Download as PDF, PPTX




























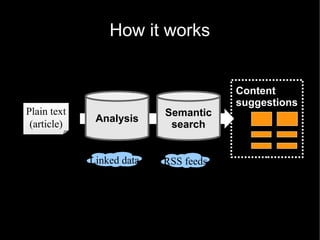

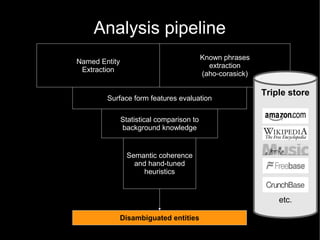
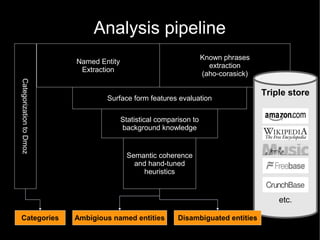


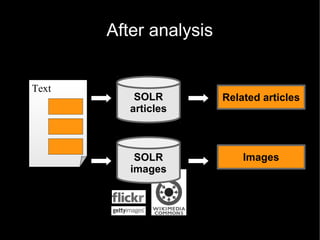



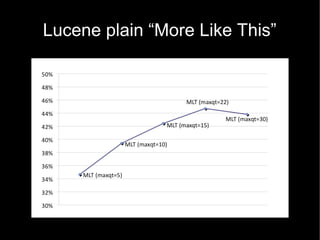




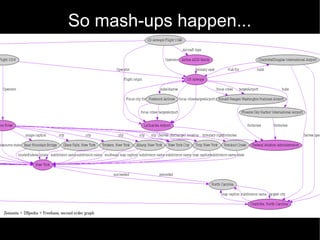






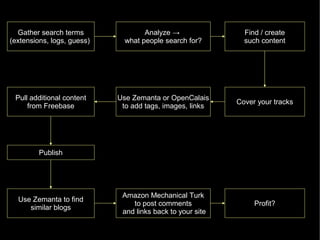

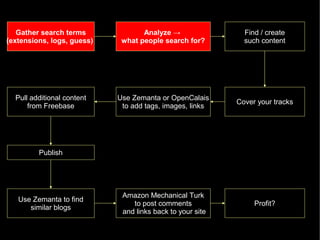

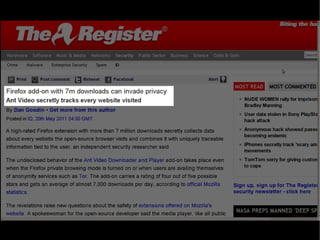

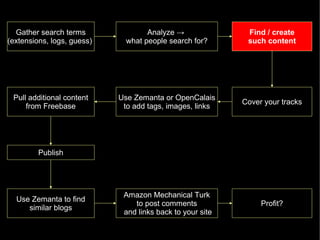





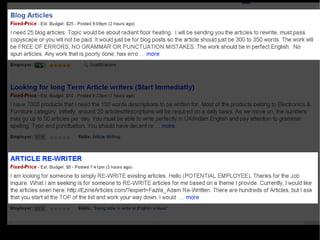
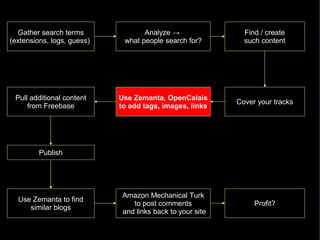


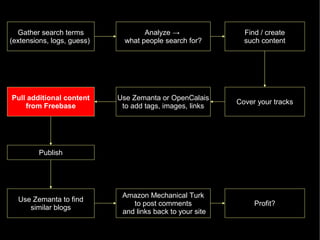
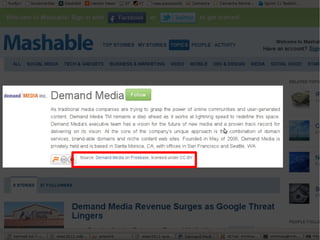

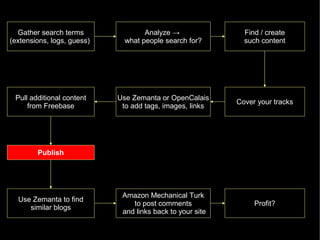

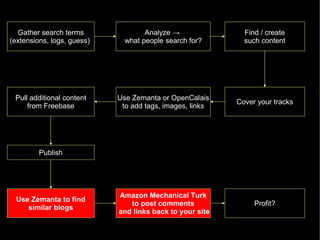


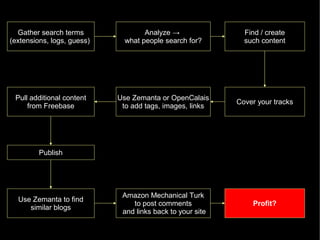











The document discusses the interplay between quality and quantity on the web, highlighting how spammers aim to profit from mass-produced, low-quality content while efforts exist to organize and enhance information. It describes the work of Zemanta, a tool designed to assist writers by connecting content with relevant resources and improving the quality of published material. The text warns about the rise of disorganized content and spamming while noting the ongoing evolution of content creation and search engine dynamics.









































































