More Related Content

PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料) 
PPTX
ファントム異常を排除する高速なトランザクション処理向けインデックス 
PDF
分散トレーシング技術について(Open tracingやjaeger) 
PDF
自律型データベース Oracle Autonomous Database 最新情報 
PDF
Yahoo! JAPANにおけるApache Cassandraへの取り組み 
PPTX
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料) 
PDF
Data persistency (draco, cygnus, sth comet, quantum leap) 
PPTX
トランザクションをSerializableにする4つの方法 What's hot

PDF
pgvectorを使ってChatGPTとPostgreSQLを連携してみよう!(PostgreSQL Conference Japan 2023 発表資料) 
PDF

PDF

PPTX
Oracleのソース・ターゲットエンドポイントとしての利用 
PPTX
限界性能試験を自動化するOperatorを作ってみた(Kubernetes Novice Tokyo #14 発表資料) 
PDF
データレイクを基盤としたAWS上での機械学習サービス構築 
PPTX
OCI GoldenGate Overview 2021年4月版 
PDF
PostgreSQLのトラブルシューティング@第5回中国地方DB勉強会 
PPTX
モノリスからマイクロサービスへの移行 ~ストラングラーパターンの検証~(Spring Fest 2020講演資料) 
PDF

PPTX
大規模データ活用向けストレージレイヤソフトのこれまでとこれから(NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05) 
PPT

PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料) 
PPT

PDF

PDF
NetflixにおけるPresto/Spark活用事例 
PDF

PDF
3分でわかるAzureでのService Principal 
PDF
単なるキャッシュじゃないよ!?infinispanの紹介 
PPTX
Elastic stack Presentation Similar to Spannerをrestでつかってみた

PDF
Spring Data RESTを利用したAPIの設計と、作り直しまでの道のり 
PDF
アプリ開発者、DB 管理者視点での Cloud Spanner 活用方法 | 第 10 回 Google Cloud INSIDE Games & App... 
PDF
![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[GKE & Spanner 勉強会] Cloud Spanner の技術概要 
PDF
元OracleMasterPlatinumがCloudSpanner触ってみた 
PDF
国内Cloud spanner初事例!「迎車料金無し!新感覚タクシーアプリ「フルクル」」 ![[db analytics showcase Sapporo 2018] B13 Cloud Spanner の裏側〜解析からベストプラクティスへ〜](https://cdn.slidesharecdn.com/ss_thumbnails/dbassapporo2018b13-180626013006-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[db analytics showcase Sapporo 2018] B13 Cloud Spanner の裏側〜解析からベストプラクティスへ〜 Spannerをrestでつかってみた
- 1.
- 2.
自己紹介
@ExistMikan ・会津大学卒 (2012年)
→IT系の猛者が集う大学
・上記大学発ベンチャー企業に就職
→ スマートフォンアプリ(Android/iOS)の開発に従事
・現職場(吉積情報株式会社)に転職 (今年)
→ GCP中心の開発へ
・先週、パパエンジニアと化す
寝不足多幸感 VS
大分前から放置気味の
アカウント(´・ω・`)
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
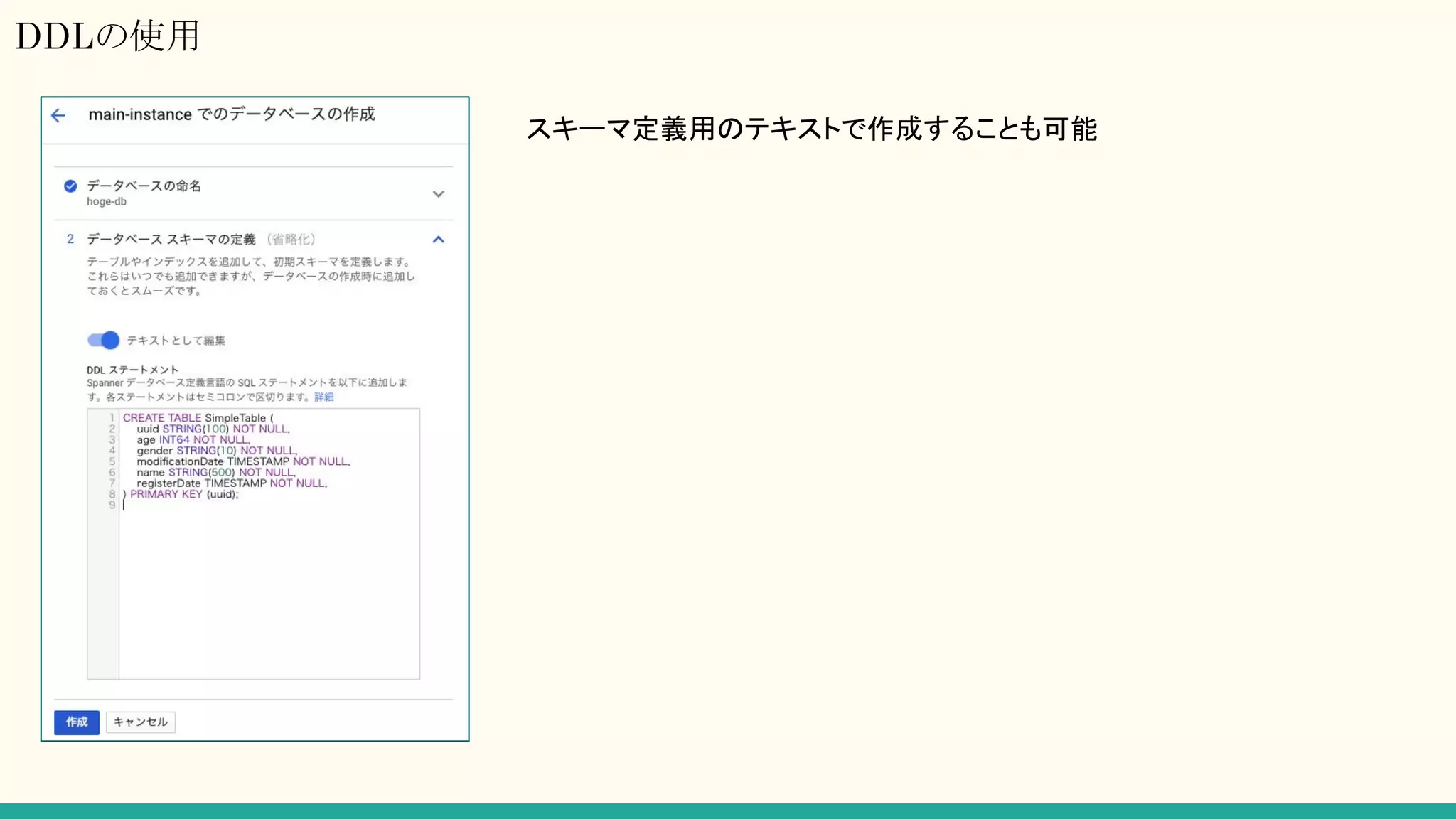
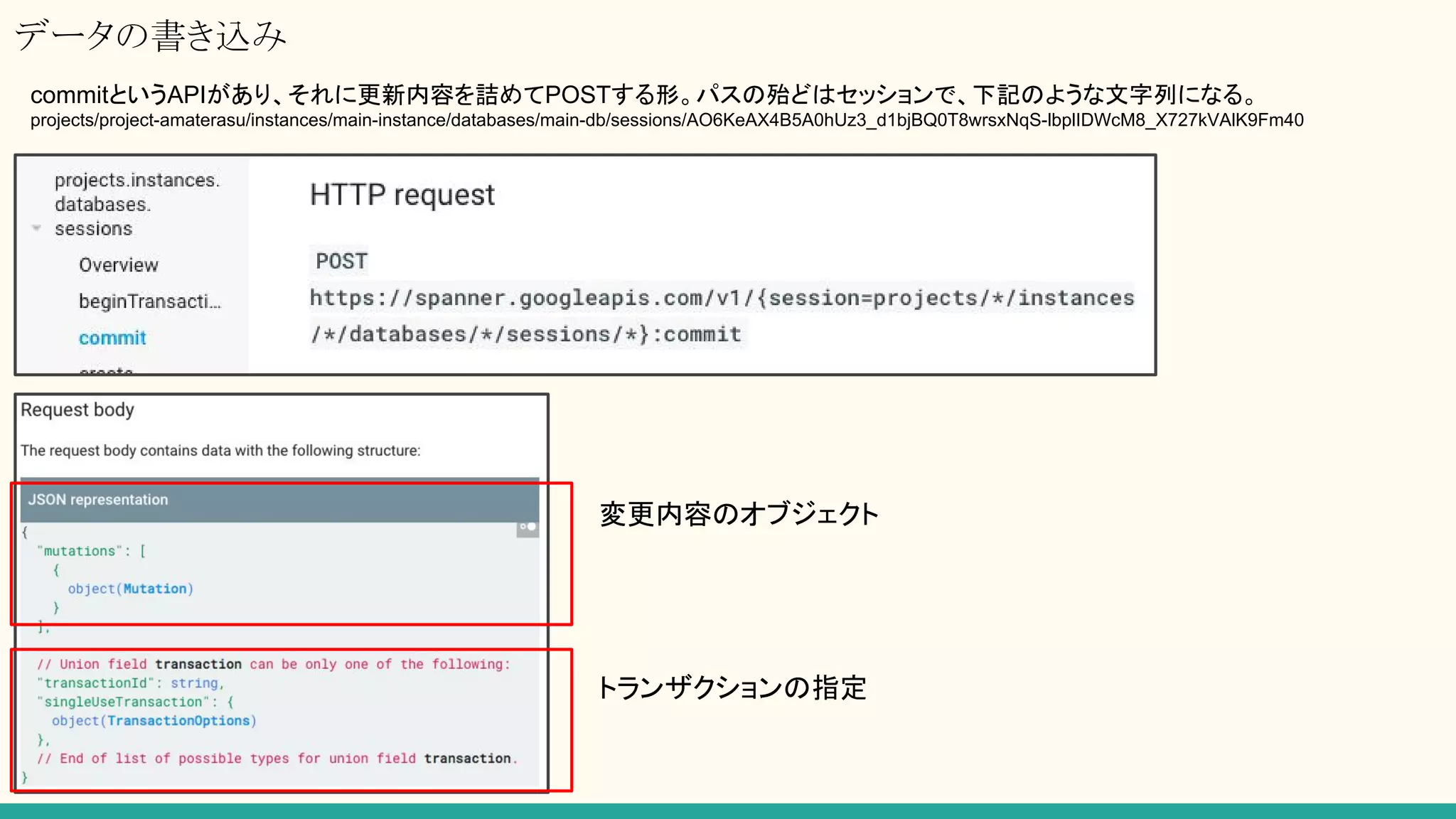
RESTでアクセス!
なぜREST?
→ GAE +SE(Java)の環境で、DBをDataStoreからSpannerに切り替えたくなった
→ しかし、GAE + SEではgRPC系ライブラリが提供されていない
→ RESTでやるしかない
GoではGAE + SEでもライブラリが
動作するらしい。。
Goのライブラリでは
Socket APIを裏で使っているため、
OverQuotaに注意
つらい
RESTでやる場合はURL Fetchの
OverQuotaに注意。
- 13.
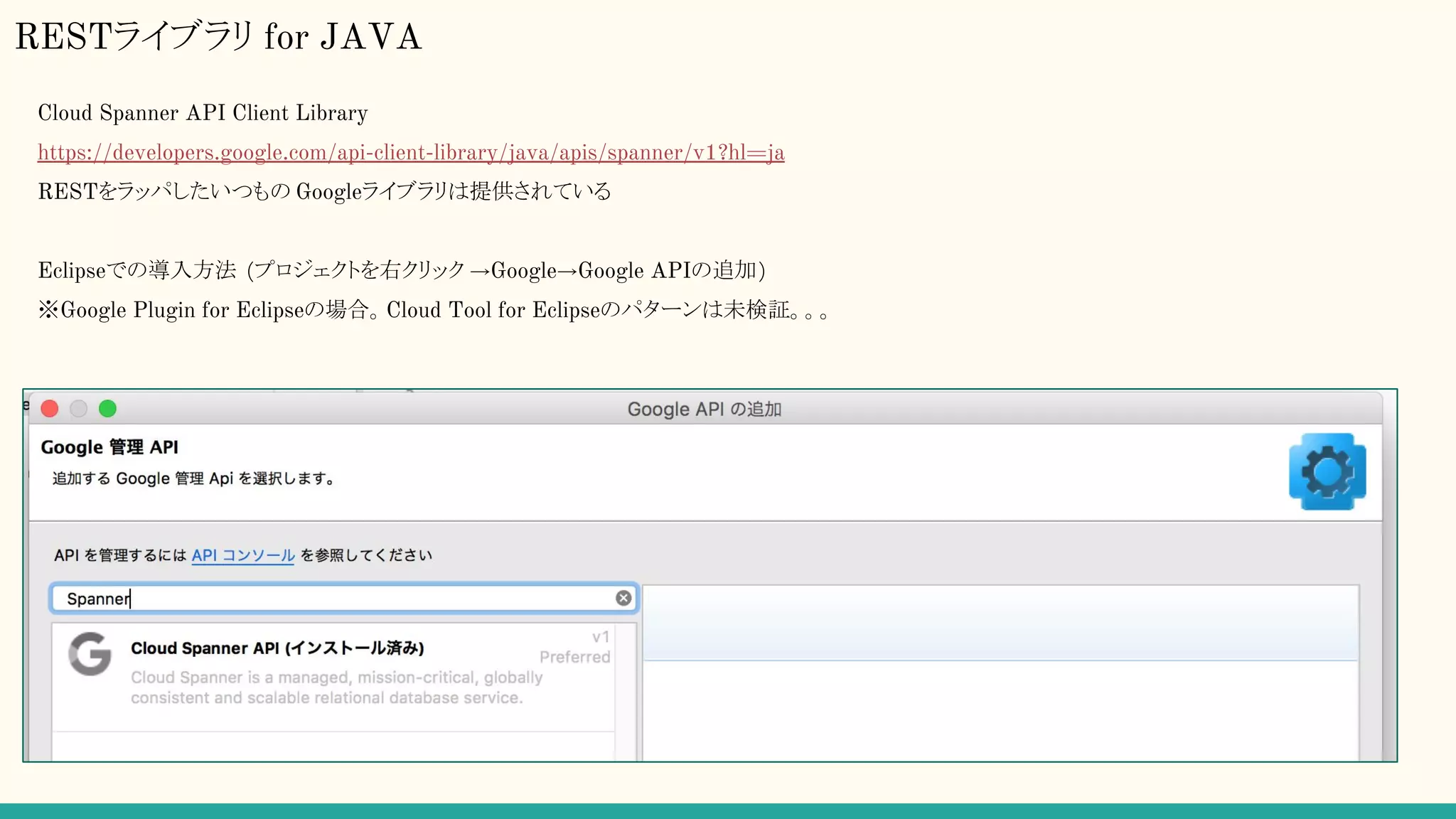
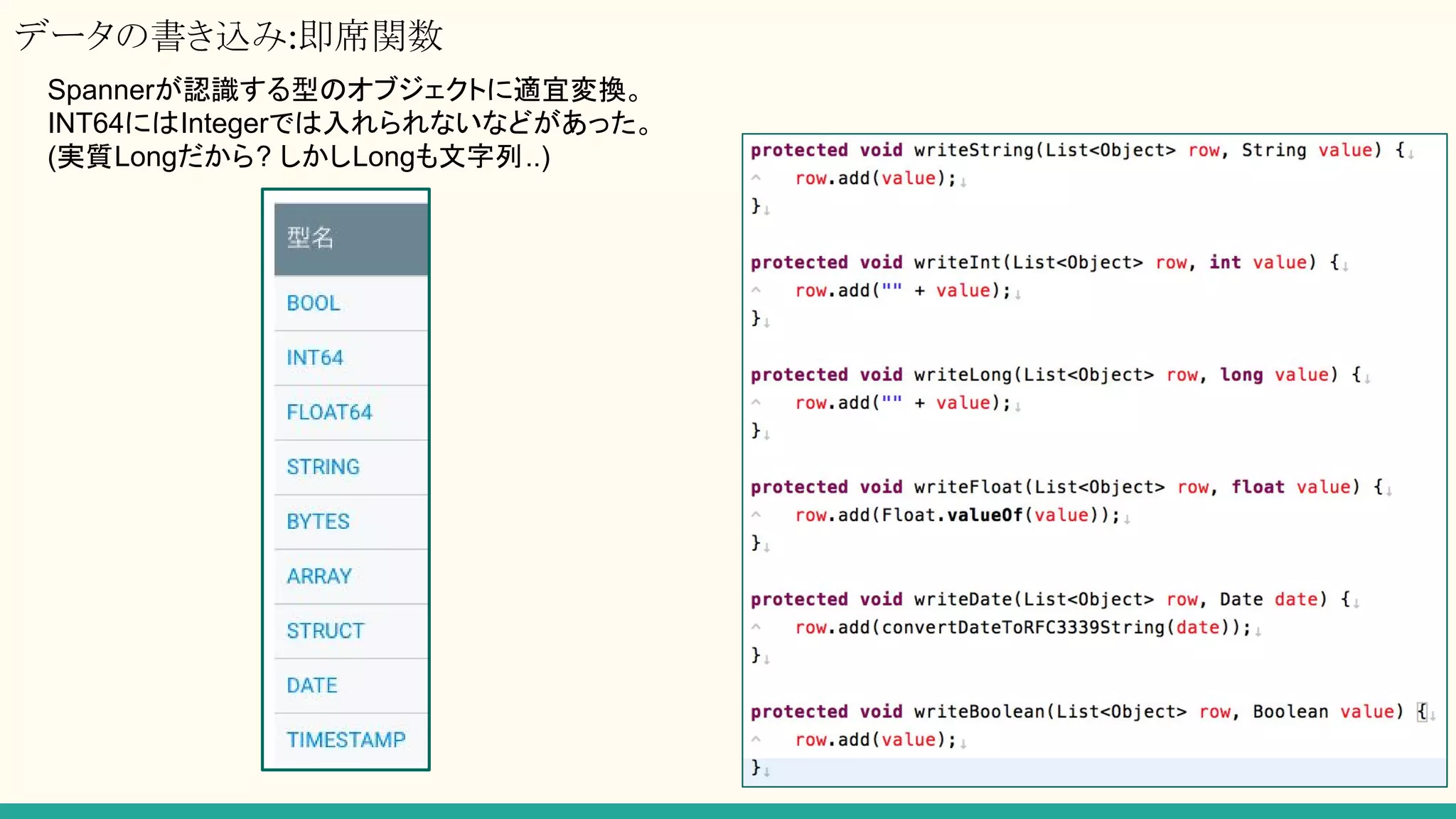
RESTライブラリ for JAVA
CloudSpanner API Client Library
https://developers.google.com/api-client-library/java/apis/spanner/v1?hl=ja
RESTをラッパしたいつもの Googleライブラリは提供されている
Eclipseでの導入方法 (プロジェクトを右クリック →Google→Google APIの追加)
※Google Plugin for Eclipseの場合。Cloud Tool for Eclipseのパターンは未検証。。。
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
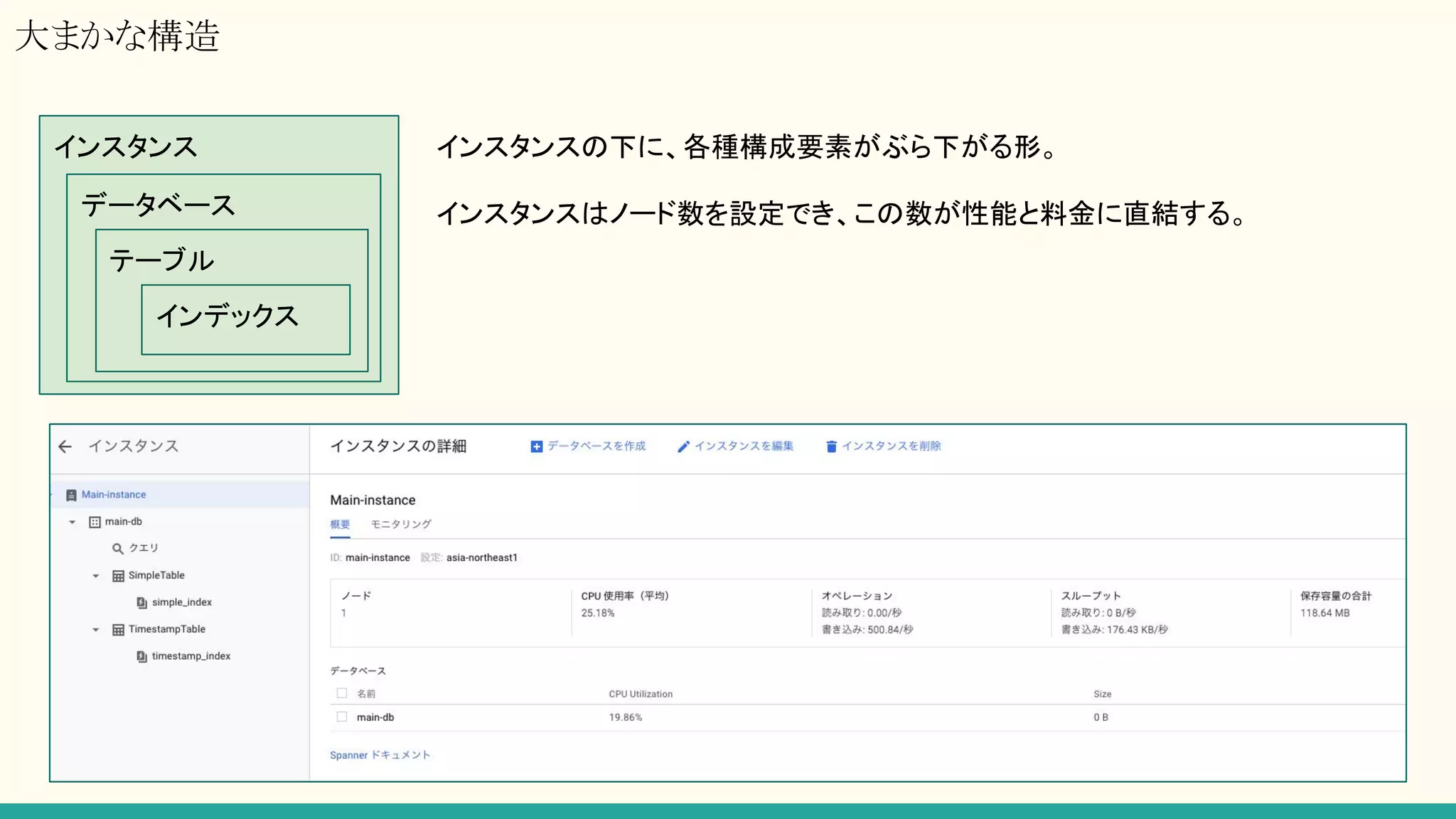
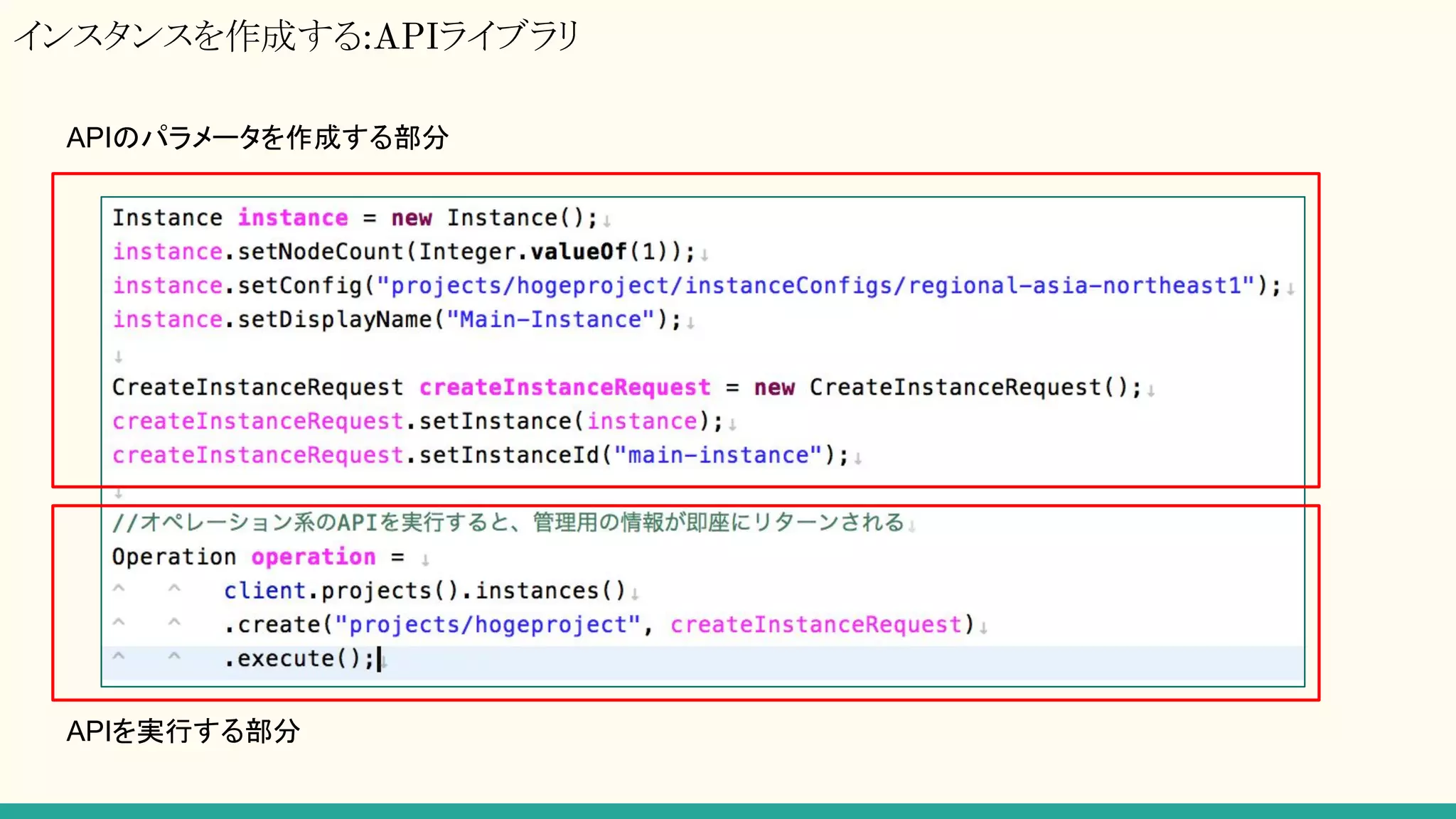
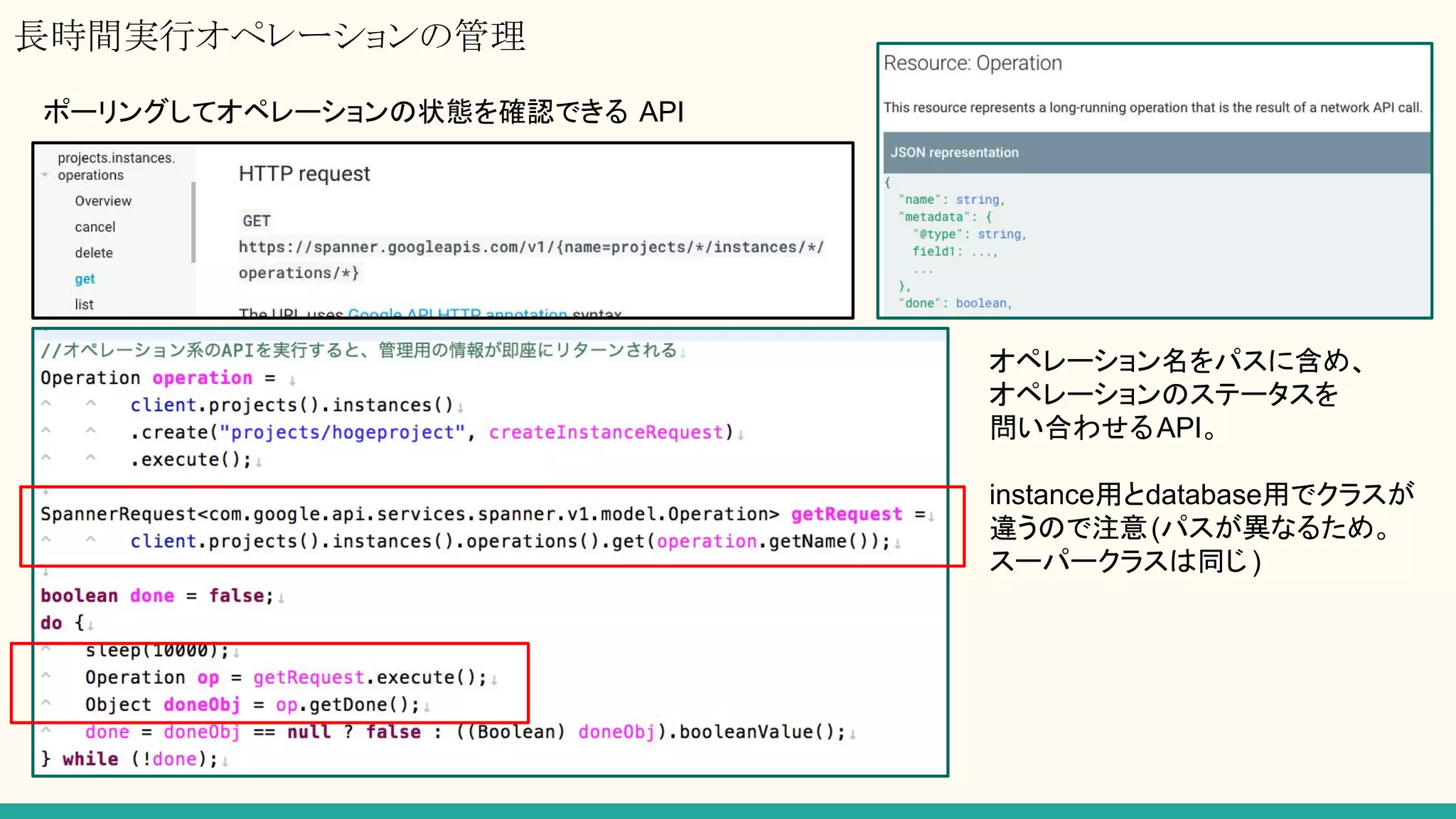
セッション管理
読み書きするために必ず必要になる、Cloud Spanner データベースサービスとの通信チャネル。
Client Libraryには、Channnelという概念があり、そこでセッションプールのような管理がされているようだが
RESTでは該当する概念無し。
生成のためのレイテンシがそれなりにかかる(100ms~1000msくらい?)
→ リクエストするたびに生成/削除をやるのはコストが高い
毎回やりたくな
い!
そうだ、
キャッシュしよう
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
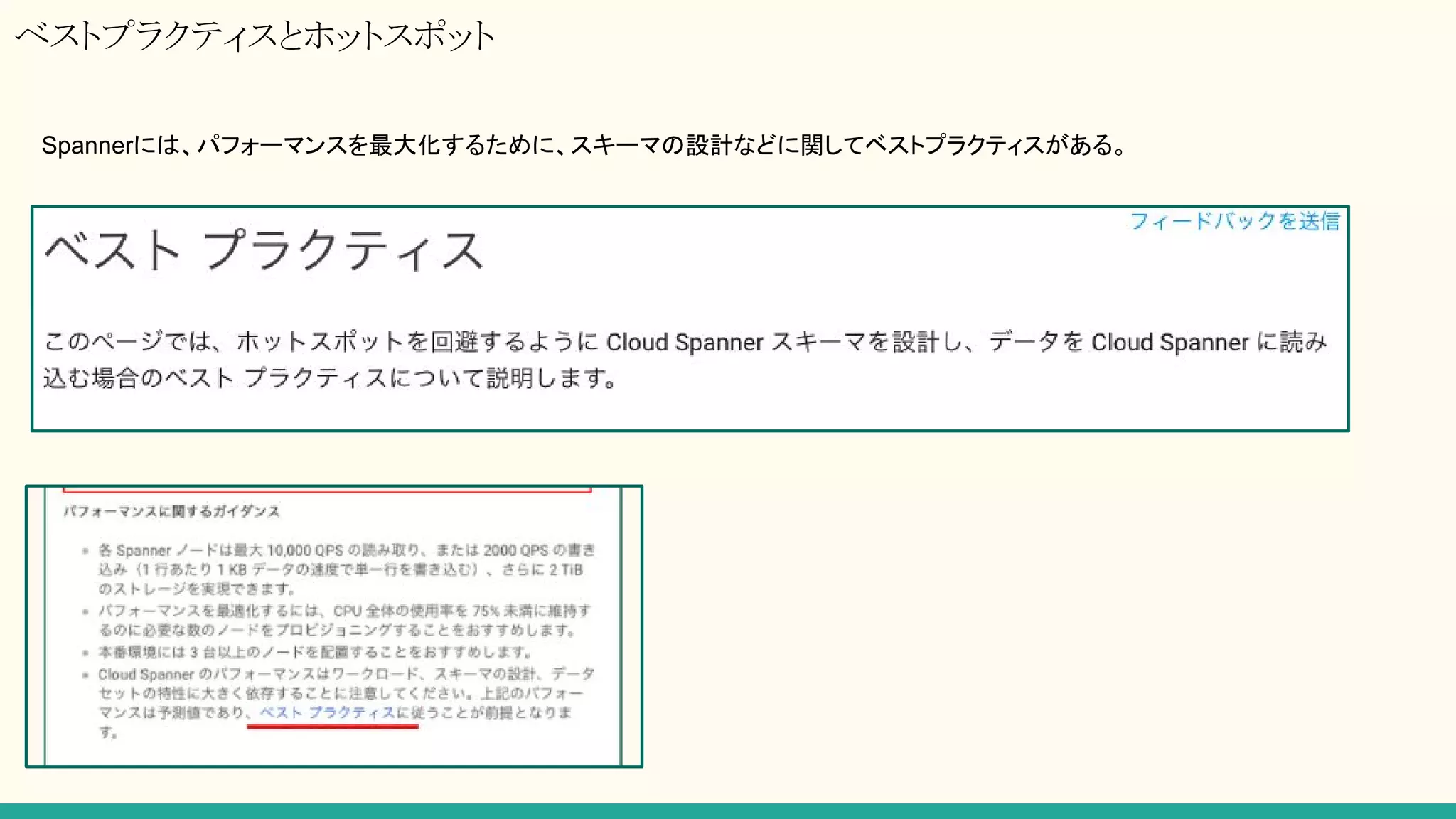
超実践 Cloud Spanner設計講座
https://www.slideshare.net/HammoudiSamir/cloud-spanner-78081604
Spannerユーザ必読。ノードやスプリットの関係についても言及されています。
普通のエンジニアが【Cloud Spanner】使ってみた
https://www.slideshare.net/ssuserc49633/20170822-cloud-spanner
こちらも参考情報盛りだくさんです。
参考資料
- 45.
- 46.