2*n-1)
indices=np.empty(2*n-1,dtype=np.int32)
indptr=np.empty(n+1,dtype=np.int32)
# to be fair, for-sentence is intentionally used
# (using indexing technique is faster)
for i in xrange(n):
indices[2*i]=i
data[2*i]=2.
if in-1:
indices[2*i+1]=i+1
data[2*i+1]=1.
indptr[i]=2*i
indptr[n]=2*n-1
a=csr_matrix((data,indices,indptr),shape=(n,n))
return a
print lil:,timeit(set_lil(10000),
number=10,setup=from __main__ import set_lil)
print csr:,timeit(set_csr(10000),
number=10,setup=from __main__ import set_csr)
21 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-21-320.jpg)



![Case 2: Applying a function to all of the elements of a
sparse matrix
A universal function can be applied to a dense matrix:
import numpy as np
a=np.arange(9).reshape((3,3))
a
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
np.tanh(a)
array([[ 0. , 0.76159416, 0.96402758],
[ 0.99505475, 0.9993293 , 0.9999092 ],
[ 0.99998771, 0.99999834, 0.99999977]])
This is convenient and fast.
However, we cannot do the same thing for a sparse matrix.
26 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-26-320.jpg)
![from scipy.sparse import lil_matrix
a=lil_matrix((3,3))
a[0,0]=1.
a[1,0]=2.
b=a.tocsr()
np.tanh(b)
3x3 sparse matrix of type 'type 'numpy.float64''
with 2 stored elements in Compressed Sparse Row format
This is because, for an arbitrary function, its application to a sparse matrix is
not necessarily sparse.
However, if a universal function satisfies
, the density is
preserved.
Then, how can we compute it?
27 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-27-320.jpg)
![Case 3: Formula which appears in a paper
In the algorithm for recommendation system [1], the following formula
appears:
øø
* g
where is dense matrix, and D is a diagonal matrix defined from a
given array as:
%
ý
*
Here, (which corresponds to the number of users or items) is big and
(which means the number of latent factors) is small.
[1] Hu et al. Collaborative Filtering for Implicit Feedback Datasets, ICDM,
2008.
*
29 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-29-320.jpg)
![Solution 1:
There is a special class dia_matrix to deal with a diagonal sparse matrix.
import scipy.sparse as sparse
import numpy as np
def f(a,d):
a: 2d array of shape (n,f), d: 1d array of length n
dd=sparse.diags([d],[0])
return np.dot(a.T,dd.dot(a))
30 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-30-320.jpg)
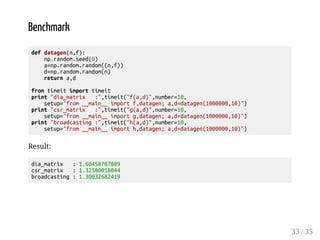
![Solution 2:
Pack csr_matrix with data,indices,indptr
data=d
indices=[0,1,..,n]
indptr=[0,1,...,n+1]
def g(a,d):
n,f=a.shape
data=d
indices=np.arange(n)
indptr=np.arange(n+1)
dd=sparse.csr_matrix((data,indices,indptr),shape=(n,n))
return np.dot(a.T,dd.dot(a))
31 / 35](https://image.slidesharecdn.com/effectivenumericalcomputationinnumpyandscipy-140913005204-phpapp01/85/Effective-Numerical-Computation-in-NumPy-and-SciPy-31-320.jpg)




This document provides an overview of effective numerical computation in NumPy and SciPy. It discusses how Python can be used for numerical computation tasks like differential equations, simulations, and machine learning. While Python is initially slower than languages like C, libraries like NumPy and SciPy allow Python code to achieve sufficient speed through techniques like broadcasting, indexing, and using sparse matrix representations. The document provides examples of how to efficiently perform tasks like applying functions element-wise to sparse matrices and calculating norms. It also presents a case study for efficiently computing a formula that appears in a machine learning paper using different sparse matrix representations in SciPy.


![[DL輪読会]Attentive neural processes](https://cdn.slidesharecdn.com/ss_thumbnails/attentiveneuralprocesses-181225051145-thumbnail.jpg?width=640&height=640&fit=bounds)











![Introduction to Pandas and Time Series Analysis [PyCon DE]](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontopandasandtimeseriesanalysispyconde-170617163724-thumbnail.jpg?width=640&height=640&fit=bounds)