Download as PDF, PPTX


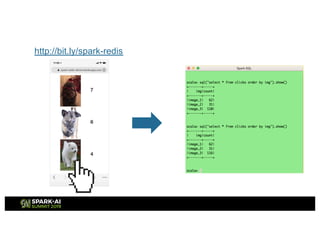


![Data Ingest Solution
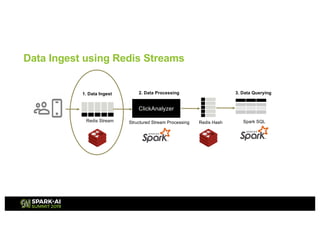
Redis Stream
1. Data Ingest
Command
xadd clickstream * img [image_id]
Sample data
127.0.0.1:6379> xrange clickstream - +
1) 1) "1553536458910-0"
2) 1) ”image_1"
2) "1"
2) 1) "1553536469080-0"
2) 1) ”image_3"
2) "1"
3) 1) "1553536489620-0"
2) 1) ”image_3"
2) "1”
.
.
.
.](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-18-320.jpg)



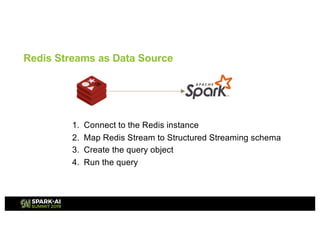
![Code Walkthrough: Redis Streams as Data Source
1. Connect to the Redis instance
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-26-320.jpg)
![Code Walkthrough: Redis Streams as Data Source
2. Map Redis Stream to Structured Streaming schema
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count
xadd clickstream * img [image_id]](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-27-320.jpg)
![Code Walkthrough: Redis Streams as Data Source
3. Create the query object
val spark = SparkSession.builder()
.appName("redis-df")
.master("local[*]")
.config("spark.redis.host", "localhost")
.config("spark.redis.port", "6379")
.getOrCreate()
val clickstream = spark.readStream
.format("redis")
.option("stream.keys","clickstream")
.schema(StructType(Array(
StructField("img", StringType)
)))
.load()
val queryByImg = clickstream.groupBy("img").count](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-28-320.jpg)

![Redis as Output Sink
override def process(record: Row) = {
var img = record.getString(0);
var count = record.getLong(1);
if(jedis == null){
connect()
}
jedis.hset("clicks:"+img, "img", img)
jedis.hset("clicks:"+img, "count", count.toString)
}
Create a custom class extending ForeachWriter and override the method, process()
Save as Hash with structure
clicks:[image]
img [image]
count [count]
Example
clicks:image_1001
img image_1001
count 1029
clicks:image_1002
img image_1002
count 392
.
.
.
.
img count
image_1001 1029
image_1002 392
. .
. .
Table: Clicks](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-30-320.jpg)

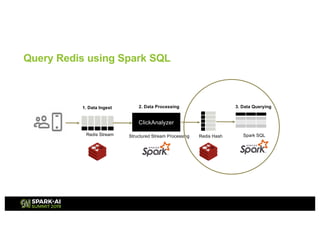

![1. Initialize
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession.builder().appName("redis-
test").master("local[*]").config("spark.redis.host","localhost").config("spark.redis.port","6379").getOrCreate()
scala> val sc = spark.sparkContext
scala> import spark.sql
scala> import spark.implicits._
2. Create table
scala> sql("CREATE TABLE IF NOT EXISTS clicks(img STRING, count INT) USING org.apache.spark.sql.redis OPTIONS (table
'clicks’)”)
How to Query Redis using Spark SQL](https://image.slidesharecdn.com/042007roshankumar-190507232820/85/Redis-Structured-Streaming-A-Perfect-Combination-to-Scale-Out-Your-Continuous-Applications-34-320.jpg)


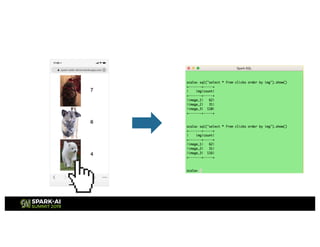
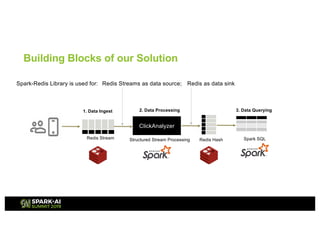



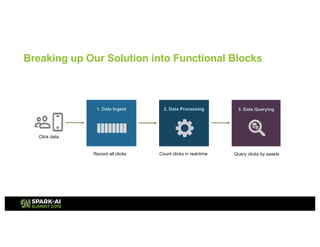
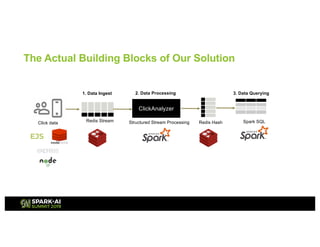
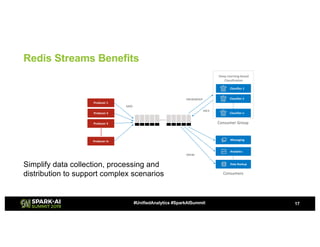
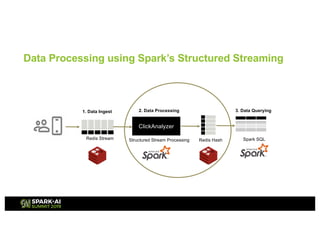
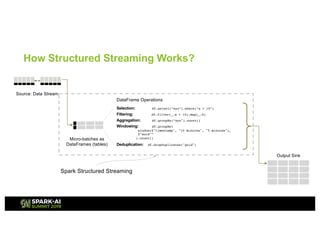
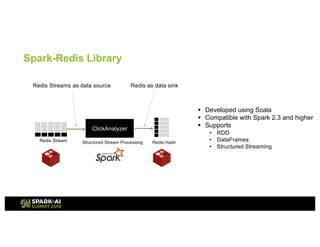
This presentation discusses how to use Redis and Spark Structured Streaming to process streaming data at scale. The solution breaks down into three functional blocks - data ingest using Redis Streams, data processing using Spark Structured Streaming, and data querying using Spark SQL. Redis Streams are used to ingest streaming click data, Spark Structured Streaming processes the data in micro-batches, and Spark SQL queries the processed data stored as Redis hashes. This combination provides a scalable solution to continuously collect, process, and query data streams in real-time.










































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Borko Kozomora - Optimizing business workflows with advances ...](https://cdn.slidesharecdn.com/ss_thumbnails/hbgekyb0txw0xpo4yfml-borko-kozomora-leading-ai-transformation-260122103838-cc29ee38-thumbnail.jpg?width=640&height=640&fit=bounds)