Download as PDF, PPTX











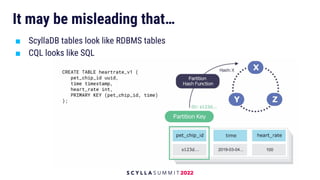

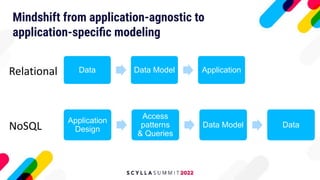






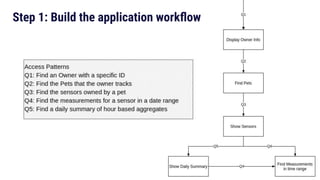
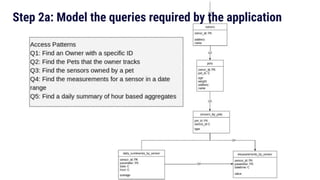
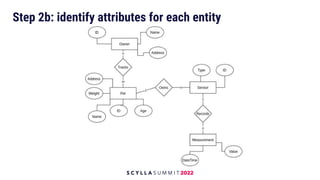

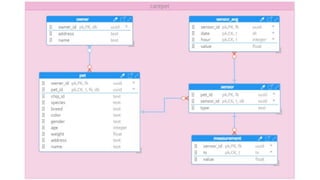



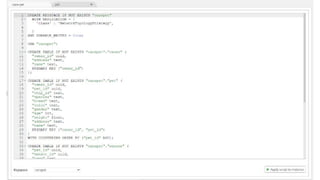

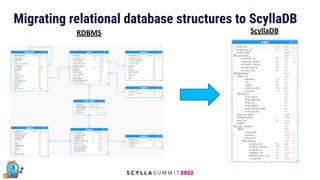
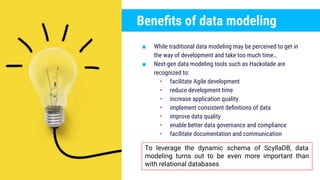


The document discusses data modeling best practices for ScyllaDB, emphasizing its significance in software development and the characteristics of ideal ScyllaDB applications. It outlines principles for creating effective data models, such as understanding primary and clustering keys, and encourages balancing data distribution with efficient query access. Finally, it suggests a methodology for migrating relational database structures to ScyllaDB while highlighting the benefits of data modeling tools.












![[❤PDF❤] Oracle 19c Database Administration Oracle Simplified](https://cdn.slidesharecdn.com/ss_thumbnails/0137142838-210409040449-thumbnail.jpg?width=640&height=640&fit=bounds)










































































