Download as PDF, PPTX











![CREATINGTABLE USING SCALA
• Create kuducontext
• val columnList = new ArrayList[ColumnSchema]()
columnList.add(new ColumnSchemaBuilder("nc_periodid",Type.INT32).key(true).build())
columnList.add(new ColumnSchemaBuilder("ac_nshopid",Type.STRING).key(true).build())
columnList.add(new ColumnSchemaBuilder("ac_lbatchtype",Type.STRING).key(false).build())
val schema = new Schema(columnList)
val cto = new CreateTableOptions()
distrubutionList.add("nc_periodid")
cto.addHashPartitions(distrubutionList, numberOfBuckets)
kuduClient.createTable(tableName, schema, cto).setRepilica(3)](https://image.slidesharecdn.com/kududemo-161020131751/85/Kudu-demo-13-320.jpg)





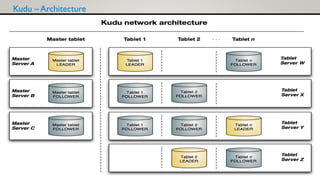
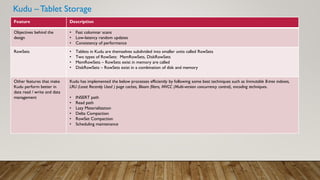
Kudu is an open source storage engine that provides low-latency random access and efficient analytical access to structured data. It horizontally partitions and replicates data across multiple servers for high availability and performance. Kudu integrates with Hadoop ecosystems tools like Impala, Spark, and MapReduce. The demo will cover Kudu's architecture, data storage, and implementation in buffer and raw data loads using Kudu tables.



































































