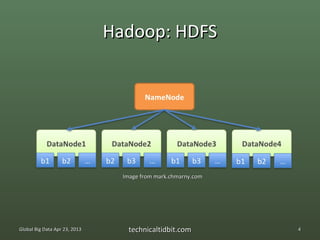
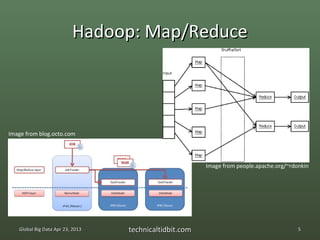
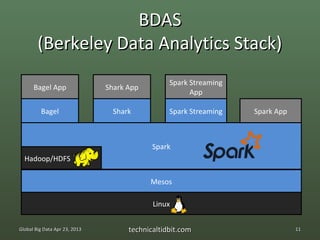
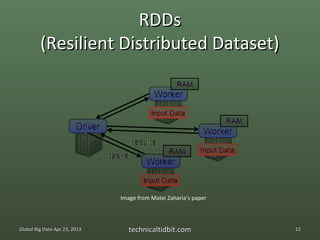
The document discusses the Spark ecosystem. It provides an overview of Spark, a cluster computing framework developed at UC Berkeley, including its core components like Resilient Distributed Datasets (RDDs) and projects like Shark. Spark aims to improve on Hadoop and MapReduce by allowing more interactive queries and streaming data analysis through its use of RDDs to cache data in memory across clusters.









 saveAsSequenceFile(path)
reduceByKey[K,V](func) foreach(func)
join[K,V,W](otherDataset)
cogroup[K,V,W1,W2](other1,
other2)
cartesian[U](otherDataset)
sortByKey[K,V]
[K,V] in Scala same as <K,V>
templates in C++, Java
Global Big Data Apr 23, 2013 technicaltidbit.com 14](https://image.slidesharecdn.com/sparkandshark20130417-130424115517-phpapp02/85/Spark-2013-04-17-14-320.jpg)






![Spark Streaming: DAG
DStream
Dstream
.filter(
.foreach(
_.eventType==
println)
bj] “error”)
[EvO
am
tre
DStream[String] Dstream Ds
Kafka .transform
(JSON) Ds
tr eam
[Ev
Ob
j]
Dstream
Dstream
.filter(
.foreach(
_.eventType==
println)
“buyGoods”)
The DAG Dstream
.map((_.id,1))
Dstream
.groupByKey
Global Big Data Apr 23, 2013 technicaltidbit.com 22](https://image.slidesharecdn.com/sparkandshark20130417-130424115517-phpapp02/85/Spark-2013-04-17-22-320.jpg)

// DAG
val events:Dstream[evObj] = messages.transform(rdd => rdd.map(new evObj(_))
val errorCounts = events.filter(_.eventType == “error”)
errorCounts.foreach(rdd => println(rdd.count))
val usersBuying = events.filter(_.eventType == “buyGoods”).map((_.id,1))
.groupByKey
usersBuying.foreach(rdd => println(rdd.count))
// Go
ssc.start
Global Big Data Apr 23, 2013 technicaltidbit.com 23](https://image.slidesharecdn.com/sparkandshark20130417-130424115517-phpapp02/85/Spark-2013-04-17-23-320.jpg)
![Stateful Spark Streaming
Class ErrorsPerUser(var numErrors:Int=0) extends Serializable
val updateFunc = (values:Seq[evObj], state:Option[ErrorsPerUser]) => {
if (values.find(_.eventType == “logOff”) == None)
None
else {
values.foreach(e => {
e.eventType match { “error” => state.numErrors += 1 }
})
Option(state)
}
}
// DAG
val events:Dstream[evObj] = messages.transform(rdd => rdd.map(new evObj(_))
val errorCounts = events.filter(_.eventType == “error”)
val states = errorCounts.map((_.id,1))
.updateStateByKey[ErrorsPerUser](updateFunc)
// Off-DAG
states.foreach(rdd => println(“Num users experiencing errors:” + rdd.count))
Global Big Data Apr 23, 2013 technicaltidbit.com 24](https://image.slidesharecdn.com/sparkandshark20130417-130424115517-phpapp02/85/Spark-2013-04-17-24-320.jpg)





































































