




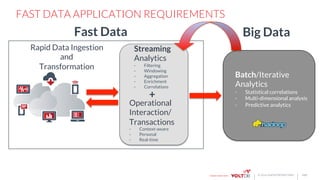
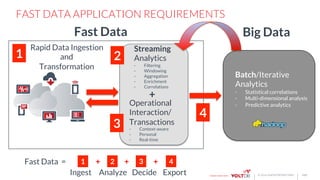

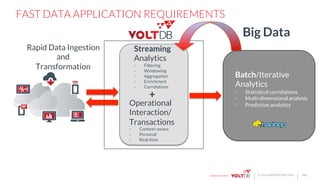




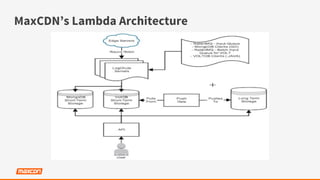











The document discusses the use of VoltDB for building fast data applications, emphasizing its real-time analytics capabilities and operational performance. It compares VoltDB with traditional databases like HBase and Cassandra, highlighting its advantages in multi-row write atomicity and consistent, low-latency processing. The architecture and functionalities are outlined, showcasing the system's ability to handle massive data streams with guaranteed data integrity and minimal support requirements.











































































