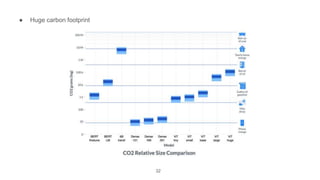
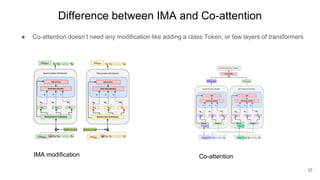
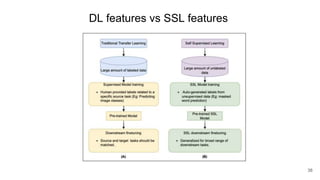
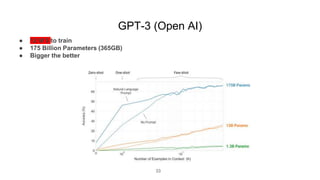
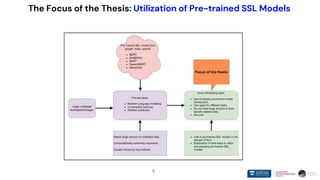
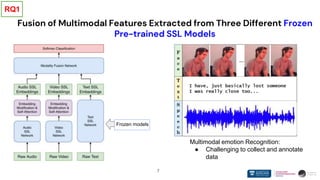
The document presents research on the use of pre-trained self-supervised learning (SSL) models in natural language understanding (NLU) within limited data contexts. It explores various research questions regarding the fusion of multimodal features from SSL models, domain adaptation techniques, and the impact of these models on tasks like emotion recognition and summarization. Findings indicate that pre-trained SSL models exhibit strong performance and adaptability, even with minimal high-quality data, which can significantly enhance tasks in AI.







![14
Some Findings
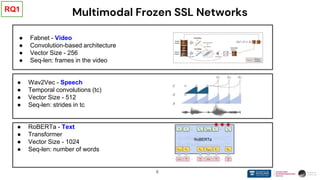
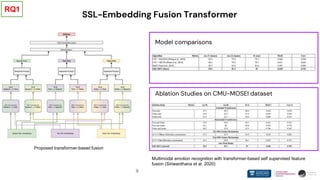
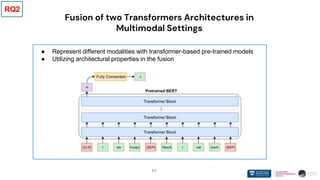
❖ Pre-trained SSL models with transformer-based architectures can easily fuse together
➢ Employing unique properties like [CLS] token
➢ Shallow fusion
❖ Transformer-based SSL models can finetune stably even with less amount of data
➢ Can finetune stably with lower learning rates
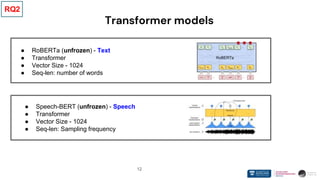
❖ Transformer architecture is becoming increasingly ubiquitous in self supervised
learning
➢ Transformer-based models represent different data modalities
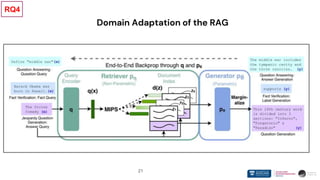
RQ2
Findings related to RQ2 have presented as a full conference paper in Interspeech 2020. S. Siriwardhana, Reis A, Weerasakera R, Nanayakkara S. “Jointly
Fine-Tuning BERT-like Self Supervised Models to Improve Multimodal Speech Emotion Recognition.” Proceedings of the Annual Conference of the
International Speech Communication Association, INTERSPEECH. Vol. 2020.
H index - 100](https://image.slidesharecdn.com/shamane-phd-defence-final-230724212035-a8268c3c/85/Shamane-PhD-Defence-Final-pptx-15-320.jpg)

![19
Some of the Findings
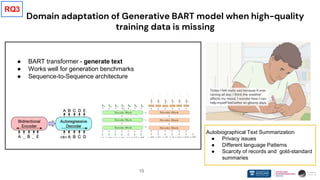
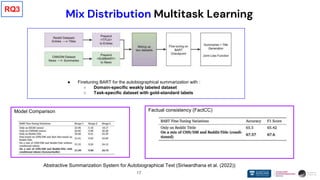
❖ SSL models like BART consist of strong language generation capabilities
➢ Such models have seen a large amount of data during the pre-training
➢ BART-like models can perform well even without high-quality data
❖ Data-centric approaches are crucial when adopting tasks like autobiographical
text summarization
➢ Designing better mechanisms to make use of available domain-specific data
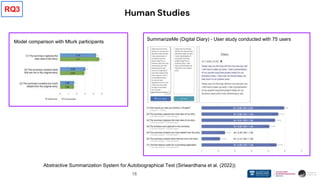
❖ Human studies are essential and beneficial for evaluating generative models
Findings related to RQ3 have submitted as a journal paper in ISRE 2022. S. Siriwardhana, Kalurachchi T, Chithralekha G Scholl P, Dissanayake V,
Nanayakkara S. ``SummarizeMe: Abstractive Summarization System for Autobiographical Text'' Proceedings of the Information System Research (ISR)
2022 [Under review]
RQ3](https://image.slidesharecdn.com/shamane-phd-defence-final-230724212035-a8268c3c/85/Shamane-PhD-Defence-Final-pptx-20-320.jpg)



![Directly related publications
● S. Siriwardhana, T. Kaluarachchi, M. Billinghurst and S. Nanayakkara, "Multimodal Emotion Recognition With Transformer-
Based Self Supervised Feature Fusion," in IEEE Access 2020.
● Siriwardhana S, Reis A, Weerasakera R, Nanayakkara S. ``Jointly Fine-Tuning BERT-like Self Supervised Models to
Improve Multimodal Speech Emotion Recognition.'' Proceedings of the International Speech Communication Association,
INTERSPEECH. 2020.
● Siriwardhana S, Kalurachchi T, Scholl P, Dissanayake V, Nanayakkara S. ``SummarizeMe: Abstractive Summarization
System for Autobiographical Text'' Proceedings of the Information System Research (ISR) 2022 [Under review]
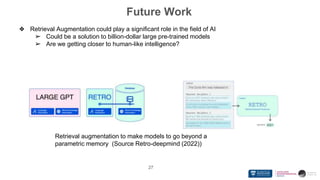
● Siriwardhana S, Weerasakera R, Kalurachchi T, Elliott W, Rana R, Nanayakkara S. ``Improving the Domain Adaptation of
Retrieval Augmented Generation (RAG) Models for Open-Domain Question-Answering'' Transactions of the Association for
Computational Linguistics TACL 2022 (will be presented at EMNLP - 2022)
29
Other Publications
● Wen, E., Kaluarachchi, T., Siriwardhana, S., Tang, V., Billinghurst, M., Lindeman, R.W., Yao, R., Lin, J. and
Nanayakkara, S.C., 2022. VRhook: A Data Collection Tool for VR Motion Sickness Research. Proceedings of the Annual
Conference of the User Interface Software and Technology UIST ’22.
● Kaluarachchi, T., Siriwardhana, S., Wenn, E., and Nanayakkara, S., A Corneal Surface Reflections-Based Intelligent
System for Lifelogging Application. International Journal of Human Computer Interaction (IJHCI) 22(4), [Under Review]](https://image.slidesharecdn.com/shamane-phd-defence-final-230724212035-a8268c3c/85/Shamane-PhD-Defence-Final-pptx-29-320.jpg)