Downloaded 17 times





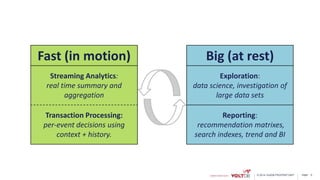



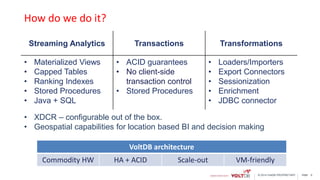






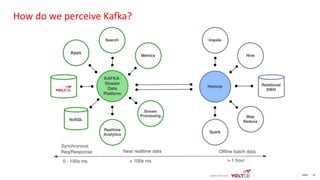

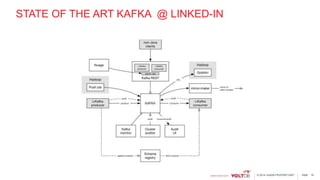

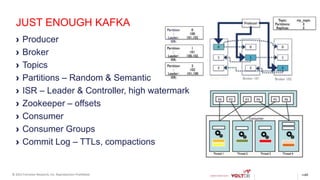














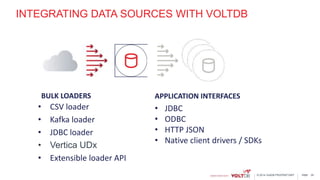
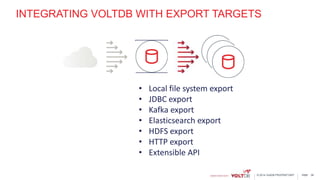
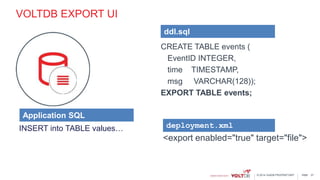
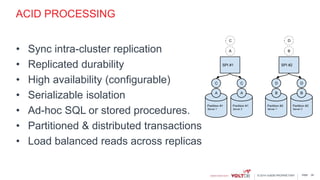
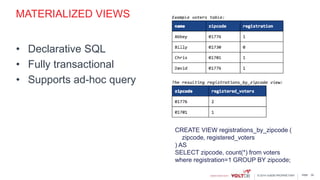
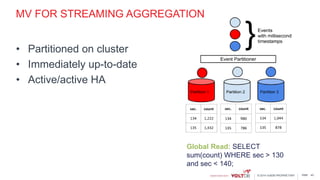

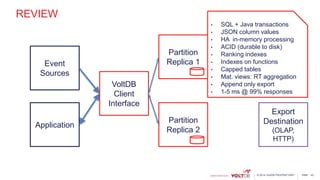











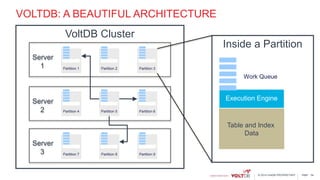

This document discusses using Kafka and VoltDB together for streaming data architectures. It provides an overview of VoltDB as an operational database that can run entirely in-memory at web scale. It describes how VoltDB supports real-time analytics like counters, aggregates, and rankings through features like materialized views. The document also discusses how to configure Kafka producers and consumers to integrate with VoltDB importers and exporters. Using Kafka can simplify streaming data architectures by providing centralized queuing and resiliency while VoltDB supports low-latency transactions and analytics on streaming data.



































![[OracleCode - SF] Distributed caching for your next node.js project](https://cdn.slidesharecdn.com/ss_thumbnails/distributedcachingforyournextnode-170302181006-thumbnail.jpg?width=640&height=640&fit=bounds)































