Downloaded 26 times



















![from the set S, s ⇠ Multinomial(✓s)
e a set of entities e 2 e, where each e is
drawn from the set E, e ⇠ Multinomial(✓e)
as ⇠ Bernoulli(✓sa
) indicates if s is an alias
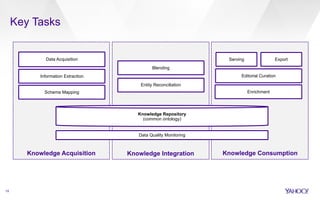
Entity linking for web search
30
as,e ⇠ Bernoulli(✓s,e
a ) indicates if s is an
alias pointing (linking/clicked) to e
c indicates which collection acts as a source
of information—query logs or Wikipedia (cq or cw)
n(s, c) count of s in c
n(e, c) count of e in c
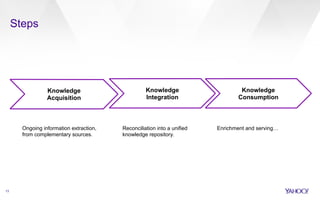
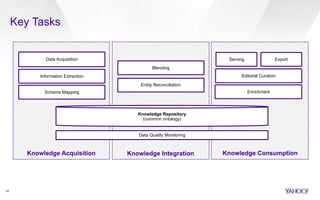
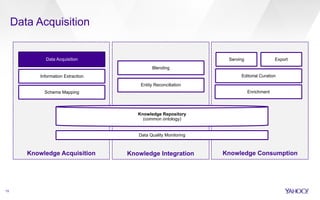
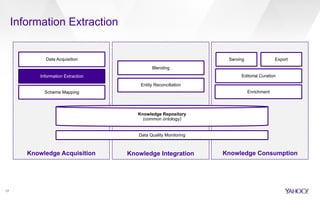
▪ Idea: jointly model mention detection (segmentation) and entity
selection
Let q be the input query, which we represent with the set
Sq of all possible segmentations of its tokens t1 · · · tk. The
algorithm will return the set of entities e, along with their
scores, that maximizes:
› compute probabilistic score for each segment-entity pair
› optimize the score of the whole query
argmax
e2E
log P(e|q) = argmax
e2E,s2Sq
P
e2e log P(e|s) (1)
s.t. s 2 s ,
S
s ✓ s ,
T
s = ;. (2)
In Eq. 1 we assume independence of the entities given a query
segment, and in Eq. 2 we impose that the segmentations are
disjoint. Each individual entity/segment probability is then
segmentation that optimizes the entity:
argmax
e2E,s2Sq
max
e2e,s2s
Both Eq. 1 and Eq. 10 are instances segmentation problem, defined as terms t = t1 · · · tk, denote any segment [titi+1 . . . ti+j−1] 8i, j ( 0. Let "that maps segments to real numbers, score of a segmentation is defined m(t1, t2, . . . , tk) =
✓
max
# (m(t1),m(t2, . . . , tk)) , . . . , # ("([t1 . . . , tk−1]),m(where m(t1) = "([t1]) and #(a, b) function, such as #(a, b) = a + #(a, b) = max(a, b) in the case function s(·) only depends on the the others, the segmentation with computed in O(k2) time using dynamic We instantiate the above problem "(s) = highestscore(s, q) =](https://image.slidesharecdn.com/20141031ssa-webscalesemanticsearch-141118105213-conversion-gate02/85/Web-scale-semantic-search-30-320.jpg)







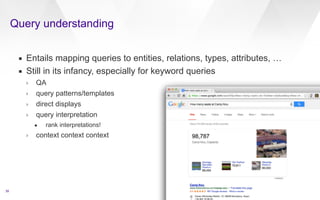
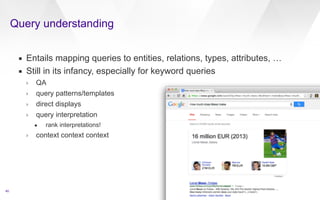
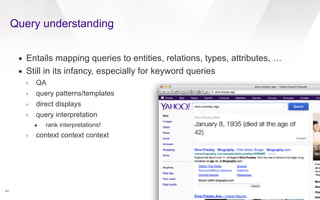



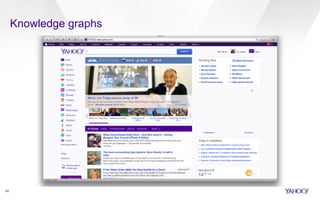










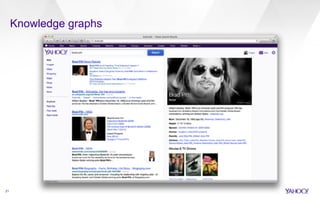
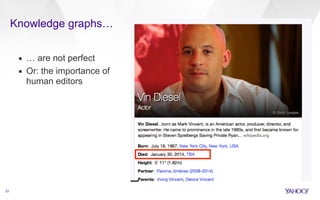
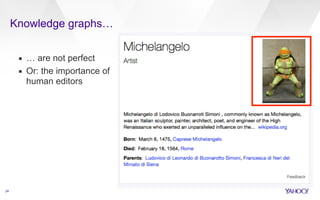
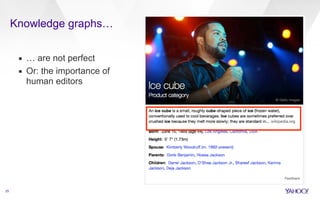
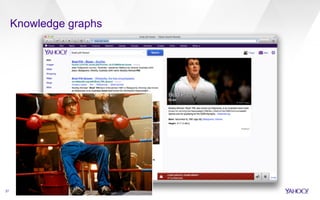
This document discusses web-scale semantic search and knowledge graphs. It introduces the concept of semantic search, which deals with understanding the meaning of queries, terms, documents and results. This is achieved by linking text to unambiguous concepts or entities. The document then discusses knowledge graphs, which define entities, attributes, types, relations and more, and form the backbone of semantic search. It also covers tasks involved in semantic search like information extraction, entity linking, query understanding and result ranking.










![(Micro)Blog : un sujet de recherche actuel [08/02/2011]](https://cdn.slidesharecdn.com/ss_thumbnails/bsg34-130516014447-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































