Downloaded 407 times



![Why Yury
Google: Yury Oracle [phone|email]
Twitter, LinkedIn, Blog, Slideshare,YouTube
Oracle ACE (RAC SIG international chair, Sydney Oracle Meetups)
Oracle Certified Master
Oracle DBA with 15+ years experience
I like my job, I like what I do, I like to share knowledge, I like to help others to share knowledge, I like to learn, I like my job.
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-4-320.jpg)


![It isn’t about data files only !
File Type Supported
Control file YES Direct NFS: FAQ [ID 954425.1]
Data file YES
Redo log file YES
RDBMS file type support matrix for
Direct NFS client
Archive/Flashback log file YES
Backup files YES
Temp file YES
Datapump dump file YES blog “Direct NFS speeds up Data
Pump”
OCR files NO
spfile YES
passwd file YES
ASM files YES blog “Reasons for using ASM on
NFS”
Voting files NO
Audit files NO
Database trace files NO
External tables NO
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-7-320.jpg)

![How can the dNFS usage be verified?
Direct NFS: FAQ [ID 954425.1]
1. Just after the initialization parameters are
listed in the alert log, you will see the
following entry
Oracle instance running with ODM: Oracle
Direct NFS ODM Library Version 2.0
2. Along with the message from the alert log,
this query on v$dnfs_servers ensures that dNFS
is truly being used (returns !=0 value):
select count(*) from v$dnfs_servers
( sometimes it isn’t true ;)
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-11-320.jpg)
![How can the dNFS usage be verified?
In my experience, the easiest and most reliable way is
1. lsof –p < dbw pid >
# DNFS OFF
lsof -p 725 | grep data01.dbf
oracle 725 oracle 262u REG ... /nfsimp/data01.dbf (192.168.51.21:/u01)
# DNFS ON
lsof -p 6540 | grep 192.168.51.21
oracle 6540 oracle 32u IPv4 ... TCP dbhost:26171->nfsserver:nfs (ESTABLISHED)
2. alert.log
Direct NFS: channel id [0] path [IPnfs] to filer [KUKARACHA] via local [IPdb] is UP
Direct NFS: channel id [1] path [IPnfs] to filer [KUKARACHA] via local [IPdb] is UP
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-12-320.jpg)

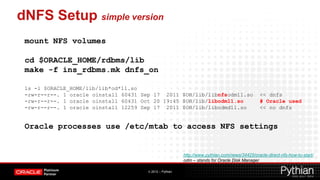
![dNFS setup – is documented
Step by Step - Configure Direct NFS Client on Linux [ID 762374.1]
Step by Step - Configure Direct NFS Client on Windows [ID 1468114.1]
=======================================================
Set filesystemio_options at least to directIO. ALL database files.
● PART A -- SETTING UP THE NFS SERVER ON LINUX
...
iv) Make sure the NFS server will get started during boot of this server.
...
MOUNTING NFS ON THE CLIENT NODE / CLUSTER NODES ON LINUX
...
stgasm:/oraclenfs /oradata1 nfs
rw,bg,hard,nointr,rsize=32768,wsize=32768,tcp,actimeo=0,vers=3,timeo=600 0 0
# Please contact your NAS vendor for NFS mount option recommendations.
...
● PART B -- Configure Direct NFS Client (DNFS)
i) Configure oranfstab file
...
Direct NFS Client can use a new configuration file or the mount tab file (/etc/mtab on Linux)
to determine the mount point settings for NFS storage devices.
...
● PART C -- DNFS Workshop
Oracle® Grid Infrastructure Installation Guide11g Release 2 (11.2) for Linux
3 Configuring Storage for Grid Infrastructure for a Cluster and Oracle RAC
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-14-320.jpg)
![dNFS oranfstab (things to remember)
● You can live without it (simple implementations)
● DB Hangs When DNFS is Enabled on UEK kernel [ID 1460787.1]
● You may get confused reading though documentations
● Enabling Direct NFS Client Oracle Disk Manager Control of NFS
● Server, Local, Path, Export, Mount, Mnt_timeout, Dontroute
● Server – any name you like (alias for a channel)
● Local, Path - You can specify other IPs than in mtab
● Export, Mount – local and remote mount points
● Mnt_timeout – sessions drops a connection after the timeout
● Dontroute – don’t use OS routeing table to send TCP/IP packages
Oracle Direct NFS configuration file explained
http://www.pythian.com/news/37259/oracle-direct-nfs-configuration-file-explained/
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-16-320.jpg)






![dNFS: wtmax = /proc/fs/nfsd/max_block_size
Oracle® Grid Infrastructure Installation Guide 11g Release
2 (11.2) for Linux
Caution: Direct NFS will not serve an NFS server with
write size values (wtmax) less than 32768.
...
ALTER DATABASE OPEN
Direct NFS: attempting to mount /u02 on filer KUKARACHA2 defined in oranfstab
Direct NFS: channel config is:
channel id [0] local [192.168.51.30] path [192.168.51.21]
Direct NFS: mount complete dir /u02 on KUKARACHA2 mntport 963 nfsport 2049
Direct NFS: Invalid filer wtmax 525232 on filer KUKARACHA2
Direct NFS: Filer wtmax 525232 must be an even multiple of 32768
Thread 1 opened at log sequence 26
...
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-23-320.jpg)
![dNFS: wtmax = /proc/fs/nfsd/max_block_size
Pythian’s dNFS related blog posts
root@nfsfiler01 sysconfig# cat /proc/fs/nfsd/max_block_size
524288
root@nfsfiler01 sysconfig# echo 1048576 > /proc/fs/nfsd/max_block_size
root@nfsfiler01 sysconfig# cat /proc/fs/nfsd/max_block_size
1048576
...
ALTER DATABASE OPEN
Direct NFS: attempting to mount /u02 on filer KUKARACHA2 defined in oranfstab
Direct NFS: channel config is:
channel id [0] local [192.168.51.30] path [192.168.51.21]
Direct NFS: mount complete dir /u02 on KUKARACHA2 mntport 883 nfsport 2049
Direct NFS: channel id [0] path [192.168.51.21] to filer [KUKARACHA2] via local [192.168.51.30] is UP
Direct NFS: channel id [1] path [192.168.51.21] to filer [KUKARACHA2] via local [192.168.51.30] is UP
Beginning crash recovery of 1 threads
...
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-24-320.jpg)

![References
Direct NFS: FAQ [ID 954425.1]
Example About How To Setup DNFS On Oracle Release 11.2 [ID 1452614.1]
How to Setup Direct NFS client multipaths in same subnet [ID 822481.1]
DB Hangs When DNFS is Enabled on UEK kernel [ID 1460787.1]
DB hang and ORA-600 [2116] errors when enabling DNFS [ID 1484422.1]
DNFS CANNOT MOUNT FILESYSTEM AND DATABASE FAILED WITH ORA-600 [2116] AFTER A REBOOT OF SERVER
DUE TO POWER FAILURE [ID 1480788.1]
DATABASE STARTUP HANGS AT MOUNTING CONTROLFILE WHEN DNFS IS ENABLED. [ID 971406.1]
Database Startup Failed with "Direct NFS: please check that oradism is setuid“ [1430654.1]
ORA-600 [2116] Using The Veritas Odm Lib Oracle Fails To Mount [ID 418603.1]
OERI [2116] [900] during database mount with > 13 instances [ID 9790947.8]
TESTCASE Step by Step - Configure Direct NFS Client (DNFS) on Windows [ID 1468114.1]
Database Alert Log entries: Direct NFS: Failed to set socket buffer size.wtmax=[1048576]
rtmax=[1048576], errno=-1 [ID 1352886.1]
@kevinclosson Oracle 11g, Direct NFS Client, An Oracle White Paper + http://bit.ly/QU3w82
@leight0nn http://blogs.griddba.com/2012/02/direct-nfs-speeds-up-data-pump.html
@rene_kundersma https://blogs.oracle.com/XPSONHA/entry/using_dnfs_for_test_purposes
@yvelikanov http://www.pythian.com/news/tag/dnfs/
© 2012 – Pythian](https://image.slidesharecdn.com/dnfsexp04-121023202441-phpapp01/85/Sharing-experience-implementing-Direct-NFS-26-320.jpg)



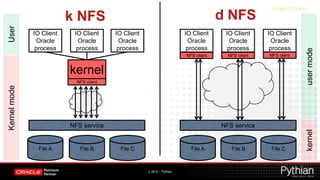
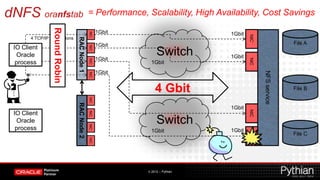
Direct NFS (dNFS) allows Oracle databases to access NFS-mounted storage directly without going through the kernel. This improves performance by reducing context switches between user and kernel space. The document discusses setting up dNFS including mounting NFS shares, configuring the oranfstab file, and verifying dNFS usage. It also provides an overview of dNFS concepts such as using multiple TCP connections in a round-robin fashion for high throughput and availability.





















![E34 : [JPOUG Presents] Oracle Database の隠されている様々な謎を解くセッション「なーんでだ?」再び @ db tec...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtechshowcase2015-150612232815-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![OOW16 - Advanced Architectures for Oracle E-Business Suite [CON6705]](https://cdn.slidesharecdn.com/ss_thumbnails/con6705-elkephelps-advanced-architectures-for-oracle-e-business-suite-160930182612-thumbnail.jpg?width=640&height=640&fit=bounds)






































































