Download as PDF, PPTX




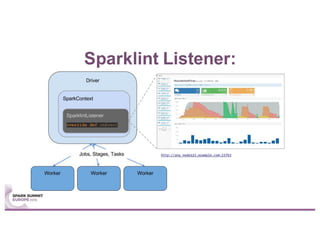
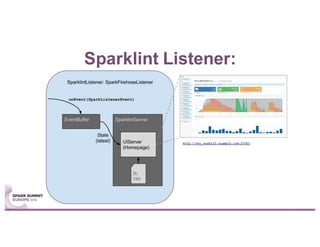
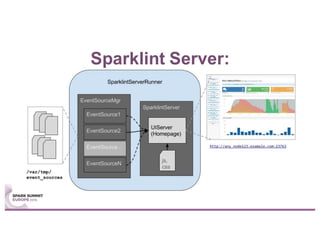

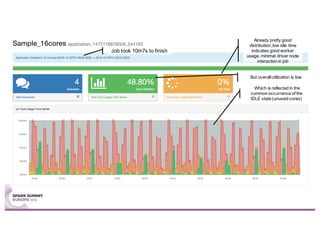
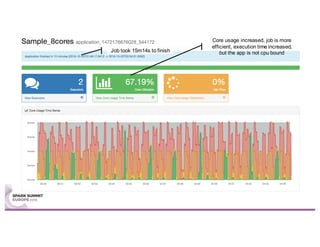
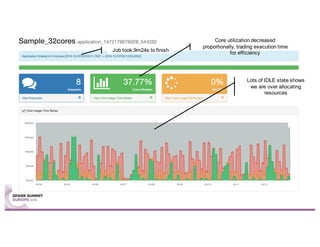
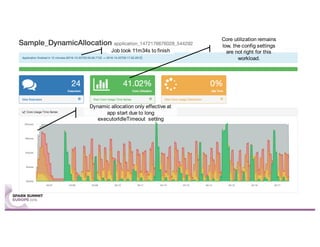
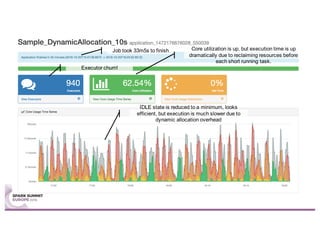
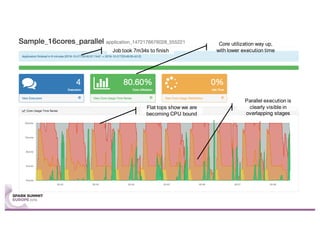
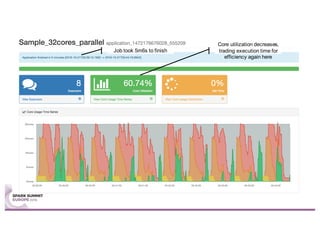
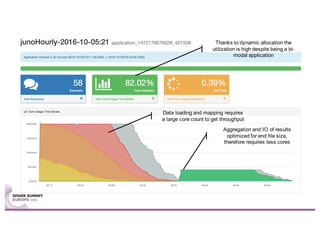





Sparklint is a tool for identifying and tuning inefficient Spark jobs across a cluster. It provides live views of application statistics or event-by-event analysis of historical logs for metrics like idle time, core usage, and task locality. The demo shows Sparklint analyzing access logs to count by IP, status, and verb over multiple jobs, tuning configuration settings to improve efficiency and reduce idle time. Future features may include more job detail, auto-tuning, and streaming optimizations. Sparklint is an open source project for contributing to Spark job monitoring and optimization.














































![[DSC DACH 23] Learnings integrating a machine learning model to existing soft...](https://cdn.slidesharecdn.com/ss_thumbnails/clemenszauchnerlearningsintegratingamachinelearningmodeltoexistingsoftware-230424080558-3c875fb8-thumbnail.jpg?width=640&height=640&fit=bounds)








































