Downloaded 10 times















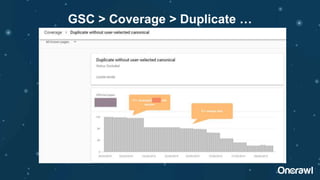



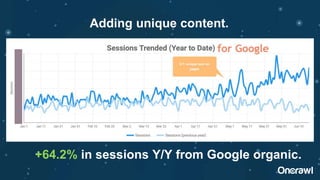

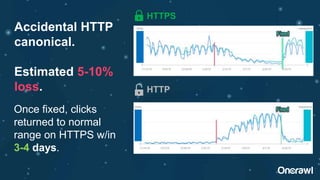











The document discusses the significance of duplicate content in SEO, emphasizing that while there is no manual penalty, it can impact indexing, links, and crawl bandwidth. It outlines common sources of duplication and offers strategies for identifying and resolving issues, including consolidating content and utilizing canonical tags. Additionally, the document speculates on the future of duplicate content management, highlighting trends towards automation and improved detection by search engines.












































































