Downloaded 120 times













![Embedded Edge Arrays
• Storing connections with user (popular choice)
Most compact form
Efficient for reads
• However….
– User documents grow
– Upper limit on degree (document size)
– Difficult to annotate (and index) edge
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"followers" : [ "jsr", "ian"],
"following" : [ "jsr", "pete"]
}](https://image.slidesharecdn.com/socialitept2-140724104718-phpapp01/85/Socialite-the-Open-Source-Status-Feed-Part-2-Managing-the-Social-Graph-16-320.jpg)
![Embedded Edge Arrays
• Creating Rich Graph Information
– Can become cumbersome
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"friends" : [
{"uid" : "jsr", "grp" : "school"},
{"uid" : "ian", "grp" : "work"} ]
}
{
"_id" : "djw",
"fullname" : "Darren Wood",
"country" : "Australia",
"friends" : [ "jsr", "ian"],
"group" : [ ”school", ”work"]
}](https://image.slidesharecdn.com/socialitept2-140724104718-phpapp01/85/Socialite-the-Open-Source-Status-Feed-Part-2-Managing-the-Social-Graph-17-320.jpg)
















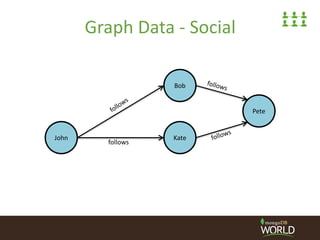
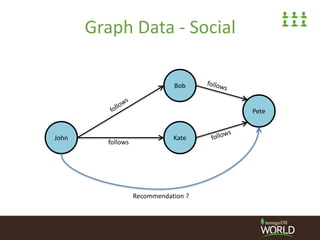
The document discusses building a social platform using MongoDB, focusing on managing the social graph and user interactions. It covers various storage options for user connections, performance considerations, and indexing strategies for managing follower relationships. Key topics include the use of edge collections, operational issues with updates, and approaches for efficiently querying follower data.
























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)






























