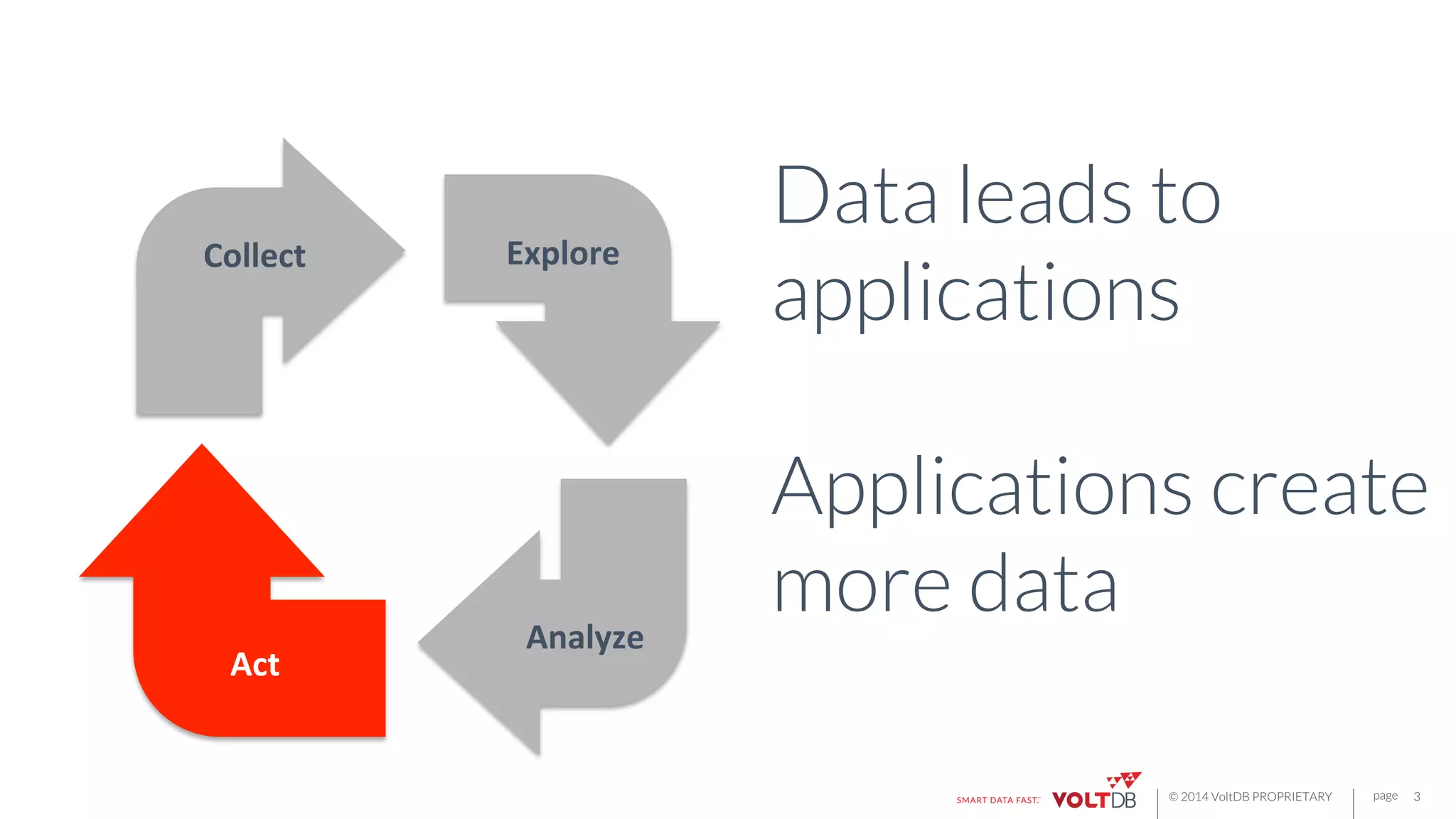
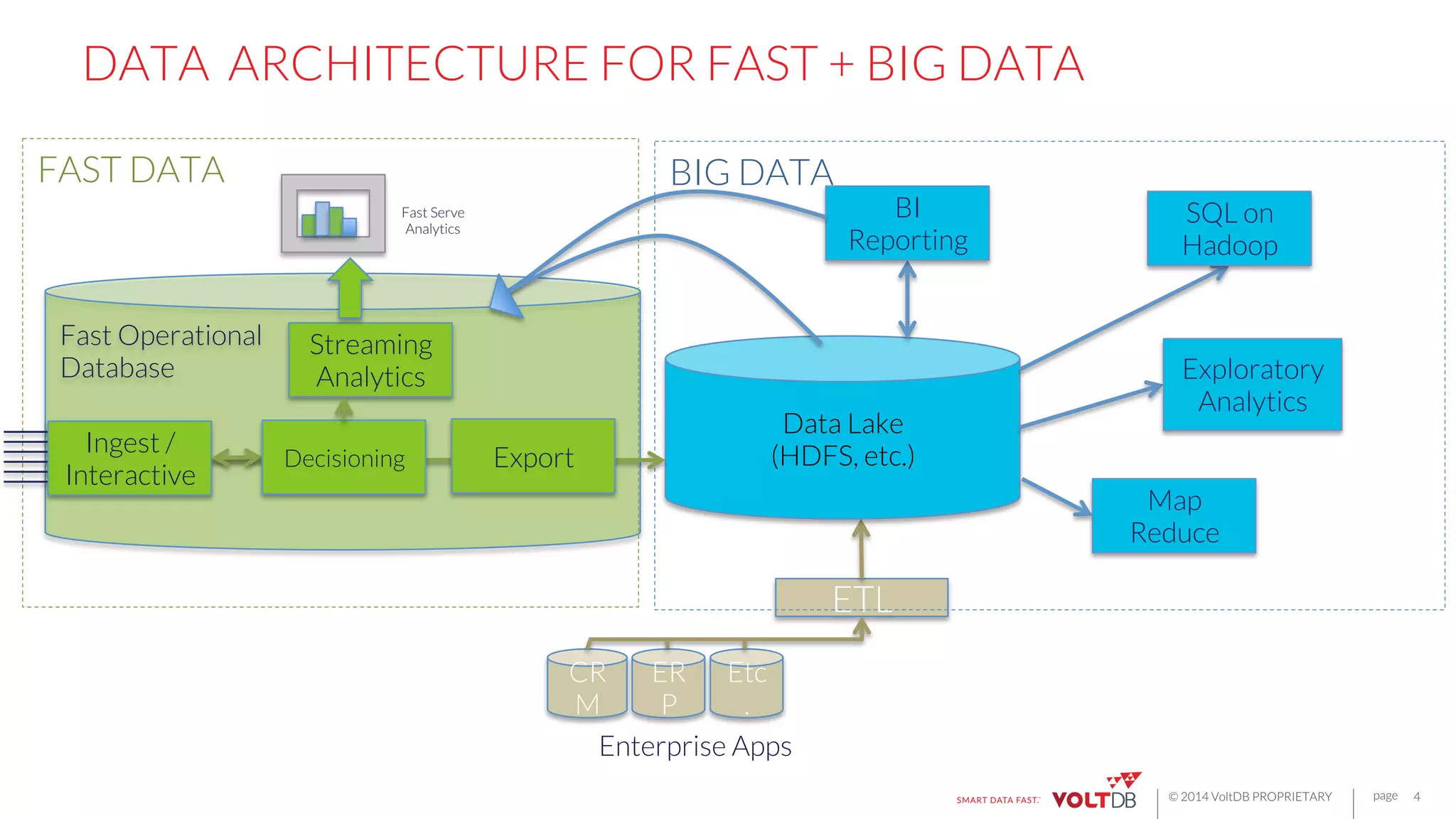
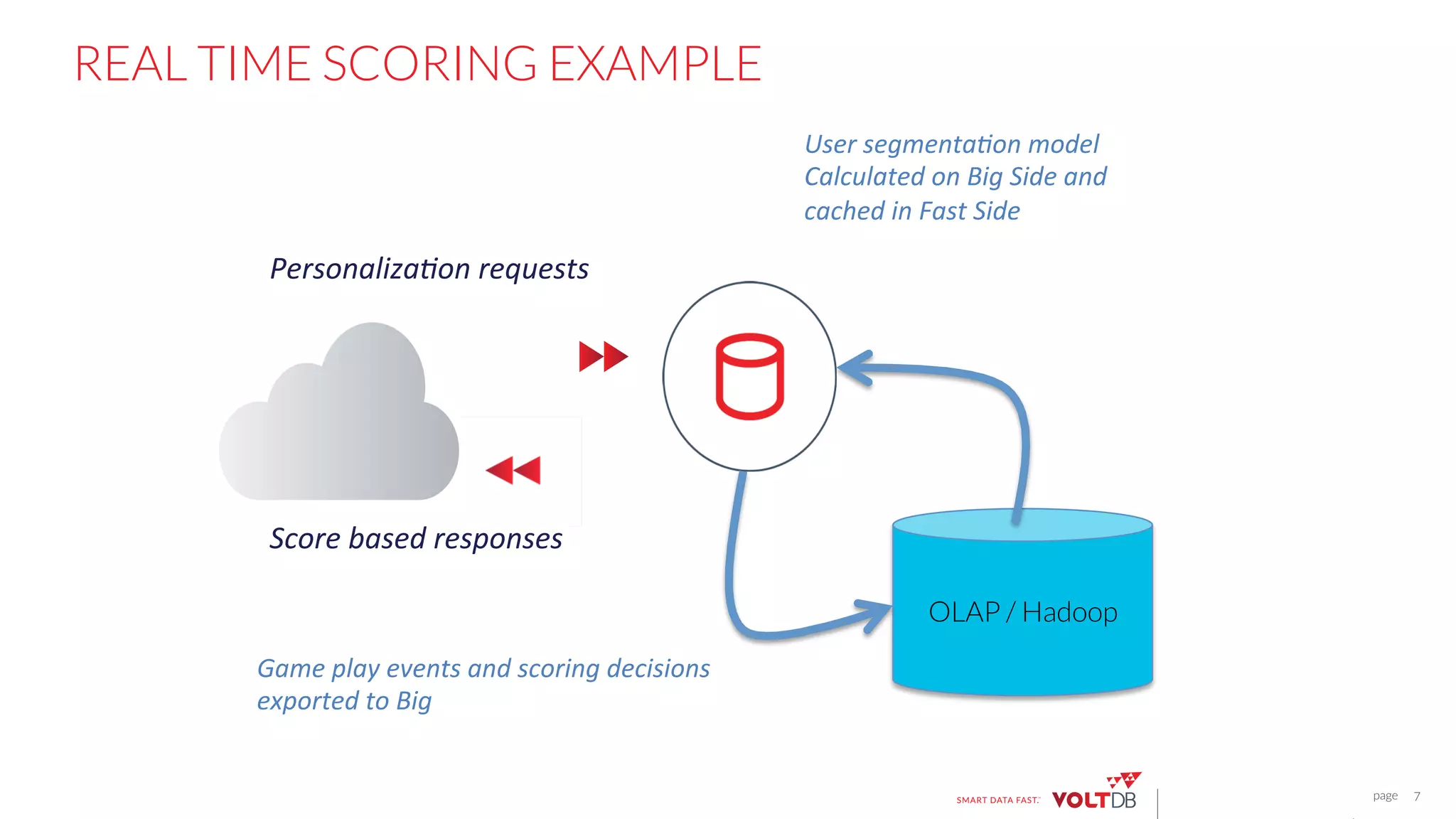
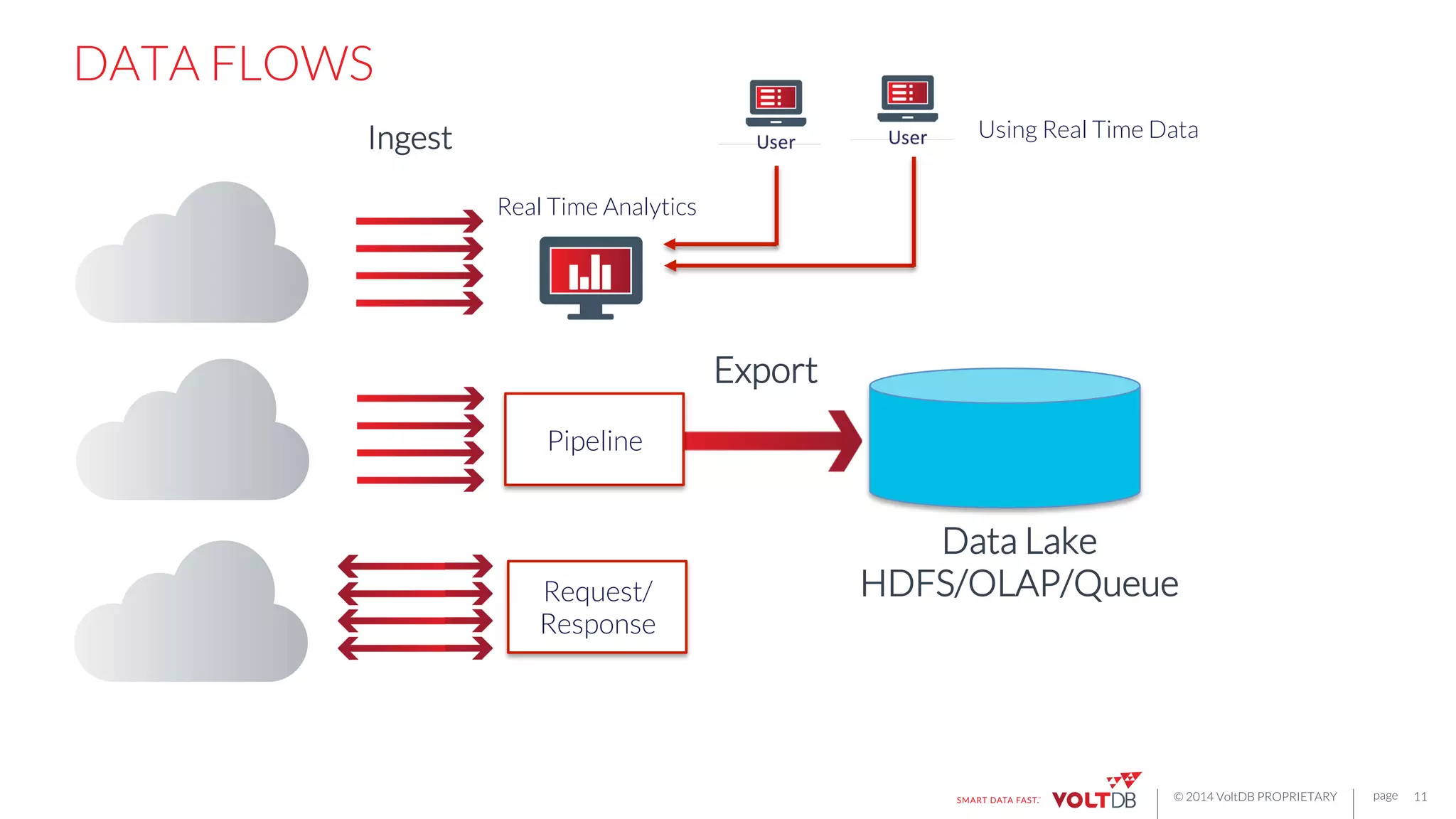
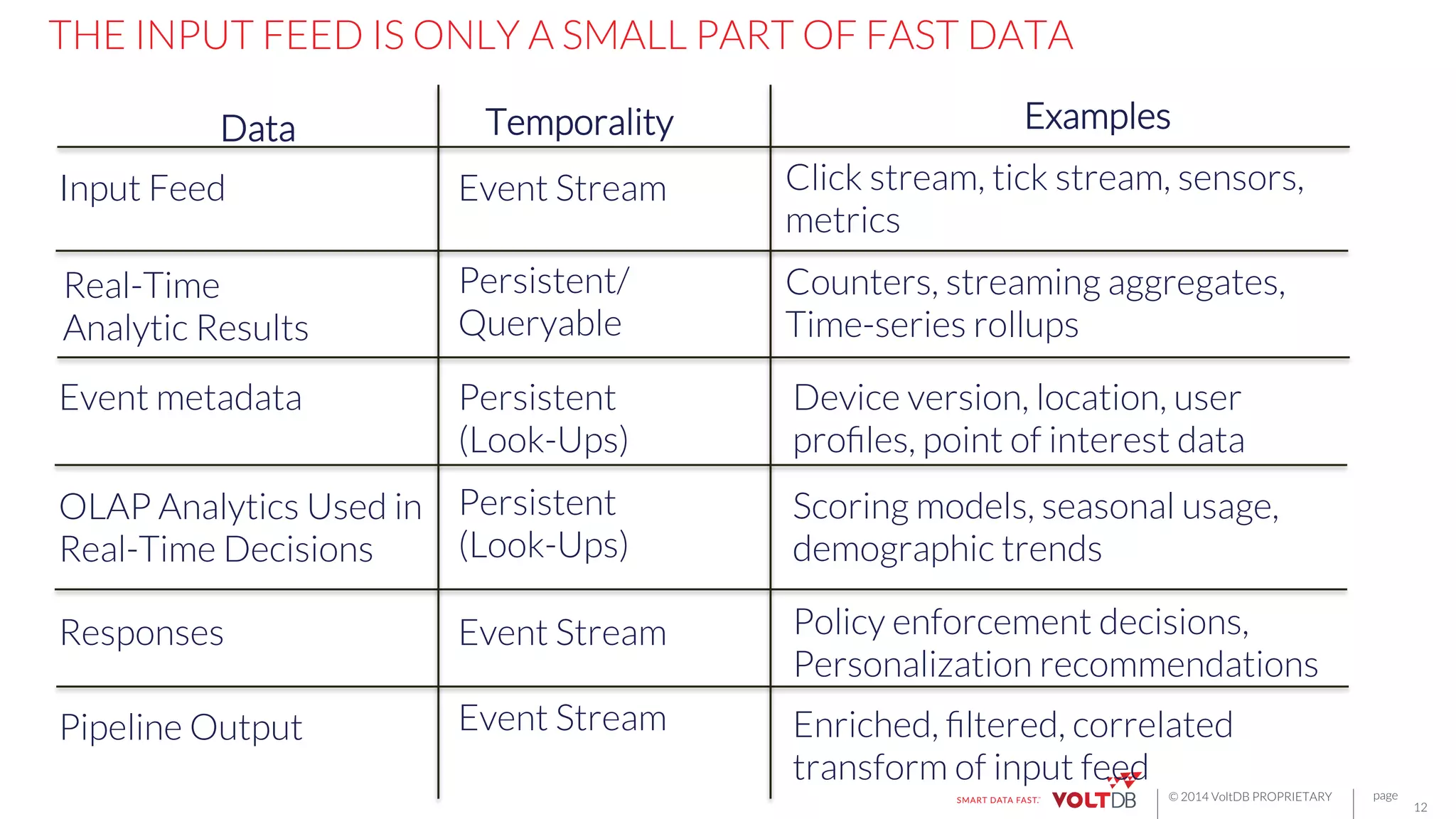
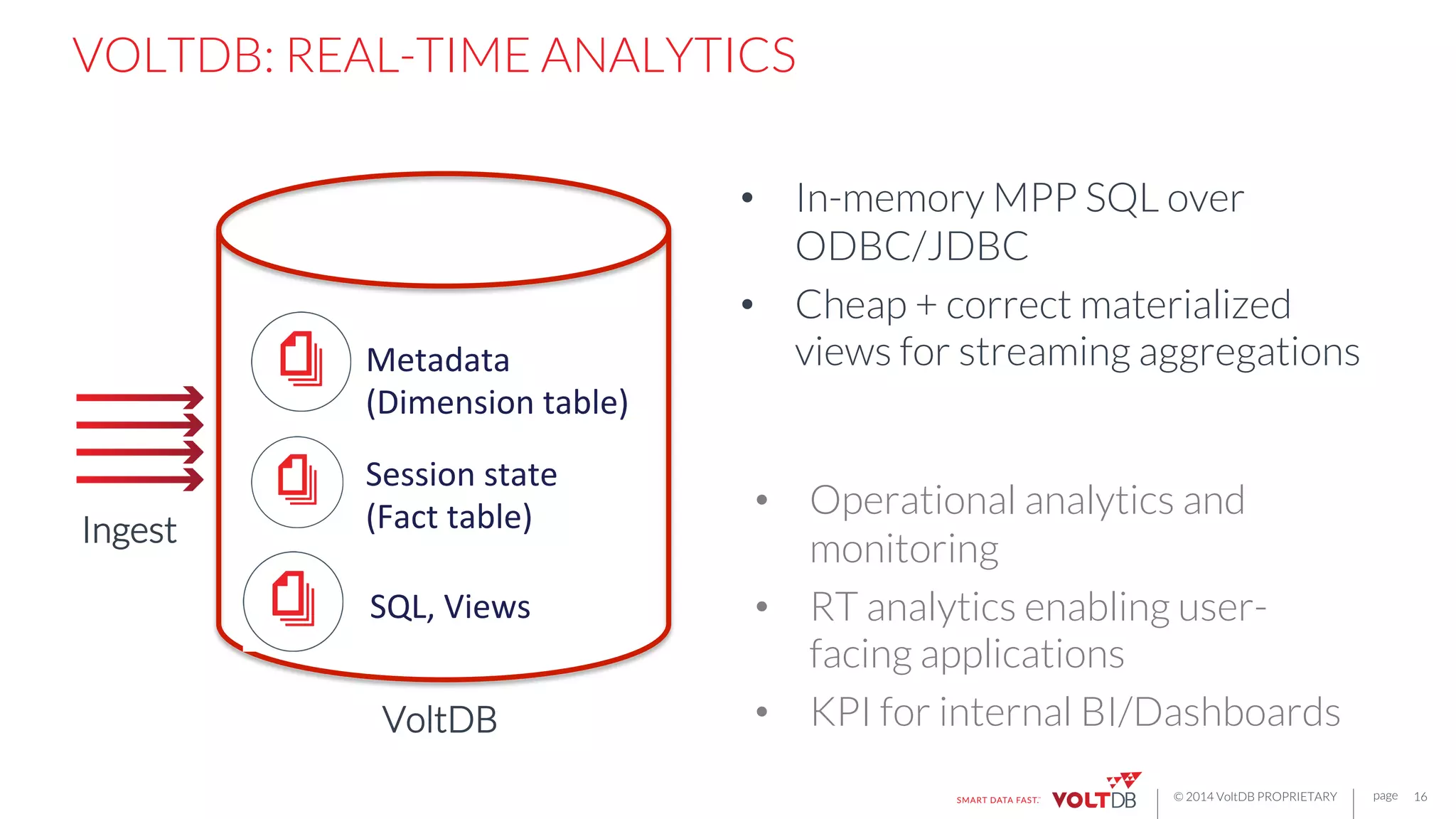
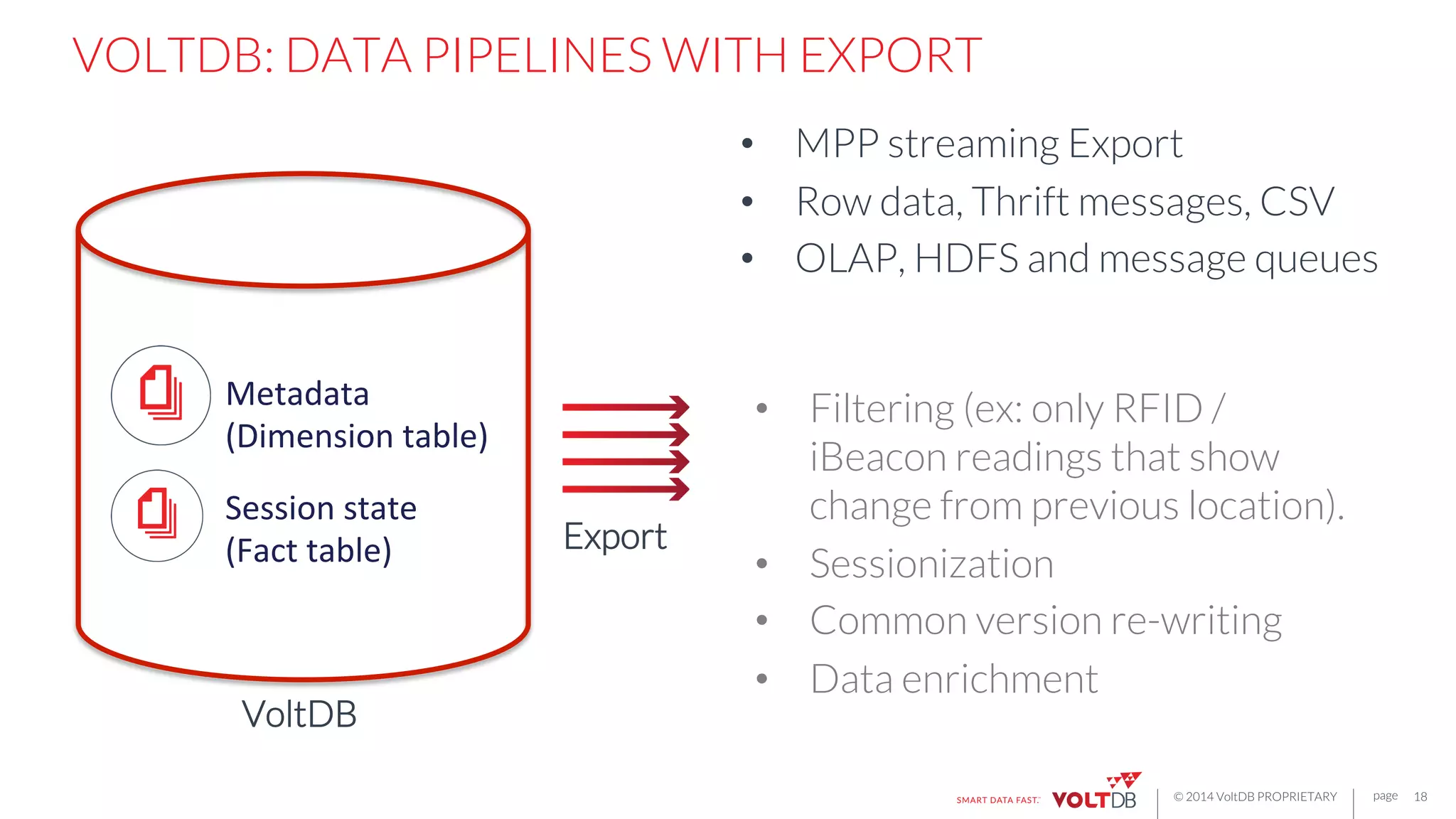
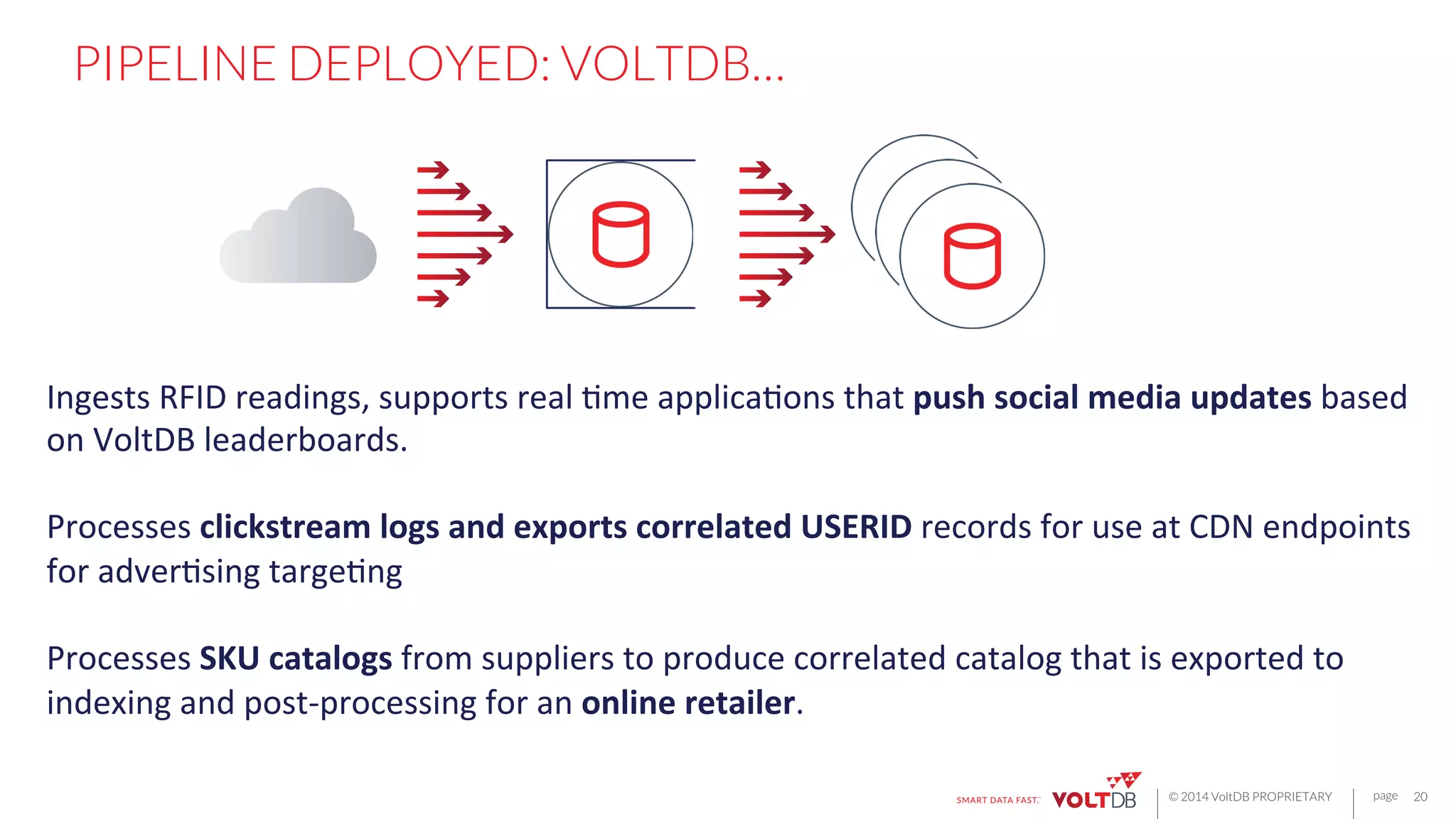
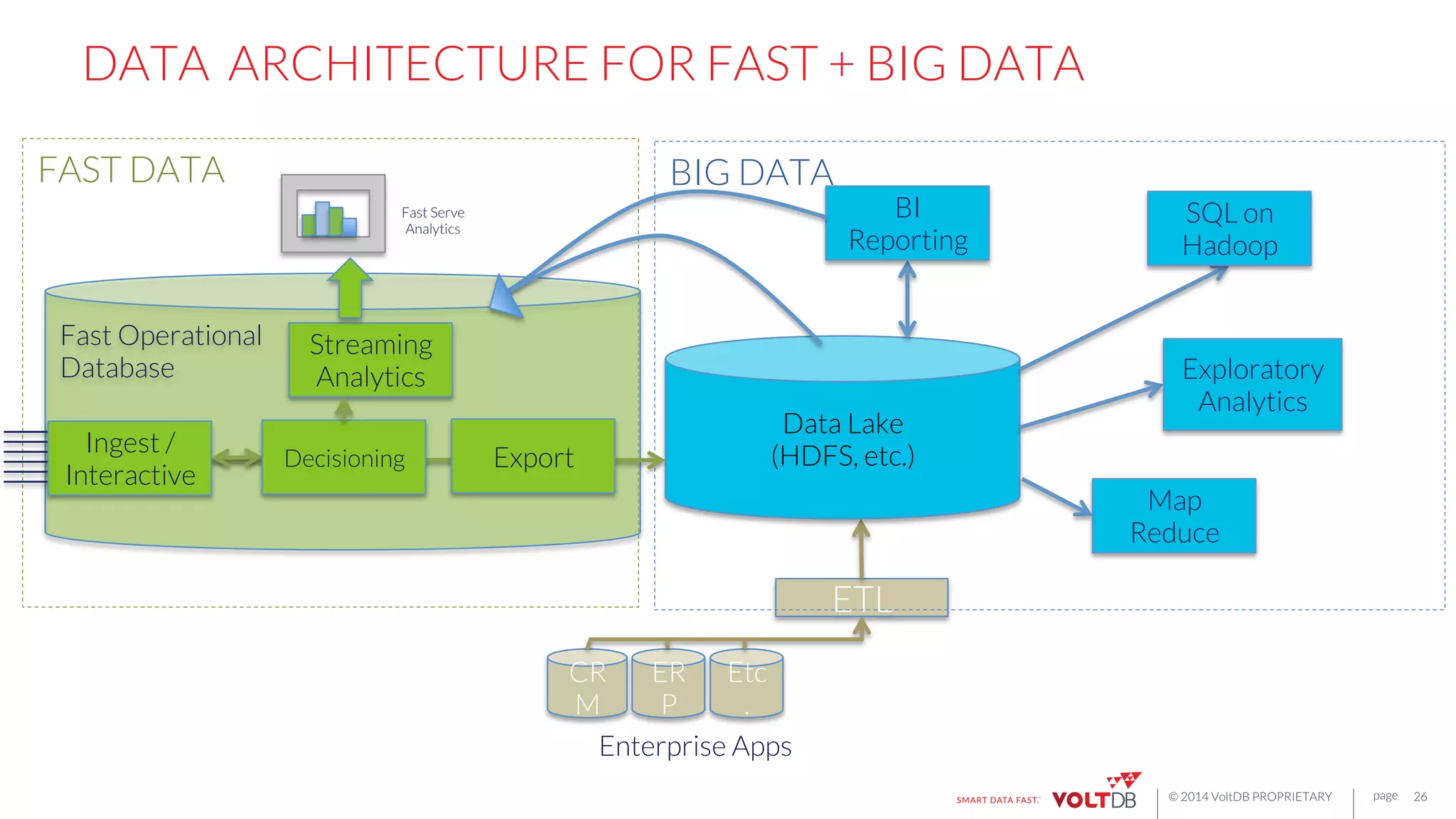
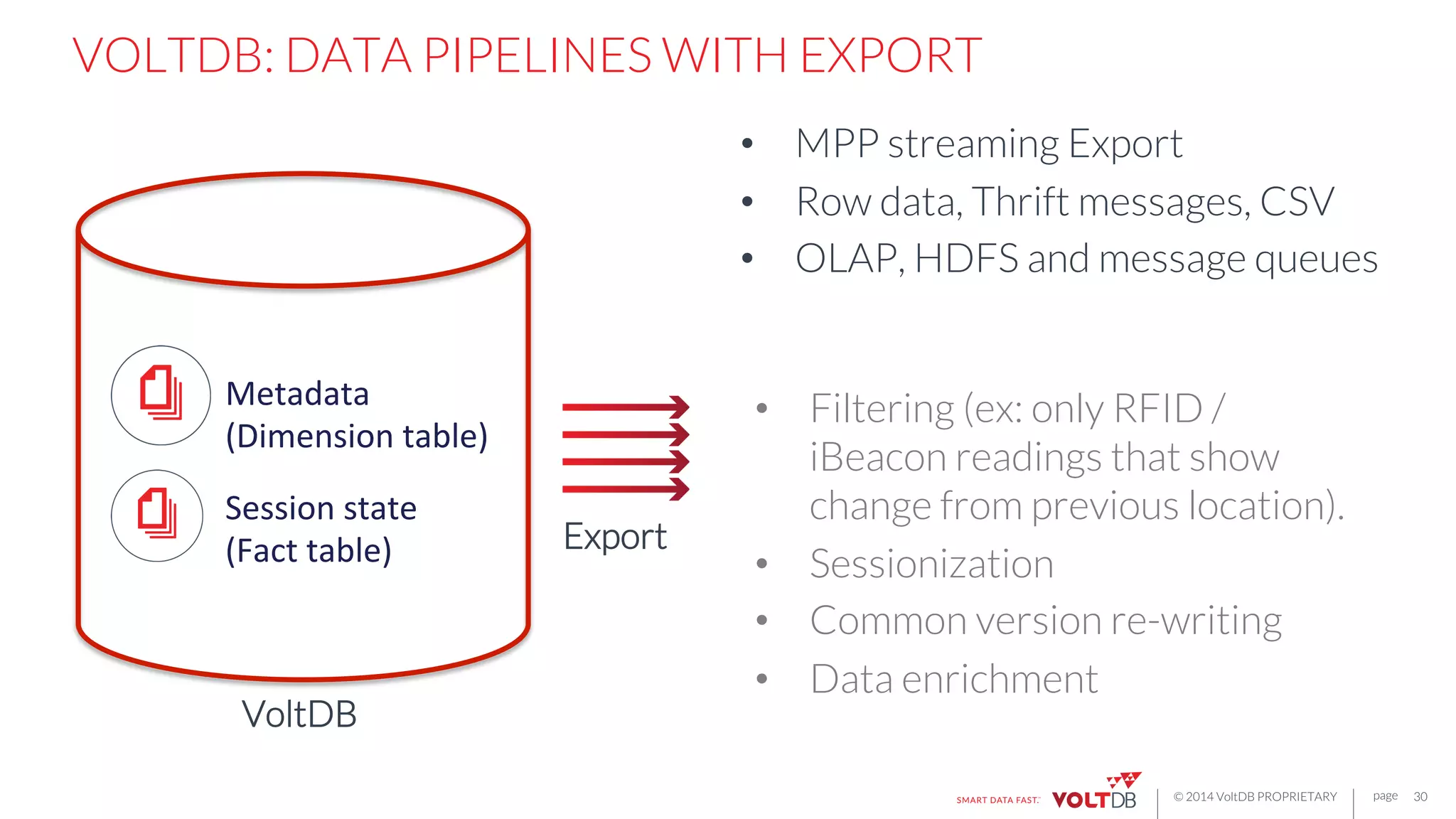
This document discusses building fast data applications with streaming data. It begins by outlining common fast data application patterns like real-time analytics, data pipelines, and fast request/response. It then contrasts streaming approaches like Storm with database approaches like VoltDB. The document argues that streaming operators often require state, which databases can provide through metadata tables and session state tables. It presents VoltDB as a solution that can handle real-time analytics, request/response decisions, and data pipelines with its export functionality to move data to data lakes and OLAP systems.















![page
© 2014 VoltDB PROPRIETARY
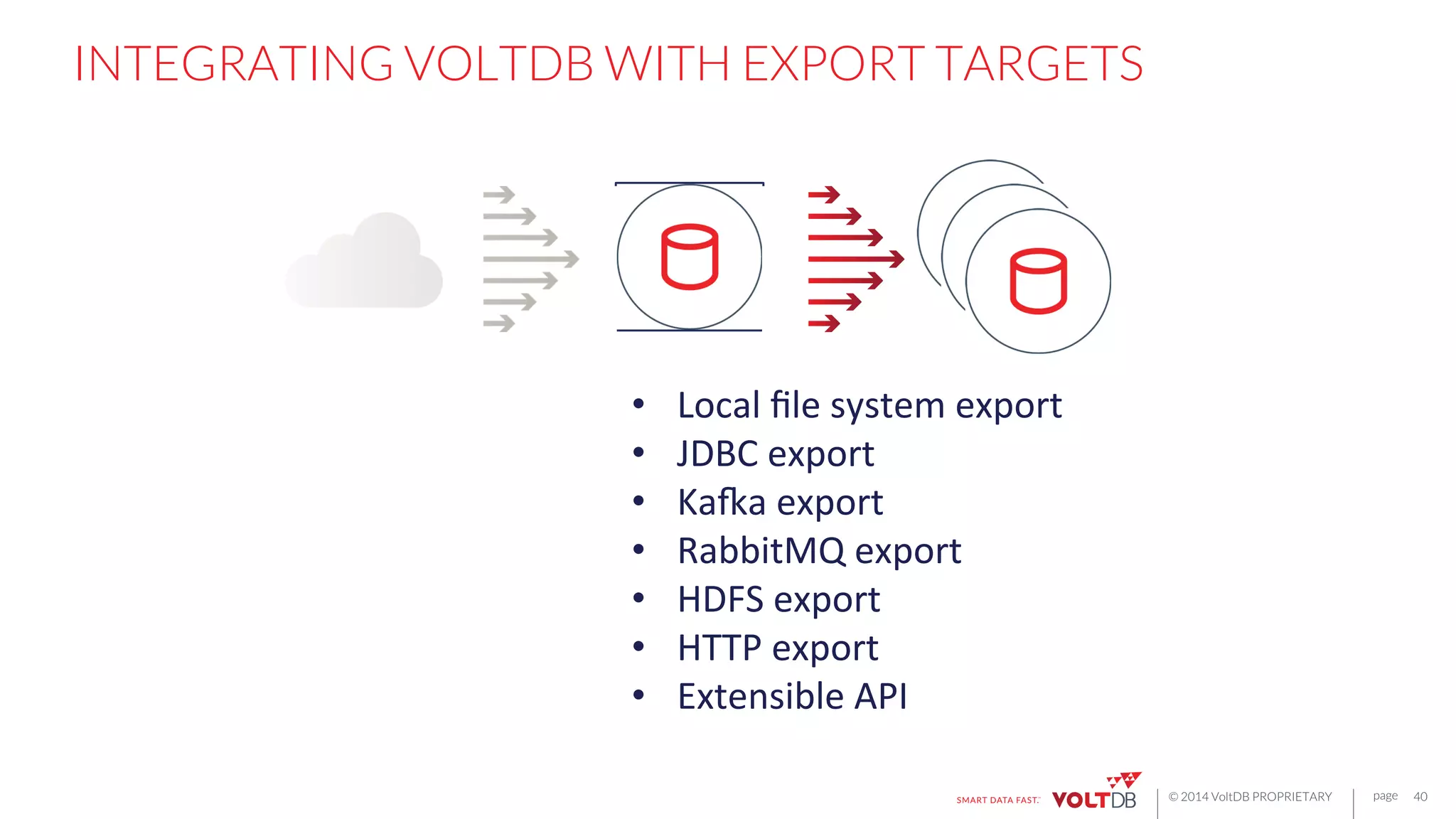
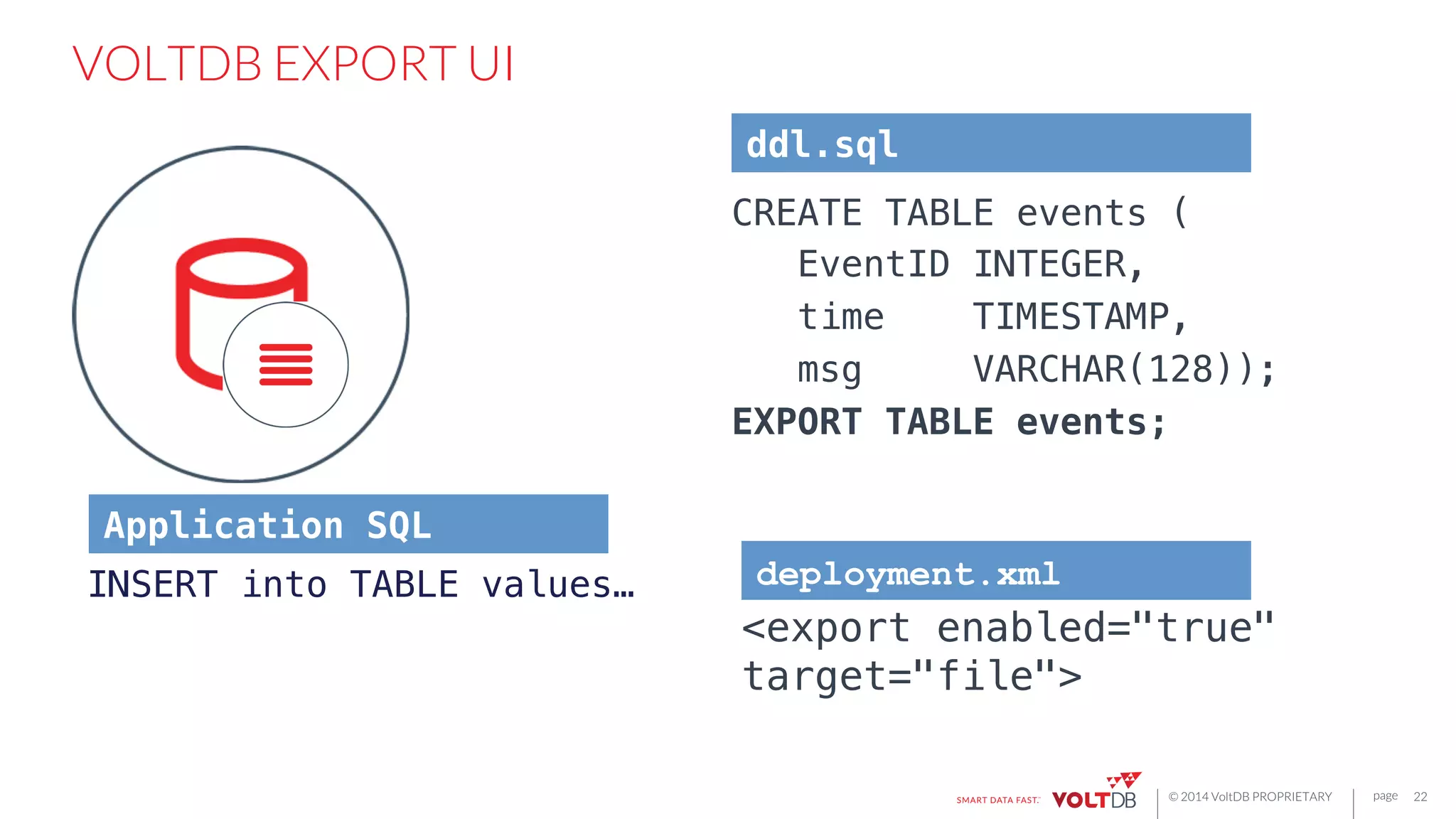
EXTENSIBLE API
25
public void onBlockStart() throws RestartBlockException;{!
}!
!
public boolean processRow(int rowSize, byte[] rowData) throws
"RestartBlockException {!
}!
!
public void onBlockCompletion() throws RestartBlockException {!
}!
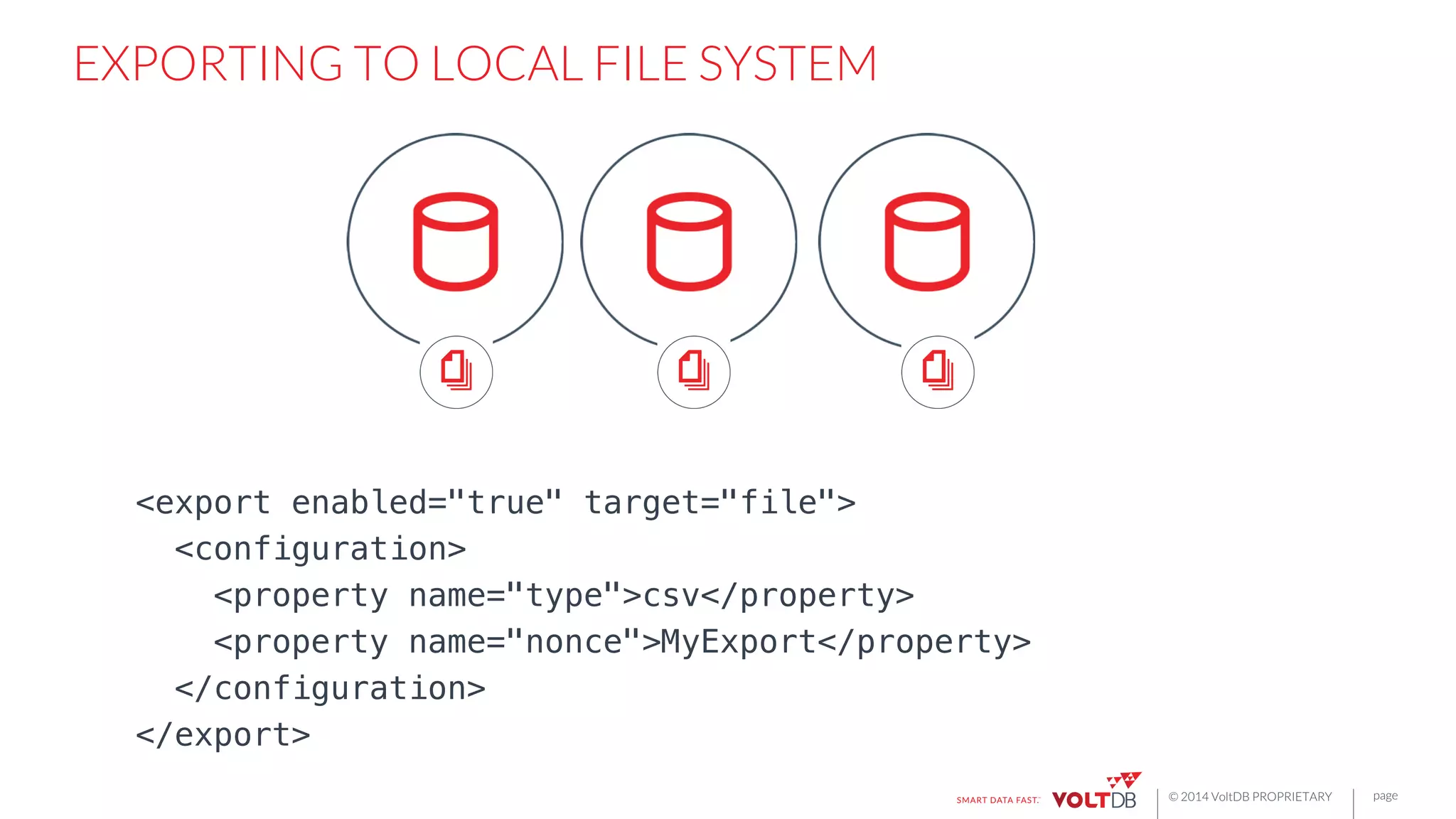
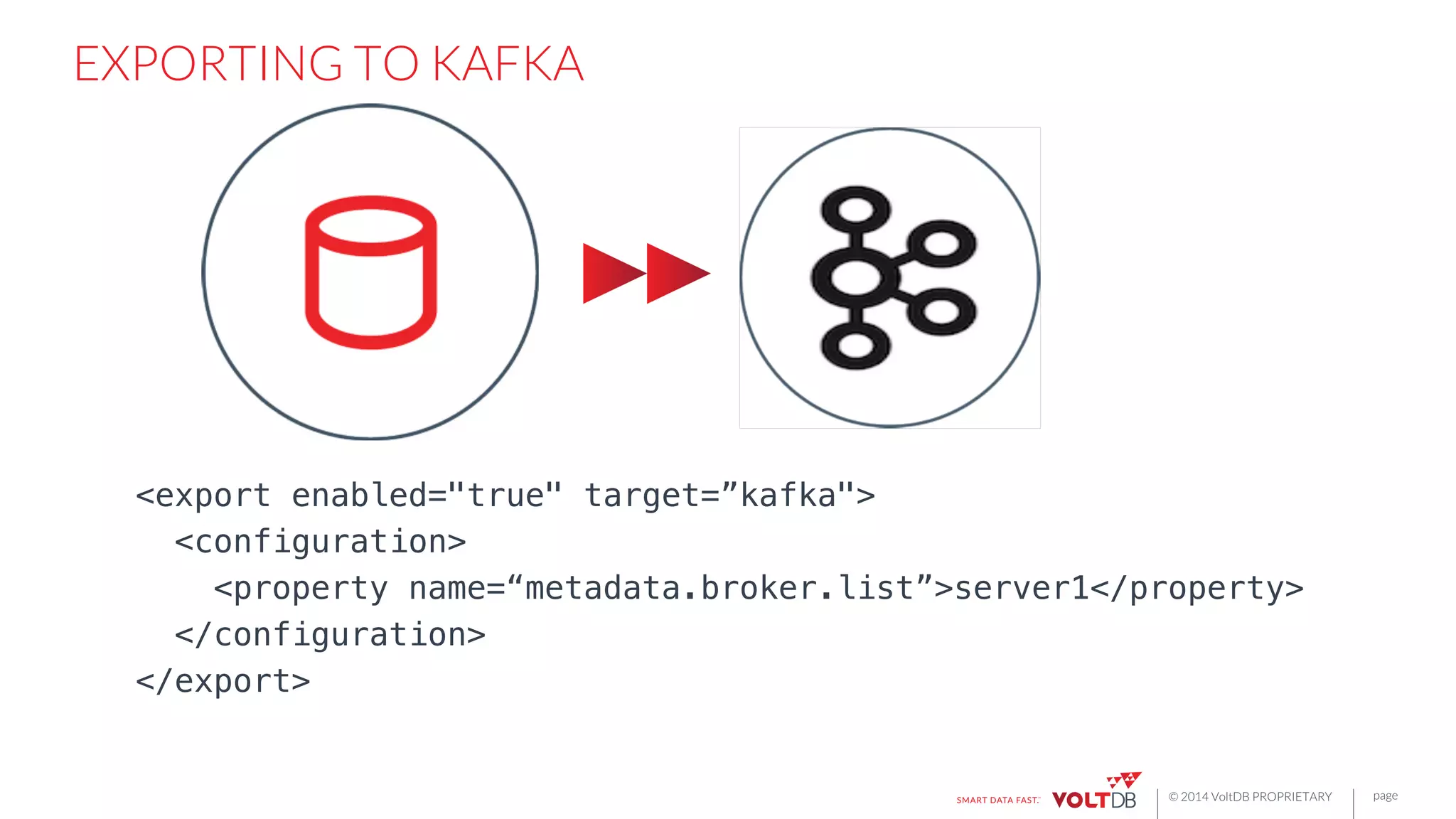
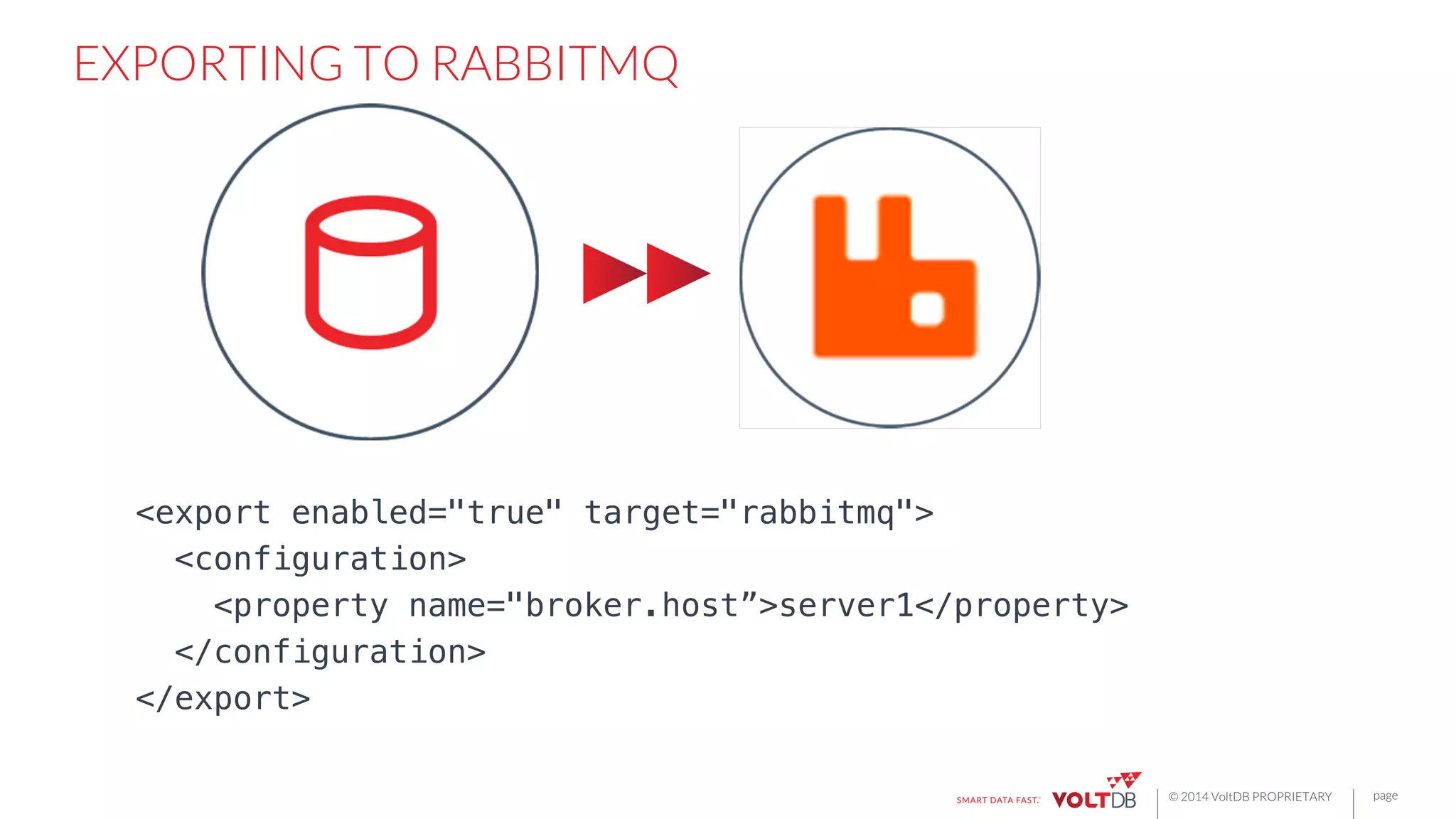
All
of
these
export
connectors
are
hosted
plugins
to
the
VoltDB
database.
VoltDB
manages
HA,
fault
tolerance,
configura6on,
and
MPP
scale-‐out.](https://image.slidesharecdn.com/rbettsbostondatafestival-150116085502-conversion-gate01/75/Building-Fast-Applications-for-Streaming-Data-25-2048.jpg)






![page
© 2014 VoltDB PROPRIETARY
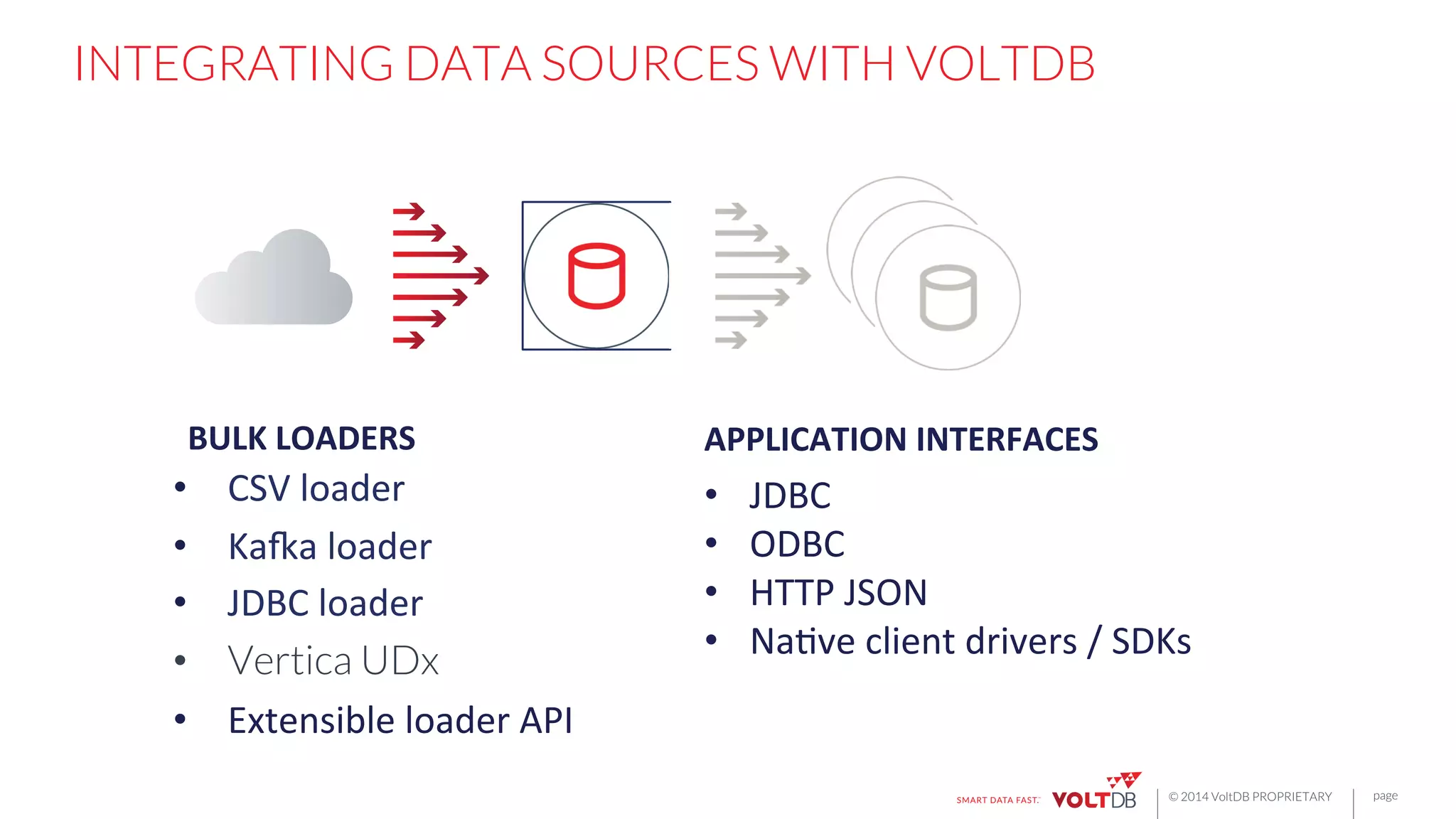
NATIVE CLIENT LIBRARIES
• Java
• C++
• PHP
• Node.js
• Go
• Python
• Erlang
• Ruby
Or,
just…
curl ‘http://localhost:8080/api/1.0/?!
Procedure=Vote&Parameters=[1,1,0]’!](https://image.slidesharecdn.com/rbettsbostondatafestival-150116085502-conversion-gate01/75/Building-Fast-Applications-for-Streaming-Data-37-2048.jpg)