Downloaded 10 times




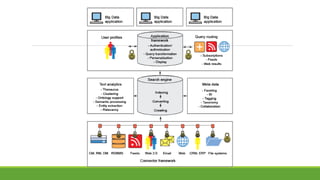


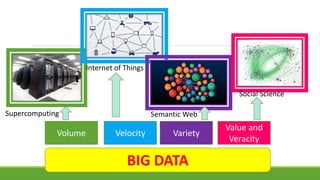




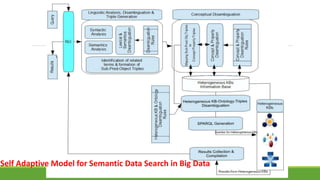




This document discusses using semantic web technologies to help make sense of big data by linking and integrating heterogeneous data sources. It presents a self-adaptive natural language interface model that takes a natural language query as input, considers possible concept annotations and SPARQL query patterns, runs the queries, and returns results to a reasoner to identify the correct query and answer. The model was tested on geography and Quran ontologies and was able to correctly answer questions with different SPARQL patterns. The conclusion discusses how semantic web and linked data can help analyze big data and create more personalized applications.



























































































