

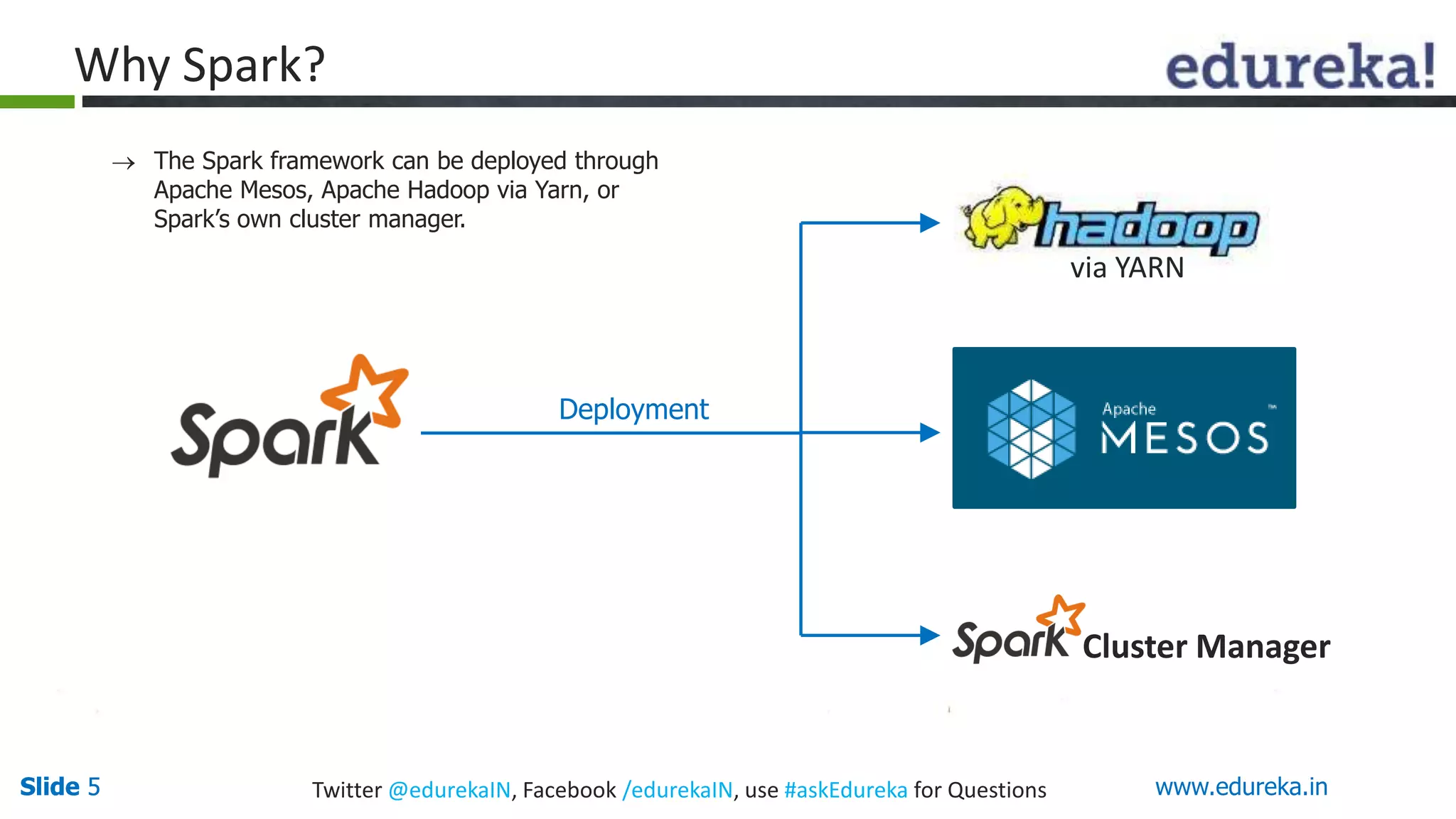
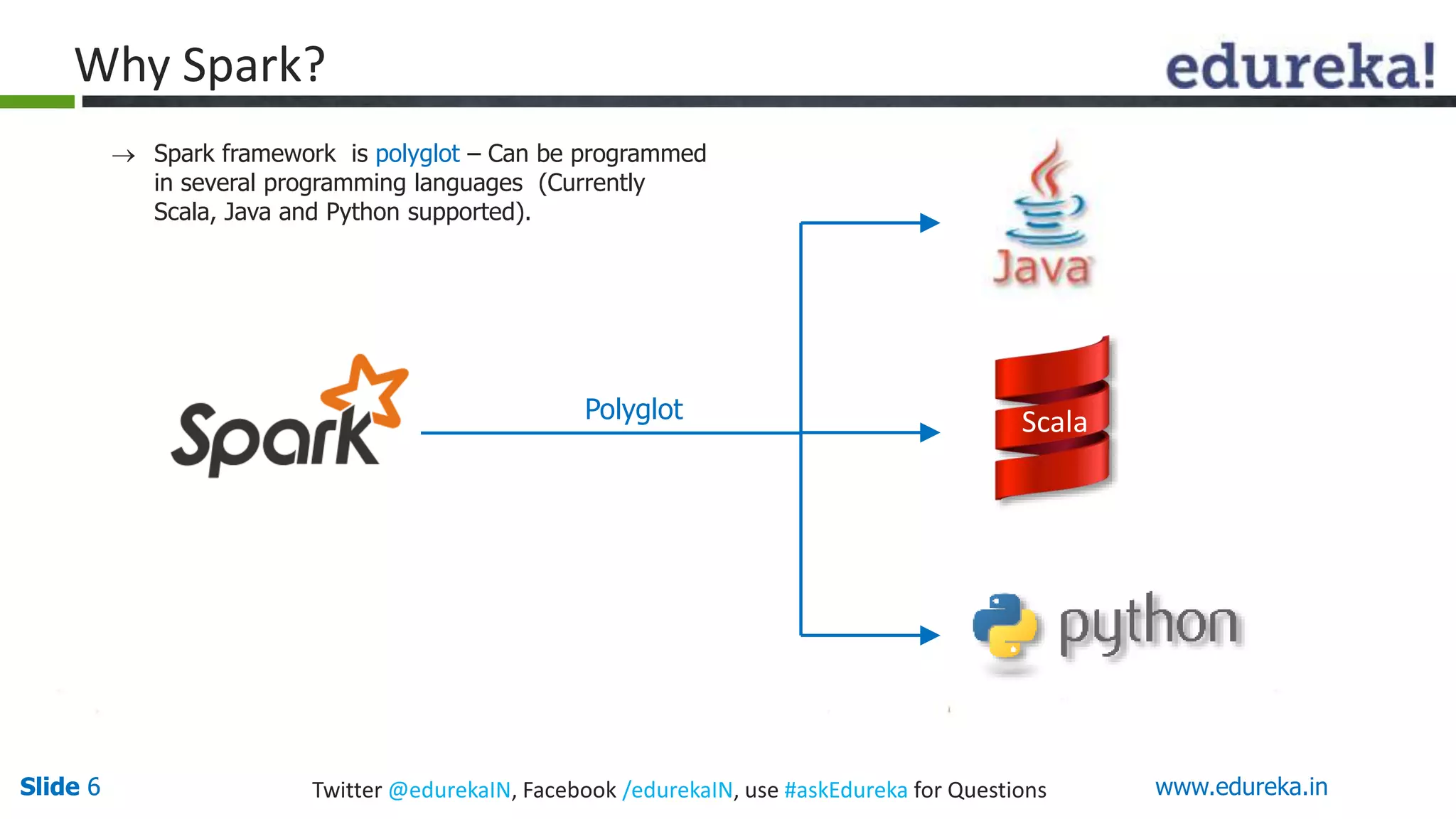


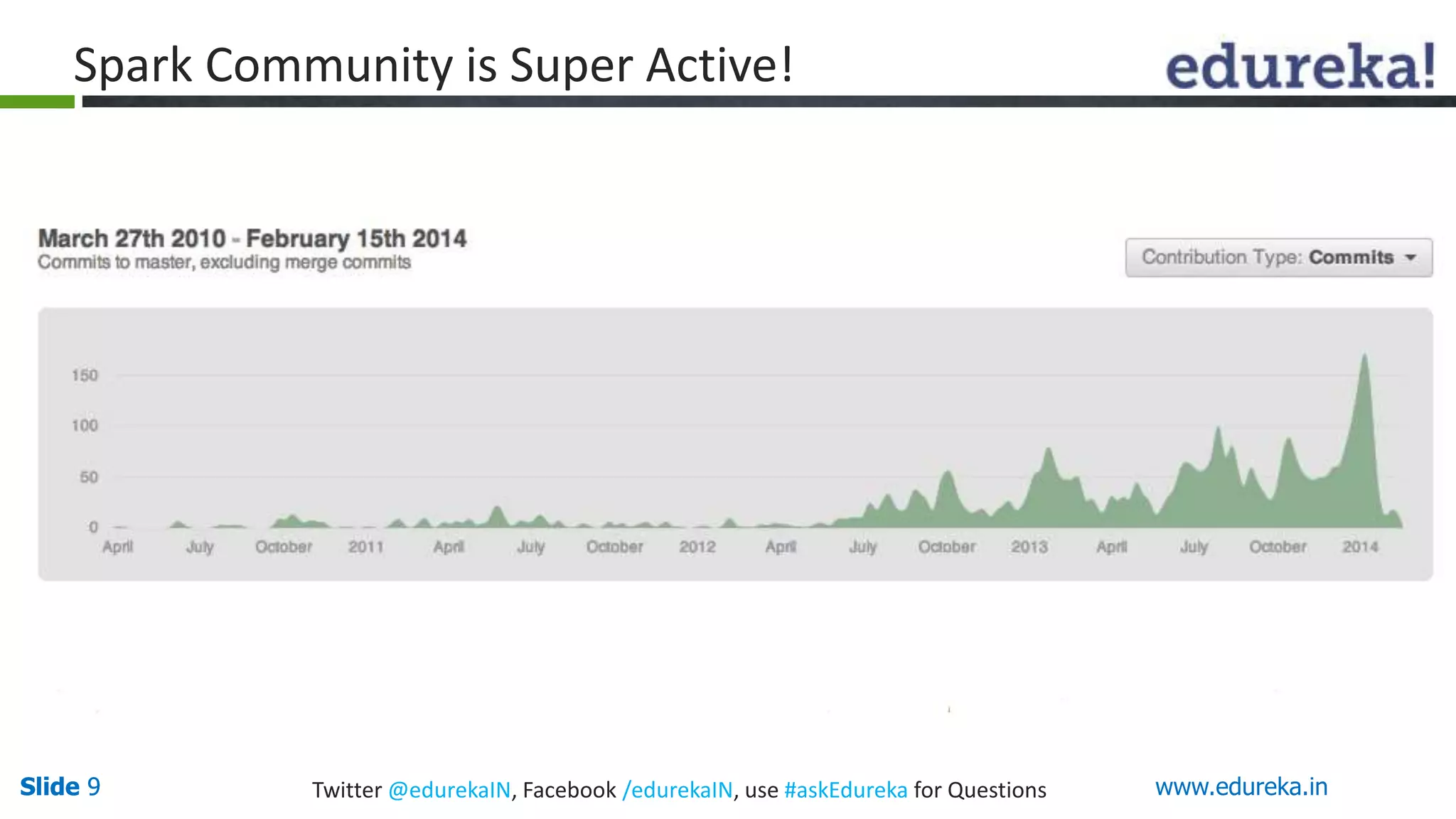
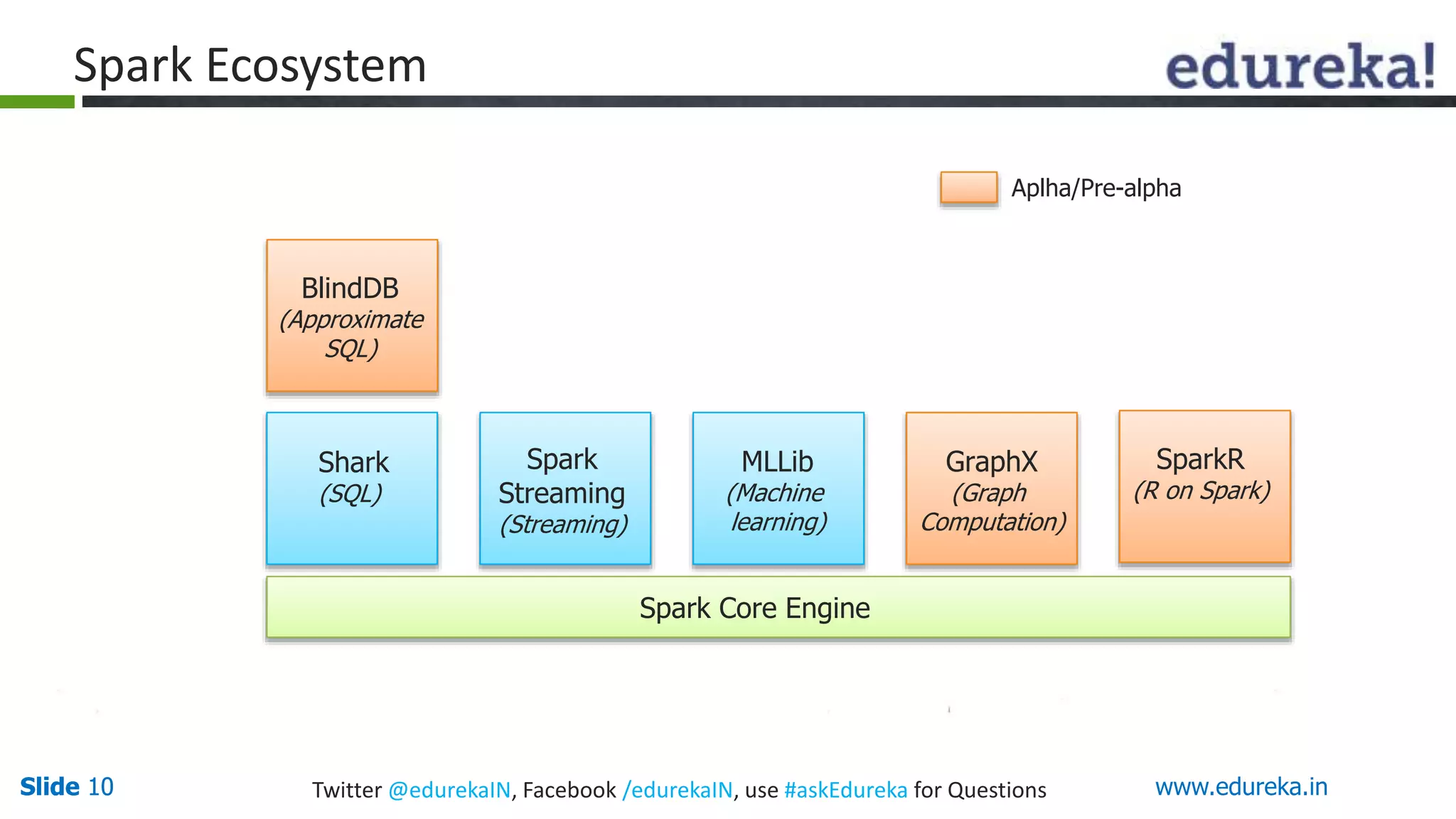
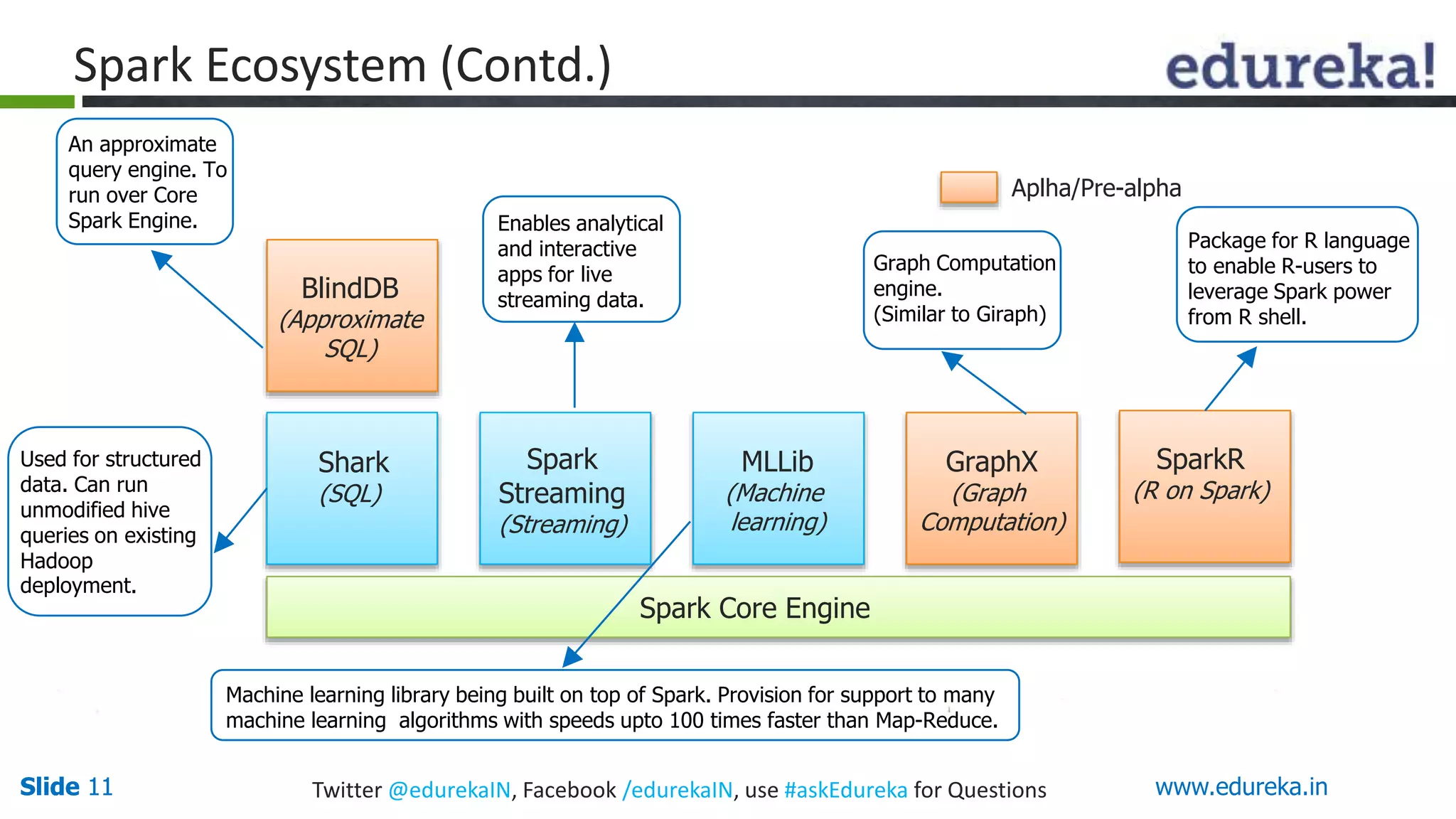






This document provides an overview of big data processing with Scala and Spark. It introduces big data concepts and defines Spark as an Apache project that provides a general-purpose cluster computing system. The document outlines why Spark is useful, such as its speed, APIs, and tools. It also describes Scala as a functional programming language integrated with Java that is well-suited for big data frameworks like Spark. The remainder covers Spark's ecosystem of modules and concludes with an invitation to try a basic "Hello World" Spark program.
![[Pgday.Seoul 2017] 2. PostgreSQL을 위한 리눅스 커널 최적화 - 김상욱](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-171106040432-thumbnail.jpg?width=640&height=640&fit=bounds)










































































































