A Safe Rulefor Sparse Logistic Regression
LR with L1 regularization
min
1
m
m∑
i=1
(
1 + exp(−βT
xi − bi c)
)
+ λ∥β∥1
∥ · ∥1 は L1 ノルム (∥β∥ :=
∑m
i=1|β|)
xi ∈ Rm, i = 1, . . . , p:学習データの特徴ベクトル
bi ∈ {−1, 1} , i = 1, . . . , p:学習データのラベル
β ∈ Rm, c ∈ R :(最適化すべき) パラメータ
7.
A Safe Rulefor Sparse Logistic Regression
双対問題への変換
min
1
m
∑
i
(
1 + exp(−βT
xi − bi c)
)
+ λ∥β∥1
双対問題:
min
{
g(θ) =
1
m
m∑
i=1
f (θi ) : ∥ ¯XT
θ∥∞, θT
b = 0, θ ∈ Rm
}
ただし
¯xi := bi xi
つまり
¯X = bT
X
8.
A Safe Rulefor Sparse Logistic Regression
Notations
学習の入力データ X ∈ Mat(m, p; R) に対して、xi は i 行目のベク
トル、xj は j 列目のベクトル。
λ に依存した最適値として、β∗
λ, θ∗
λ
β の i 番目の要素は [β]i で表す。
A Safe Rulefor Sparse Logistic Regression
既存研究
同じようにゼロ要素を先に見つける手法:
1 SAFE (El Ghaoui et al., 2010)
2 Strong rules (Tibshirani et al., 2012)
3 DOME (Xiang et al., 2012)
ここで、2. と 3. は safe ではない (つまり最適解が 0 でない要素を
0 と判定することがある)。
本研究では safe かつ効率のよい手法を提案。
11.
A Safe Rulefor Sparse Logistic Regression
閾値について
P = {i|bi = 1} , N = {i|bi = −1} , m+
= #P, m−
= #N
[
θ∗
λmax
]
i
=
{
m−/m if i ∈ P
m+/m if i ∈ N
λmax =
1
m
∥XT
θλ∗
max
∥∞
と定義すると次が成り立つ。







![A Safe Rule for Sparse Logistic Regression
Notations
学習の入力データ X ∈ Mat(m, p; R) に対して、xi は i 行目のベク
トル、xj は j 列目のベクトル。
λ に依存した最適値として、β∗
λ, θ∗
λ
β の i 番目の要素は [β]i で表す。](https://image.slidesharecdn.com/nips2014yomi-150120074645-conversion-gate02/85/A-Safe-Rule-for-Sparse-Logistic-Regression-8-320.jpg)
![A Safe Rule for Sparse Logistic Regression
L1 regularization と sparseness
L1 regularization 項がある最適化は解が疎であることが期待
できる
この場合も、KKT 条件から次の式が得られる
|θ∗T
λ ¯xj
| < mλ ⇒ [βλ]j = 0
実際最適解の多くのパラメータが 0 になる。](https://image.slidesharecdn.com/nips2014yomi-150120074645-conversion-gate02/85/A-Safe-Rule-for-Sparse-Logistic-Regression-9-320.jpg)

![A Safe Rule for Sparse Logistic Regression
閾値について
P = {i|bi = 1} , N = {i|bi = −1} , m+
= #P, m−
= #N
[
θ∗
λmax
]
i
=
{
m−/m if i ∈ P
m+/m if i ∈ N
λmax =
1
m
∥XT
θλ∗
max
∥∞
と定義すると次が成り立つ。](https://image.slidesharecdn.com/nips2014yomi-150120074645-conversion-gate02/85/A-Safe-Rule-for-Sparse-Logistic-Regression-11-320.jpg)

![A Safe Rule for Sparse Logistic Regression
条件の緩和
KKT 条件により
|θ∗T
λ ¯xj
| < mλ ⇒ [βλ]j = 0
これを緩和し最適値 θ∗
λ が含まれるような領域を Aλ とすると
max
θ∈Aλ
|θT
¯xj
| < mλ ⇒ [βλ]j = 0
方針:この条件を十分条件で簡略化していき、良いバウンドを見
つける。
(途中計算略)](https://image.slidesharecdn.com/nips2014yomi-150120074645-conversion-gate02/85/A-Safe-Rule-for-Sparse-Logistic-Regression-13-320.jpg)
![A Safe Rule for Sparse Logistic Regression
定理
λmax ≥ λ0 > λ > 0 のとき次のいずれかが成り立てば [β∗
λ]i = 0
1 ¯xj − ¯xjT b
∥b∥2
2
b = 0
2 max
{
Tξ(θ∗
λ, ¯xj ; θ∗
λ0
)|ξ = ±1
}
< mλ
ただし
Tξ(θ∗
λ, ¯xj
; θ∗
λ0
) := max
θ∈Aλ
λ0
ξθT
¯xj
Aλ
λ0
:=
{
θ|∥θ − θ∗
λ0
∥2
2 ≤ r2
, θT
b = 0, θT
¯x∗
≤ mλ
}
2. は凸最適化で、解析的な最適解 (Theorem 8) が得られる。
実際の計算時には λ0 = λmax として計算してよい。](https://image.slidesharecdn.com/nips2014yomi-150120074645-conversion-gate02/85/A-Safe-Rule-for-Sparse-Logistic-Regression-14-320.jpg)


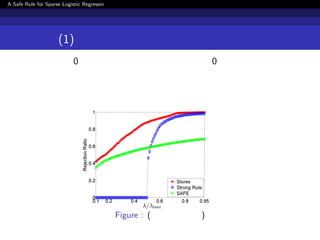

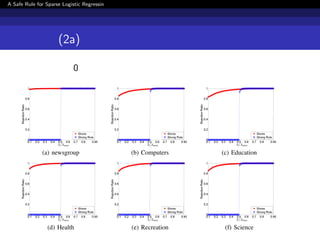
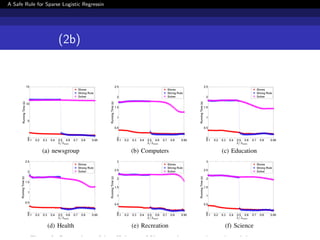






















![[DSO]勉強会_データサイエンス講義_Chapter7](https://cdn.slidesharecdn.com/ss_thumbnails/dsodatasciencelecturechapter7-191122112044-thumbnail.jpg?width=640&height=640&fit=bounds)


























