Downloaded 32 times


















![As of Today
• Assumed the role of Associate Director for
Data Science (ADDS):
NIH Data Science Point Person
Reports to NIH Director
Lead the BD2K initiative
Trans-NIH responsibilities for data
Eric Green, Acting
[Modified slide from Eric Green]
3/01/14
2014 SPARC Annual Meeting
20](https://image.slidesharecdn.com/sparc0314-140302074519-phpapp01/85/Where-is-Open-Going-20-320.jpg)








![How Data Are Used
Structure Summary page activity for
H1N1 Influenza related structures
Jan. 2008
Jul. 2008
* http://www.cdc.gov/h1n1flu/estimates/April_March_13.htm
Jan. 2009
Jul. 2009
Jan. 2010
Jul. 2010
3B7E: Neuraminidase of A/Brevig Mission/1/1918
H1N1 strain in complex with zanamivir
1RUZ: 1918 H1 Hemagglutinin
3/01/14
29
2014 SPARC Annual Meeting
[Andreas Prlic]](https://image.slidesharecdn.com/sparc0314-140302074519-phpapp01/85/Where-is-Open-Going-29-320.jpg)















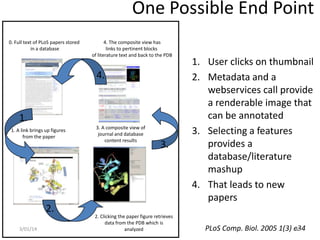




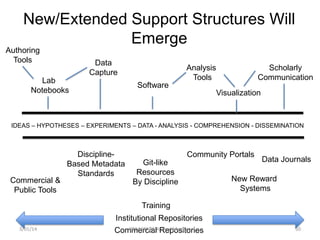
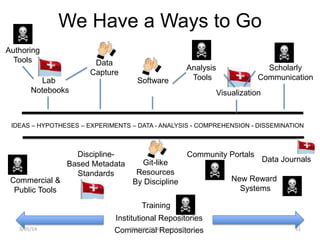



This document discusses where open science is headed and provides one perspective on this issue. It notes that the answer depends on who you ask and then outlines the speaker's background and bias as being from biomedicine and an advocate for open science. It asks what the endpoint of open science should be and discusses some implications of the democratization of science, such as more scrutiny, new types of rewards, and removing artificial boundaries. The speaker then provides some personal examples to illustrate these implications.






















































































