Downloaded 12 times














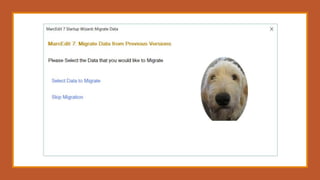













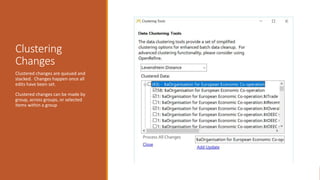








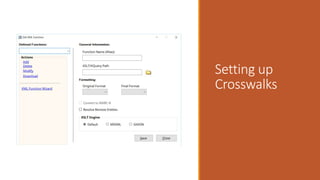




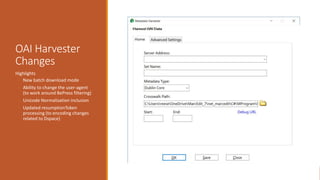







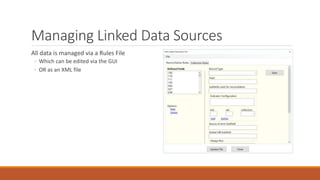















![How we use Regular Expressions in
MarcEdit
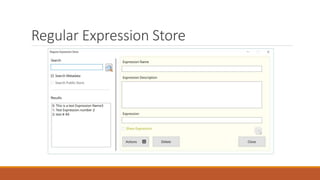
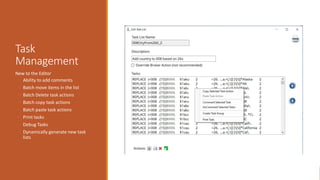
Your most important parts of the regular expression language are:
1. Character escapes: dwrn$
2. Character Classes [] & [^]
3. Grouping Elements ()
4. Anchors: ^$
5. Quantifiers: *?+{#}
6. Substitutions: $#](https://image.slidesharecdn.com/nasig2018-180718190516/85/Slides-from-the-NASIG-2018-Preconference-117-320.jpg)

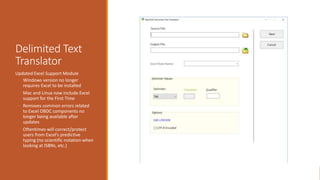
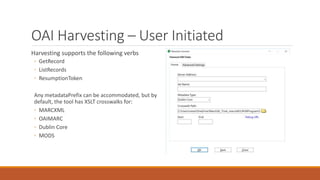
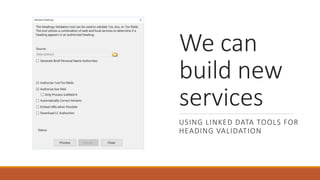
![Examples 1
◦ Add a period to the 500 if it is missing
◦ Find What: (=500 ..)(.*[^W]$)
◦ Replace With: $1$2.
Explanation:
◦ (=500 ..)
◦ Searches for the 500 field. We leave two blanks because there are always 2 blank characters as part of the mnemonic format. The
two periods which stand for any character. If we want to search for exact indicators, you’d place those values rather than the
periods.
◦ (.*[^W.]$)
◦ Take any characters, and match on a field where the last character in the field isn’t a period.](https://image.slidesharecdn.com/nasig2018-180718190516/85/Slides-from-the-NASIG-2018-Preconference-119-320.jpg)
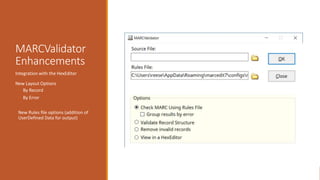
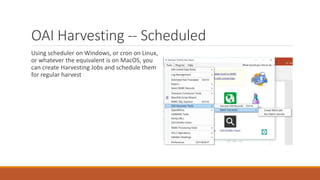
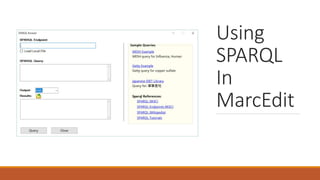
![Examples 2
Add online resource information to the 300 field
Example:
◦ Change: 300 $a 32 p.
◦ To: 300 $a1 online resource (32 p.)
Explanation:
◦ (=500 ..)
◦ Searches for the 500 field. We leave two blanks because there are always 2 blank characters as part of the mnemonic format. The
two periods which stand for any character. If we want to search for exact indicators, you’d place those values rather than the
periods.
◦ (?<one>$a)([^$]*)
◦ Capture the $a and then all data in the subfield until you get to the next subfield (if there is one)](https://image.slidesharecdn.com/nasig2018-180718190516/85/Slides-from-the-NASIG-2018-Preconference-120-320.jpg)
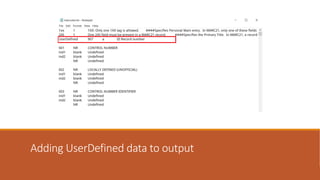
![Example 3
Split the 856 into two fields, breaking on the $u.
◦ Find What: (=856.{4})($u.*[^$])($u.*)
◦ (=856.{4})
◦ Matches the 856 field
◦ ($u.*[^$])
◦ Match $u, but stop at the end of the subfield
◦ ($u.*)
◦ Match reminder of field
◦ Replace With: $1$2n=856 41$3](https://image.slidesharecdn.com/nasig2018-180718190516/85/Slides-from-the-NASIG-2018-Preconference-121-320.jpg)

![Example (lcase)
Find the 500 with all upper case characters and convert the case of all values but the first letter
in the sentence to lower case.
◦ Find What: (=500.{4})($a.)([A-Z .]*)
◦ Replace With: $1$2lcase($3)](https://image.slidesharecdn.com/nasig2018-180718190516/85/Slides-from-the-NASIG-2018-Preconference-123-320.jpg)


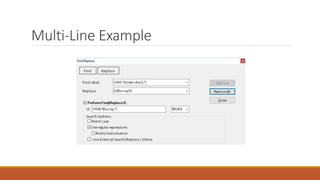



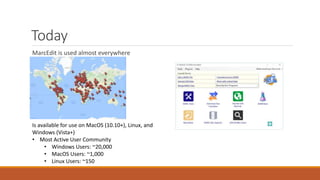
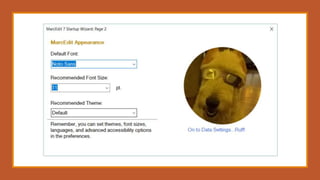
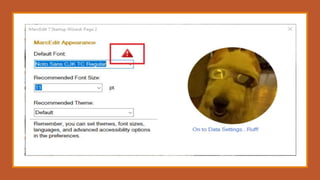
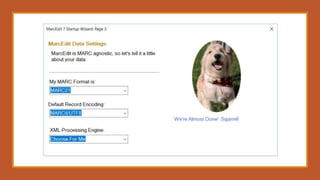
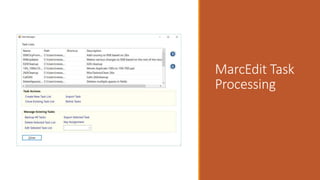
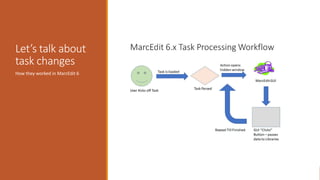
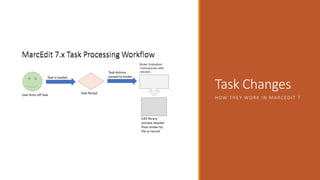
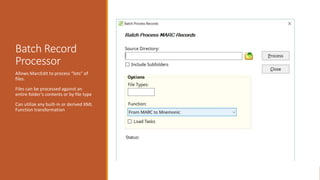
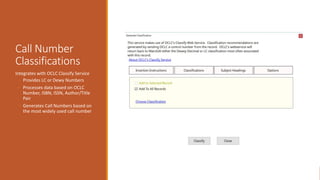
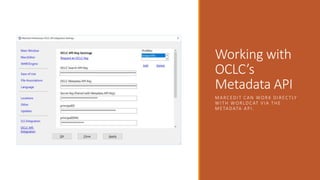
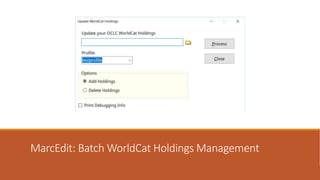
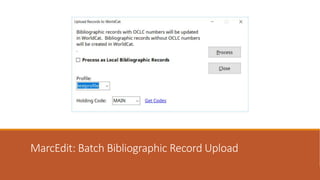
This document provides an overview of a day-long workshop on the current and future features of MarcEdit. The workshop will include demonstrations of new MarcEdit 7 features, discussions of changes to MarcEdit 7, and opportunities for participant questions. The schedule includes content sessions in the morning and afternoon with breaks. Topics that participants are interested in learning about include fonts, Unicode processing, RDA processing, automation features, XML processing, regular expressions, and integration opportunities with library systems and OCLC.















































































