Download as PDF, PPTX







![Problem Definition
We have Apache logs from our website. They follow a standard pattern and we
want to parse them to gain some insights on usage.
114.200.179.85 - - [24/Feb/2016:00:10:02 -0500] "GET /wp HTTP/1.1" 200 5279
"http://sparkdeveloper.com/" "Mozilla/5.0"
Bytes Sent
HTTP Referer
User Agent
IP Address
ClientID
UserID
Date Time Stamp
Request String
HTTP Status Code](https://image.slidesharecdn.com/airisdataapachesparkoverviewpart1-160322205227/85/Apache-Spark-Overview-7-320.jpg)


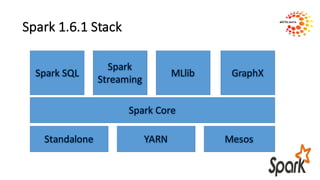



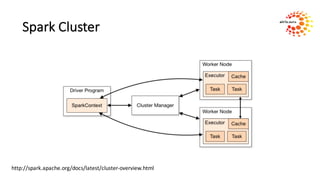


Tim Spann will present on learning Apache Spark. He is a senior solutions architect who previously worked as a senior field engineer and startup engineer. airis.DATA, where Spann works, specializes in machine learning and graph solutions using Spark, H20, Mahout, and Flink on petabyte datasets. The agenda includes an overview of Spark, an explanation of MapReduce, and hands-on exercises to install Spark, run a MapReduce job locally, and build a project with IntelliJ and SBT.





















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

