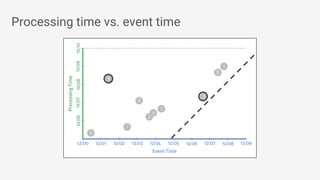
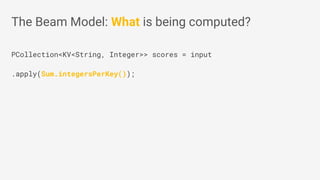
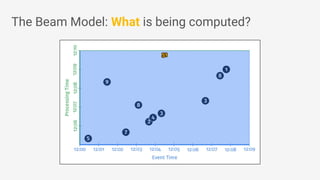
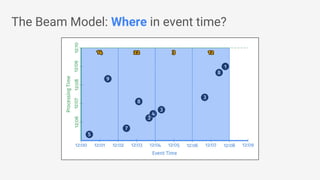
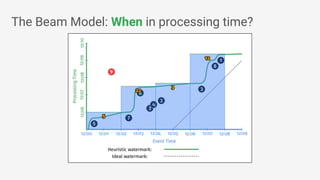
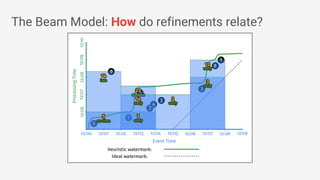
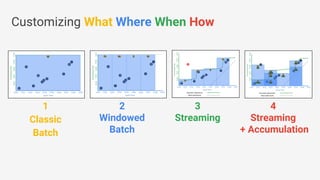
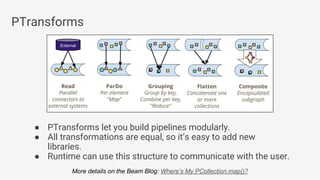
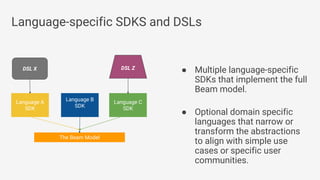
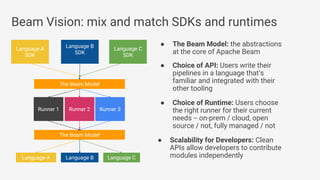
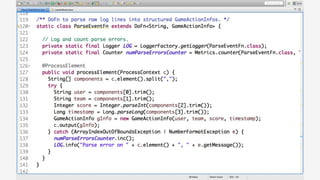
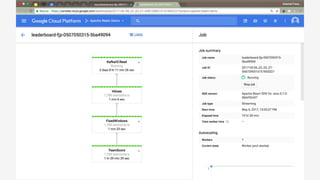
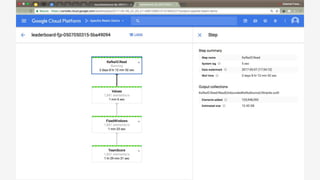
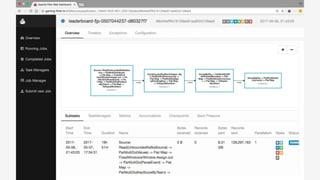
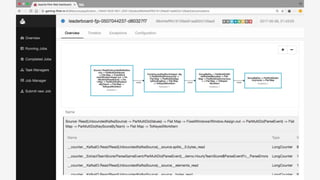
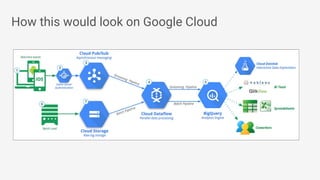
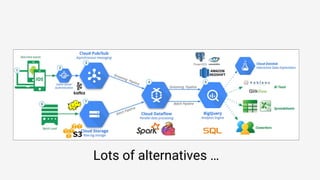
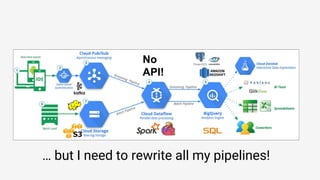
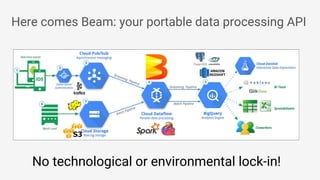
The document discusses Apache Beam, an open-source data processing API that enables the development of portable and scalable batch and streaming pipelines. It highlights its key features such as unified processing, extensibility, and support for multiple runtime environments, making it easy for developers to build data analytics solutions without being locked into specific technologies. A use case involving gaming analytics illustrates how to leverage real-time data collection and analysis to improve player engagement and spending.






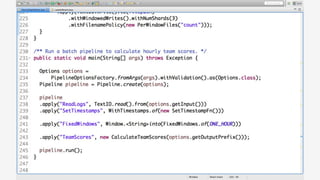
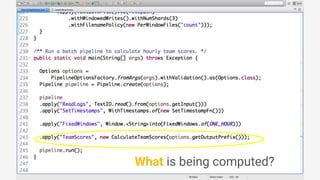

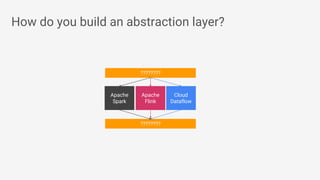
![● Beam’s Java SDK runs on multiple
runtime environments, including:
○ Apache Apex
○ Apache Spark
○ Apache Flink
○ Google Cloud Dataflow
○ [in development] Apache Gearpump
● Cross-language infrastructure is in
progress.
○ Beam’s Python SDK currently runs
on Google Cloud Dataflow
● First stable version at the end of May!
Beam Vision: as of May 2017
Beam Model: Fn Runners
Apache
Spark
Cloud
Dataflow
Beam Model: Pipeline Construction
Apache
Flink
Java
Java
Python
Python
Apache
Apex
Apache
Gearpump](https://image.slidesharecdn.com/portablebatchstreamingpipelineswithapachebeambigdatameetupmay2017-170512172649/85/Portable-batch-and-streaming-pipelines-with-Apache-Beam-Big-Data-Applications-Meetup-May-2017-16-320.jpg)