Download as PDF, PPTX
























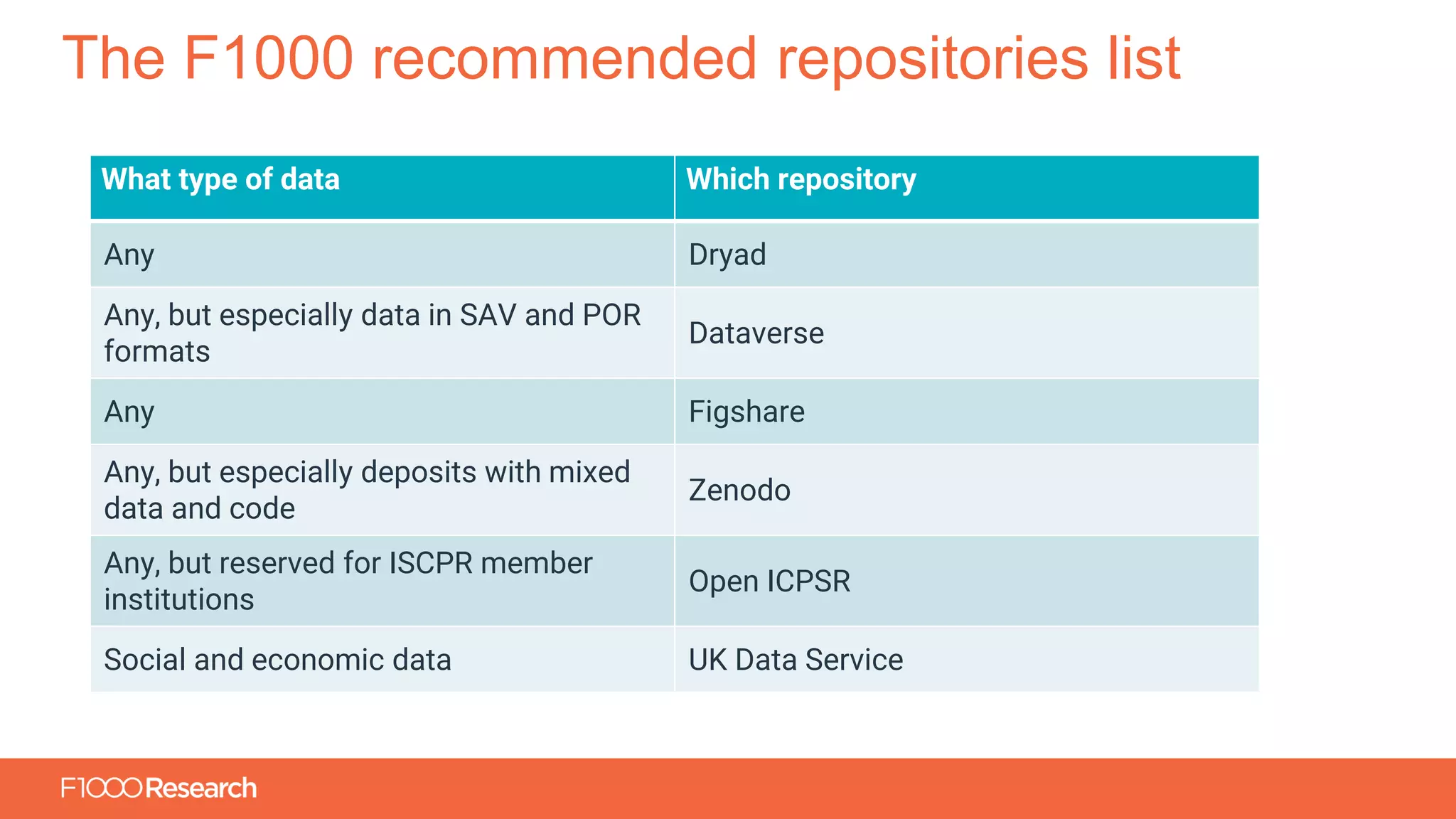
















The document outlines the move of MedEdPublish to a new platform aimed at enhancing transparency and sharing of medical education research data. It emphasizes the importance of an open data policy, where articles must include citations to data repositories and details of software used, thereby allowing for replication and further analysis of studies. Key points cover the challenges of data sharing, ethical considerations, and best practices for anonymizing sensitive data, ultimately supporting an increased credibility and visibility in medical research.



































































