Download to read offline







![Tips
• Use mapPartitions if you’ve got expensive objects to instantiate.
def partitionLines(lines:Iterator[String] )={
val parser = new CSVParser('t')
lines.map(parser.parseLine(_).size)
}
rdd.mapPartitions(partitionLines)
• Caching if you’re going to reuse objects.
rdd.cache() == rdd.persist(MEMORY_ONLY)
• Partition files to improve read performance
all_bids.write
.mode("append")
.partitionBy("insert_date","insert_hr")
.json(stage_path)](https://image.slidesharecdn.com/introtospark-160328124844/85/Intro-to-Spark-10-320.jpg)

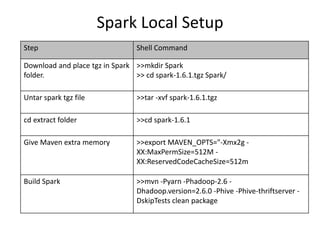


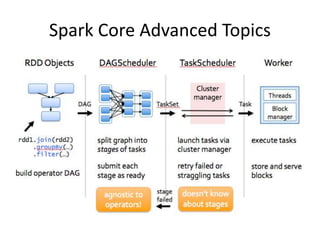
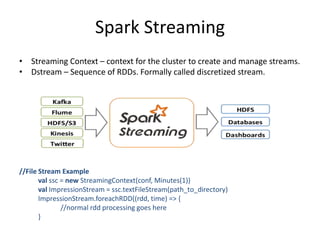
This document provides an introduction and overview of Apache Spark. It discusses why Spark is useful, describes some Spark basics including Resilient Distributed Datasets (RDDs) and DataFrames, and gives a quick tour of Spark Core, SQL, and Streaming functionality. It also provides some tips for using Spark and describes how to set up Spark locally. The presenter is introduced as a data engineer who uses Spark to load data from Kafka streams into Redshift and Cassandra. Ways to learn more about Spark are suggested at the end.


























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








